深度学习与自然语言处理教程(5) - 语言模型、RNN、GRU与LSTM(NLP通关指南·完结)

- 作者:韩信子@ShowMeAI
- 教程地址:http://www.showmeai.tech/tutorials/36
- 本文地址:http://www.showmeai.tech/article-detail/239
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

本系列为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》的全套学习笔记,对应的课程视频可以在 这里 查看。


ShowMeAI为CS224n课程的全部课件,做了中文翻译和注释,并制作成了 GIF动图!点击 第6讲-循环神经网络与语言模型 和 第7讲-梯度消失问题与RNN变种 查看的课件注释与带学解读。更多资料获取方式见文末。
引言
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程,核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
本篇笔记对应斯坦福CS224n自然语言处理专项课程的知识板块:**语言模型、循环神经网络RNN、变种RNN (LSTM、GRU等) **。首先介绍了语言模型及其应用场景,进而介绍循环神经网络RNN及优化后的变种LSTM和GRU模型。
内容要点
- 语言模型
- RNN
- 循环神经网络
- 双向RNN
- 深度RNN
- 长短时记忆网络
- LSTM
- GRU
1.语言模型
(语言模型部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章 深度学习教程 | 序列模型与RNN网络)
1.1 简介
语言模型计算特定序列中多个单词以一定顺序出现的概率。一个 m m m 个单词的序列 { w 1 , … , w m } \{w_{1}, \dots, w_{m}\} {w1,…,wm} 的概率定义为 P ( w 1 , … , w m ) P\left(w_{1}, \dots, w_{m}\right) P(w1,…,wm)。单词 w i w_i wi 前有一定数量的单词,其特性会根据它在文档中的位置而改变, P ( w 1 , … , w m ) P\left(w_{1}, \dots, w_{m}\right) P(w1,…,wm) 一般只考虑前 n n n 个单词而不是考虑全部之前的单词。
P ( w 1 , … , w m ) = ∏ i = 1 i = m P ( w i ∣ w 1 , … , w i − 1 ) ≈ ∏ i = 1 i = m P ( w m ∣ w i − n , … , w i − 1 ) P(w_{1}, \ldots, w_{m})=\prod_{i=1}^{i=m} P(w_{i} \mid w_{1}, \ldots, w_{i-1}) \approx \prod_{i=1}^{i=m} P(w_{m} \mid w_{i-n}, \ldots, w_{i-1}) P(w1,…,wm)=i=1∏i=mP(wi∣w1,…,wi−1)≈i=1∏i=mP(wm∣wi−n,…,wi−1)
上面的公式在语音识别和机器翻译系统中有重要的作用,它可以辅助筛选语音识别和机器翻译的最佳结果序列。
在现有的机器翻译系统中,对每个短语/句子翻译,系统生成一些候选的词序列 (例如, { I h a v e , I h a s , I h a d , m e h a v e , m e h a d } \{ I have,I has,I had,me have,me had \} {Ihave,Ihas,Ihad,mehave,mehad}) ,并对其评分以确定最可能的翻译序列。
在机器翻译中,对一个输入短语,通过评判每个候选输出词序列的得分的高低,来选出最好的词顺序。为此,模型可以在不同的单词排序或单词选择之间进行选择。它将通过一个概率函数运行所有单词序列候选项,并为每个候选项分配一个分数,从而实现这一目标。最高得分的序列就是翻译结果。例如:
- 相比
small is the cat,翻译系统会给the cat is small更高的得分; - 相比
walking house after school,翻译系统会给walking home after school更高的得分。
1.2 n-gram语言模型
为了计算这些概率,每个 n-gram 的计数将与每个单词的频率进行比较,这个称为 n-gram 语言模型。
- 例如,如果选择 bi-gram模型 (二元语言模型) ,每一个 bi-gram 的频率,通过将单词与其前一个单词相结合进行计算,然后除以对应的 uni-gram 的频率。
- 下面的两个公式展示了 bi-gram 模型和 tri-gram 模型的区别。
p ( w 2 ∣ w 1 ) = c o u n t ( w 1 , w 2 ) c o u n t ( w 1 ) p(w_{2} \mid w_{1}) =\frac{count (w_{1}, w_{2})}{count(w_{1})} p(w2∣w1)=count(w1)count(w1,w2)
p ( w 3 ∣ w 1 , w 2 ) = c o u n t ( w 1 , w 2 , w 3 ) c o u n t ( w 1 , w 2 ) p(w_{3} \mid w_{1}, w_{2}) =\frac{count (w_{1}, w_{2}, w_{3})}{count (w_{1}, w_{2})} p(w3∣w1,w2)=count(w1,w2)count(w1,w2,w3)
上式 tri-gram 模型的关系主要是基于一个固定的上下文窗口 (即前 n n n个单词) 预测下一个单词。一般 n n n的取值为多大才好呢?
