AI越进化越跟人类大脑像!Meta找到了机器的“前额叶皮层”,AI学者和神经科学家都惊了...
鱼羊 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
说出来你可能不信,有一只AI刚刚被证明,处理语音的方式跟大脑谜之相似。
甚至在结构上都能相互对应——
科学家们在AI身上直接定位出了“视觉皮层”。
这项来自Meta AI等机构的研究一经po出,立马在社交媒体上炸开了锅。一大波神经科学家和AI研究者前往围观。

LeCun称赞这是“出色的工作”:自监督Transformer分层活动与人类听觉皮层活动之间,确实密切相关。
还有网友趁机调侃:Sorry马库斯,但AGI真的快要来了。
不过,研究也引发了一些学者的好奇。
例如麦吉尔大学神经科学博士Patrick Mineault提出疑问:
我们发表在NeurIPS的一篇论文中,也尝试过将fMRI数据和模型联系起来,但当时并不觉得这俩有啥关系。
所以,这到底是一项怎样的研究,它又是如何得出“这只AI干起活来像大脑”的结论的?
AI学会像人脑一样工作
简单来说,在这项研究中,研究人员聚焦语音处理问题,将自监督模型Wav2Vec 2.0同412名志愿者的大脑活动进行了比较。
这412名志愿者中,有351人说英语,28人说法语,33人说中文。研究人员给他们听了大约1个小时的有声书,并在此过程中用fMRI对他们的大脑活动进行了记录。
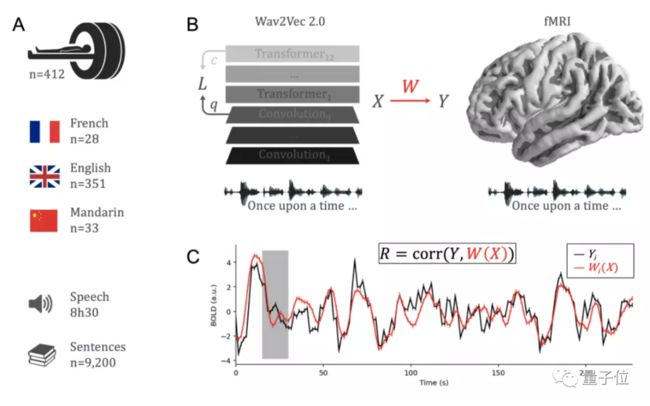
模型这边,研究人员则用超过600小时的无标签语音来训练Wav2Vec 2.0。
对应志愿者的母语,模型也分为英语、法语、中文三款,另外还有一款是用非语音声学场景数据集训练的。
而后这些模型也听了听志愿者同款有声书。研究人员从中提取出了模型的激活。
相关性的评价标准,遵照这个公式:

其中,X为模型激活,Y为人类大脑活动,W为标准编码模型。
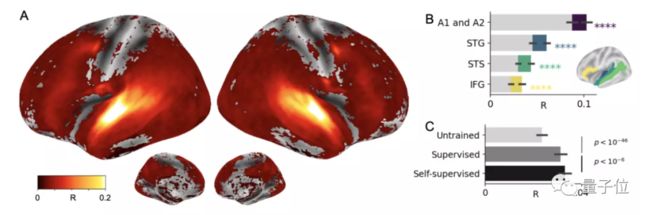
从结果来看,自监督学习确实让Wav2Vec 2.0产生了类似大脑的语音表征。
从上图中可以看到,在初级和次级听觉皮层,AI明显预测到了几乎所有皮层区域的大脑活动。
研究人员还进一步发现了AI的“听觉皮层”、“前额叶皮层”到底长在哪一层。
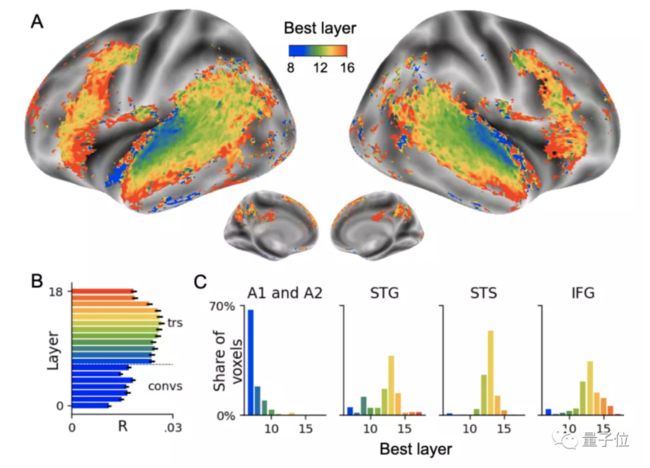
图中显示,听觉皮层与Transformer的第一层(蓝色)最吻合,而前额叶皮层则与Transformer的最深一层(红色)最吻合。
此外,研究人员量化分析了人类感知母语和非母语音素的能力差异,并与Wav2Vec 2.0模型进行对比。
他们发现,AI也像人类一样,对“母语”有更强的辨别能力,比如,法语模型就比英语模型更容易感知来自法语的刺激。
上述结果证明了,600小时的自监督学习,就足以让Wav2Vec 2.0学习到语言的特定表征——这与婴儿在学说话的过程中接触到的“数据量”相当。
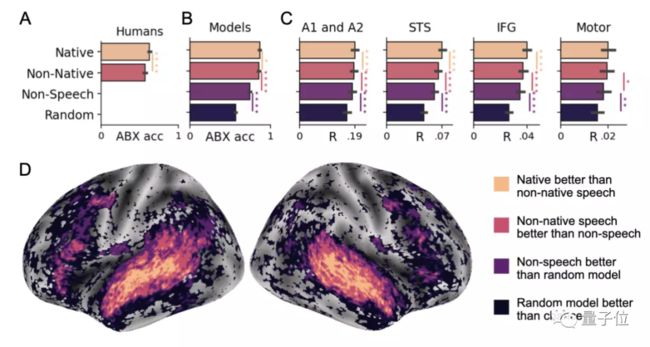
要知道,之前DeepSpeech2论文认为,至少需要10000小时的语音数据(还得是标记的那种),才能构建一套不错的语音转文字(STT)系统。

