PyTorch搭建LSTM实现服装分类(FashionMNIST)
FashionMNIST 数据集官网:https://github.com/zalandoresearch/fashion-mnist.
这里不再介绍该数据集,如需了解请前往官网。
思路: 数据集中的每张图片都是尺寸为 ( 28 , 28 ) (28,28) (28,28) 的灰度图。我们可以将其看作 28 × 28 28\times28 28×28 的数字矩阵,将该矩阵按行进行逐行分块可得一个长度为 28 28 28 的序列,且序列中的每个 “词元” 对应的特征维数也是 28 28 28。
运行环境:
- 系统:Ubuntu 20.04;
- GPU:RTX 3090;
- Pytorch:1.11;
- Python:3.8
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
# Data Preprocessing
train_data = torchvision.datasets.FashionMNIST(root='data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.FashionMNIST(root='data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True, num_workers=4)
test_loader = DataLoader(test_data, batch_size=64, num_workers=4)
# Model building
class LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(28, 64, num_layers=2)
self.linear = nn.Linear(64, 10)
def forward(self, x):
output, (h_n, c_n) = self.lstm(x, None)
return self.linear(h_n[0])
def setup_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# Setup
setup_seed(42)
NUM_EPOCHS = 20
LR = 4e-3
train_loss, test_loss, test_acc = [], [], []
device = 'cuda' if torch.cuda.is_available() else 'cpu'
lstm = LSTM()
lstm.to(device)
critertion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lstm.parameters(), lr=LR)
# Training and testing
for epoch in range(NUM_EPOCHS):
print(f'[Epoch {epoch + 1}]', end=' ')
avg_train_loss, avg_test_loss, correct = 0, 0, 0
# train
lstm.train()
for batch_idx, (X, y) in enumerate(train_loader):
# (64, 1, 28, 28) -> (28, 64, 28)
X = X.squeeze().movedim(0, 1)
X, y = X.to(device), y.to(device)
# forward
output = lstm(X)
loss = critertion(output, y)
avg_train_loss += loss
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_train_loss /= (batch_idx + 1)
train_loss.append(avg_train_loss.item())
# test
lstm.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(test_loader):
X = X.squeeze().movedim(0, 1)
X, y = X.to(device), y.to(device)
pred = lstm(X)
loss = critertion(pred, y)
avg_test_loss += loss
correct += (pred.argmax(1) == y).sum().item()
avg_test_loss /= (batch_idx + 1)
test_loss.append(avg_test_loss.item())
correct /= len(test_loader.dataset)
test_acc.append(correct)
print(
f"train loss: {train_loss[-1]:.4f} | test loss: {test_loss[-1]:.4f} | test acc: {correct:.4f}"
)
# Plot
x = np.arange(1, 21)
plt.plot(x, train_loss, label="train loss")
plt.plot(x, test_loss, label="test loss")
plt.plot(x, test_acc, label="test acc")
plt.xlabel("epoch")
plt.legend(loc="best", fontsize=12)
plt.show()
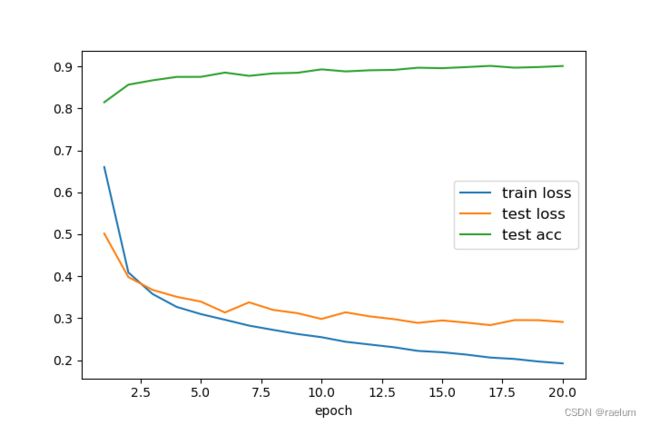
输出结果:
[Epoch 1] train loss: 0.6602 | test loss: 0.5017 | test acc: 0.8147
[Epoch 2] train loss: 0.4089 | test loss: 0.3979 | test acc: 0.8566
[Epoch 3] train loss: 0.3577 | test loss: 0.3675 | test acc: 0.8669
[Epoch 4] train loss: 0.3268 | test loss: 0.3509 | test acc: 0.8751
[Epoch 5] train loss: 0.3098 | test loss: 0.3395 | test acc: 0.8752
[Epoch 6] train loss: 0.2962 | test loss: 0.3135 | test acc: 0.8854
[Epoch 7] train loss: 0.2823 | test loss: 0.3377 | test acc: 0.8776
[Epoch 8] train loss: 0.2720 | test loss: 0.3196 | test acc: 0.8835
[Epoch 9] train loss: 0.2623 | test loss: 0.3120 | test acc: 0.8849
[Epoch 10] train loss: 0.2547 | test loss: 0.2981 | test acc: 0.8931
[Epoch 11] train loss: 0.2438 | test loss: 0.3140 | test acc: 0.8882
[Epoch 12] train loss: 0.2372 | test loss: 0.3043 | test acc: 0.8909
[Epoch 13] train loss: 0.2307 | test loss: 0.2977 | test acc: 0.8918
[Epoch 14] train loss: 0.2219 | test loss: 0.2888 | test acc: 0.8970
[Epoch 15] train loss: 0.2187 | test loss: 0.2946 | test acc: 0.8959
[Epoch 16] train loss: 0.2132 | test loss: 0.2894 | test acc: 0.8985
[Epoch 17] train loss: 0.2061 | test loss: 0.2835 | test acc: 0.9014
[Epoch 18] train loss: 0.2028 | test loss: 0.2954 | test acc: 0.8971
[Epoch 19] train loss: 0.1966 | test loss: 0.2952 | test acc: 0.8986
[Epoch 20] train loss: 0.1922 | test loss: 0.2910 | test acc: 0.9011
相应的曲线:
一些心得 :
- 切勿直接使用
X = X.reshape(28, -1, 28),否则X对应的将不是原来的图片(读者可自行尝试使用torchvision.transforms.ToPILImage去输出X对应的图片观察效果)。 - 学习率相同的情况下,SGD 的效果没有 Adam 好。