动图+独家思维导图!让你秒懂李宏毅2020深度学习(四)—— CNN(Convolutional Neural network)
动图+独家思维导图!让你秒懂李宏毅2020深度学习(四)—— CNN(Convolutional Neural network)
系列文章传送门:
文章目录
- 动图+独家思维导图!让你秒懂李宏毅2020深度学习(四)—— CNN(Convolutional Neural network)
- CNN(Convolutional Neural Network)
-
- Three Property for CNN theory base
- 一张图搞定CNN(必看干货!)
- 动图演示
- What does CNN learn?
-
- what does filter do
- what does neuron do
- what about output
CNN(Convolutional Neural Network)
前面我们介绍了Fully Connect Feedforward Network(全连接前馈⽹络),但是这种网络在运用到图像处理的时候,往往需要太多参数,因此进化出了CNN(Convolutional Neural network)来简化NN的架构,拿掉Fully Connected 的layer中的一些参数。
那怎么简化呢?这里提炼出CNN简化的三个property
Three Property for CNN theory base
- Property1: Some patterns are much smaller than the whole image
- Property2: The same patterns appear in different regions
- Property3: Subsampling the pixels will not change the object
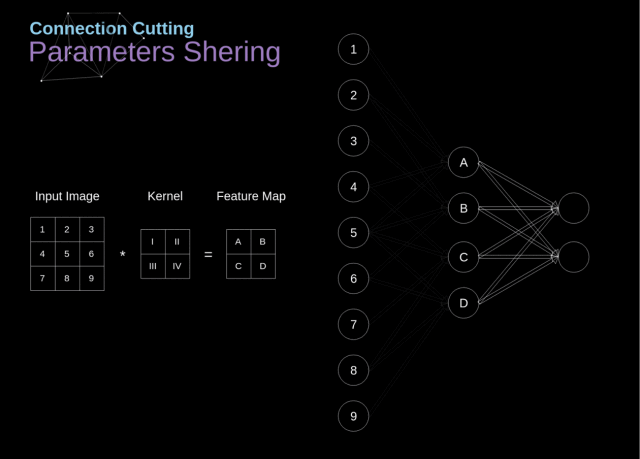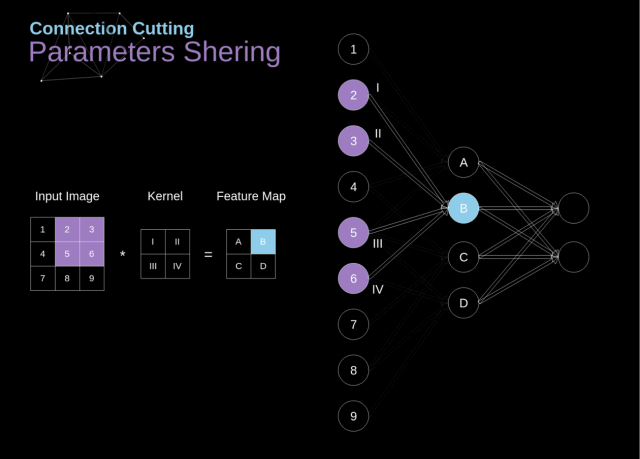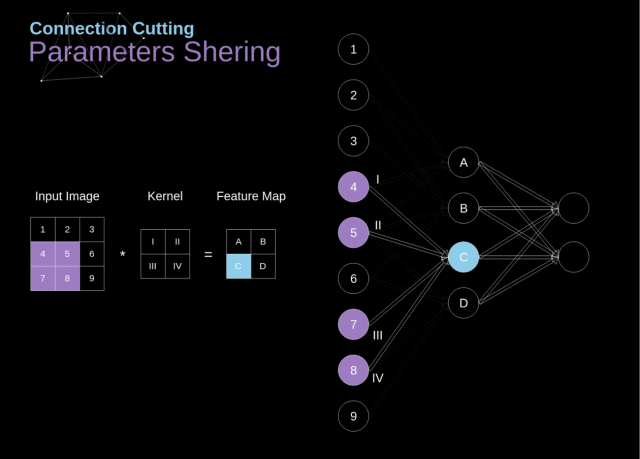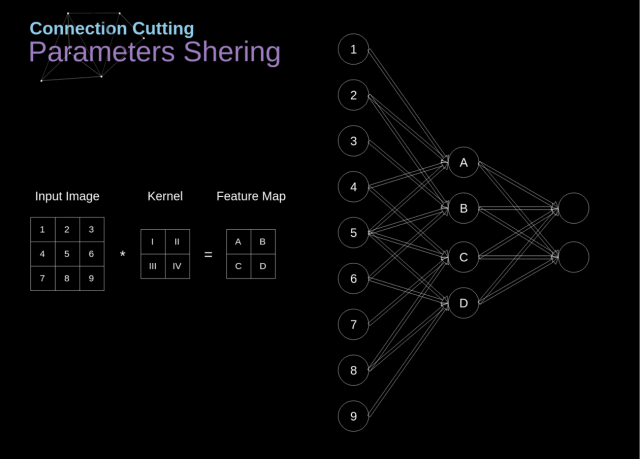
一张图搞定CNN(必看干货!)
