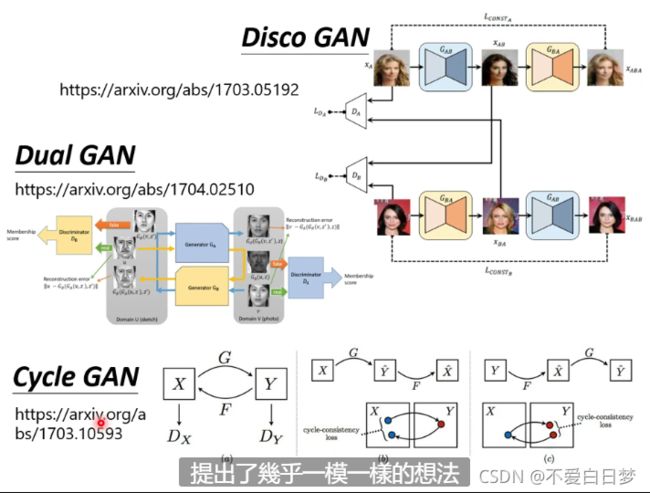
李宏毅2021春机器学习课程 GAN笔记
https://www.bilibili.com/video/BV1Wv411h7kN?p=40
Network做生成器的特别之处在于:
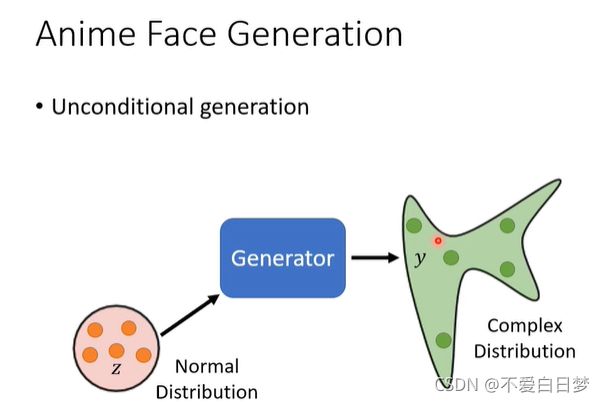
有一个Z :random variable
是不固定的,随机生成的是从分布中采样来的,
distribution 一般比较简单,比如高斯分布
最后得到的output是复杂的 distribution
为什么输出需要是一个分布
因为多种决策是同时存在在训练资料里的
Network 需要做到两面讨好
为了解决:输出一个概率
当任务需要一点”创造力“
同样的输入,有多种不同可能的输出,且多种输出都是对的
比如:画图、聊天机器人
unconditional: 无x
generator:产生高维向量
discriminator: scaler越大 越像是真的,一般用CNN(处理影响)

固定 g 训练d
固定d 训练g
反复
应用:
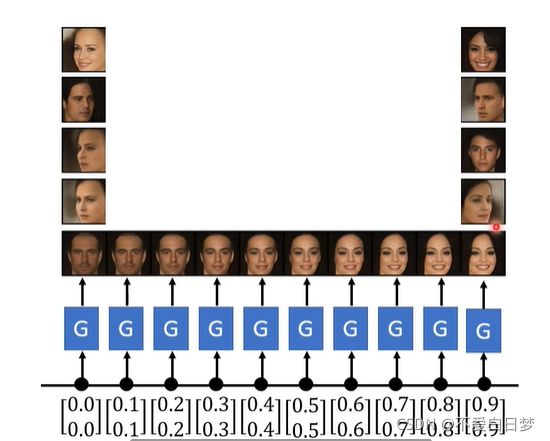
向量做内插
Theory behind GAN
min/max的是一个分布 越接近越好

divergenc【散度】e越小代表越相近,是衡量相似度的measure
如:KL /JS divergence
divergence 如何计算?- sample
怎么在只有做sample的前提下 估算出 divergence
我们可以从Pdata,PG中做sample,GAN的工作就是如何在sample的前提,而不知道整体formulation的前提下,得到divergence

依靠discriminator:
分辨,看到真图给高分,看到生成的图给低分
看作优化问题 objective function (一开始是为了和二元分类扯上关系,cross entropy)

objective function 与JS散度有关(推导之后发现的)
小的散度(small divergence 分布很像 )对应小的Vd(D,G)