- 在某些情况下,前面的连续的 n n n 个单词的窗口可能不足以捕获足够的上下文信息。
- 例如,考虑句子 (类似完形填空,预测下一个最可能的单词)
Asthe proctor started the clock, the students opened their __。如果窗口只是基于前面的三个单词the students opened their,那么基于这些语料计算的下划线中最有可能出现的单词就是为books——但是如果 n n n 足够大,能包括全部的上下文,那么下划线中最有可能出现的单词会是exam。
这就引出了 n-gram 语言模型的两个主要问题:「稀疏性」和「存储」。
1) n-gram语言模型的稀疏性问题
n-gram 语言模型的问题源于两个问题。
① 对应公式中的分子,可能有稀疏性问题。
- 如果 w 1 w_1 w1, w 2 w_2 w2, w 3 w_3 w3 在语料中从未出现过,那么 w 3 w_3 w3 的概率就是 0 0 0。
- 为了解决这个问题,在每个单词计数后面加上一个很小的 δ \delta δ,这就是平滑操作。
② 对应公式中的分母,可能有稀疏性问题。
- 如果 w 1 w_1 w1, w 2 w_2 w2 在语料中从未出现过,那么 w 3 w_3 w3 的概率将会无法计算。
- 为了解决这个问题,这里可以只是单独考虑 w 2 w_2 w2,这就是
backoff操作。
增加 n n n 会让稀疏问题更加严重,所以一般 n ≤ 5 n \leq 5 n≤5。
2) n-gram语言模型的存储问题
我们知道需要存储在语料库中看到的所有 n-gram 的统计数。随着 n n n的增加(或语料库大小的增加),模型的大小也会增加。
1.3 基于文本滑窗的预估型语言模型 (NNLM)
Bengio 的论文《A Neural Probabilistic Language Model》中首次解决了上面所说的“维度灾难”,这篇论文提出一个自然语言处理的大规模的深度学习模型,这个模型能够通过学习单词的分布式表示,以及用这些表示来表示单词的概率函数。
下图展示了NNLM对应的神经网络结构,在这个模型中,输入向量在隐藏层和输出层中都被使用。

下面公式展示了由标准 tanh 函数 (即隐藏层) 组成的 softmax 函数的参数以及线性函数 W ( 3 ) x + b ( 3 ) W^{(3)} x+b^{(3)} W(3)x+b(3),捕获所有前面 n n n 个输入词向量。
y ^ = softmax ( W ( 2 ) tanh ( W ( 1 ) x + b ( 1 ) ) + W ( 3 ) x + b ( 3 ) ) \hat{y}=\operatorname{softmax}\left(W^{(2)} \tanh \left(W^{(1)}x+b^{(1)}\right)+W^{(3)} x+b^{(3)}\right) y^=softmax(W(2)tanh(W(1)x+b(1))+W(3)x+b(3))
注意权重矩阵 W ( 1 ) W^{(1)} W(1)是应用在词向量上 (上图中的绿色实线箭头) , W ( 2 ) W^{(2)} W(2)是应用在隐藏层 (也是绿色实线箭头) 和 W ( 3 ) W^{(3)} W(3)是应用在词向量 (绿色虚线箭头) 。
这个模型的简化版本如下图所示:

- 蓝色的层表示输入单词的 embedding 拼接: e = [ e ( 1 ) ; e ( 2 ) ; e ( 3 ) ; e ( 4 ) ] e=\left[e^{(1)} ; e^{(2)} ; e^{(3)} ; e^{(4)}\right] e=[e(1);e(2);e(3);e(4)]
- 红色的层表示隐藏层: h = f ( W e + b 1 ) \boldsymbol{h}=f\left(\boldsymbol{W} e+\boldsymbol{b}_{1}\right) h=f(We+b1)
- 绿色的输出分布是对词表的一个 softmax 概率分布: y ^ = softmax ( U h + b 2 ) \hat{y}=\operatorname{softmax}\left(\boldsymbol{U} \boldsymbol{h}+\boldsymbol{b}_{2}\right) y^=softmax(Uh+b2)
2.循环神经网络 (RNN)
(循环神经网络部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 序列模型与RNN网络)
传统的统计翻译模型,只能以有限窗口大小的前 n n n 个单词作为条件进行语言模型建模,循环神经网络与其不同,RNN 有能力以语料库中所有前面的单词为条件进行语言模型建模。
下图展示的 RNN 的架构,其中矩形框是在一个时间步的一个隐藏层 t t t。

每个这样的隐藏层都有若干个神经元,每个神经元对输入向量用一个线性矩阵运算然后通过非线性变化 (例如 tanh 函数) 得到输出。
-
在每一个时间步,隐藏层都有两个输入
- 前一个时间步的隐藏层 h t − 1 h_{t-1} ht−1
- 当前时间步的输入 x t x_t xt
-
前一个时间步的隐藏层 h t − 1 h_{t-1} ht−1 通过和权重矩阵 W ( h h ) W^{(hh)} W(hh) 相乘和当前时间步的输入 x t x_t xt 和权重矩阵 W ( h x ) W^{(hx)} W(hx) 相乘得到当前时间步的隐藏层 h t h_t ht
-
h t h_t ht 和权重矩阵 W ( S ) W^{(S)} W(S) 相乘,接着对整个词表通过 softmax 计算得到下一个单词的预测结果 y ^ \hat y y^,如下面公式所示:
h t = σ ( W ( h h ) h t − 1 + W ( h x ) x [ t ] ) h_{t} =\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{[t]}\right) ht=σ(W(hh)ht−1+W(hx)x[t])
y ^ = softmax ( W ( S ) h t ) \hat{y} =\operatorname{softmax}\left(W^{(S)} h_{t}\right) y^=softmax(W(S)ht)
每个神经元的输入和输出如下图所示:
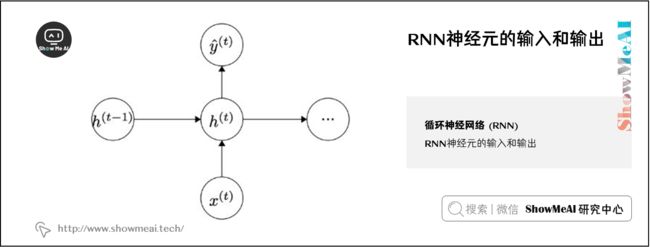
在这里一个有意思的地方是在每一个时间步使用相同的权重 W ( h h ) W^{(hh)} W(hh)和 W ( h x ) W^{(hx)} W(hx)。这样模型需要学习的参数就变少了,这与输入序列的长度无关——这从而解决了维度灾难。
以下是网络中每个参数相关的详细信息:
-