博主花了许多心血将CNN的整个结构浓缩在这一张图中:
动图演示
由此可以看出CNN的本质就是就是减少参数的过程,如果对上面的某些过程还不了解,下面给出一些网络上博主认为比较好的动图供大家理解
1.卷积过程动图
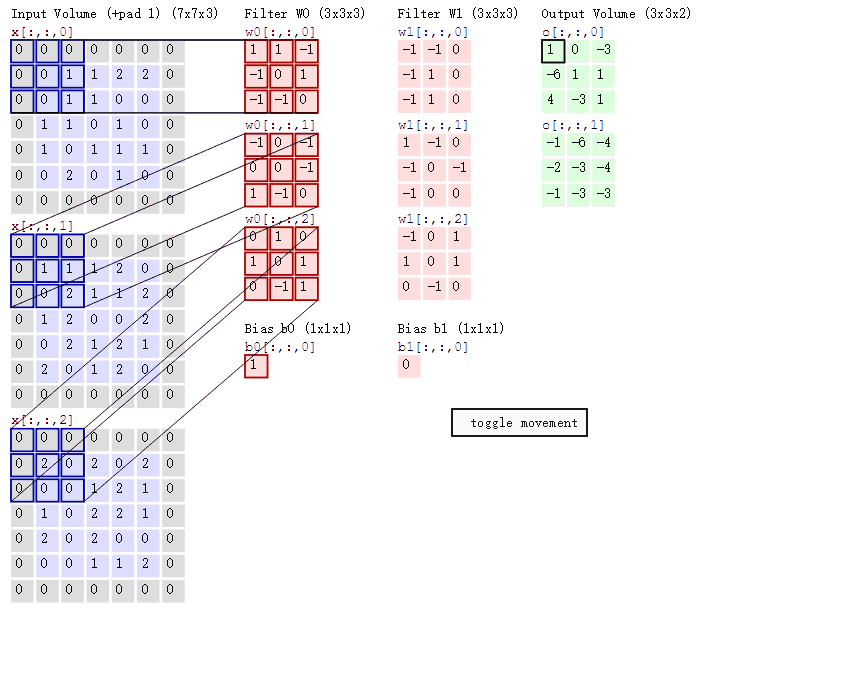