CVPR2022 | Group R-CNN : 化框为点,简化物体检测数据标注
物体检测作为最基础的视觉任务之一, 一直受到学术界与工业界的广泛关注。自深度学习兴起以来,数据驱动成为了主流。而检测作为实例级别的任务,需要标注员为每个感兴趣的实例标注框与类别,这导致标注员需要较长时间来精细地调整框的边界,使得检测数据标注成本变得较高。近些年随着检测模型结构与训练流程越来越成熟,大家开始越来越关注如何低成本地获得检测数据。
我们在 CVPR2022 上提出了 Group R-CNN,可以有效地使用点标注来提升检测器性能,大幅度超越之前的方法,其基于 MMDetection 实现的代码现在已经开源,欢迎大家使用和交流。
Code :https://github.com/jshilong/GroupRCNN
Paper : https://arxiv.org/abs/2205.05920
为什么需要点标注
近些年大家为节省检测数据的获取成本,已经做了诸多尝试,提出了诸多新的 setting,例如 Semi-Supervised Object Detection 和 Weakly Semi-supervised with image level annotations,但都收获甚微。
Semi-Supervised Object Detection,即少量有带框标注的图片和大量无标注的图片,如下图所示。但是无标注数据能提供的信息仅仅是图片本身的结构信息,因此对检测器的提升较为有限。

Weakly Semi-supervised with image level annotations,即少量有带框标注的图片和大量图片级别类别标注的图片,如下图所示。虽然图片级别类别标注提供了一定的类别信息,但是没有提供任何实例的位置信息。而实例的定位是物体检测任务中重要的部分,因此对检测器的提升仍然较为有限。

那么,有没有可能存在一种标注,既可以提供实例的位置信息,又大大节省了标注时间呢?答案是有的。那就是我们此次论文和之前的 Point DETR 中都使用的 setting:Weakly Semi-supervised with point annotations,即少量有带框标注的图片和大量实例级别的点标注(带类别)。
实例级别的点标注只需要在图片中实例上的任意位置点一个点作为标注,如下图所示,从而节省了最耗时的调整框边界的时间。实测表明:相比标注框, 标注点只需要约1/ 9 的时间;相比图片级别的类别标注,时间上虽然没有明显的差异,但是却提供了更为丰富的实例位置信息,显然是一种更为经济的选择。