x 1 , … , x t − 1 , x t , x t + 1 , … x T x_{1}, \dots, x_{t-1}, x_{t}, x_{t+1}, \dots x_{T} x1,…,xt−1,xt,xt+1,…xT:含有 T T T 个单词的语料库对应的词向量
-
h t = σ ( W ( h h ) h t − 1 + W ( h x ) x t ) h_{t}=\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{t}\right) ht=σ(W(hh)ht−1+W(hx)xt):每个时间步 t t t 的隐藏层的输出特征的计算关系
-
x t ∈ R d x_{t} \in \mathbb{R}^{d} xt∈Rd:在时间步 t t t 的输入词向量
-
W h x ∈ R D h × d W^{h x} \in \mathbb{R}^{D_{h} \times d} Whx∈RDh×d:输入词向量 x t x_t xt 对应的权重矩阵
-
W h h ∈ R D h × D h W^{h h} \in \mathbb{R}^{D_{h} \times D_{h}} Whh∈RDh×Dh:上一个时间步的输出 h t − 1 h_{t-1} ht−1 对应的权重矩阵
-
h t − 1 ∈ R D h h_{t-1} \in \mathbb{R}^{D_{h}} ht−1∈RDh:上一个时间步 t − 1 t-1 t−1 的非线性函数输出。 h 0 ∈ R D h h_{0} \in \mathbb{R}^{D_{h}} h0∈RDh 是在时间步 t = 0 t=0 t=0 的隐藏层的一个初始化向量
-
σ \sigma σ:非线性函数 (这里是 sigmoid 函数)
-
y ^ = softmax ( W ( S ) h t ) \hat{y}=\operatorname{softmax}\left(W^{(S)} h_{t}\right) y^=softmax(W(S)ht):在每个时间步 t t t 全部单词的概率分布输出。本质上 y ^ \hat y y^ 是给定文档上下文分数 (例如 h t − 1 h_{t-1} ht−1) 和最后观测的词向量 x t x_t xt,对一个出现单词的预测。这里 W ( S ) ∈ R ∣ V ∣ × D h W^{(S)} \in \mathbb{R}^{|V| \times D_{h}} W(S)∈R∣V∣×Dh, y ^ ∈ R ∣ V ∣ \hat{y} \in \mathbb{R}^{\left | V \right |} y^∈R∣V∣,其中 ∣ V ∣ \left | V \right | ∣V∣ 是词汇表的大小。
一个 RNN 语言模型的例子如下图所示。

图中的符号有一些的不同:
- W h W_h Wh 等同于 W ( h h ) W^{(hh)} W(hh)
- W e W_e We 等同于 W ( h x ) W^{(hx)} W(hx)
- U U U 等同于 W ( S ) W^{(S)} W(S)
- E E E 表示单词输入 x ( t ) x^{(t)} x(t) 转化为 e ( t ) e^{(t)} e(t)
在 RNN 中常用的损失函数是在之前介绍过的交叉熵误差。下面的公式是这个函数在时间步 t t t 全部单词的求和。最后计算词表中的 softmax 计算结果展示了基于前面所有的单词对输出单词 x ( 5 ) x^{(5)} x(5) 的不同选择的概率分布。这时的输入可以比4到5个单词更长。
2.1 RNN损失与困惑度
RNN 的损失函数一般是交叉熵误差。
J ( t ) ( θ ) = ∑ j = 1 ∣ V ∣ y t , j × log ( y ^ t , j ) J^{(t)}(\theta)=\sum_{j=1}^{\left | V \right |} y_{t, j} \times \log \left(\hat{y}_{t, j}\right) J(t)(θ)=j=1∑∣V∣yt,j×log(y^t,j)
在大小为 T T T的语料库上的交叉熵误差的计算如下:
J = − 1 T ∑ t = 1 T J ( t ) ( θ ) = − 1 T ∑ t = 1 T ∑ j = 1 ∣ V ∣ y t , j × log ( y ^ t , j ) J=-\frac{1}{T} \sum_{t=1}^{T} J^{(t)}(\theta)=-\frac{1}{T} \sum_{t=1}^{T} \sum_{j=1}^{\left | V \right |} y_{t, j} \times \log \left(\hat{y}_{t, j}\right) J=−T1t=1∑TJ(t)(θ)=−T1t=1∑Tj=1∑∣V∣yt,j×log(y^t,j)
2.2 RNN的优缺点及应用
RNN 有以下优点:
- 它可以处理任意长度的序列
- 对更长的输入序列不会增加模型的参数大小
- 对时间步 t t t 的计算理论上可以利用前面很多时间步的信息
- 对输入的每个时间步都应用相同的权重,因此在处理输入时具有对称性
但是 RNN 也有以下不足:
- 计算速度很慢——因为它每一个时间步需要依赖上一个时间步,所以不能并行化
- 在实际中因为梯度消失和梯度爆炸,很难利用到前面时间步的信息
运行一层 RNN 所需的内存量与语料库中的单词数成正比。
例如,我们把一个句子是为一个 mini batch,那么一个有 k k k 个单词的句子在内存中就会占用 k k k 个词向量的存储空间。同时,RNN必须维持两对 W W W 和 b b b 矩阵。然而 W W W 的可能是非常大的,它的大小不会随着语料库的大小而变化 (与传统的语言模型不一样) 。对于具有 1000 1000 1000个循环层的RNN,矩阵 W W W的大小为 1000 × 1000 1000 \times 1000 1000×1000而与语料库大小无关。
RNN可以应用在很多任务,例如:
- 标注任务 (词性标注、命名实体识别)
- 句子分类 (情感分类)
- 编码模块 (问答任务,机器翻译和其他很多任务)
在后面的两个任务,我们希望得到对句子的表示,这时可以通过采用该句子中时间步长的所有隐藏状态的 e l e m e n t − w i s e element-wise element−wise的最大值或平均值来获得。
下图是一些资料中对 RNN 模型的另外一种表示。它将 RNN 的每个隐层用一个环来表示。

2.3 梯度消失与梯度爆炸问题
(梯度消失和梯度爆炸部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 深度学习的实用层面)
RNN 从一个时间步传播权值矩阵到下一个时间步。回想一下,RNN 实现的目标是通过长距离的时间步来传播上下文信息。例如,考虑以下两个句子:
场景1
Jane walked into the room. John walked in too. Jane said hi to __
场景2
Jane walked into the room. John walked in too. It was late in the day, and everyone was walking home after a long day at work. Jane said hi to __
对上面的两个句子,根据上下文,都可以知道空白处的答案是John,第二个在两个句子的上下文中均提及了好几次的人。
迄今为止我们对 RNN 的了解,在理想情况下,RNN 也是能够计算得到正确的答案。然而,在实际中,RNN 预测句子中的空白处答案正确可能性,第一句要比第二句高。这是因为在反向传播的阶段的过程中,从前面时间步中回传过来的梯度值会逐渐消失。因此,对于长句子,预测到 John 是空白处的答案的概率会随着上下文信息增大而减少。
下面,我们讨论梯度消失问题背后的数学原因。
考虑公式在时间步 t t t,计算RNN误差 d E d W \frac{dE}{dW} dWdE,然后我们把每个时间步的误差都加起来。也就是说,计算并累积每个时间步长 t t t 的 d E t d W \frac{dE_t}{dW} dWdEt。
∂ E ∂ W = ∑ i = 1 T ∂ E t ∂ W \frac{\partial E}{\partial W}=\sum_{i=1}^{T} \frac{\partial E_{t}}{\partial W} ∂W∂E=i=1∑T∂W∂Et
通过将微分链式法则应用于以下公式来计算每个时间步长的误差
h t = σ ( W ( h h ) h t − 1 + W ( h x ) x [ t ] ) y ^ = softmax ( W ( S ) h t ) \begin{aligned} h_{t} &=\sigma\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{[t]}\right) \\ \hat{y} &=\operatorname{softmax}\left(W^{(S)} h_{t}\right) \end{aligned} hty^=σ(W(hh)ht−1+W(hx)x[t])=softmax(W(S)ht)
下列公式展示对应的微分计算。注意 d h t d h k \frac{d h_{t}}{d h_{k}} dhkdht 是 h t h_t ht 对之前所有的 k k k 个时间步的偏导数。
∂ E t ∂ W = ∑ k = 1 T ∂ E t ∂ y t ∂ y t ∂ h t ∂ h t ∂ h k ∂ h k ∂ W \frac{\partial E_{t}}{\partial W}=\sum_{k=1}^{T} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}} \frac{\partial h_{t}}{\partial h_{k}} \frac{\partial h_{k}}{\partial W} ∂W∂Et=k=1∑T∂yt∂Et∂ht∂yt∂hk∂ht∂W∂hk
下式展示了计算每个 d h t d h k \frac{d h_{t}}{d h_{k}} dhkdht 的关系;这是在时间间隔 [ k , t ] [k,t] [k,t] 内对所有的隐藏层的应用一个简单的微分链式法则。
∂ h t ∂ h k = ∏ j = k + 1 t ∂ h j ∂ h j − 1 = ∏ j = k + 1 t W T × diag [ f ′ ( j j − 1 ) ] \frac{\partial h_{t}}{\partial h_{k}}=\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}=\prod_{j=k+1}^{t} W^{T} \times \operatorname{diag}\left[f^{\prime}\left(j_{j-1}\right)\right] ∂hk∂ht=j=k+1∏t∂hj−1∂hj=j=k+1∏tWT×diag[f′(jj−1)]
因为 h ∈ R D n h \in \mathbb{R}^{D_{n}} h∈RDn,每个 ∂ h j ∂ h j − 1 \frac{\partial h_{j}}{\partial h_{j-1}} ∂hj−1∂hj 是 h h h 的Jacobian矩阵的元素:
∂ h j ∂ h j − 1 = [ ∂ h j ∂ h j − 1 , 1 ⋯ ∂ h j ∂ h j − 1 , D n ] = [ ∂ h j , 1 ∂ h j − 1 , 1 ⋯ ∂ h j , 1 ∂ h j − 1 , D n ⋮ ⋱ ⋮ ∂ h j , D n ∂ h j − 1 , 1 ⋯ ∂ h j , D n ∂ h j − 1 , D n ] \begin{aligned} \frac{\partial h_{j}}{\partial h_{j-1}}&=\left[\frac{\partial h_{j}}{\partial h_{j-1,1}} \cdots \frac{\partial h_{j}}{\partial h_{j-1, D_{n}}}\right] \\ &=\begin{bmatrix} {\frac{\partial h_{j, 1}}{\partial h_{j-1,1}}} & \cdots & {\frac{\partial h_{j,1}}{\partial h_{j-1, D_{n}}}} \\ \vdots & \ddots & \vdots \\ {\frac{\partial h_{j, D_{n}}}{\partial h_{j - 1,1}}} & \cdots & {\frac{\partial h_{j, D_{n}}}{\partial h_{j-1, D_{n}}}} \end{bmatrix} \end{aligned} ∂hj−1∂hj=[∂hj−1,1∂hj⋯∂hj−1,Dn∂hj]=⎣⎢⎢⎡∂hj−1,1∂hj,1⋮∂hj−1,1∂hj,Dn⋯⋱⋯∂hj−1,Dn∂hj,1⋮∂hj−1,Dn∂hj,Dn⎦⎥⎥⎤
将公式合起来,我们有以下关系。