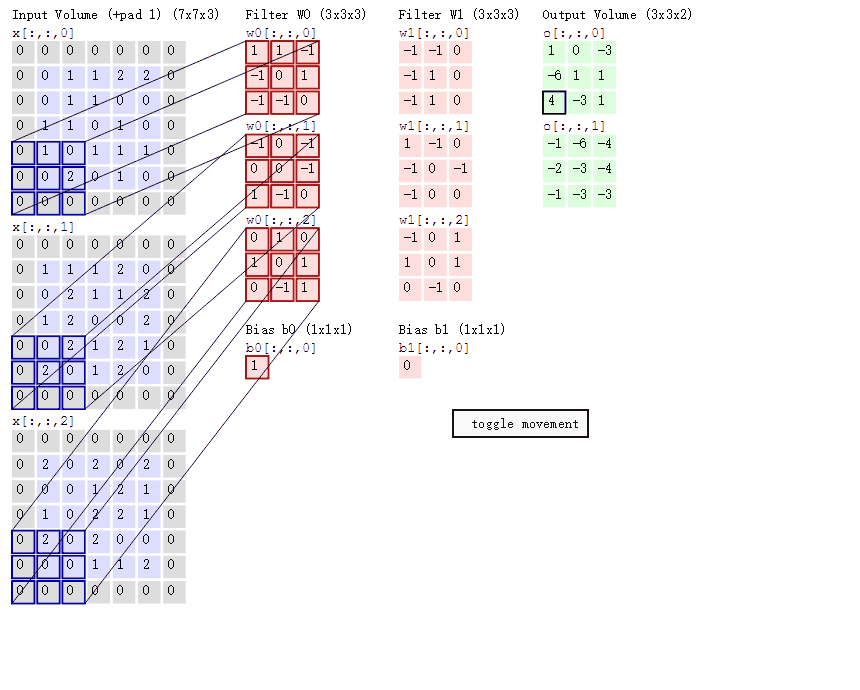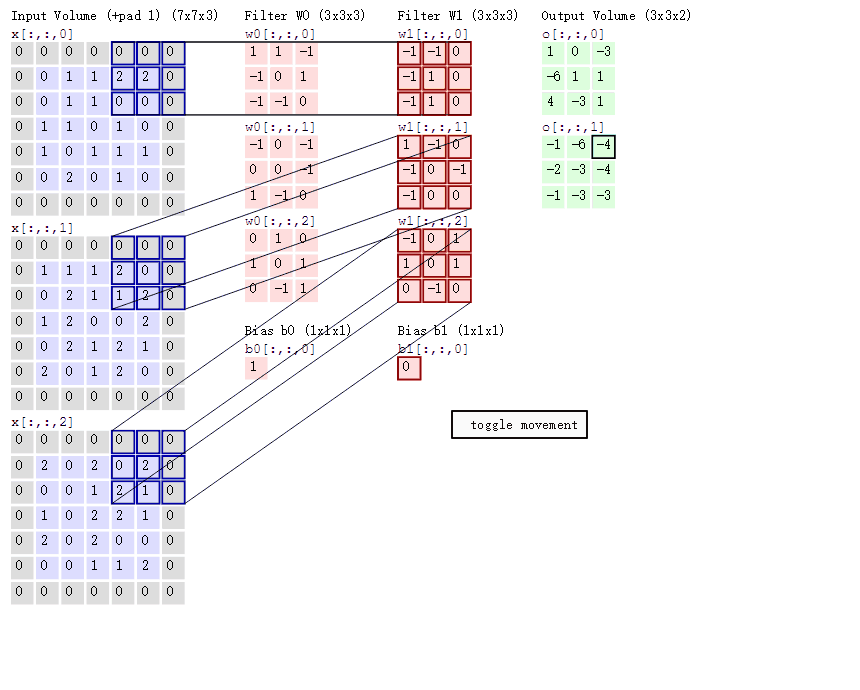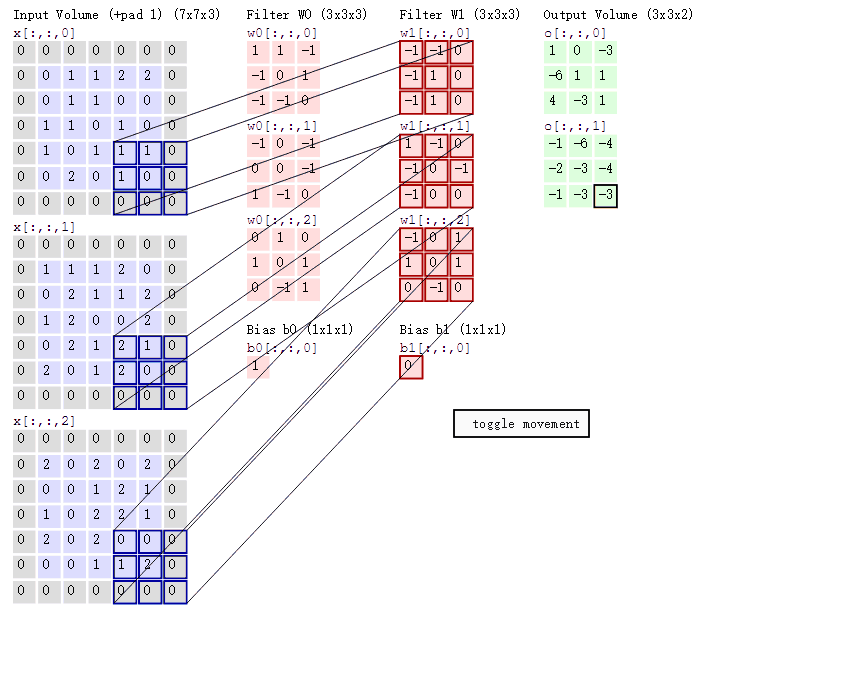
