Point Cloud Transformer的pytorch代码实现
目录
1. Attention
1.1 Self Attention
1.2 Offset Attention
2. Sampling and Grouping
2.1 KNN
2.2 FPS
2.3 Encoder
3. PCT
3.1 PCT
3.2 PCT2Cls
3.3 PCT2Seg
4. DataSet
5. Train
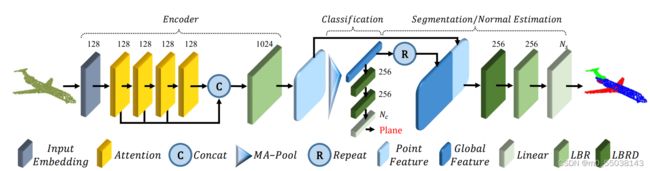
首先我们从PCT的整体架构来看,分析其所需要的基本网络包括作为Input Embedding的encoder,以及Attention模块,除此之外,还包括在sampling中使用到的knn以及FPS算法。下面将对其逐一实现。
1. Attention
1.1 Self Attention
class SelfAttention(nn.Module):
def __init__(self, in_f, dim_k=None, dim_v=None, transform='SS'):
"""
Self Attention Mechanism
:param in_f: dim of input feature
:param dim_k: dim of query,key vector(default in_f)
:param dim_v: dim of value vector,and also 3th dim of output(default in_f)
:param transform: SS(default) means Scale + SoftMax,SL means SoftMax+L1Norm
"""
super().__init__()
self.dim_k = dim_k if dim_k else in_f
self.dim_v = dim_v if dim_v else in_f
self.transform = transform
self.Q = nn.Linear(in_f, self.dim_k)
self.K = nn.Linear(in_f, self.dim_k)
self.V = nn.Linear(in_f, self.dim_v)
self.sm = nn.Softmax(dim=1)
def forward(self, x):
B, _, _ = x.shape
Q = self.Q(x)
K = self.K(x)
V = self.V(x)
if self.transform == 'SS':
att_score = self.sm(torch.divide(torch.matmul(Q, K.permute(0, 2, 1)), math.sqrt(self.dim_k)))
elif self.transform == 'SL':
QK = torch.matmul(Q, K.permute(0, 2, 1))
att_score = torch.divide(self.sm(QK), QK.sum(dim=2).view(B, -1, 1))
else:
att_score = None
Z = torch.matmul(att_score, V)
return Z我们首先实现了一个self attention模块,除了可以指定Q,K,V的dimension,还可以指定PCT文章中提到的方法,即SS(Scale & SoftMax)和SL(SolfMax & L1Norm),其中SS是Self Attention原本的方法。原文给出的公式如下(SS,SL)
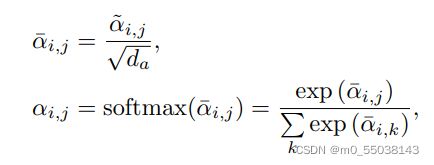
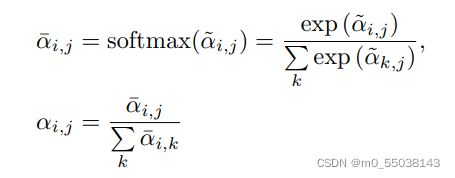
1.2 Offset Attention
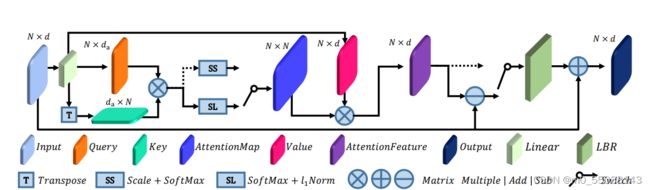
从PCT原文提供的Offset Attention架构来看,其实是对Self Attention的一个改进,作者表示这启发于拉普拉斯矩阵L=D-E在GNN上代替邻接矩阵E的好处。不难实现,其实就是把SA中得到的Z与原本的input做差,经过LBR之后得到输出。
class OffsetAttention(nn.Module):
def __init__(self, num_points, in_f, dim_k=None, dim_v=None):
"""
Offset-Attention
:param num_points: num of points
:param in_f: dim of input feature
:param dim_k: dim of query,key vector(default in_f)
:param dim_v: dim of value vector,and also 3th dim of output(default in_f)
"""
super().__init__()
self.dim_k = dim_k if dim_k else in_f
self.dim_v = dim_v if dim_v else in_f
self.sa = SelfAttention(in_f, self.dim_k, self.dim_v, 'SL')
self.fc = nn.Linear(self.dim_v, self.dim_v)
self.bn = nn.BatchNorm1d(num_points)
self.relu = nn.ReLU()
def forward(self, x):
atte_score = self.sa(x)
x = self.relu(self.bn(self.fc(atte_score.sub(x)))).add(x)
return x于是我们把上面实现的Self Attention作为这里的子网络进行调用。同时这里采用了前文提到的SL。
2. Sampling and Grouping
这里将会实现采样以及分组网络
2.1 KNN
def knn(x, k):
"""
knn 's application
:param x: (batch_size * num_point * in_f)
:param k: num of sampling point
:return: (batch_size * num_point * k * in_f)
"""
batch_size, num_point, in_f = x.size()