Group R-CNN 是如何利用点标注的
首先审视我们手头的数据,少量的带框标注的数据与大量的带点标注的数据,那么如何利用点标注呢?一个非常直觉的想法是:我们希望通过少量的框标注数据训练出一个网络,这个网络可以将实例上任意点的位置作为输入而输出对应的实例框. 。经过这样一个转换,我们就有了全量框标注的数据,就可以被任意的检测器使用了。
至此,我们发现问题的关键变为了:如何设计出一个检测器,当输入为图片以及图片中所有实例的点标注时, 网络输出为各个实例的框标注。
面对这样一个非典型的检测问题,我们该如何进行这样一个检测器的设计呢。回顾经典检测器的设计哲学(如 Faster R-CNN、Cascade R-CNN):我们一般会先利用 RPN 提出一些 propsals,这些proposals 应该具有足够高的 recall,然后通过第二阶段的检测头对这些框进行进一步的分类与回归,从而得到最终的检测结果。
秉持着先高 recall 再高 precision 的设计理念,我们按以下思路设计出了 Group R-CNN。
NOTE: 下文中 Ablation 中的结果均是我们在 COCO Val 上利用 Group R-CNN 将点标注转化为框,再计算框的 mAP 得来的,其可以代表 Group R-CNN 生成框的质量。
1. Instance-level proposal grouping,为每个实例构建 Instance Group 以提升 RPN Recall
首先我们分析点标注带来的信息,即图片中所有实例的类别与大概的位置。直觉上这样的信息几乎保证了我们的 recall 可以达到 100%。我们想到在 FPN 上,包含最佳预测的特征点一定在点标注投影附近,但是因为点标注失去了尺度信息,我们无法判定实例在其 FPN 的具体 level,由此我们想到可以用 instance-level proposal grouping 算法来提升 RPN 输出的 recall (如下图所示)。具体的实现过程为:我们将点标注投影到 FPN 的特征图上,选取投影在 FPN 每层最近的的K个点,共 5*K 个点组成一个 Instance Group,这个 Group 中应当包含了这个 Instance 备选框,考虑到一个特征图上存在点被包含在多个 group,最后我们会在 group 间进行一次 NMS 来去重。
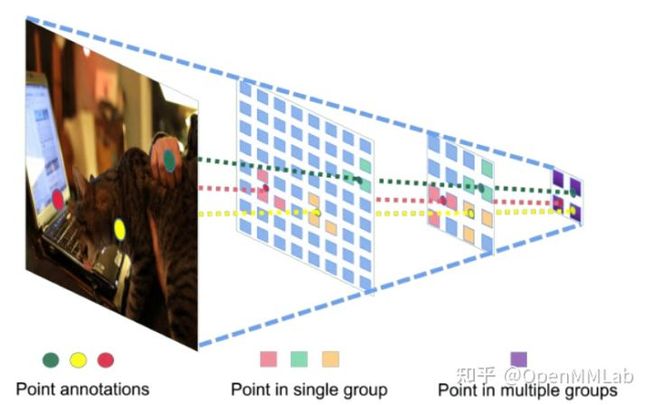
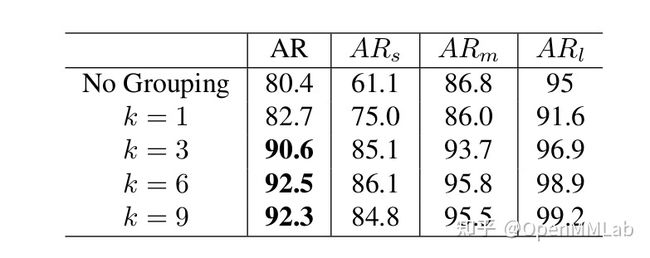
实验证明,我们提出的 instance-level proposal grouping 算法极大地提升了检测器的 recall,
从下表可以看到:在 K=3 时,我们在输出更少的 proposals 的情况下,就将 recall 从 80.4 提升到了90.6。
2. Instance-aware representation learning,实现 Instance Group 到实例框的一一对应
目前我们已经利用点标注结合 grouping 算法提升了 recall,接下来我们要做的就是经过 refine head,将每个 group 中最贴合对应实例的框选择出来(即要求只有贴合对应实例的框拥有高的分数),从而实现 Instance Group 到实例框的一一对应。
但是我们传统的 Faster R-CNN 和 Cascade R-CNN 的 refine head 都无法实现 Instance Group 到实例框的一一对应。因为传统的正负样本匹配策略是:只要 proposal 与任意 GT 框的 IOU 大于一定的阈值,那就是正样本。所以一个实例组的 proposal 可能匹配到其他的实例,最后可能导致两个 Instance Group 经过 refine head 会存在同一实例的高分框。在同类拥挤的情况下,最后很容易导致多个 Instance Group 选择出来同一实例的框。而在较为拥挤的 COCO 数据集中,同类拥挤的现象是十分常见的。
所以一个非常自然的想法是:我们实现 Instance 级别的正负样本匹配,即每个 Group 内的框只有与对应实例的 IOU 大于特定阈值,才会被认为是正样本。我们利用下图来展示 Instance Assign 与传统的 Assign 的不同:红色框代表负样本,蓝色框代表正样本,(a)中展示了传统 Assign 的正负样本,(b)、(c)、(d)分别展示了框在不同实例组的 Assign 结果。

想法非常美好,但是经过我们这样简单的修改后,发现效果不增反降,这是为什么呢?经过分析讨论,因为 CNN 具有等变性, 不同的 Instance Group 的 proposal 共享了相同的 FPN feature map 与 head 参数,这样不同 group 中较为相似的 proposal 会有较为相似的回归输出与分数,但是在 instance 级别的 assign 策略下可能会有完全相反的 assign 结果,从而导致网络难以收敛,那如何解决这种矛盾呢?
我们想到从 FPN feature map 与 head 参数两方面入手,如下图所示:使得不同 group 相似 proposal 的 refine 后的结果适应我们新的 assign 策略。