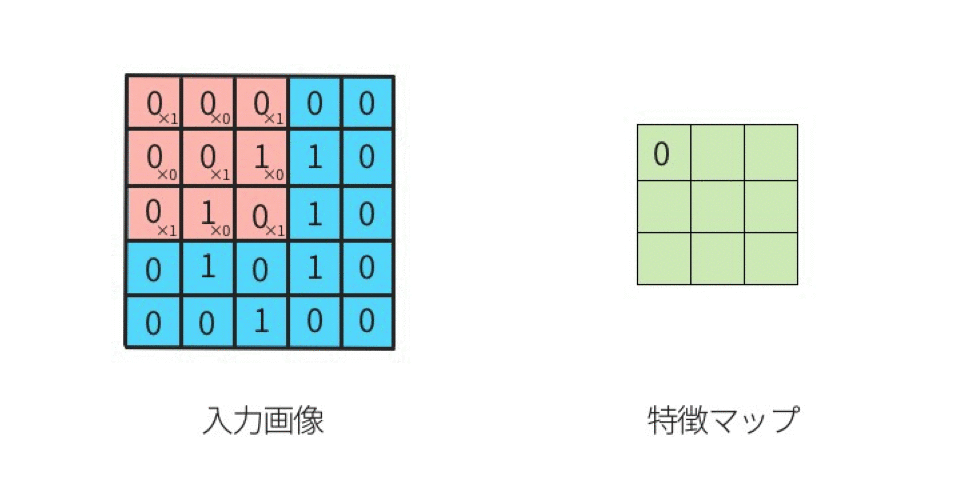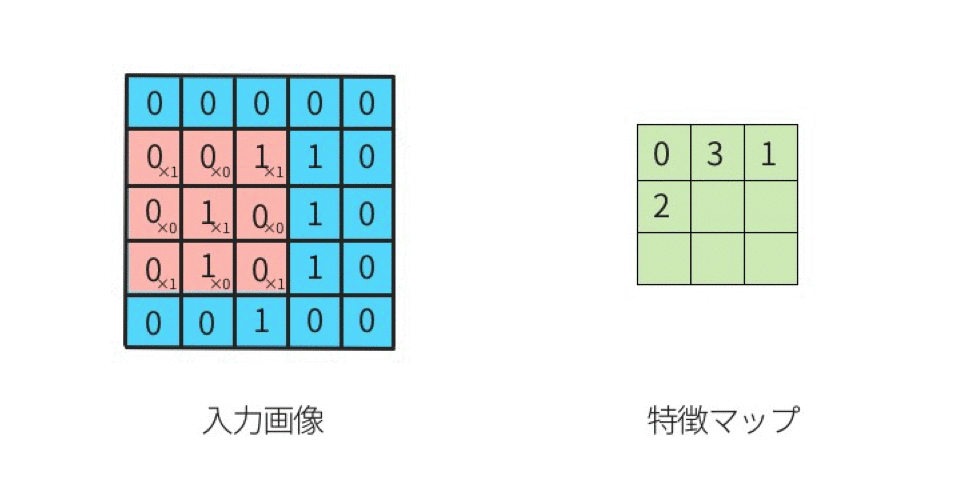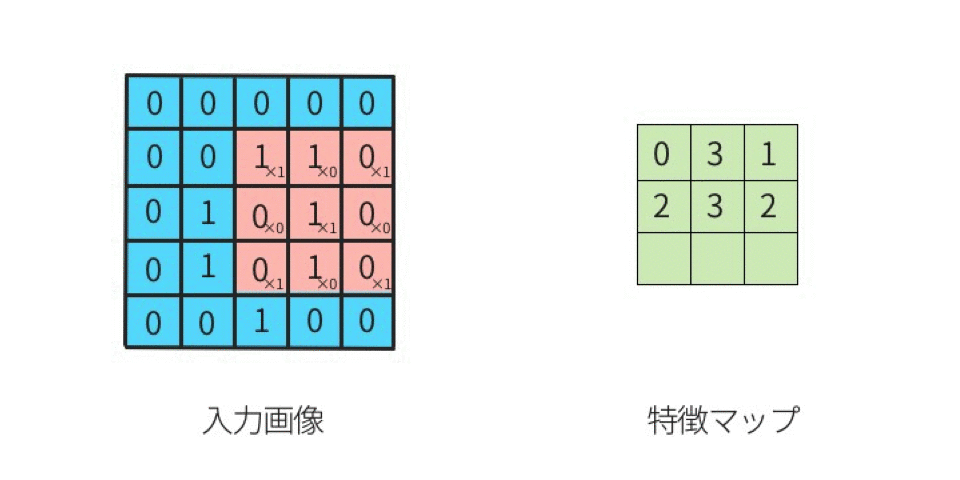