2021年高教杯数学建模国赛C题的解题过程附全部代码以及参赛论文(百度网盘)
我们小组参加了2021年数学建模,本人负责代码方面,此文仅为自己的思考理解+代码分析+题目分析
题目:
注:试题完整版和对应的附件在我另一篇文章里面
某建筑和装饰板材的生产企业所用原材料主要是木质纤维和其他植物素纤维材料,总体可分为 A,B,C 三种类型。该企业每年按 48 周安排生产,需要提前制定 24 周的原材料订购和转运计划,即根据产能要求确定需要订购的原材料供应商(称为“供应商”)和相应每周的原材料订购数量(称为“订货量”),确定第三方物流公司(称为“转运商”)并委托其将供应商每周的原材料供货数量(称为“供货量”)转运到企业仓库。
该企业每周的产能为 2.82 万立方米,每立方米产品需消耗 A 类原材料0.6 立方米,或 B 类原材料 0.66 立方米,或 C 类原材料 0.72 立方米。由于原材料的特殊性,供应商不能保证严格按订货量供货,实际供货量可能多于或少于订货量。为了保证正常生产的需要,该企业要尽可能保持不少于满足两周生产需求的原材料库存量,为此该企业对供应商实际提供的原材料总是全部收购。在实际转运过程中,原材料会有一定的损耗(损耗量占供货量的百分比称为“损耗率”),转运商实际运送到企业仓库的原材料数量称为“接收量”。每家转运商的运输能力为 6000 立方米/周。通常情况下,一家供应商每周供应的原材料尽量由一家转运商
运输。原材料的采购成本直接影响到企业的生产效益,实际中 A 类和 B 类原材料的采购单价分别比 C 类原材料高 20%和 10%。三类原材料运输和储存的单位费用相同。附件 1 给出了该企业近 5 年 402 家原材料供应商的订货量和供货量数据。附件 2 给出了 8 家转运商的运输损耗率数据。请你们团队结合实际情况,对相关数据进行深入分析,研究下列问题:
1.根据附件 1,对 402 家供应商的供货特征进行量化分析,建立反映保障企业生产重要性的数学模型,在此基础上确定 50 家最重要的供应商,并在论文中列表给出结果。
2.参考问题 1,该企业应至少选择多少家供应商供应原材料才可能满足生产的需求?针对这些供应商,为该企业制定未来 24 周每周最经济的原材料订购方案,并据此制定损耗最少的转运方案。试对订购方案和转运方案的实施效果进行分析。
3.该企业为了压缩生产成本,现计划尽量多地采购 A 类和尽量少地采购 C 类原材料,以减少转运及仓储的成本,同时希望转运商的转运损耗率尽量少。请制定新的订购方案及转运方案,并分析方案的实施效果。
4.该企业通过技术改造已具备了提高产能的潜力。根据现有原材料的供应商和转运商的实际情况,确定该企业每周的产能可以提高多少,并给出未来 24 周的订购和转运方案。
第一问:
理论分析:
该企业每周的产能为 2.82 万立方米,按照每立方米产品需消耗 A 类原材料 0.6 立方米,或 B 类原材料 0.66 立方米,或 C 类原材料 0.72 立方米。按原材料的最小需求量算是2.82万✖0.6=16920,按原材料的最大需求量算是2.82万✖0.72=20304。而我们根据excel表格计算402家每周所有的供应量仅仅只有40+周是肯定能满足要求的(即是该周供应量超过20304),有50+周是不一定能满足的(即是该周供应量在16920到20304之间),还有140周是一定不能满足要求的,既然402家供应商全部供应量加起来都不一定能达到所需产能,那选择最重要的50家企业就需要以这个供应量为标准,然后我们又考虑到了有些供应商的数据非常奇怪(连续几周供应量非常低,然后突然供应量达到最大值),如图
![]()
像这种我们就需要考虑他的方差,我们需要把这两个因素考虑进去,从而在402家供应商里面挑选50家最重要供应商,我们把每周的供应量进行排序,给每一家供应商一个排名,如果遇到供应量相同的供应商,给一个相同的排名,某家企业240周每周的排名的平均值即是以权值相等去同时考虑供应量和方差。以这个平均值去排序得到前50家供应商就是我们需要的最重要50家供应商。
