目标检测系列——开山之作RCNN原理详解
作者简介:秃头小苏,致力于用最通俗的语言描述问题
往期回顾:ubuntu使用指南 阿里云对象存储oss+picgo+typora实现步骤及无法上传图片解决方案
近期目标:拥有10000粉丝
支持小苏:点赞、收藏⭐、留言
文章目录
- RCNN原理
-
- 写在前面
- 候选区域生成
- 神经网络提取特征
- SVM分类器分类
- 回归器修正候选框位置
- 小结
- 参考链接
RCNN原理
写在前面
RCNN是目标检测领域的开山之作,作者是Ross Girshick ,我们称之为RGB大神 可以在google学术中看看这位大牛都写了哪些文章,看看这引用次数,只能惊呼!!!

接下来将详细介绍介绍RCNN的原理,先来看看论文中这张经典的图片。这张图片展示了RCNN的实现过程,其主要有四步,下面分别对每步进行讲解。

候选区域生成
候选区域生成在RCNN中采用的是selective search 【简称SS算法】,这个算法的原理大致是通过颜色、大小、形状等一些特征对图像进行聚类,算法的结果是在一张图片中生成一系列的候选框,RCNN中让每张图像都生成2000个候选框。这些候选框有着大量的重叠部分,因此我们后面需要将这些重叠的候选框去除,得到相对准确的候选框。【注:这里不对SS算法做详细的讲解,感兴趣的可以自己查阅了解】下图展示了SS算法得到的大致结果,可见一个目标会有多个候选框生成。【注:RCNN中SS算法每幅图像生成的候选框个数为2000】

神经网络提取特征
上一步我们由SS算法从一张图片中得到了2000个候选框,接下来需要对这些候选框进行特征提取,即分别将2000个候选框区域喂入ALexNet网络进行训练,提取特征。【注:有关ALexNet的网络结构我前文有介绍,不清楚的点击☞了解详情】为方便大家阅读,我把ALexNet的网络结构也贴出供大家参考,如下图所示:

需要注意的是,在RCNN中,我们不需要最后的softmax层,只需要经过最后两次全连接层,利用其提取到的特征即可。此外由于全连接层的存在,需要对输出图片的尺寸进行限制,即需要图片分辨率为227*227。论文中所采用的方法为无论候选区域的大小或纵横比如何,先将其周围扩展16个邻近像素,然后将所有像素强制缩放至227*227尺寸。【注:可见此方案会使原图像发生畸变,如人物变矮变胖等】相关缩放方案如下图所示:
SVM分类器分类
上一步我们已经通过ALexNet网络提取到特征,每一个候选框区域都会生成4096维的特征向量,如下图所示:
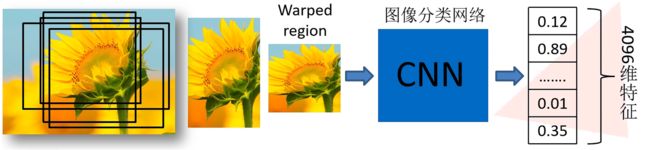
上图展示的是一个候选框提取到的特征,我们采用SS算法会从一幅图片中生成2000个候选框,将所有候选框输入网络,就会得到2000*4096维的特征矩阵。将2000*4096维的特征矩阵与20个SVM组成的权值矩阵4096*20相乘,会得到2000*20维的概率矩阵,其中每一行代表一个候选框属于各个目标类别的概率。【注意:若采用的是VOC数据集,那么类别是应该有21类,包括一个背景类】
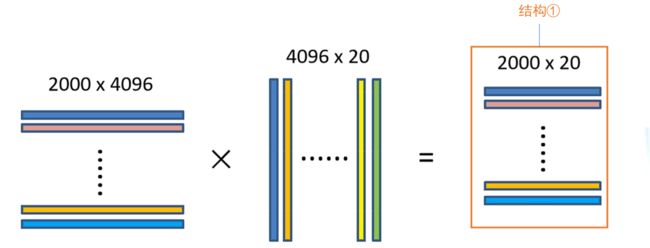
为让大家更容易理解,对于上图的结构①做更详细的解释,如下图所示:

从上图可以看出,2000*20维矩阵的每一列表示2000个候选框分别对某一类的预测概率,如第一列则表示2000个候选框分别对狗的预测概率。我们对每一列即每一类进行非极大值抑制(NMS)用于剔除重叠候选框,得到该列中得分最高的的建议框。具体NMS过程如下:

关于这一部分开始可能会有点迷惑,为什么要删除IOU大的目标呢?我之前也产生过这个疑问,其实这还是我们对这个流程不是很清楚。首先我们会在某一列中找出得分最高的目标,然后会计算其它目标和这个得分最高目标的IOU【注意不是计算与Ground Truth的IOU】,这个IOU大表示什么含义呢?这个值越大表示这两个候选框重叠的部分越多,则表示这两个候选框很可能表示的是同一个物体,那么删除得分低的候选框就很容易理解了。下图展示了相关过程:

回归器修正候选框位置
上一步骤中我们剔除了许多候选框,接下来我们需要对剩余的候选框进一步筛选,即分别用20个回归器对上述20个类别中剩余的候选框进行回归操作,最终得到每个类别修正后的得分最高的bounding box。
那么我们怎么由候选框得到最后的预测框呢?我们依旧会由ALexNet输出的特征向量来得到回归器的预测结果,其结果为 ( d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ) (d_x(P),d_y(P),d_w(P),d_h(P)) (dx(P),dy(P),dw(P),dh(P)) ,其表示中心点坐标偏移和宽度和候选框高度偏移的缩放因子。其预测的结果 G i ∧ {\mathop {\rm{G_i}}\limits^ \wedge} Gi∧的表达式如下所示:

我们由上式反解出 ( d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ) (d_x(P),d_y(P),d_w(P),d_h(P)) (dx(P),dy(P),dw(P),dh(P)) 的表达式,现用 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th) 表示,因为标注框参数和候选框参数都是给定的,因此 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th) 也是可直接计算得到的,为真实值。

接下来就用 ( d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) ) (d_x(P),d_y(P),d_w(P),d_h(P)) (dx(P),dy(P),dw(P),dh(P))值去拟合 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th)值,使损失函数最小,损失函数如下:

小结
RCNN的原理部分就介绍到这里了,希望可以对大家有所帮助。后续会持续更新fast_RCNN和Faster_RCNN的内容以及相关代码讲解,一起加油吧!!!
参考链接
RCNN理论合集
RCNN论文精读
如若文章对你有所帮助,那就
咻咻咻咻~~duang~~点个赞呗