∂ E ∂ W = ∑ t = 1 T ∑ k = 1 t ∂ E t ∂ y t ∂ y t ∂ h t ( ∏ j = k + 1 t ∂ h j ∂ h j − 1 ) ∂ h k ∂ W \frac{\partial E}{\partial W}=\sum_{t=1}^{T} \sum_{k=1}^{t} \frac{\partial E_{t}}{\partial y_{t}} \frac{\partial y_{t}}{\partial h_{t}}\left(\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}\right) \frac{\partial h_{k}}{\partial W} ∂W∂E=t=1∑Tk=1∑t∂yt∂Et∂ht∂yt⎝⎛j=k+1∏t∂hj−1∂hj⎠⎞∂W∂hk
下式展示了Jacobian矩阵的范数。这里的 β W \beta_{W} βW 和 β h \beta_{h} βh 是这两个矩阵范数的上界值。因此通过公式所示的关系计算在每个时间步 t t t 的部分梯度范数。
∥ ∂ h j ∂ h j − 1 ∥ ≤ ∥ W T ∥ ∥ diag [ f ′ ( h j − 1 ) ] ∥ ≤ β W β h \left\|\frac{\partial h_{j}}{\partial h_{j-1}}\right\| \leq \left\| W^{T} \right\| \quad \left\| \operatorname{diag} \left [f^{\prime}\left(h_{j-1}\right)\right]\right\| \leq \beta_{W} \beta_{h} ∥∥∥∥∂hj−1∂hj∥∥∥∥≤∥∥WT∥∥∥diag[f′(hj−1)]∥≤βWβh
计算这两个矩阵的L2范数。在给定的非线性函数sigmoid下, f ′ ( h j − 1 ) f^{\prime}\left(h_{j-1}\right) f′(hj−1) 的范数只能等于1。
∥ ∂ h t ∂ h k ∥ = ∥ ∏ j = k + 1 t ∂ h j ∂ h j − 1 ∥ ≤ ( β W β h ) t − k \left\|\frac{\partial h_{t}}{\partial h_{k}}\right\|=\left\|\prod_{j=k+1}^{t} \frac{\partial h_{j}}{\partial h_{j-1}}\right\| \leq (\beta_{W} \beta_{h})^{t-k} ∥∥∥∥∂hk∂ht∥∥∥∥=∥∥∥∥∥∥j=k+1∏t∂hj−1∂hj∥∥∥∥∥∥≤(βWβh)t−k
当 t − k t - k t−k 足够大和 β W β h \beta_{W} \beta_{h} βWβh 远远小于1或者远远大于1,指数项 ( β W β h ) t − k \left(\beta_{W} \beta_{h}\right)^{t-k} (βWβh)t−k 的值就很容易变得非常小或者非常大。
由于单词之间的距离过大,用一个很大的 t − k t-k t−k 评估交叉熵误差可能会出现问题。在反向传播的早期就出现梯度消失,那么远处单词对在时间步长 t t t预测下一个单词中,所起到的作用就会变得很小。
在实验的过程中:
- 一旦梯度的值变得非常大,会导致在运行过程中容易检测到其引起的溢出 (即NaN) ;这样的问题称为「梯度爆炸」问题。
- 当梯度接近为0的时候,梯度近乎不再存在,同时降低模型对语料库中的远距离的单词的学习质量;这样的问题称为「梯度消失」问题。
- 如果相对梯度消失问题的有更直观的了解,你可以访问这个 样例网站。
2.4 梯度消失与爆炸解决方法
现在我们知道了梯度消失问题的本质以及它在深度神经网络中如何表现出来,让我们使用一些简单实用的启发式方法来解决这些问题。
2.4.1 梯度爆炸解决方法
为了解决梯度爆炸的问题,Thomas Mikolov 等人首先提出了一个简单的启发式解决方案,每当梯度大于一个阈值的时候,将其截断为一个很小的值,具体如下面算法中的伪代码所示。
g ^ ← ∂ E ∂ W if ∥ g ^ ∥ ≥ threshold then g ^ ← threshold ∥ g ^ ∥ g ^ end if \begin{array}{l} \hat{g} \leftarrow \frac{\partial E}{\partial W} \\ \text { if }\|\hat{g}\| \geq \text { threshold then } \\ \qquad \hat{g} \leftarrow \frac{\text { threshold }}{\|\hat{g}\|} \hat{g} \\ \text { end if } \end{array} g^←∂W∂E if ∥g^∥≥ threshold then g^←∥g^∥ threshold g^ end if
❐ Algorithm : Pseudo-code for norm clipping in the gradients whenever they explode【范数梯度裁剪的伪代码】
下图可视化了梯度截断的效果。它展示了一个权值矩阵为 W W W 和偏置项为 b b b 的很小的RNN神经网络的决策界面。该模型由一个单一单元的循环神经网络组成,在少量的时间步长上运行;实心箭头阐述了在每个梯度下降步骤的训练过程。

当在梯度下降的过程中,模型碰到目标函数中的高误差壁时,梯度被推到决策面上的一个遥远的位置。截断模型生成了虚线,在那里它将误差梯度拉回到靠近原始梯度的地方。
2.4.2 梯度消失解决方法
为了解决梯度消失问题,研究人员提出两个技术:
- 第一个技术是不去随机初始化 W ( h h ) W^{(hh)} W(hh),而是初始化为单位矩阵。
- 第二个技术是使用Rectified Linear (ReLU) 单元代替 sigmoid 函数。ReLU 的导数是 0 0 0 或者 1 1 1。这样梯度传回神经元的导数是 1 1 1,而不会在反向传播了一定的时间步后梯度变小。
2.5 深度双向循环神经网络
前面部分我们讲解了用 RNN 如何使用过去的词来预测序列中的下一个单词。同理,可以通过令 RNN 模型向反向读取语料库,根据未来单词进行预测。
Irsoy 等人展示了一个双向深度神经网络;在每个时间步 t t t,这个网络维持两个隐藏层,一个是从左到右传播,而另外一个是从右到左传播。
为了在任何时候维持两个隐藏层,该网络要消耗的两倍存储空间来存储权值和偏置参数。最后的分类结果 y ^ \hat y y^,是结合由两个 RNN 隐藏层生成的结果得分产生。
下图展示了双向 RNN 的网络结构。

而下式展示了给出了建立双向RNN隐层的数学公式。两个公式之间唯一的区别是递归读取语料库的方向不同。最后一行展示了通过总结过去和将来的单词表示,显示用于预测下一个单词的分类关系:
h → t = f ( W → x t + V → h → t − 1 + b → ) \overrightarrow{h}_{t}=f(\overrightarrow{W} x_{t}+\overrightarrow{V} \overrightarrow{h}_{t-1}+\overrightarrow{b}) ht=f(Wxt+Vht−1+b)