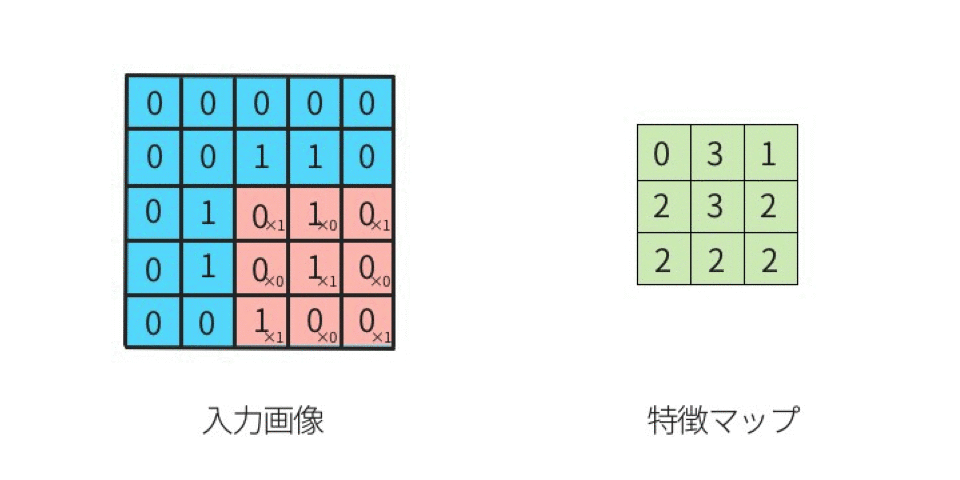

2.卷积的计算
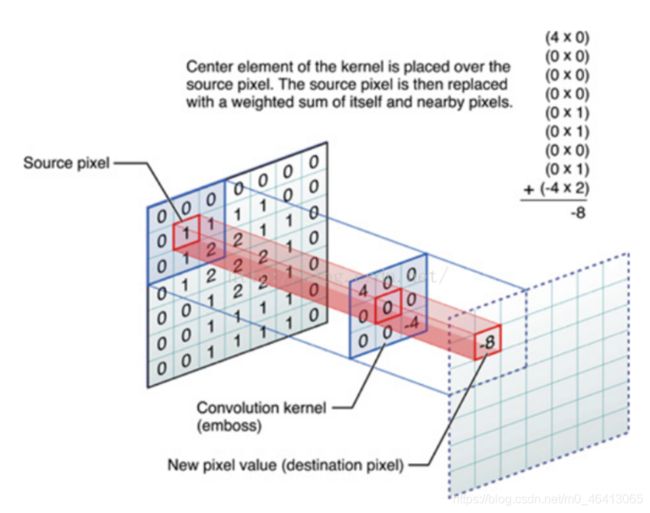
3.卷积对应于神经网络计算的动图
4.池化动图

What does CNN learn?