neigh = []
for b in range(batch_size):
neigh.append(NearestNeighbors(n_neighbors=k))
new_x = torch.zeros(batch_size, num_point, k, in_f)
for b in range(batch_size):
neigh[b].fit(x[b].detach().numpy())
z = torch.zeros(num_point, k, in_f)
for i in range(num_point):
_, index = neigh[b].kneighbors(x[b][i].reshape(-1, in_f).detach().numpy())
for t, j in enumerate(index[0]):
z[i][t] = x[b][j]
new_x[b] = z
return new_x
在这里我们直接调用sklearn中knn算法,将点云数据直接input到算法中(k作为hyper parameter),获取返回的k个近邻点的索引,并使用循环逐步拼接为output(B*N*K*in_f),注意这里输入的特征数据并非一定是B*N*3的,因为在网络架构中重复的LBR,Sampling&Grouping得到的特征维度会上升。
2.2 FPS
本算法在网上都有较多实现案例,但是返回的都是采样的索引,这里调用后进行一个简单的拼接即可。参考最远点采样(Farthest Point Sampling)介绍
def farthest_point_sample(x, samp_num):
"""
FPS
:param x: input [B,N,F]
:param samp_num: num of sampled points
:return:index of sampled points [B,samp_num]
"""
device = x.device
B, N, F = x.shape
centroids = torch.zeros(B, samp_num, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(samp_num):
# 更新第i个最远点
centroids[:, i] = farthest
# 取出这个最远点的xyz坐标
centroid = x[batch_indices, farthest, :].view(B, 1, F)
# 计算点集中的所有点到这个最远点的欧式距离
# 等价于torch.sum((xyz - centroid) ** 2, 2)
dist = torch.sum((x - centroid) ** 2, -1)
# 更新distances,记录样本中每个点距离所有已出现的采样点的最小距离
mask = dist < distance
distance[mask] = dist[mask]
# 从更新后的distances矩阵中找出距离最远的点,作为最远点用于下一轮迭代
# 取出每一行的最大值构成列向量,等价于torch.max(x,2)
farthest = torch.max(distance, -1)[1]
return centroids
def FPS(x, samp_num):
"""
using fps algorithm
:param x: input [B,N,F]
:param samp_num: num of sampled points
:return: sampled points [B,samp_num,F]
"""
index = farthest_point_sample(x, samp_num)
B, N, F = x.shape
new_x = torch.zeros(B, samp_num, F)
for i in range(B):
for k, j in enumerate(index[i]):
new_x[i][k] = x[i][j]
return new_x2.3 Encoder
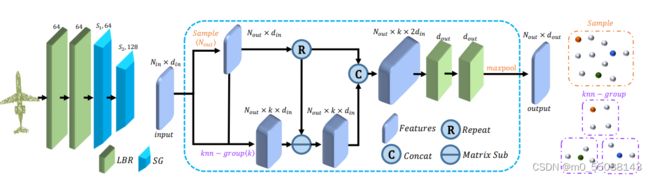
这里其实就是重复的LBR以及Sampling & Grouping,但是需要注意输入tensor维度的变化。
class SampGroup(nn.Module):
def __init__(self, in_f, k, sam_num, out_f):
"""
the model of Sampling&Grouping, after this you' ll get the result with [B,N,out_f]
:param in_f: dim of input feature
:param k: hyper parameter in knn
:param sam_num: num of sampled points
:param out_f: 3rd dim of output
"""
super().__init__()
self.k = k
self.sam_num = sam_num
self.out_f = out_f
self.fc1 = nn.Linear(2 * in_f, self.out_f)
self.fc2 = nn.Linear(self.out_f, self.out_f)
self.bn = nn.BatchNorm2d(self.sam_num)
self.relu = nn.ReLU()
self.mp = nn.MaxPool2d((self.k, 1))
def forward(self, x):
B, _, N = x.shape
sam_point = FPS(x, self.sam_num) # sampling
gro_point = knn(sam_point, self.k) # grouping in sampled points
sam_point = sam_point.repeat(1, self.k, 1, 1).view(B, self.sam_num, self.k, N) # repeat to [B,sam_num,k,3]
NKD = torch.sub(sam_point, gro_point) # repeated sam_points subtract grouped points
x = torch.cat((sam_point, NKD), dim=3) # concat them to [B,sam_num,k,2*3]