生成器的任务是min橙框,而橙框是鉴别器maxJS散度的一个函数

Tips of training

WGAN
PG和Pdata 重叠的部分往往非常少
原因1:
(资料本身特性)
图片其实是高维空间中低维的一个 manifold(流形)
目标的分布在高维空间中是非常狭窄的(一般的分布并不是二次元头像=-=)
原因2:
sample
从来不知道PG Pdata的样子,只是sample来的
如果sample的点不够多不够密,会有差异

对JS造成的问题:
(1)没有重叠往往算出来都是log2(评价不客观)
(2)通常train完后, discriminator 100%(样本太少,硬记)

Wgan
两个分布:想象在开推土机,P是土,Q是目的地
把P的土挪到Q。有许多种moving plan
D必须属于1- Lipschitz (一个足够平滑的function[为了防止正负无穷的出现])


spectral normalization 是目前比较好的wgan
train discriminator的时候能不能用generator的训练资料?
实操上,discriminator train的次数较少
生成器效应评估与条件式生成
GAN 难train的原因:
discriminator是鉴别 生成图像与真实图像的
generator是生成图像以欺骗鉴别器的
两者是相辅相成的,一个崩了另一个也会

需要match to each other
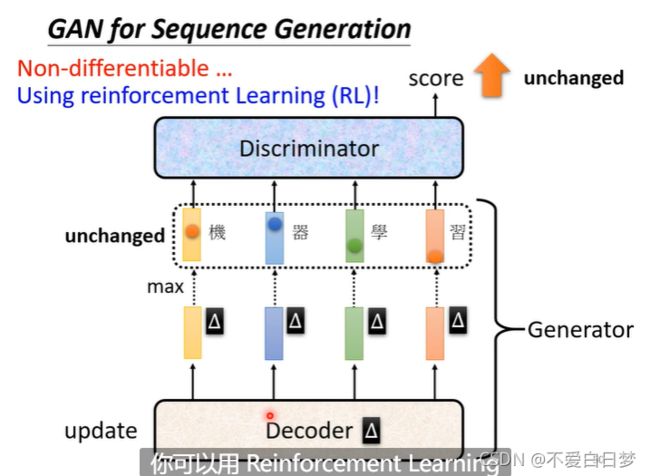
难度max:生成文字
因为需要一个seq2seq的model,变成generator。decoder产生文字, 当decoder参数变动,很难对token(处理问题的单位)产生影响,分数最大的token没有改变,很难gradient descent

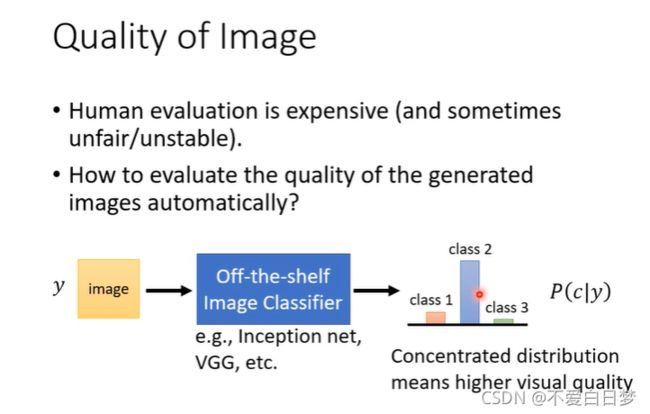
影像分类系统:
mode collapse: 模型坍缩

多样性问题:

diversity 和Quality有点互斥,但他们评估的范围不一样,Quality是对一张图片而言,观察分布是否集中。
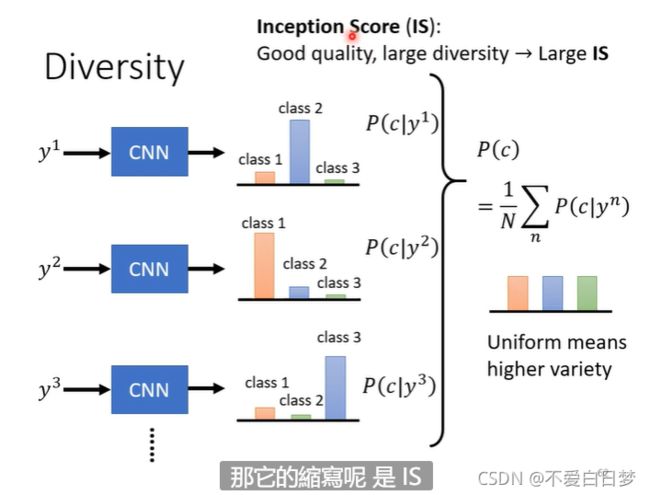
evaluate 2:
取中间的向量代表图片
diatance 越小越好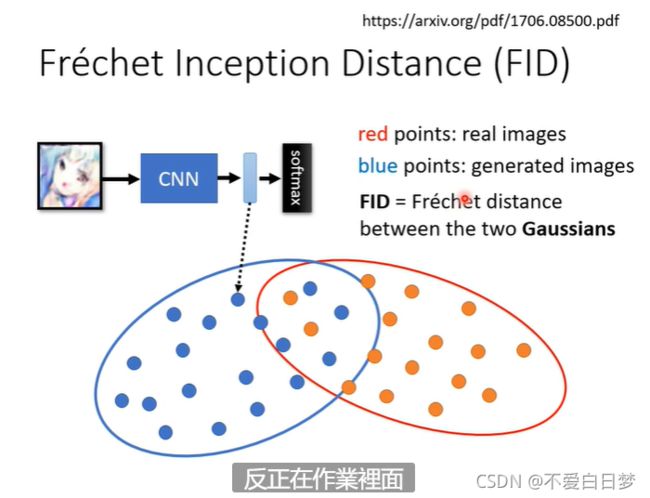
高斯分布属于近似化,且需要较大的计算量
Are GANs Created Equal?
很难评判

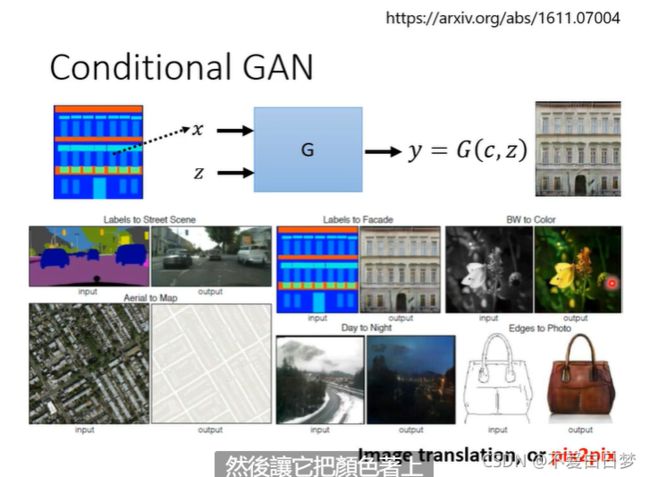
Conditional Generator
操控生成:

图片要好,也要和x匹配,需要成对的资料

应用2:pix2pix 也叫image transaction
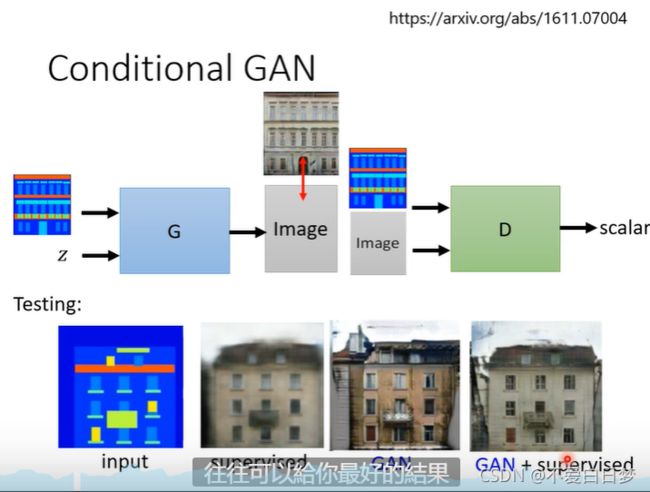
声音到影像:nb = =