h ← t = f ( W ← x t + V ← h ← t − 1 + b ← ) \overleftarrow{h}_{t}=f(\overleftarrow{W} x_{t}+\overleftarrow{V} \overleftarrow{h}_{t-1}+\overleftarrow{b}) ht=f(Wxt+Vht−1+b)
y ^ t = g ( U h t + c ) = g ( U [ h → t ; h ← t ] + c ) \hat{y}_{t}=g (U h_{t}+c)=g(U \left[\overrightarrow{h}_{t} ; \overleftarrow{h}_{t}\right]+c) y^t=g(Uht+c)=g(U[ht;ht]+c)
RNN也可以是多层的。下图展示一个多层的双向 RNN,其中下面的隐藏层传播到下一层。
如图所示,在该网络架构中,在时间步 t t t,每个中间神经元从前一个时间步 (在相同的 RNN 层) 接收一组参数和前一个 RNN 隐藏层的两组参数;这两组参数一组是从左到右的 RNN 输入,另外一组是从右到左的 RNN 输入。
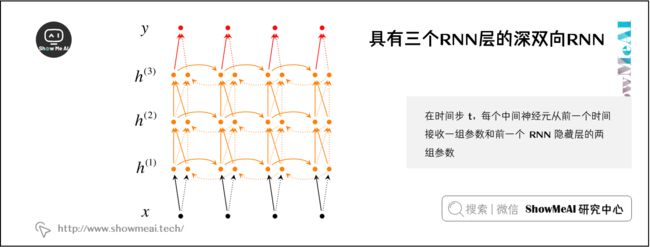
为了构建一个 L 层的深度 RNN,上述的关系要修改为在公式中的关系,其中在第 i i i 层的每个中间神经元的输入是在相同时间步 t t t 的RNN第 i − 1 i-1 i−1 层的输出。最后的输出 y ^ \hat y y^,每个时间步都是输入参数通过所有隐层传播的结果。
h → t ( i ) = f ( W → ( i ) h t ( i − 1 ) + V → ( i ) h → t − 1 ( i ) + b → ( i ) ) \overrightarrow{h}_{t}^{(i)}=f\left(\overrightarrow{W}^{(i)} h_{t}^{(i-1)}+\overrightarrow{V}^{(i)} \overrightarrow{h}_{t-1}^{(i)}+\overrightarrow{b}^{(i)}\right) ht(i)=f(W(i)ht(i−1)+V(i)ht−1(i)+b(i))
h ← t ( i ) = f ( W ← ( i ) h t ( i − 1 ) + V ← ( i ) h ← t + 1 ( i ) + b → ( i ) ) \overleftarrow{h}_{t}^{(i)}=f\left(\overleftarrow{W}^{(i)} h_{t}^{(i-1)}+\overleftarrow{V}^{(i)} \overleftarrow{h}_{t+1}^{(i)}+\overrightarrow{b}^{(i)}\right) ht(i)=f(W(i)ht(i−1)+V(i)ht+1(i)+b(i))
y ^ t = g ( U h t + c ) = g ( U [ h → t ( L ) ; h ← t ( L ) ] + c ) \hat{y}_{t}=g\left(U h_{t}+c\right)=g\left(U\left[\overrightarrow{h}_{t}^{(L)} ; \overleftarrow{h}_{t}^{(L)}\right]+c\right) y^t=g(Uht+c)=g(U[ht(L);ht(L)]+c)
2.6 应用:基于RNN的翻译系统
(神经机器翻译部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | Seq2Seq序列模型和注意力机制)
传统的翻译模型是非常复杂的:它们包含很多应用在语言翻译流程的不同阶段的机器学习算法。这里讲解采用 RNN 作为传统翻译模型的替代方法。
考虑下图中展示的 RNN 模型:其中德语短语 Echt dicke Kiste 翻译为 Awesome sauce。

首先,前三个时间步的隐藏层编码德语单词为一些语言的单词特征 ( h 3 h_3 h3) 。后面两个时间步解码 h 3 h_3 h3 为英语单词输出。下式分别展示了编码阶段和解码阶段(后两行)。
h t = ϕ ( h t − 1 , x t ) = f ( W ( h h ) h t − 1 + W ( h x ) x t ) {h_{t}=\phi\left(h_{t-1}, x_{t}\right)=f\left(W^{(h h)} h_{t-1}+W^{(h x)} x_{t}\right)} ht=ϕ(ht−1,xt)=f(W(hh)ht−1+W(hx)xt)
h t = ϕ ( h t − 1 ) = f ( W ( h h ) h t − 1 ) {h_{t}=\phi\left(h_{t-1}\right)=f\left(W^{(h h)} h_{t-1}\right)} ht=ϕ(ht−1)=f(W(hh)ht−1)
y t = softmax ( W ( s ) h t ) {y_{t}=\operatorname{softmax}\left(W^{(s)} h_{t}\right)} yt=softmax(W(s)ht)
一般可以认为使用交叉熵函数的RNN模型可以生成高精度的翻译结果。在实际中,在模型中增加一些扩展方法可以提升翻译的准确度表现。
max θ 1 N ∑ n = 1 N log p θ ( y ( n ) ∣ x ( n ) ) \max _{\theta} \frac{1}{N} \sum_{n=1}^{N} \log p_{\theta}\left(y^{(n)} \mid x^{(n)}\right) θmaxN1n=1∑Nlogpθ(y(n)∣x(n))
扩展 1:在训练 RNN 的编码和解码阶段时,使用不同的权值。这使两个单元解耦,让两个 RNN 模块中的每一个进行更精确的预测。这意味着在公式中 ϕ ( ) \phi( ) ϕ() 函数里使用的是不同的 W ( h h ) W^{(hh)} W(hh) 矩阵。
扩展 2:使用三个不同的输入计算解码器中的每个隐藏状态

- 前一个隐藏状态 h t − 1 h_{t-1} ht−1 (标准的)
- 编码阶段的最后一个隐藏层 (上图中的 c = h T c=h_T c=hT)
- 前一个预测的输出单词 y ^ t − 1 \hat y_{t-1} y^t−1
将上述的三个输入结合将之前公式的解码函数中的 ϕ \phi ϕ 函数转换为下式的 ϕ \phi ϕ 函数。上图展示了这个模型。
h t = ϕ ( h t − 1 , c , y t − 1 ) h_{t}=\phi\left(h_{t-1}, c, y_{t-1}\right) ht=ϕ(ht−1,c,yt−1)