代码分析:
首先需要从excel表格中读取402家供应商的240周的数据,
import xlrd
file_location = "C:/Users/95870/Desktop/数学建模代码/a.xlsx"#这个位置需要更改,否则不能运行
data = xlrd.open_workbook(file_location)
sheet = data.sheet_by_index(1) # 引用第二个表
sheet2=data.sheet_by_index(0) # 引用第一个表
data = [[sheet.cell_value(r,c) for c in range(sheet.ncols)] for r in range(sheet.nrows)] #读取该表1中所有的数据
data_d=[[sheet2.cell_value(r,c) for c in range(sheet2.ncols)] for r in range(sheet2.nrows)] #读取该表2中所有的数据
定义了一个列表,num_list(402✖240),用以存放每家供应商每周的排名(这个排名是没有并序的,就是数据相同的按照供应商号码进行排序),然后用冒泡法把402家供应商240周的供应量进行排序,并根据供应商号有一个对应关系,然后将排名进行并行排序,然后算排名的平均值,根据平均值再进行排序,前50家就是我们需要的50家最重要供应商(结果如图)。
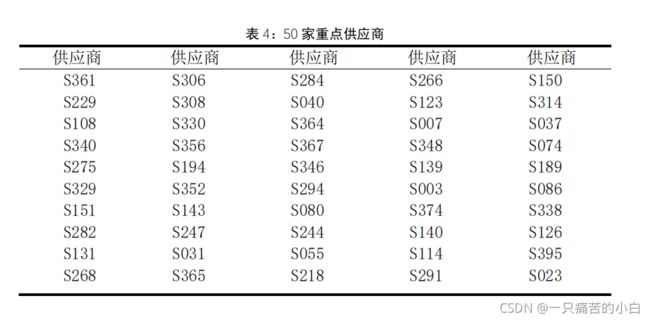
代码如下:
# -*- coding: utf-8 -*-
import xlrd
file_location = "C:/Users/95870/Desktop/数学建模代码/a.xlsx"
data = xlrd.open_workbook(file_location)
sheet = data.sheet_by_index(1)
sheet2=data.sheet_by_index(0)
data = [[sheet.cell_value(r,c) for c in range(sheet.ncols)] for r in range(sheet.nrows)]
#排名
import numpy
num_list = numpy.zeros((402,240))
for i in range(0,402):
for j in range(0,240):
num_list[i][j] = i+1
#把数据按每周进行排序
for k in range (240):
for i in range (0,402):
for j in range(0,401-i):
if data[j+1][k+2]<data[j+2][k+2]:
(data[j+1][k+2],data[j+2][k+2])=(data[j+2][k+2],data[j+1][k+2])
(num_list[j][k],num_list[j+1][k])=(num_list[j+1][k],num_list[j][k])
#排名相同的同一个排名(进行并序排名)
y = numpy.zeros((402,240))
for i in range (0,240):
a=1
y[0][i]=1
n=1
for j in range(0,401):
if data[j+1][i+2]==data[j+2][i+2]:
y[j+1][i]=y[j][i]
n=n+1
else :
y[j+1][i]=a+n
a=a+n
n=1
#算每家供应商每周排名的平均值
list = numpy.zeros((402,2))
for k in range(1,403):
sum=0.0
for i in range(0,402):
for j in range (0,240):
if num_list[i][j]==k:
sum=sum+y[i][j]
sum=sum/240
list[k-1][0]=sum
list[k-1][1]=k
# 对每周排名的平均值进行排序
for i in range (0,402):
for j in range(0,401-i):
if list[j][0]>list[j+1][0]:
(list[j][0],list[j+1][0])=(list[j+1][0],list[j][0])
(list[j][1],list[j+1][1])=(list[j+1][1],list[j][1])
#输出结果
for i in range(0,50):
print(list[i][1])
改进:
最重要这个有三个因素去影响它,第一个是方差,第二个是供应量,第三个是供应量和订购量的差值,函数:f = 供应量-方差-差值(供应量和方差,差值不是一个数量级,可以用供应量除以最大供应量,还可以根据这三个因素的重要程度设置权值)
当时我们小组因为时间不够,没有完善这个。
第二问:
思路:(具体分析可见论文)
对 402 家企业近 5 年的总产能进行排序,在总产能误差为 0.3%的限定条件下筛选,最终选择 37 家供应商。
将 240 周 402 企业的订货量与供货量的差取绝对值,依次对上述连续两周所求的绝对值求均值后从小到大排序,选取位于前 12 位的连续两周,即选定 24 周,并得到订购方案
转运方案是根据原材料有一定的损耗(损耗量占供货量的百分比称为“损耗率”),这个概率越小越好
还有一个限制,每家转运商的运输能力为6000立方米/周,根据每周需要转运的数量选择供应商
代码:
首先是要对 402 家企业近 5 年的总产能进行排序
import xlrd
import numpy
file_location = "C:/Users/95870/Desktop/数学建模代码/a.xlsx"
data = xlrd.open_workbook(file_location)
sheet = data.sheet_by_index(1)
sheet2=data.sheet_by_index(0)
data1 = [[sheet.cell_value(r,c) for c in range(sheet.ncols)] for r in range(sheet.nrows)]#读取数据
#402家供应商240周供应量总和
list1 = numpy.zeros((402,2))#240周总共的
for i in range(0,402):
sum=0
for j in range(0,240):
sum=sum+data1[i+1][j+2]
list1[i][0]=sum
list1[i][1]=i+1
#402家供应商240周供应量总和的排序
for i in range (0,402):#排序
for j in range(0,401-i):
if list1[j][0]<list1[j+1][0]:
(list1[j][0],list1[j+1][0])=(list1[j+1][0],list1[j][0])
(list1[j][1],list1[j+1][1])=(list1[j+1][1],list1[j][1])
在总产能误差为 0.3%的限定条件下筛选,即是按排名累加240周的供应量如果累加后和累加前的差值小于总产能误差为0.3%,我们则认为该家供应商不是必须的供应商,据此选取供应商。
#0.3%:240*28200*0.3%=20304(这个不是排名,是实际值)
qushu=0
for i in range (0,402):
if list1[i][0]<20304:
qushu=i+1
break
print(qushu)
for i in range(0,qushu):
print(list1[i][1])
最终得出的结果是选取了37家企业。
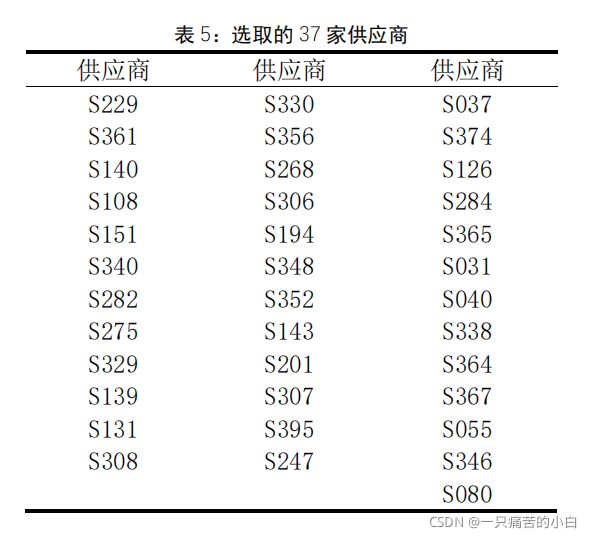
