PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】笔记
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】笔记
- 教程与代码地址
- P1 PyTorch环境的配置及安装(Configuration and Installation of PyTorch)【PyTorch教程】
- P2 Python编辑器的选择、安装及配置(PyCharm、Jupyter安装)【PyTorch教程】
- P3 【FAQ】为什么torch.cuda.is_available返回False
- P4 Python学习中的两大法宝函数(当然也可以用在PyTorch)
- P5 PyCharm及Jupyter使用及对比
- P6 PyTorch加载数据初认识
- P7 Dataset类代码实战
- P8 TensorBoard的使用(一)
- P9 TensorBoard的使用(二)
- P10 Transforms的使用(一)
- P11 Transforms的使用(二)
- P12 常见的Transforms(一)
- P13 常见的Transforms(二)
- P14 torchvision中的数据集使用
- P15 DataLoader的使用
- P16 神经网络的基本骨架-nn.Module的使用
- P17 土堆说卷积操作(可选看)
- P18 神经网络-卷积层
- P19 神经网络-最大池化的使用
- P20 神经网络-非线性激活
- P21 神经网络-线性层及其他层介绍
- P22 神经网络-搭建小实战和Sequential的使用
- P23 损失函数与反向传播
- P24 优化器(一)
- P25 现有网络模型的使用及修改
- P26 网络模型的保存与读取
- P27 完整的模型训练套路(一)
- P28 完整的模型训练套路(二)
- P29 完整的模型训练套路(三)
-
- torch.nn.module.train()
- torch.nn.module.eval()
- P30 利用GPU训练(一)
- P31 利用GPU训练(二)
- P32 完整的模型验证套路
- P33 【完结】看看开源项目
教程与代码地址
笔记中,图片和代码基本源自up主的视频和代码
视频链接: PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
视频代码: https://github.com/xiaotudui/PyTorch-Tutorial
如果想要爬虫视频网站一样的csdn目录,可以去这里下载代码:https://github.com/JeffreyLeal/MyUtils/tree/%E7%88%AC%E8%99%AB%E5%B7%A5%E5%85%B71
P1 PyTorch环境的配置及安装(Configuration and Installation of PyTorch)【PyTorch教程】
P2 Python编辑器的选择、安装及配置(PyCharm、Jupyter安装)【PyTorch教程】
P3 【FAQ】为什么torch.cuda.is_available返回False
P4 Python学习中的两大法宝函数(当然也可以用在PyTorch)
- dir()
- help()

P5 PyCharm及Jupyter使用及对比

P6 PyTorch加载数据初认识
在jupyter中:
from torch.utils.data import Dataset
# 查询Dataset的doc描述
# 方式一:
help(Dataset)
# 方式二:
Dataset??
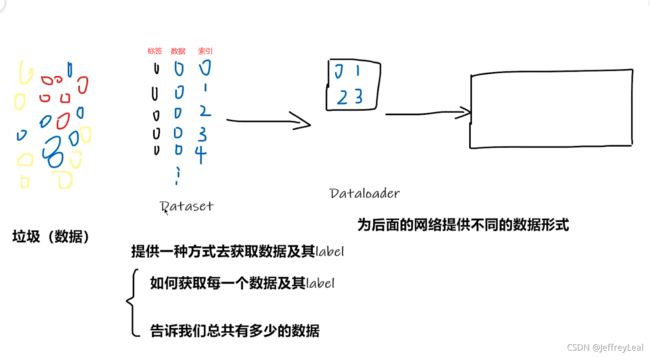 三种数据集标签标注形式:
三种数据集标签标注形式:
第一种:文件夹名字就是标签名;
第二钟:有另外一个文件记录下文件与标签的映射关系;
第三种:文件本身带有标签名。
P7 Dataset类代码实战
详细代码看read_data.py
from torch.utils.data import Dataset
os.path.join(self.root_dir, self.label_dir) 对地址字符串进行拼接,参数为可变形参
os.listdir(self.image_path) 把路径下的文件装入到list容器中
P8 TensorBoard的使用(一)
TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。
详细代码看P8_Tensorboard.py
from torch.utils.tensorboard import SummaryWriter
容易遇到以下问题,以及tensorboard的安装问题
pytorch 1.6.0 出现ModuleNotFoundError: No module named ‘tensorboard‘错误.