x = self.relu(self.bn((self.fc1(x)))) # first LBR
x = self.relu(self.bn((self.fc2(x)))) # second LBR
x = self.mp(x).view(B, self.sam_num, self.out_f) # max pooling to [B,sam_num,out_f]
return x
class InputEmbedding(nn.Module):
def __init__(self, num_points, k1, k2, sam_num1, sam_num2):
"""
input embedding, after this you' ll get the result with [B,N,128]
:param num_points: num of points
:param k1: first hyper parameter in grouping
:param k2: second hyper parameter in grouping
:param sam_num1: first hyper parameter in sampling
:param sam_num2: second hyper parameter in sampling
"""
super().__init__()
self.k1 = k1
self.k2 = k2
self.sam_num1 = sam_num1
self.sam_num2 = sam_num2
self.fc1 = nn.Linear(3, 64)
self.bn = nn.BatchNorm1d(num_points)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(64, 64)
self.SG1 = SampGroup(64, self.k1, self.sam_num1, 64)
self.SG2 = SampGroup(64, self.k2, self.sam_num2, 128)
def forward(self, x):
x = self.relu(self.bn((self.fc1(x))))
x = self.relu(self.bn((self.fc2(x))))
x = self.SG1(x)
x = self.SG2(x)
return x这里分为了两个模块,一个是作为子网络的Sampling&Grouping,一个是调用子网络的ImputEmbedding,这里的超参数包括sam_num(采样点数)、k(knn)、in_f(输入的特征第四维度,第一为batch size),注意他是有两个Sampling & Grouping的,自然k,sam_num就会有两个了。
3. PCT
PCT实现的任务分为两个,Classification以及Segmentation,因此在这里我们将分为三个模块,PCT(输出给后续任务),PCT2Cls(分类任务),PCT2Seg(分割任务)。回顾一下网络整体架构,然后逐一上代码。
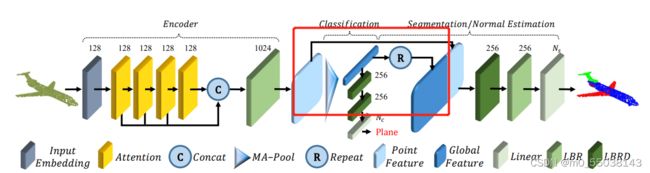
Classification任务直接获取Max Pooling结果,而Segmentation区别在于需要对Max Pooling后的输出做repeat,然后与Point Feature做一个拼接,除此之外Segmentation为了成功得到每个点的概率分布可以将采样点点设置成原有点云点数(即不做采样)。
原文

3.1 PCT
class PCT(nn.Module):
def __init__(self, k1, k2, sam_num1, sam_num2, drop=0.5, task='cls'):
"""
PCT for classification
:param sam_num1: first hyper parameter in sampling
:param sam_num2: second hyper parameter in sampling
:param k1: first hyper parameter in grouping
:param k2: second hyper parameter in grouping
:param drop: dropout rate
:param task: 'cls' or 'seg'
"""
super().__init__()
self.dropout = drop
self.task = task
self.sam_num2 = sam_num2
self.ec = InputEmbedding(num_points=10000, k1=k1, k2=k2, sam_num1=sam_num1, sam_num2=sam_num2)
self.offset_sa1 = OffsetAttention(sam_num2, 128)
self.offset_sa2 = OffsetAttention(sam_num2, 128)
self.offset_sa3 = OffsetAttention(sam_num2, 128)
self.offset_sa4 = OffsetAttention(sam_num2, 128)
self.fc = nn.Linear(128 * 4, 1024)
self.bm = nn.BatchNorm1d(sam_num2)
self.relu = nn.ReLU()
self.mp = nn.MaxPool2d((sam_num2, 1))
def forward(self, x):
x = self.ec(x)
Z1 = self.offset_sa1(x) # first offset attention
Z2 = self.offset_sa2(x) # second offset attention
Z3 = self.offset_sa3(x) # third offset attention
Z4 = self.offset_sa4(x) # forth offset attention
x = torch.cat((Z1, Z2, Z3, Z4), dim=2) # making concat
feat = self.relu(self.bm(self.fc(x)))
x = self.mp(feat) # first LBR and max pooling
if self.task == 'cls':
return x
elif self.task == 'seg':
