Pytorch—NiN和GoogleNet神经网络
Pytorch—NiN和GoogleNet神经网络
1 NiN神经网络
在前面介绍的LeNet,AlexNet,VGG神经网络中,其共同点在于使用卷积层和池化层提取输入特征。在将矩阵展开成一个向量的形式,再利用线性层进行输出分类结果。在下面的内容中,我们描述另外的一种思路。
1.1 基本介绍
在我们之前的实现的LeNet,VGG中,原始输入的形式一般为(Batch_size,channel,high,width)这样的四个维度。通过卷积层之后,我们将卷积获得的结果进行展开操作,再输入到线性层中进行下一步的操作。下面我们来思考,如果我们在线性层输出之后,想要在将输出的结果输入到卷积和池化层中,这势必要将数据再次整理成上述的四维的形式。
那么,回忆一下11的卷积过程,如如果我们定义一个11的卷积核,当卷积核在输入矩阵上进行滑动的时候,该卷积核的参数和矩阵中的每一个元素进行计算,这将相当于一个全连接层,其中隐层的单元只有一个。为了便于理解,这里我用图来展示:

在理解了11的卷积之后,我们不妨可以想到,如果我们使用11的卷积对输入矩阵进行卷积,这就相当于做了全连接的操作。并且不会破坏输入的四个维度,相当于输出的结果的维度为(Batch_size,channels,heigh,width)。
所以,在这里我们使用1*1的卷积对于原来的全连接进行替换,新的结构成为NIN神经网络。变换过程如下图所示:
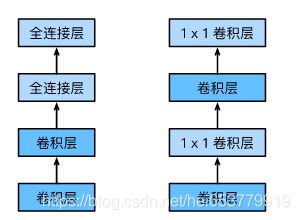
1.2 代码实现
#encoding=utf-8
import time
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from utils import Flatten
from utils import load_data
from utils import train
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def nin_block(input_channels,output_channels,kernel_size,stride,padding):
blk = nn.Sequential(nn.Conv2d(input_channels,output_channels,kernel_size,stride,padding),
nn.ReLU(),
nn.Conv2d(output_channels,output_channels,kernel_size=1),
nn.ReLU(),
nn.Conv2d(output_channels,output_channels,kernel_size=1),
nn.ReLU())
return blk
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d,self).__init__()
def forward(self,x):
return F.avg_pool2d(x,kernel_size = x.size()[2:])
net = nn.Sequential(
nin_block(1,96,kernel_size=11,stride=4,padding=0),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(96,256,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(256,384,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Dropout(0.5),
nin_block(384,10,kernel_size=5,stride=1,padding=2),
GlobalAvgPool2d(),
Flatten()
)
batch_size = 128
train_iter,test_iter = load_data(batch_size,resize=224)
lr,num_epochs = 0.002,5
optimizer = optim.Adam(net.parameters(),lr=lr)
if __name__ == '__main__':
train(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs=5)
#X = torch.rand(10,1,224,224)
#x = net(X)
2 GoogleNet
2.1 基本思路
Google也是一个非常具有代表性的神经网络结构。在GoogleNet 中使用了Inception模块,与上面的NIN块相比,这种模块的结构更加的复杂,如下面的图所示:
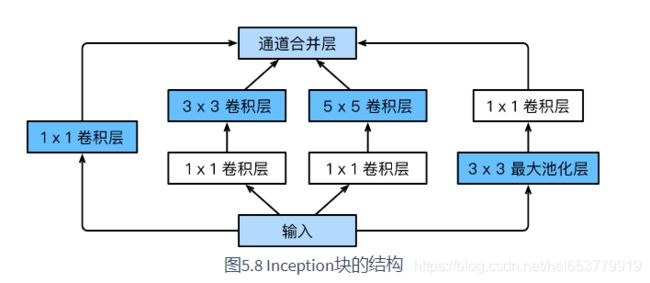
根据上图所示,整个Inception模块中包含四条并行的线路,最后在通道的位置对四条线路的输出进行合并。通过多个Interception模块的堆叠,最后构造整个GoogleNet网络。
2.2 代码实现
#encoding=utf-8
import torch
import torch.nn as nn
import time
import torch.optim as optim
import torch.nn.functional as F
from utils import GlobalAvgPool2d
from utils import Flatten
device = ('cuda' if torch.cuda.is_available() else 'cpu')
## Inception块实现
class Inceprion(nn.Module):
def __init__(self,in_channel,part_one_channel,part_two_channels,part_three_channels,part_four_channel):
super(Inceprion,self).__init__()
self.part_one = nn.Conv2d(in_channel,part_one_channel,kernel_size=1)
self.part_two_1 = nn.Conv2d(in_channel,part_two_channels[0],kernel_size=1)
self.part_two_2 = nn.Conv2d(part_two_channels[0],part_two_channels[1],kernel_size=3,padding=1)
self.part_three_1 = nn.Conv2d(in_channel,part_three_channels[0],kernel_size=1)
self.part_three_2 = nn.Conv2d(part_three_channels[0],part_three_channels[1],kernel_size=5,padding=2)
self.part_four_1 = nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
self.part_four_2 = nn.Conv2d(in_channel,part_four_channel,kernel_size=1)
def forward(self,x):
x_1 = F.relu(self.part_one(x))
x_2 = F.relu(self.part_two_2(F.relu(self.part_two_1(x))))
x_3 = F.relu(self.part_three_2(F.relu(self.part_three_1(x))))
x_4 = F.relu(self.part_four_2(self.part_four_1(x)))
return torch.cat((x_1,x_2,x_3,x_4),dim=1)
## GoogleNet模块搭建
block_1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
block_2 = nn.Sequential(nn.Conv2d(64,64,kernel_size=1),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
block_3 = nn.Sequential(Inceprion(192,64,(92,128),(16,32),32),
Inceprion(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
block_4 = nn.Sequential(Inceprion(480, 192, (96, 208), (16, 48), 64),
Inceprion(512, 160, (112, 224), (24, 64), 64),
Inceprion(512, 128, (128, 256), (24, 64), 64),
Inceprion(512, 112, (144, 288), (32, 64), 64),
Inceprion(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
block_5 = nn.Sequential(Inceprion(832,256,(160,320),(32,128),128),
Inceprion(832, 384, (192, 384), (48, 128), 128),
GlobalAvgPool2d())
net = nn.Sequential(block_1,block_2,block_3,block_4,block_5,Flatten(),nn.Linear(1024,10))
if __name__ == '__main__':
X = torch.rand(1,1,96,96)
for blk in net.children():
X = blk(X)
print('output shape: ',X.shape)
3 总结
本文主要回顾了NIN模块的基本思路实现和GoogleNet的的基本思路和实现。这里没有给出具体的计算公式推导,感兴趣的读者可以参考其他的文章。
4 参考
- 动手学习深度学习—pytorch版