urllib.error.URLError: urlopen error [SSL: CERTIFICATE_VERIFY_FAILED]
P9 TensorBoard的使用(二)
详细代码看P8_Tensorboard.py
- 创建SummaryWriter类,传入logs文件输出地址
- 图片文件地址
- Image类打开图片文件
- 将Image类转换numpy格式
- SummaryWriter类加载numpy格式图片
- 画图
- 关闭SummaryWriter流
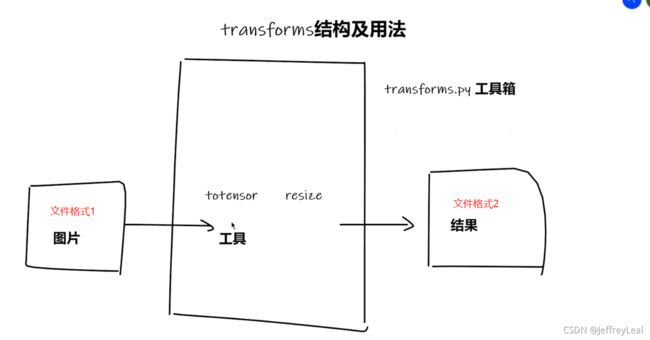
P10 Transforms的使用(一)
详细代码看P9_transforms.py
transforms一个torchvision下的一个工具箱,用于格式转化,视觉处理工具,不用于文本。
按住ctrl,点击transforms
再按住ctrl,点击transforms,就能看到transforms的源代码,左下角structure可以看到文件结构。

它里面有多个工具类:
Compose类:将几个变换组合在一起。
CoTensor类:顾名思义,讲其他格式文件转换成tensor类的格式。
ToPILImage类:转换成Image类。
Nomalize类:用于正则化。
Resize类:裁剪。
RandomCrop:随机裁剪。
工具类都有__call__()方法,具体作用看python中的 call().
P11 Transforms的使用(二)
P12 常见的Transforms(一)
格式转换流程都大同小异,以Image转换成tensor为例:
- 传入图片路径,创建Image类;
- 创建ToTensor类;
- 使用toTensor(image),传入Image类,调用ToTensor类的__call__()方法,返回Tensor类。
P13 常见的Transforms(二)

P14 torchvision中的数据集使用
进入pytorch官网
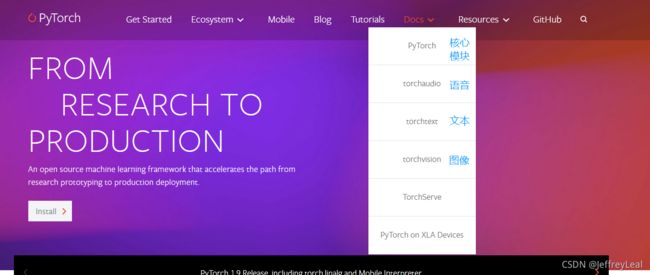
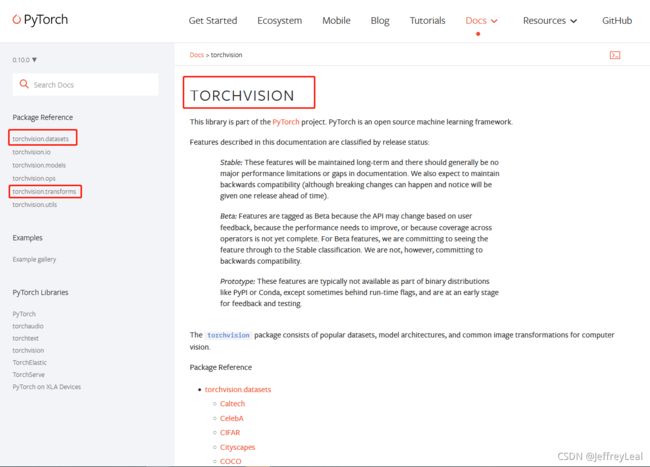 讲述dataset和transform的联合使用。
讲述dataset和transform的联合使用。
代码见P10_dataset_transform.py。
路径中:’.‘表示当前目录,’ …'表示上层目录,Linux里的shell语法
P15 DataLoader的使用
Dataset如果是一叠扑克牌的话,DataLoader就是一只手,参数就是告诉这只手怎么抓取扑克牌。
DataLoader常用参数:
dataset (Dataset) – 使用哪个数据集
batch_size (int, optional) – 一次抓取多少个数据,多少张牌
shuffle (bool, optional) – 是否重新洗牌
num_workers (int, optional) – 多线程,windows下要设成0,不然会出错,出现
BrokenPipeError: [Errno 32] Broken pipe
drop_last (bool, optional) – 当数据集大小不能被批大小整除时,设置为True则以删除最后一个不完整的批。False,则不删除,最后一批将变小。(默认值:False)
datasetloader加载批数据过程:
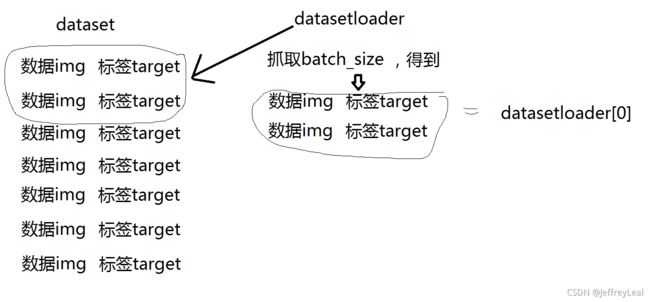 代码见dataloader.py