刚刚介绍了CNN的结构,接下来我们来分析下CNN的每一层到底学到了什么
以下图CNN为例:

先描述下图中所描述的过程:
- 假设我们input是⼀个1×28×28的image
- 通过25个filter的convolution layer以后你得到的output,会有25个channel,⼜因为filter的size是3×3,因此如果不考虑image边缘处的处理的话,得到的channel会是(28-2)×(28-2)的,因此通过第⼀个convolution得到25×26×26的cubic image(这⾥把这张image想象成⻓宽为26,⾼为25的cubic⽴⽅体)
- 接下来就是做Max pooling,把2×2的pixel分为⼀组,然后从⾥⾯选⼀个最⼤的组成新的image,⼤⼩为25×13×13(cubic⻓宽各被砍掉⼀半)
- 再做⼀次convolution,假设这次选择50个filter,每个filter size是25×3×3的话,output的channel就变成有50个,那13×13的image,通过3×3的filter,就会变成(13-2)×(13-2),因此通过第⼆个convolution得到50×11×11的image(得到⼀个新的⻓宽为11,⾼为50的cubic)
- 再做⼀次Max Pooling,变成50×50×5
要分析第⼀个convolution的filter是⽐较容易的,因为第⼀个convolution layer⾥⾯,每⼀个filter就是
⼀个3×3的matrix,它对应到3×3范围内的9个pixel,所以你只要看这个filter的值,就可以知道它在detect什么东西,因此第⼀层的filter是很容易理解的。
但是你⽐较没有办法想像它在做什么事情的,是第⼆层的filter,它们是50个同样为3×3的filter,但是这些filter的input并不是pixel,⽽是做完convolution再做Max pooling的结果,因此filter考虑的范围并不是3×3=9个pixel,⽽是⼀个⻓宽为3×3,⾼为25的cubic(这里的高指channel),filter实际在image上看到的范围是远⼤于9个pixel的,所以你就算把它的weight拿出来,也不知道它在做什么。
what does filter do
来分析⼀个filter它做的事情:
我们把经过convolution layer中第k个filter卷积出来的matrix中的每一个element, 我们叫它 a i j k a_{ij}^{k} aijk上标k表⽰这是第k个filter,下标ij表⽰它在这个matrix⾥的第i个row,第j个column接下来我们define⼀个 a k a^{k} ak叫做Degree of the activation of the k-th filter,这个值表⽰现在的第k个filter,它有多被activate,有多被“启动”,直观来讲就是描述现在input的东西跟第k个filter有多接近, 它对filter的激活程度有多少
第k个filter被启动的degree a k a^{k} ak就定义成,它与input进⾏卷积所输出的output⾥所有element的summation,以上图为例,就是这11×11的output matrix⾥所有元素之和,⽤公式描述如下:
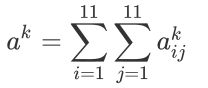
即我们input⼀张image,然后把filter和image进⾏卷积所output的11×11个值全部加起来,当作现在这个filter被activate的程度
接下来我们要做的事情是这样⼦,我们想要知道第k个filter的作⽤是什么,那我们就要找⼀张image, 这张image可以让第k个filter被activate的程度最⼤;于是我们现在要解的问题是,找⼀个image x,它可以让我们定义的activation的degree a k a^{k} ak最⼤,即:

之前我们求minimize⽤的是gradient descent,那现在我们求Maximum⽤gradient ascent(梯度上升法)就可以做到这件事了
即把input x作为要找的参数,对它去⽤gradient ascent进⾏update,原来在train CNN的时候,input是固定的,model的参数是要⽤gradient descent去找出来的;但是现在这个⽴场是反过来的,在这个task⾥⾯model的参数是固定的,我们要⽤gradient ascent去update这个x,让它可以使degree of activation最⼤

