谈Inception V1网络结构 与 GoogLeNet
谈Inception网络结构 与 GoogLeNet
- 1 x 1 卷积核
- Inception V1
- 多个尺寸上进行卷积再聚合
- 参考文章
1 x 1 卷积核
此观点是在 Network in Network(NIN)中提出,那这样的卷积有什么用处呢?先回顾下相关基础概念吧~
卷积核: 可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有1x1 , 3x3 和 5x5的尺寸(一般是奇数x奇数)
下面通过吴恩达老师的课件,对1 x 1卷积运算的理解。例如对于如下的二维矩阵,做卷积,相当于直接乘以2
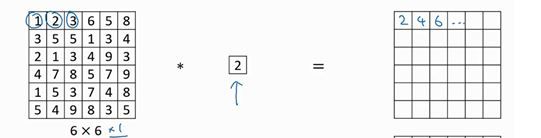
对于三维矩阵,用 1 x 1 卷积核做卷积
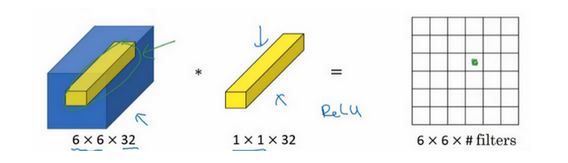
如上图,如果是一张6×6×32的图片,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。当有多个过滤器时,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6过滤器数量。
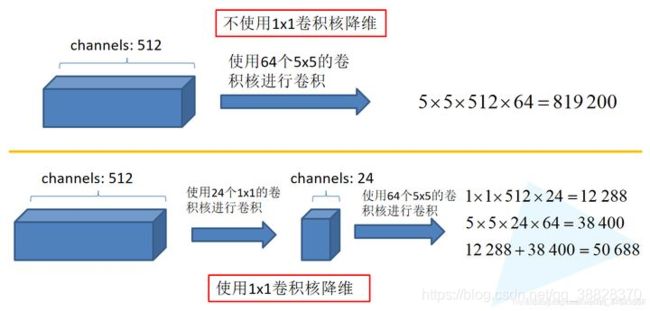
当设置多个1*1filter时,可以起到一个跨通道聚合的作用,所以进一步就可以随意增减输出的通道数,也就是降维(或升维),起到减少参数的目的。

1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为 n C [ l + 1 ] n_C^{[l+1]} nC[l+1],在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量)
Tips:用卷积核实现全连接层,可以康康这篇文章 【机器学习】关于CNN中1×1卷积核和Network in Network的理解
综上, 1 x 1卷积核的作用:
-
降维,降低了计算复杂度
但 1×1 并没改变输出的宽度和高度
-
增加非线性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数,如ReLU),把网络做的很深 -
跨通道信息交互【这点没搞懂】
使用1x1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3x3,64 channels的卷积核后面添加一个1x1x28 channels的卷积核,就变成了3x3x28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28 channels,这就是通道间的信息交互
注:新手不太懂,如有错误,请指出,互相交流学习加油
或许可以再看看 这篇 1X1卷积核到底有什么作用呢?
卷积过程,咱们看下这个动画,加深下:

大致理解了 1 x 1 卷积核,接下来学习下 Inception模块。
Inception历经了V1、V2、V3、V4等多个版本的发展,不断趋于完善
Inception V1
在Inception模块未出现时,绝大部分的神经网络都是 卷积层 + 池化层 的顺序连接,最后再加上 全连接层,主要通过增加网络深度和宽度提高精度(如VGG),这也导致了参数量大,过拟合等问题。
Google最开始提出的原始Inception网络结构如下图:

那通过设计该稀疏网络结构,但能产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。【通过使用不同的卷积核,达到在同一层就可以提取到稀疏(3x3,5x5)、不稀疏(1x1)的特征,牛掰,666】
我们可以看到该结构将常用的卷积核(1x1 , 3x3 , 5x5【当然尺寸可根据实际情况适当调整】)和池化操作堆叠一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
通过池化操作减少空间大小,降低过度拟合。并且在这些层之上,在每一个卷积层后都要做一个ReLU操作,以增加网络的非线性特征。借用吴恩达老师深度学习课程的图:
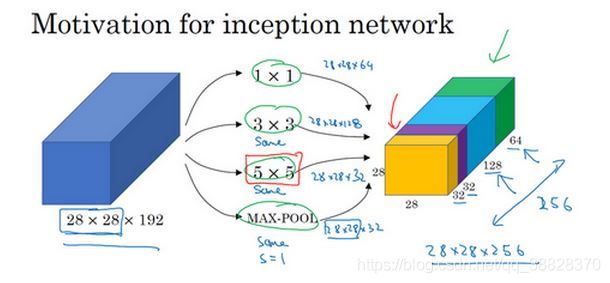
该原始版本,所有的卷积核都在上一层的所有输出上进行卷积,导致5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大。为了改善这种现象,借鉴Network-in-Network的思想,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,使用1x1的卷积核实现降维操作(也间接增加了网络的深度),以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络结构,如下图所示:
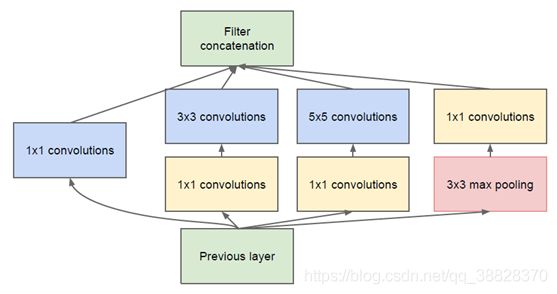
多个尺寸上进行卷积再聚合
本节来自 [深入理解GoogLeNet结构(原创)
上图可以看到对输入做了4个分支,分别用不同尺寸的filter进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构有什么好处呢?Szegedy从多个角度进行了解释:
- 解释1:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
- 解释2:利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
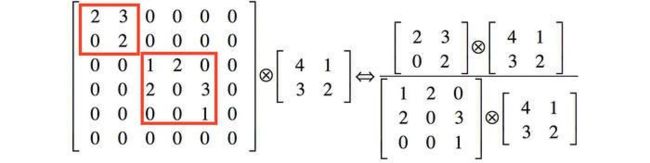
举个例子下图左侧是个稀疏矩阵(很多元素都为0,不均匀分布在矩阵中),和一个2x2的矩阵进行卷积,需要对稀疏矩阵中的每一个元素进行计算;如果像右图那样把稀疏矩阵分解成2个子密集矩阵,再和2x2矩阵进行卷积,稀疏矩阵中0较多的区域就可以不用计算,计算量就大大降低。这个原理应用到inception上就是要在特征维度上进行分解! 传统的卷积层的输入数据只和一种尺度(比如3x3)的卷积核进行卷积,输出固定维度(比如256个特征)的数据,所有256个输出特征基本上是均匀分布在3x3尺度范围上,这可以理解成输出了一个稀疏分布的特征集;而inception模块在多个尺度上提取特征(比如1x1,3x3,5x5),输出的256个特征就不再是均匀分布,而是相关性强的特征聚集在一起(比如1x1的的96个特征聚集在一起,3x3的96个特征聚集在一起,5x5的64个特征聚集在一起),这可以理解成多个密集分布的子特征集。这样的特征集中因为相关性较强的特征聚集在了一起,不相关的非关键特征就被弱化,同样是输出256个特征,inception方法输出的特征“冗余”的信息较少。用这样的“纯”的特征集层层传递最后作为反向计算的输入,自然收敛的速度更快。
- 解释3:Hebbin赫布原理。 Hebbin原理是神经科学上的一个理论,解释了在学习的过程中脑中的神经元所发生的变化,用一句话概括就是fire togethter, wire together。赫布认为“两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋”。比如狗看到肉会流口水,反复刺激后,脑中识别肉的神经元会和掌管唾液分泌的神经元会相互促进,“缠绕”在一起,以后再看到肉就会更快流出口水。用在inception结构中就是要把相关性强的特征汇聚到一起。这有点类似上面的解释2,把1x1,3x3,5x5的特征分开。因为训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用。
基于Inception构建了GoogLeNet的网络结构如下(共22层):

对上图说明如下:
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
参考文章
- 一文读懂卷积神经网络中的1x1卷积核
- 大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
- 卷积神经网络结构简述(二)Inception系列网络
- 【模型解读】Inception结构,你看懂了吗
- 从Inception到Xception,卷积方式的成长之路!
- 深入理解GoogLeNet结构(原创)