再次引发神经科学和AI界讨论
对于这项研究,有学者认为,它确实做出了一些新突破。
例如,来自谷歌大脑的Jesse Engel称,这项研究将可视化滤波器提升到了一个新的层次。
现在,不仅能看到它们在“像素空间”里长啥样,连它们在“类脑空间”中的模样也能模拟出来了:
又例如,前MILA和谷歌研究员Joseph Viviano认为,这个研究还证明了fMRI中的静息态(resting-state)成像数据是有意义的。
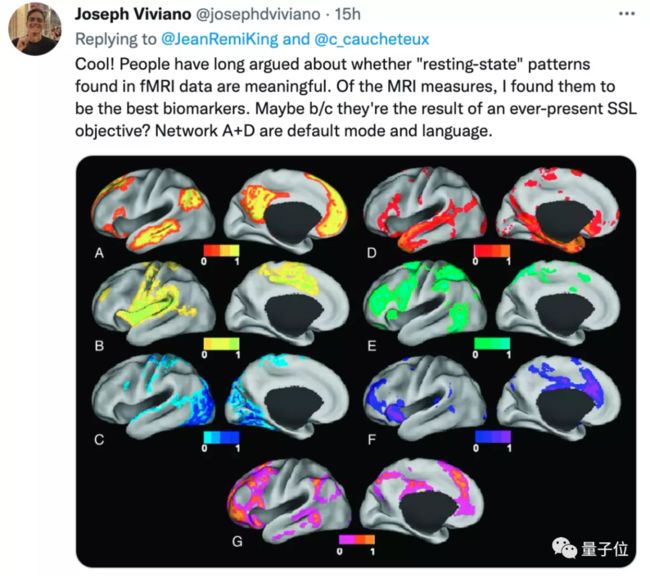
但在一片讨论中,也出现了一些质疑的声音。
例如,神经科学博士Patrick Mineault除了指出自己做过相似研究但没得出结论外,也给出了自己的一些质疑。

他认为,这篇研究并没有真正证明它测量的是“语音处理”的过程。
相比于人说话的速度,fMRI测量信号的速度其实非常慢,因此贸然得出“Wav2vec 2.0学习到了大脑的行为”的结论是不科学的。
当然,Patrick Mineault表示自己并非否认研究的观点,他自己也是“作者的粉丝之一”,但这项研究应该给出一些更有说服力的数据。
此外也有网友认为,Wav2vec和人类大脑的输入也不尽相同,一个是经过处理后的波形,但另一个则是原始波形。
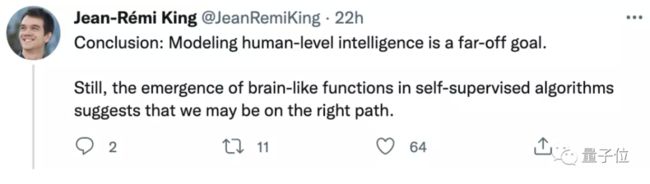
对此,作者之一、Meta AI研究员Jean-Rémi King总结:
模拟人类水平的智能,确实还有很长的路要走。但至少现在来看,我们或许走在了一条正确的道路上。
你认为呢?
论文地址:
https://arxiv.org/abs/2206.01685
参考链接:
[1]https://twitter.com/patrickmineault/status/1533888345683767297
[2]https://twitter.com/JeanRemiKing/status/1533720262344073218
[3]https://www.reddit.com/r/singularity/comments/v6bqx8/toward_a_realistic_model_of_speech_processing_in/
[4]https://twitter.com/ylecun/status/1533792866232934400