【玩转yolov5】使用TensorRT C++ API搭建yolov5s-v4.0网络结构(3)
接上篇【玩转yolov5】使用TensorRT C++ API搭建v4.0网络结构(2),backbone部分已经讲完了,现在进入到neck部分。在继续讲解neck部分之前,我们有必要先回顾一下PANet,因为neck部分是一个FPN+PAN的结构。

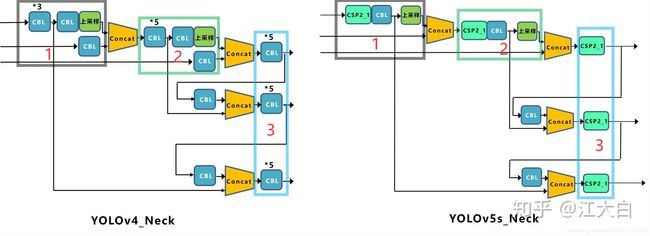
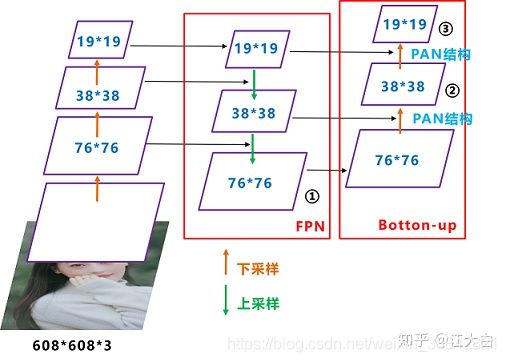
PANet在FPN的基础上增加了Bottom-up Path Augmentation,主要是考虑到网络的浅层特征中包含了大量的边缘形状等特征,他们对于实例分割这种像素级别的分类任务起到至关重要的作用。上图红色的箭头表示在FPN中,因为要经过自底向上的过程,浅层特征传到顶层要经过几十甚至上白层网络,浅层信息丢失严重。红色的箭头表示作者添加的Bottom-up Path Augmentation结构,这个结构本生不到十层。这样,浅层特征经过原始FPN中的横向连接到P2,然后再从P2由Bottom-up Path Augmentation传到顶层,经过的层数很少,能较好的保存浅层特征。注意,这里的N2和P2表示的是同一个特征图,而N3,N4,N5和P3,P4,P5不一样,N3,N4,N5是P3,P4,P5融合后的结果。YOLOv5的Neck网络仍然使用了FPN+PAN结构,但是在它的基础上做了一些改进操作,YOLOv4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck网络中,采用借鉴CSPnet设计的CSP2结构,从而加强网络特征融合能力。下图展示了YOLOv4与YOLOv5的Neck网络的具体细节,通过比较我们可以发现:(1)灰色区域表示第1个不同点,YOLOv5不仅利用CSP2_1结构代替部分CBL模块,而且去掉了下方的CBL模块;
(2)绿色区域表示第2个不同点,YOLOv5不仅将Concat操作之后的CBL模块更换为CSP2_1模块,而且更换了另外一个CBL模块的位置;
(3)蓝色区域表示第3个不同点,YOLOv5中将原始的CBL模块更换为CSP2_1模块。
yolov5包含3个检测分支,分别在8x,16,32x的特征图上,首先来使用tensort api来构造第一个分支的Neck部分。

auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9"); //CSP2_1
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10"); //CBL
//第一次上采样,32x->upsample->16x
auto upsample11 = network->addResize(*conv10->getOutput(0));
assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
//Concat
ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };
auto cat12 = network->addConcatenation(inputTensors12, 2);
auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");
//第二次上采样,16x->upsample->8x
auto upsample15 = network->addResize(*conv14->getOutput(0));
assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
//Concat
ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");Neck部分的CSP结构为CSP2_X,在前文提到过CSP2_X和CSP1_X最重要的区别就在于中间的若干Bottleneck结构变成了普通卷积。上采样部分借助TensorRT API addResize(...)函数来完成,经过两次上采样操作,将32x的特征图变化到8x大小。
再来构造第2和第3个分支,这个就相对简单了。

//The second branch
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
auto cat19 = network->addConcatenation(inputTensors19, 2);
auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
//The third branch
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors22, 2);
auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);Yolov5的Head部分采用1x1的卷积结构,总共三组输出,输出特征图大小分辨率为:
BS x 255 x 76 x76
BS x 255 x 38 x 38
BS x 255 x 19 x 19
其中,BS是Batch Size,255的计算方式为[na * (nc + 1 + 4)],具体参数
-
na(number of anchor) 为每组 anchor 的尺度数量(YOLOv5中一共有 3 组anchor,每组有3个尺度);
-
nc 为number of class (coco的class 为80);
-
1 为前景背景的置信度score;
- 4 为中心点坐标和宽高;
最后,输出的特征图上会应用锚定框,并生成带有类别概率、置信度得分和包围框的最终输出向量。

IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);【参考文献】
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#create_network_c #nvidia官方