将 240 周 402 企业的订货量与供货量的差取绝对值,依次对连续两周所求的绝对值求均值后从小到大排序,选取位于前 12 位的连续两周,即选定 24 周。
首先根据37家供应商的连续两周的供应商供应量与订购量的差值的平均数进行排名
file = "C:/Users/95870/Desktop/数学建模代码/c.xlsx"#37家供应商的表格
data2 = xlrd.open_workbook(file)
sheet1 = data2.sheet_by_index(0)
data_d = [[sheet1.cell_value(r,c) for c in range(sheet1.ncols)] for r in range(sheet1.nrows)]
sheet2 = data2.sheet_by_index(1)
data_g = [[sheet2.cell_value(r,c) for c in range(sheet2.ncols)] for r in range(sheet2.nrows)]
list1 = numpy.zeros((37,239,4))#第三和第四是每个的差值(有正负那种)
a=b=c=0
for i in range(0,37):
for j in range(0,239):
a=data_g[i+1][j+2]-data_d[i+1][j+2]
b=data_g[i+1][j+3]-data_d[i+1][j+3]
list1[i][j][2]=a
list1[i][j][3]=b
if a>=0:
a=a
else:
a=-a
if b>=0:
b=b
else:
b=-b
c=(a+b)/2
list1[i][j][0]=c #差值(除法)
list1[i][j][1]=j+1#周数
for k in range(0,37):
for i in range (0,239):
for j in range(0,238-i):
if list1[k][j][0]>list1[k][j+1][0]:
(list1[k][j][0],list1[k][j+1][0])=(list1[k][j+1][0],list1[k][j][0])
(list1[k][j][1],list1[k][j+1][1])=(list1[k][j+1][1],list1[k][j][1])
(list1[k][j][2],list1[k][j+1][2])=(list1[k][j+1][2],list1[k][j][2])
(list1[k][j][3],list1[k][j+1][3])=(list1[k][j+1][3],list1[k][j][3])
从中选取12个连续两周的供应量作为我们的对接下来的24周的预期订购量
list2 = numpy.zeros((37,12,3))
for i in range(0,37):
for j in range(0,12):
list2[i][j][0]=-2
for i in range(0,37):
#k=12
k=0
for flag in range(0,50):
#for k in range(0,12):
b=0
for j in range (0,12):
#if list1[i][12-k][1]==list2[i][j][0]+1:
if list1[i][flag][1]==list2[i][j][0]+1 or list1[i][flag][1]==list2[i][j][0]-1:
b=1
break
if b==0:
list2[i][k][0]=list1[i][flag][1]
list2[i][k][1]=list1[i][flag][2]
list2[i][k][2]=list1[i][flag][3]
#list2[i][12-k][0]=list1[i][12-k][1]
k=k+1
if k==12:
break