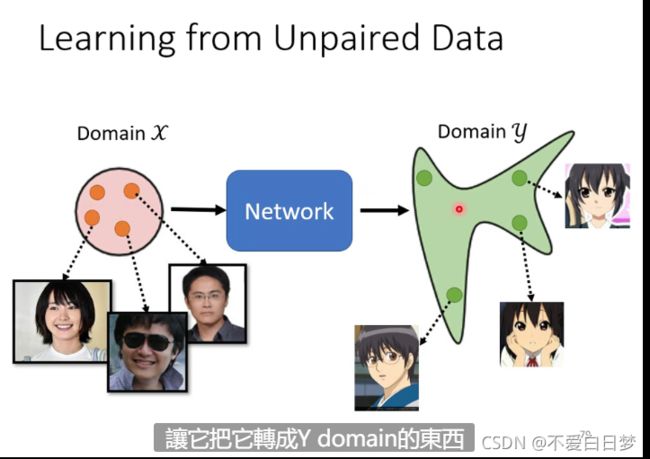
Learning from Unpaired Data
风格迁移
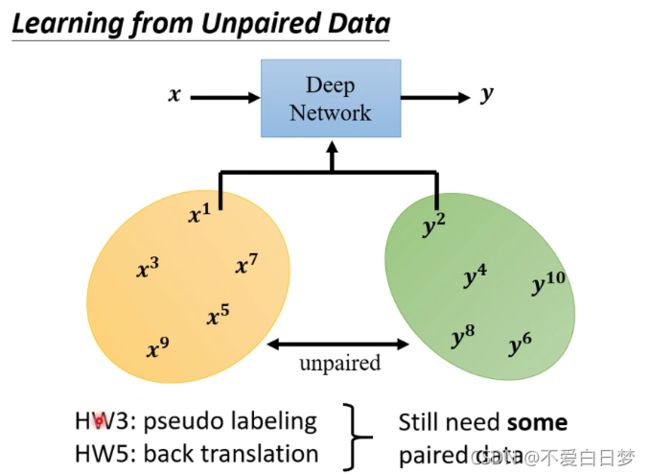
没有成对的资料
如果只是套用原来的GAN的方法是不够的,因为只是训练G,有可能生成的与X没有什么关系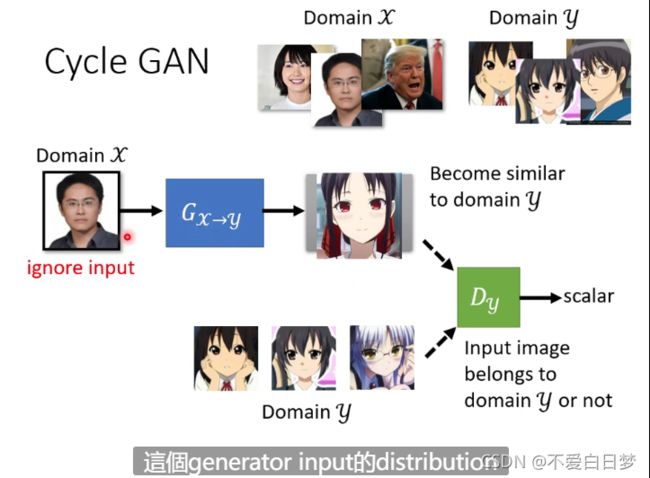
conditional GAN 有称对的资料,可以xy组合
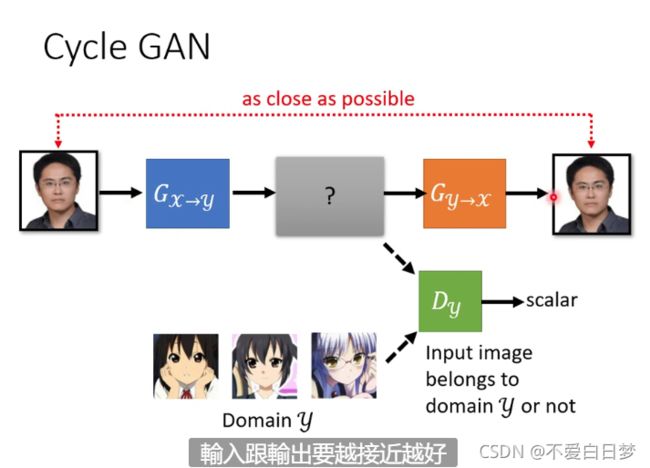
3个Network
(关系不一定是我们想要的 有可能会学到奇怪的转换)
Network 本身还是会输出比较像的东西