代码见dataloader.py
P16 神经网络的基本骨架-nn.Module的使用
代码见nn_module.py
input -> nn -> output,其中使用nn模型的时候,会自动调用__call__()方法,call()方法里面又调用了forword()方法,所以在继承一个nn模型的时候,要重写它的__init__()方法和__forword()__方法。
P17 土堆说卷积操作(可选看)
torch.nn模块会用就可以,相对于方向盘。
torch.functional模块不需要掌握,相对于齿轮。
卷积原理的保姆级教程。
代码见nn_conv.py,使用torch.nn.functional模块。
P18 神经网络-卷积层
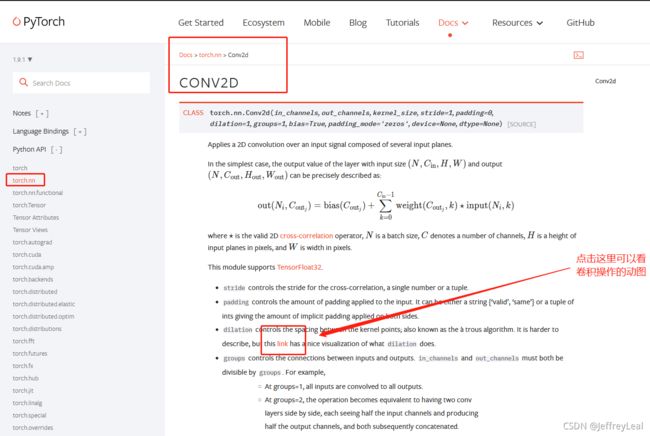
conv2d常用参数:
in_channels (int) – 输入通道数,RGB图像就是三通道。
out_channels (int) – 输出通道数,也就是卷积核的个数,输入通道不为1的情况,
kernel_size (int or tuple) – 卷积核大小,比如3就代表3×3的卷积核。
stride (int or tuple, optional) – 步长,卷积完成一次计算后,卷积核移动多少步。
padding (int, tuple or str, optional) – 填充,比如1就代表图像外围加一圈数据,默认都是0。
padding_mode (string, optional) – 填充模式,“零”、“反射”、“复制”或“圆形”。 默认值:‘零’ 。
dilation (int or tuple, optional) – 内核元素之间的间距 . Default: 1,具体这里介绍Dilated convolution animations
groups (int, optional) – 从输入通道到输出通道的阻塞连接数。 Default: 1
bias (bool, optional) –偏置,如果为 True,则向输出添加可学习的偏差。 默认值:真
P19 神经网络-最大池化的使用
class
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
ceil_mode – 对于float型,向上取整ceil还是向下取整floor。
代码见nn_maxpool.py
P20 神经网络-非线性激活
关于RELU,原始数据是否原地操作:

P21 神经网络-线性层及其他层介绍
代码见nn_linear.py
视频18:58左右运动代码出错,是因为最后一个batch的大小 代码见nn_loss.py和nn_loss_network.py 由于loss()函数接收的数要是float类型,所以传入tensor数据的时候,要把tensor()参数中的dtype=torch.float32 代码见nn_optim.py 出名的模型才会有现有的 代码见model_save.py和model_load.py format函数的用法: 详细见:Python format 格式化函数 代码见train.py 查看验证集 torch.no_grad函数:禁用梯度计算的上下文管理器。 torch.no_grad函数在用验证集的测试性能的时候使用,可以使得测试的过程中,不会计算用于反向传播的梯度,减小消耗。 在pytorch官网中ctrl+F搜索 将模块设置为训练模式。 