把37家企业的24周的预计订购量放在列表里面,方便后续填表。
list3 = numpy.zeros((37,24))
for i in range(0,37):
a=b=c=0
for j in range (0,12):
a=list2[i][j][0]
b=a+1
c=int(a+2)
list3[i][j*2]=data_d[i+1][c]
k=k+1
c=int(b+2)
list3[i][j*2+1]=data_d[i+1][c]
然后确定转运方案,按照损耗率高低进行排序,每家转运商每周只能转运6000立方米,根据每周6000立方米确定每周这37家供应商需要多少家转运商,再按照转运商的损耗率排名(选取损耗率非0 的进行计算平均值确定排名)先后选择。
转运商排名:
list = numpy.zeros((8,2))
for i in range(0,8):
sum0=0
sum=0
for j in range (0,240):
if data[i+1][j+1]==0 :
sum0=sum0+1
else :
sum=sum+data[i+1][j+1]
sum=sum/(240-sum0)
list[i][0]=sum
list[i][1]=i+1
for i in range (0,8):
for j in range(0,7-i):
if list[j][0]>list[j+1][0]:
(list[j][0],list[j+1][0])=(list[j+1][0],list[j][0])
(list[j][1],list[j+1][1])=(list[j+1][1],list[j][1])
for i in range(0,8):
print(list[i][0],list[i][1])
每周需要的转运商家数(按照排名先后选取对应的转运商家数进行填表)
a=0
list4= numpy.zeros(24)
for i in range(0,24):#列
sum=0
for j in range(0,37):#行
a = data_y[j+1][i+2]
sum=sum+a
list4[i]=sum
for i in range(0,24):#b代表的是需要选取转运商的家数
b=list4[i]//6000
if list4[i]%6000 != 0:
b=b+1
第三问
思路:
先根据402家供应商的240周供应量(每周来看可能是不够的,但按周平均下来,供应量是足够的)进行排序,在第一问的50家重要供应商的前提下,进行多A少C的挑选,直至平均每周的供应量达到企业每周的产能,至此进行挑选出第三问的32家企业,再根据第二问的思路进行制定订购方案和转运方案。(订购方案:在240周中挑选出12个连续的供应量和订购量差值最小的两周作为接下来24周的预测值,以此确定订购方案。转运方案:根据24周的预测订购量确定需要多少家转运商,根据转运商损耗率由低到高的排序进行选择对应家数的转运商,以此作为转运方案。)
代码:
计算402家供应商240周的供应量均值
file_location = "C:/Users/95870/Desktop/数学建模代码/a.xlsx"
data = xlrd.open_workbook(file_location)
sheet = data.sheet_by_index(1)
sheet2=data.sheet_by_index(0)
data = [[sheet.cell_value(r,c) for c in range(sheet.ncols)] for r in range(sheet.nrows)]
data1 = [[sheet.cell_value(r,c) for c in range(sheet.ncols)] for r in range(sheet.nrows)]
data_d=[[sheet2.cell_value(r,c) for c in range(sheet2.ncols)] for r in range(sheet2.nrows)]