扩展 3:使用多个 RNN 层来训练深度循环神经网络。神经网络的层越深,模型的就具有更强的学习能力从而能提升预测的准确度。当然,这也意味着需要使用大规模的语料库来训练这个模型。
扩展 4:训练双向编码器,提高准确度。
扩展 5:给定一个德语词序列 A B C A B C ABC,它的英语翻译是 X Y X Y XY。在训练 R N N RNN RNN时不使用 A B C → X Y A B C \to X Y ABC→XY,而是使用 C B A → X Y C B A \to X Y CBA→XY。这么处理的原因是 A A A更有可能被翻译成 X X X。因此对前面讨论的梯度消失问题,反转输入句子的顺序有助于降低输出短语的错误率。
3.Gated Recurrent Units (GRU模型)
(GRU模型的讲解也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 序列模型与RNN网络)
除了迄今为止讨论的扩展方法之外,我们已经了解到 RNN 通过使用更复杂的激活单元来获得表现更好。到目前为止,我们已经讨论了从隐藏状态 h t − 1 h_{t-1} ht−1向 h t h_t ht转换的方法,使用了一个仿射转换和 p o i n t − w i s e point-wise point−wise的非线性转换。
研究者通过调整门激活函数的结构完成对 RNN 结构的修改。
虽然理论上 RNN 能捕获长距离信息,但实际上很难训练网络做到这一点。门控制单元可以让 RNN 具有更多的持久性内存,从而更容易捕获长距离信息。让我们从数学角度上讨论 GRU 如何使用 h t − 1 h_{t-1} ht−1 和 x t x_t xt 来生成下一个隐藏状态 h t h_t ht。然后我们将深入了解 GRU 架构。
Update gate: z t = σ ( W ( z ) x t + U ( z ) h t − 1 ) z_{t} =\sigma \left(W^{(z)} x_{t}+U^{(z)} h_{t-1}\right) zt=σ(W(z)xt+U(z)ht−1)
Reset gate: r t = σ ( W ( r ) x t + U ( r ) h t − 1 ) r_{t} =\sigma\left(W^{(r)} x_{t}+U^{(r)} h_{t-1}\right) rt=σ(W(r)xt+U(r)ht−1)
New memory: h ~ t = tanh ( r t ∘ U h t − 1 + W x t ) \tilde{h}_{t} = \tanh \left(r_{t} \circ U h_{t-1}+W x_{t}\right) h~t=tanh(rt∘Uht−1+Wxt)
Hidden state: h t = ( 1 − z t ) ∘ h ~ t + z t ∘ h t − 1 h_{t} = \left(1-z_{t}\right) \circ \tilde{h}_{t}+z_{t} \circ h_{t-1} ht=(1−zt)∘h~t+zt∘ht−1
上述的共识可以认为是 GRU 的四个基本操作阶段,下面对这些公式作出更直观的解释,下图展示了 GRU 的基本结构和计算流程:

-
① 新记忆生成:一个新的记忆 h ~ t \tilde{h}_{t} h~t 是由一个新的输入单词 x t x_t xt 和过去的隐藏状态 h t − 1 h_{t-1} ht−1 共同计算所得。这个阶段是将新输入的单词与过去的隐藏状态 h t − 1 h_{t-1} ht−1 相结合,根据过去的上下文来总结得到向量 h ~ t \tilde{h}_{t} h~t。
-
② 重置门:复位信号 r t r_t rt 是负责确定 h t − 1 h_{t-1} ht−1 对总结 h ~ t \tilde{h}_{t} h~t 的重要程度。如果确定 h ~ t \tilde{h}_{t} h~t 与新的记忆的计算无关,则复位门能够完全消除过去的隐藏状态 (即忽略之前隐藏的信息) 。
-
③ 更新门:更新信号 z t z_t zt 负责确定有多少 h t − 1 h_{t-1} ht−1 可以向前传递到下一个状态。例如,如果 z t ≈ 1 z_{t} \approx 1 zt≈1,然后 h t − 1 h_{t-1} ht−1 几乎是完全向前传递到下一个隐藏状态。反过来,如果 z t ≈ 0 z_{t} \approx 0 zt≈0,然后大部分的新的记忆 h ~ t \tilde{h}_{t} h~t 向前传递到下一个隐藏状态。
-
④ 隐状态:利用更新门的建议,使用过去的隐藏输入 h t − 1 {h}_{t-1} ht−1 和新生成的记忆 h ~ t \tilde{h}_{t} h~t 生成隐藏状态 h t {h}_{t} ht。
需要注意的是,为了训练GRU,我们需要学习所有不同的参数: W , U , W ( r ) , U ( r ) , W ( z ) , U ( z ) W, U, W^{(r)}, U^{(r)}, W^{(z)}, U^{(z)} W,U,W(r),U(r),W(z),U(z)。这些参数同样是通过反向传播算法学习所得。
4.长短时记忆网络 (LSTM)
(LSTM模型的讲解也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 序列模型与RNN网络)
Long-Short-Term-Memories 是和 GRU 有一点不同的另外一种类型的复杂激活神经元。它的作用与 GRU 类似,但是神经元的结构有一点区别。我们首先来看看 LSTM 神经元的数学公式,然后再深入了解这个神经元的设计架构:
输入门/Input gate: i t = σ ( W ( i ) x t + U ( i ) h t − 1 ) i_{t}=\sigma\left(W^{(i)} x_{t}+U^{(i)} h_{t-1}\right) it=σ(W(i)xt+U(i)ht−1)
遗忘门/Forget gate: f t = σ ( W ( f ) x t + U ( f ) h t − 1 ) f_{t}=\sigma\left(W^{(f)} x_{t}+U^{(f)} h_{t-1}\right) ft=σ(W(f)xt+U(f)ht−1)
输出门/Output/Exposure gate: o t = σ ( W ( o ) x t + U ( o ) h t − 1 ) o_{t}=\sigma\left(W^{(o)} x_{t}+U^{(o)} h_{t-1}\right) ot=σ(W(o)xt+U(o)ht−1)