return torch.cat((x.repeat(1, self.sam_num2, 1), feat), dim=2)
else:
return None通过逐一调用上述所实现的子网络,并且在输入参数时指定task即可得到相对应任务所需要的输出。
3.2 PCT2Cls
class PCT2Cls(nn.Module):
def __init__(self, num_cls, sam_num1=512, sam_num2=256, k1=20, k2=20, drop=0.5):
"""
for classification
:param num_cls: num of class
:param sam_num1: first hyper parameter in sampling, default 512
:param sam_num2: second hyper parameter in sampling, default 256
:param k1: first hyper parameter in grouping,default 20
:param k2: second hyper parameter in grouping,default 20
:param drop: drop rate
"""
super().__init__()
self.num_cls = num_cls
self.drop = drop
self.pct = PCT(k1=k1, k2=k2, sam_num1=sam_num1, sam_num2=sam_num2, drop=self.drop, task='cls')
self.relu = nn.ReLU()
self.fc1 = nn.Linear(1024, 256)
self.bn1 = nn.BatchNorm1d(1)
self.dro1 = nn.Dropout(p=self.drop)
self.fc2 = nn.Linear(256, 256)
self.bn2 = nn.BatchNorm1d(1)
self.dro2 = nn.Dropout(p=self.drop)
self.fc3 = nn.Linear(256, self.num_cls)
def forward(self, x):
x = self.pct(x) # get global feature
x = self.dro1(self.relu(self.bn1(self.fc1(x)))) # second LBRD
x = self.dro2(self.relu(self.bn2(self.fc2(x)))) # third LBRD
x = self.fc3(x).view(-1, self.num_cls) # transform to classification vector
return x在这里,第一次以及第二次采样点数分别设置成512以及256,原有数据点数为10000。
3.3 PCT2Seg
class PCT2Seg(nn.Module):
def __init__(self, num_cls, k1=20, k2=20, drop=0.5):
"""
for segmentation
:param num_cls: num of part class
:param k1: first hyper parameter in grouping,default 20
:param k2: second hyper parameter in grouping,default 20
:param drop: drop rate
"""
super().__init__()
self.num_cls = num_cls
self.drop = drop
self.pct = PCT(k1=k1, k2=k2, sam_num1=10000, sam_num2=10000, drop=self.drop, task='seg')
self.relu = nn.ReLU()
self.fc1 = nn.Linear(2048, 256)
self.bm1 = nn.BatchNorm1d(10000)
self.dro1 = nn.Dropout(p=self.drop)
self.fc2 = nn.Linear(256, 256)
self.bm2 = nn.BatchNorm1d(10000)
self.fc3 = nn.Linear(256, self.num_cls)
def forward(self, x):
x = self.pct(x) # get global feature
x = self.dro1(self.relu(self.bm1(self.fc1(x)))) # first LBRD
x = self.relu(self.bm2(self.fc2(x))) # second LBR
x = self.fc3(x) # transform to the part classification vector per point
return x在这里,可以看到sam_num1以及sam_num2分别设置10000(前文所述)。
4. DataSet
下面是本人自己写的Datase类,适用于ShapeNet数据集(10000个点,6个特征)。
class ShapeNet(Dataset):
def __init__(self, root, num_cls, split='train'):
"""
:param root: root of dataset
:param num_cls: num of class
:param split: split to 'train' or 'test'
"""
self.split = split
self.root = root
self.num_cls = num_cls
self.dataset = []
files = os.listdir(root)
cls = 0
if not os.path.isdir(self.root):
raise ValueError("input root is not a dir")
for file in files: # read each class
spls = os.listdir(os.path.join(root, file))
for spl in spls: # distinguish
if spl == self.split:
files2 = os.listdir(os.path.join(root, file, spl))