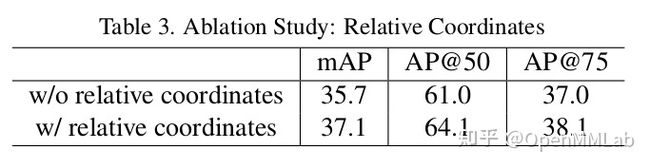
首先是 FPN feature map,我们希望不同 group 的 proposal 可以通过 RoI Pooling 获得 instance-awrare 的 feature,具体做法为:在每个 group 的 proposal 做 RoI Pooling 前,我们以这个实例的点标注为原点为其特征增加相对位置编码, 这样不同 group 的 proposal 区域池化的特征就是不同的了,同时这样的编码也有助于网络感知物体的大体位置, Ablation 也证明了我们猜想是正确的,如下表所示:
另一个策略是为不同的 group 生成特定的参数,如何生成参数才能对 group 内的 RoI feature 更具有针对性呢,即可以识别出一个 RoI feature 是否是属于对应实例而不是对应类别的,我们想到构造两个向量来表征一个实例:
1.我们已经通过点标注知道了这个实例的类别,那我们可以提前初始化一系列 Category Embedding,从而选择对应的 Category Embedding 作为一个实例的标志。
2.我们想到一个 group 内或许某个单一的 proposal 会与其他 instance 有较大 IOU,但是平均来看,绝大多数 proposal 还是与对应实例有更大的 IOU,那么一个 group 内所有 roi feature 的均值也是一个很好的标志。
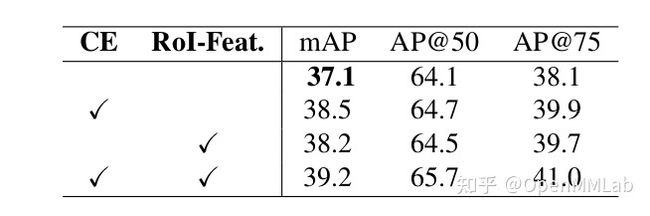
我们将 Category Embedding(CE) 与 mean RoI Feature 联合在一起,共同生成这个这个 group 的部分 head 参数,从而增加不同 group 的区分性,从下表可以看到:提升非常明显。
与之前方法的对比
我们在 COCO 训练集上抽取不同比例(5%,10%...)的数据作为全标注数据。剩余数据我们从实例 mask 上随机选择一个点来模拟人的标注,这样我们就拥有了全标注数据和大量点标注数据。
在训练过程中,我们仅仅使用全标注数据来训练 Group R-CNN,使其获得从点标注推理框标注的能力,在每个 iteration,我们在 GT 框内随机选择一个点作为输入标注点来回归对应 GT。训练结束后,我们在点标注数据上推理出所有 GT 框,这样我们就有了一个完整标注的 COCO 数据集,为了与之前的 Point DETR 对比,我们使用这样的数据来训练一个 FCOS 模型,以观察我们生成的 GT 框的质量。

从上图可以发现,我们相比之前的方法 Point DETR 提升较大,在使用 5% 的全标注 和 95% 的点标注数据时,提升接近 4mAP;仅仅使用 50% 全标注数据时,就可以达到接近原 COCO 标注的效果。
待探索的问题
细心的读者可能会发现,相比现在 Semi 的方法, 我们只最大程度地利用全标注的数据来训练 Group R-CNN, 虽然我们在补充材料里也简单尝试了使用点标注数据来提高 Group R-CNN 并证明了可行性,但都是非常 naive 的尝试,值得后来者继续探索。
另外整个问题的 setting 也并没有非常成熟,现在我们主要衡量的还是点标注生成的框的质量,如何尽可能利用全标注与点标注来尽可能提升一个检测器的性能也是值得探索的方向。
但是无论如何,一个高性能的点标注到框标注的转化网络都是绕不开的一步,希望 Group R-CNN 能成为检测点标注问题的一个坚实的 baseline。
小预告:
令人期待的全球计算机视觉盛宴 CVPR 2022 就要来啦,作为计算机视觉领域最具有影响力的开源算法平台 OpenMMLab 又怎会错过呢!本次大会上,我们将举办主题为 OpenMMLab: A Foundational Platform for Computer Vision Research and Production 的 Tutorial。
我们很荣幸地邀请到 5 位重磅演讲嘉宾,他们分别是香港中文大学的林达华教授、南洋理工大学的吕健勤教授、清华大学交叉信息院的赵行教授、微软亚洲研究院主任研究员胡瀚博士以及 OpenMMLab 负责人、上海人工智能实验室的青年科学家陈恺博士。大佬云集,是不是更加期待了?
本次 Tutorial 暂定在美国中部时间的 6 月 20 日举行,详细的分享主题和观看方式将在之后的推送中分享给大家,敬请期待哦~
(时间随主办方安排,可能会有变动)