新记忆生成/New memory cell: c ~ t = tanh ( W ( c ) x t + U ( c ) h t − 1 ) \tilde{c}_{t}=\tanh \left(W^{(c)} x_{t}+U^{(c)} h_{t-1}\right) c~t=tanh(W(c)xt+U(c)ht−1)
最终记忆合成/Final memory cell: c t = f t ∘ c t − 1 + i t ∘ c ~ t c_{t}=f_{t} \circ c_{t-1}+i_{t} \circ \tilde{c}_{t} ct=ft∘ct−1+it∘c~t
h t = o t ∘ tanh ( c t ) h_{t}=o_{t} \circ \tanh \left(c_{t}\right) ht=ot∘tanh(ct)
下图是LSTM的计算图示

我们可以通过以下步骤了解 LSTM 的架构以及这个架构背后的意义:
-
① 新记忆生成:这个阶段是类似于 GRU 生成新的记忆的阶段。我们基本上是用输入单词 x t x_t xt 和过去的隐藏状态来生成一个包括新单词 x ( t ) x^{(t)} x(t) 的新的记忆 c ~ t \tilde{c}_{t} c~t。
-
② 输入门:我们看到在生成新的记忆之前,新的记忆的生成阶段不会检查新单词是否重要——这需要输入门函数来做这个判断。输入门使用输入词和过去的隐藏状态来决定输入值是否值得保存,从而用来进入新内存。因此,它产生它作为这个信息的指示器。
-
③ 遗忘门:这个门与输入门类似,只是它不确定输入单词的有用性——而是评估过去的记忆是否对当前记忆的计算有用。因此,遗忘门查看输入单词和过去的隐藏状态,并生成 f t f_t ft。
-
④ 最终记忆合成:这个阶段首先根据忘记门 f t f_t ft 的判断,相应地忘记过去的记忆 c t − 1 c_{t-1} ct−1。类似地,根据输入门 i t i_t it 的判断,相应地输入新的记忆 c ~ t \tilde c_t c~t。然后将上面的两个结果相加生成最终的记忆 c t c_t ct。
-
⑤ 输出门:这是GRU中没有明确存在的门。这个门的目的是从隐藏状态中分离最终的记忆。最终的记忆 c t c_t ct 包含很多不需要存储在隐藏状态的信息。隐藏状态用于LSTM的每个单个门,因此,该门是要评估关于记忆单元 c t c_t ct 的哪些部分需要显露在隐藏状态 h t h_t ht 中。用于评估的信号是 o t o_t ot,然后与 c t c_t ct 通过 o t ∘ tanh ( c t ) o_{t} \circ \tanh \left(c_{t}\right) ot∘tanh(ct) 运算得到最终的 h t h_t ht。
5.参考资料
- 《ShowMeAI 深度学习与自然语言处理教程》的PDF在线阅读版本 - note5
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
ShowMeAI 深度学习与自然语言处理教程(完整版)
- ShowMeAI 深度学习与自然语言处理教程(1) - 词向量、SVD分解与Word2vec
- ShowMeAI 深度学习与自然语言处理教程(2) - GloVe及词向量的训练与评估
- ShowMeAI 深度学习与自然语言处理教程(3) - 神经网络与反向传播
- ShowMeAI 深度学习与自然语言处理教程(4) - 句法分析与依存解析
- ShowMeAI 深度学习与自然语言处理教程(5) - 语言模型、RNN、GRU与LSTM
- ShowMeAI 深度学习与自然语言处理教程(6) - 神经机器翻译、seq2seq与注意力机制
- ShowMeAI 深度学习与自然语言处理教程(7) - 问答系统
- ShowMeAI 深度学习与自然语言处理教程(8) - NLP中的卷积神经网络
- ShowMeAI 深度学习与自然语言处理教程(9) - 句法分析与树形递归神经网络
ShowMeAI 斯坦福NLP名课 CS224n带学详解(20讲·完整版)
- 斯坦福NLP名课带学详解 | CS224n 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP名课带学详解 | CS224n 第2讲 - 词向量进阶
- 斯坦福NLP名课带学详解 | CS224n 第3讲 - 神经网络知识回顾
- 斯坦福NLP名课带学详解 | CS224n 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP名课带学详解 | CS224n 第5讲 - 句法分析与依存解析
- 斯坦福NLP名课带学详解 | CS224n 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP名课带学详解 | CS224n 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP名课带学详解 | CS224n 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP名课带学详解 | CS224n 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP名课带学详解 | CS224n 第10讲 - NLP中的问答系统
- 斯坦福NLP名课带学详解 | CS224n 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP名课带学详解 | CS224n 第12讲 - 子词模型
- 斯坦福NLP名课带学详解 | CS224n 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP名课带学详解 | CS224n 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP名课带学详解 | CS224n 第15讲 - NLP文本生成任务
- 斯坦福NLP名课带学详解 | CS224n 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP名课带学详解 | CS224n 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP名课带学详解 | CS224n 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP名课带学详解 | CS224n 第19讲 - AI安全偏见与公平
- 斯坦福NLP名课带学详解 | CS224n 第20讲 - NLP与深度学习的未来
ShowMeAI系列教程精选推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