#订货量算总数(402家企业240周总供应量)
list2 = numpy.zeros((402,2))
for i in range(0,402):
sum=0
for j in range(0,240):
sum=sum+data_d[i+1][j+2]
list2[i][0]=sum
list2[i][1]=i+1
将402家供应商240周的供应量均值进行排名
#订货量排名
for i in range (0,402):#排序
for j in range(0,401-i):
if list2[j][0]<list2[j+1][0]:
(list2[j][0],list2[j+1][0])=(list2[j+1][0],list2[j][0])
(list2[j][1],list2[j+1][1])=(list2[j+1][1],list2[j][1])
按照前50进行先A,再B,最后C,直到平均产能满足每周产能28200,记录挑选上的供应商号,以及记录挑选上多少家供应商。以满足多A少C且能满足企业的每周产能28200立方米 。
num=0
sum=0
for i in range(0,50):
a=int(list2[i][1])
if data_d[a][1]=='A':
sum=sum+list2[i][0]/0.6
num=num+1
print(list2[i][1])
if (sum/240) >28200:
print('$',num+1,list2[i][1])
break
for i in range(0,50):
a=int(list2[i][1])
if data_d[a][1]=='B':
sum=sum+list2[i][0]/0.66
num=num+1
print(list2[i][1])
if (sum/240) >28200:
print('$',num+1,list2[i][1])
break
for i in range(0,50):
a=int(list2[i][1])
if data_d[a][1]=='C':
sum=sum+list2[i][0]/0.72
num=num+1
print(list2[i][1])
if (sum/240) >28200:
print('$',num,list2[i][1])
break
挑选出以下供应商。
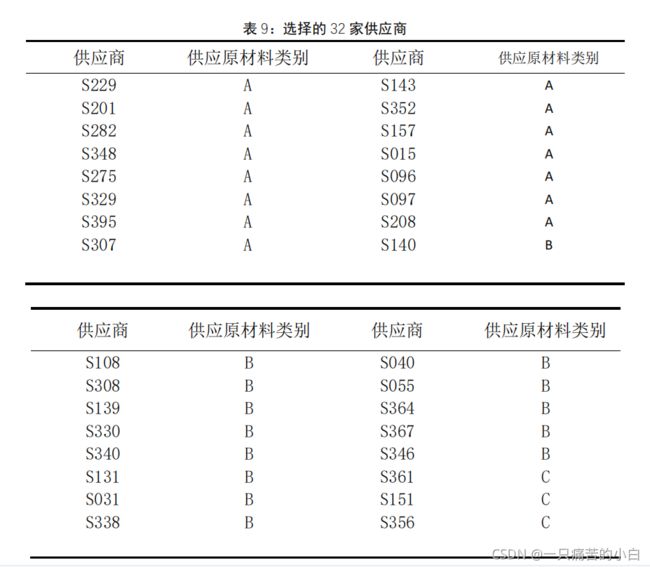
然后把这32家供应商的240周订购量信息和供应量信息挑选到excel表格里,我这里是放在了e.xlsx里面。
订购方案的选取,转运方案的制定和第二问一致,就不加以赘述了。
第四问:
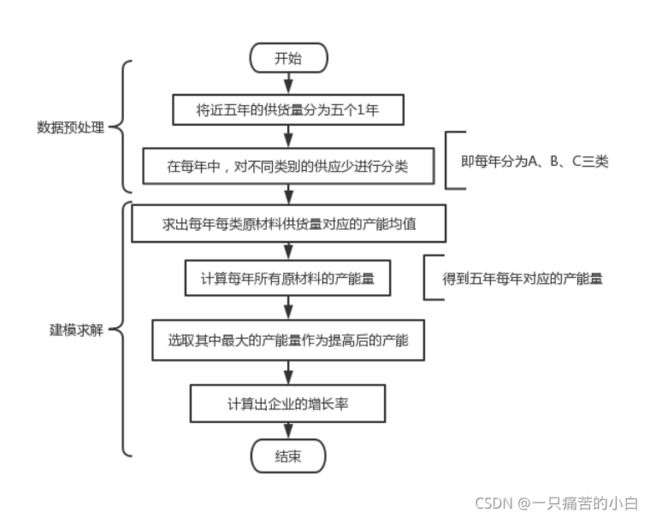
将近五年的数据按照年份分为 5 组,即 240 周数据每 48 周为一组,并对每组数据按照供货商的供货类别进行分类,根据不同类别,分别计算出每年每类原材料所对应的供货量,(有些供应商某些周内供应量为1,2这种小数,不妨大胆做个假设,这些供应商没有将所有的产品供给该企业,按照题目意思,假设这些供应商尽量将产品提供给该企业,我们可以把周期定为一年,在给定数据的五年中,计算每年的数据,按照其最大的年产能来提高企业的周产能)
得到五年的数据:
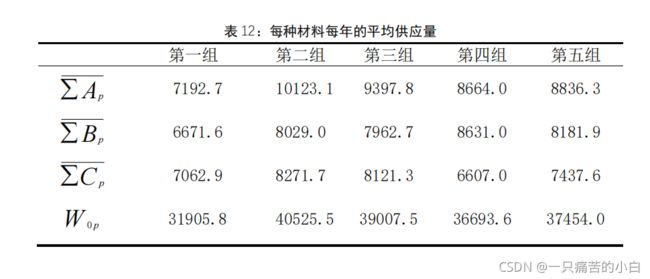
按照五年平均最高的供应量去算即是40525.5,企业周产能可以提高到40525.5,和现在相比是提高了12325.5。
代码基本罗列过,就不再重复罗列了
代码百度网盘链接:
链接: https://pan.baidu.com/s/1hK2Xmmi1cFN5dgpD7zOvtw
提取码:7d8c
我们小组论文链接:
链接: https://pan.baidu.com/s/1yuVGCmFLNJIM3u0q_PBpTw
提取码:7d8c