for file2 in files2: # read each txt file
model = []
with open(os.path.join(root, file, spl, file2), "r") as f:
for line in f.readlines(): # each point
point = []
list = line.split(',')
for i in range(3):
point.append(float(list[i]))
model.append(point)
label = cls
self.dataset.append({'model': torch.tensor(model), 'label': label})
cls = cls + 1
def __len__(self):
return len(self.dataset)
def __getitem__(self, index) -> T_co:
if index < 0 or index >= len(self.dataset):
return None
return self.dataset[index]['model'], self.dataset[index]['label']5. Train
import torch
from torch.utils.tensorboard import SummaryWriter
from model.PCT import PCT2Cls
from torch.utils.data import DataLoader
from torch.nn import CrossEntropyLoss
from utils.dataset import ShapeNet
from torch.optim import SGD
root = 'D:/PointCloud/point_cloud_dataset/ShapeNet' # root of dataset
batch_size = 16 # mini batch size
epoch = 1 # times of training
lr = 1e-2 # learning rate
mom_tum = 9e-1 # momentum
num_cls = 40 # num of class
writer = SummaryWriter()
train_data = ShapeNet(root=root, num_cls=num_cls, split='train')
train_data_loader = DataLoader(train_data, batch_size=batch_size, shuffle=False)
test_data = ShapeNet(root=root, num_cls=num_cls, split='test')
test_data_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
model = PCT2Cls(num_cls=num_cls)
loss_func = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=lr, momentum=mom_tum)
# is GPU available?
GPU = torch.cuda.is_available()
print(f'my device is {"GPU" if GPU else "CPU"}')
model.train()
for i in range(epoch):
correct = 0
step = 0
print(f'epoch:{i + 1}')
for data in train_data_loader:
step += 1 # record the num of batches(sample size/batch_size)
optimizer.zero_grad() # gradient reset
input, target = data
if GPU: # if available, computing with GPU
input.cuda()
target.cuda()
output = model(input)
loss = loss_func(output, target)
loss.backward()
optimizer.step() # update parameters
correct += (output.argmax(1) == target).sum()
writer.add_scalar('acc', (correct / len(train_data)).item(), step)
print(f'\ttrain loss:{loss.item()}')
print(f'\ttrain acc {round((correct / len(train_data) * 100).item(), 3)}%')
print('\t--------------------')
model.eval()
print('test......')
with torch.no_grad(): # without computing gradient
acc = 0
step = 0
for data in test_data_loader:
step += 1 # record the num of batches(sample size/batch_size)
input, target = data
if GPU: # if available, computing with GPU
input.cuda()
target.cuda()
output = model(input)
loss = loss_func(output, target)
acc += (output.argmax(1) == target).sum()
print(f'\t{step}batch, test loss:{loss.item()}')
print(f'\t{step}batch, test acc {round((acc / len(test_data) * 100).item(), 3)}%')
print('\t--------------------')
指定好各种hyper parameter后可以开始训练......
实验结果正在跑......没有GPU实在难以跑起来。
上诉如有不对请在评论区指出,互相学习!