这仅对某些模块有任何影响。 如果它们受到影响,请参阅特定模块的文档以了解其在培训/评估模式下的行为的详细信息,例如 Dropout、BatchNorm 等 将模块设置为评估模式。 这仅对某些模块有任何影响。 如果它们受到影响,请参阅特定模块的文档以了解其在培训/评估模式下的行为的详细信息,例如 Dropout、BatchNorm 等 这相当于 self.train(False)。 代码见train_gpu_1.py 使用以下句式进行gpu加速: 使用time模块来计时 使用谷歌、天池的GPU加速 代码见train_gpu_2.py 使用以下句式进行gpu加速: 06:00开始看,如何读懂github上面的代码P22 神经网络-搭建小实战和Sequential的使用
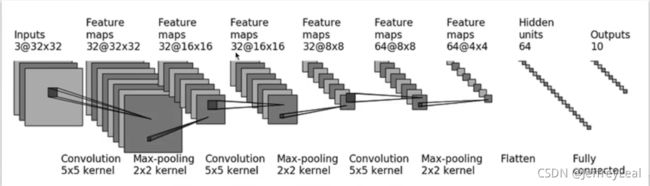 以下是这个模型的代码,Sequential的作用就是简化代码块1,把代码块1装进去Sequential容器里,就是代码块2的代码了,然后代码块1就可以删除了。
以下是这个模型的代码,Sequential的作用就是简化代码块1,把代码块1装进去Sequential容器里,就是代码块2的代码了,然后代码块1就可以删除了。
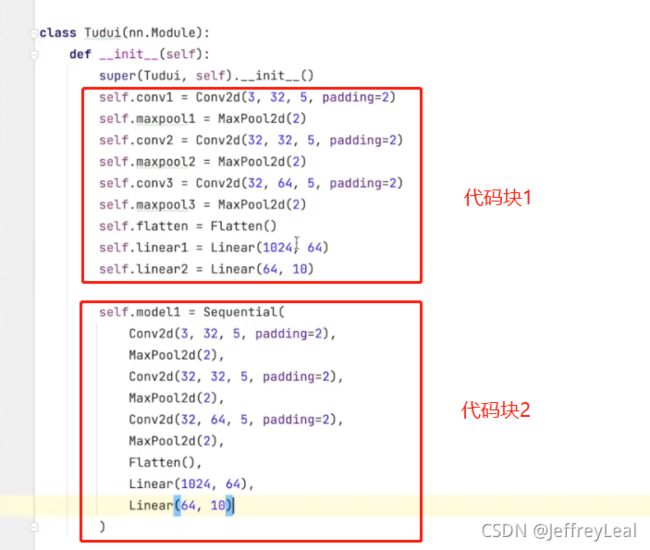
这里用tensorboard,可以得到非常牛逼的模型结构图P23 损失函数与反向传播
P24 优化器(一)
# 优化器通常设置模型的参数,学习率等
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
for input, target in dataset:
#把上一次计算的梯度清零
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# 损失反向传播,计算梯度
loss.backward()
# 使用梯度进行学习,即参数的优化
optimizer.step()
P25 现有网络模型的使用及修改
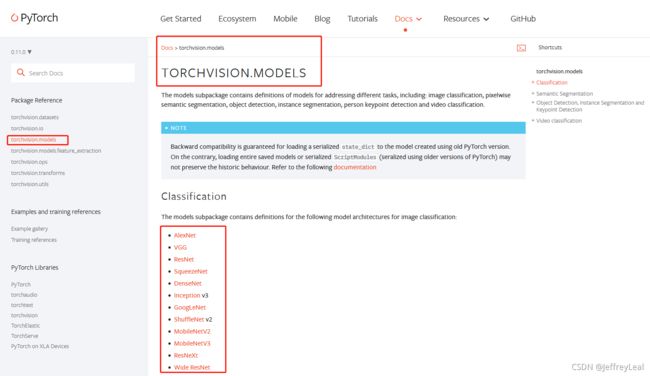 代码见model_pretrained.py
代码见model_pretrained.pyP26 网络模型的保存与读取
P27 完整的模型训练套路(一)
 代码见model.py和train.py
代码见model.py和train.pyprint("-------第 {} 轮训练开始-------".format(3))
输出:
-------第 3 轮训练开始-------
P28 完整的模型训练套路(二)
当您确定不会调用 Tensor.backward() 时,禁用梯度计算对于推理很有用。 它将减少原本需要 requires_grad=True 的计算的内存消耗。P29 完整的模型训练套路(三)
torch.nn.module.train()
torch.nn.module.eval()
P30 利用GPU训练(一)
if torch.cuda.is_available():
tudui = tudui.cuda()
P31 利用GPU训练(二)
device = torch.device("cuda")
# Tudui是一个神经网络模型
tudui = Tudui()
tudui = tudui.to(device)
P32 完整的模型验证套路

 代码见test.py
代码见test.pyP33 【完结】看看开源项目