上图就是得到的结果,50个filter理论上可以分别找50张image使对应的activation最⼤,这⾥仅挑选了其中的12张image作为展⽰,这些image有⼀个共同的特征,它们⾥⾯都是⼀些反复出现的某种texture(纹路),⽐如说第三张image上布满了⼩⼩的斜条纹,这意味着第三个filter的⼯作就是detect图上有没有斜条纹,要知道现在每个filter检测的都只是图上⼀个⼩⼩的范围⽽已,所以图中⼀旦出现⼀个⼩⼩的斜条纹,这个filter就会被activate,相应的output也会⽐较⼤,所以如果整张image上布满这种 斜条纹的话,这个时候它会最兴奋,filter的activation程度是最⼤的,相应的output值也会达到最⼤
因此每个filter的⼯作就是去detect某⼀种pattern,detect某⼀种线条,上图所⽰的filter所detect的就是不同⻆度的线条,所以今天input有不同线条的话,某⼀个filter会去找到让它兴奋度最⾼的匹配对象,这个时候它的output就是最⼤的
what does neuron do
我们做完convolution和max pooling之后,会将结果⽤Flatten展开,然后丢到Fully connected的neural network⾥⾯去,之前已经搞清楚了filter是做什么的,那我们也想要知道在这个neural network⾥的每⼀个neuron是做什么的,所以就对刚才的做法如法炮制

我们定义第j个neuron的output就是 ,接下来就⽤gradient ascent的⽅法去找⼀张image x,把它丢到neural network⾥⾯就可以让 的值被maximize,即:
![]()
找到的结果如上图所⽰,同理这⾥仅取出其中的9张image作为展⽰,你会发现这9张图跟之前filter所观察到的情形是很不⼀样的,刚才我们观察到的是类似纹路的东西,那是因为每个filter考虑的只是图上⼀部分的vision,所以它detect的是⼀种texture;但是在做完Flatten以后,每⼀个neuron不再是只看整 张图的⼀⼩部分,它现在的⼯作是看整张图,所以对每⼀个neuron来说,让它最兴奋的、activation最⼤的image,不再是texture,⽽是⼀个完整的图形
what about output
接下来我们考虑的是CNN的output,由于是⼿写数字识别的demo,因此这⾥的output就是10维,我们把某⼀维拿出来,然后同样去找⼀张image x,使这个维度的output值最⼤,即
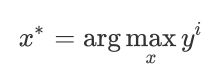
你可以想象说,既然现在每⼀个output的每⼀个dimension就对应到⼀个数字,那如果我们去找⼀张image x,它可以让对应到数字1的那个output layer的neuron的output值最⼤,那这张image显然应该看起来会像是数字1,你甚⾄可以期待,搞不好⽤这个⽅法就可以让machine⾃动画出数字。
但实际上,我们得到的结果是这样⼦,如下图所⽰

上⾯的每⼀张图分别对应着数字0-8,你会发现,可以让数字1对应neuron的output值最⼤的image其 实⻓得⼀点也不像1,就像是电视机坏掉的样⼦,为了验证程序有没有bug,这⾥⼜做了⼀个实验,把上述得到的image真的作为testing data丢到CNN⾥⾯,结果classify的结果确实还是认为这些image就对应着数字0-8
所以今天这个neural network,它所学到的东西跟我们⼈类⼀般的想象认知是不⼀样的
那我们有没有办法,让上⾯这个图看起来更像数字呢?想法是这样的,我们知道⼀张图是不是⼀个数字,它会有⼀些基本的假设,⽐如这些image,你不知道它是什么数字,你也会认为它显然就不是⼀个digit,因为⼈类⼿写出来的东西就不是⻓这个样⼦的,所以我们要对这个x做⼀些regularization,我们要对找出来的x做⼀些constraint(限制约束),我们应该告诉machine说,虽然有⼀些x可以让你的y很⼤,但是它们不是数字
那我们应该加上什么样的constraint呢?最简单的想法是说,画图的时候,⽩⾊代表的是有墨⽔、有笔画的地⽅,⽽对于⼀个digit来说,整张image上涂⽩的区域是有限的,像上⾯这些整张图都是⽩⽩的, 它⼀定不会是数字
假设image⾥的每⼀个pixel都⽤ x i j {x_{ij}} xij表⽰,我们把所有pixel值取绝对值并求和,这⼀项其实就是之前提到过的L1的regularization,再⽤ y i {y^i} yi减去这⼀项,得到

这次我们希望再找⼀个input x,它可以让 y i {y^i} yi最⼤的同时,也要让 ∣ x i j ∣ {|x_{ij}|} ∣xij∣的summation越⼩越好,也就是说我们希望找出来的image,⼤部分的地⽅是没有涂颜⾊的,只有少数数字笔画在的地⽅才有颜⾊出现,加上这个constraint以后,得到的结果会像下图右侧所⽰⼀样,已经隐约有些可以看出来是数字的形状了
如果再加上⼀些额外的constraint,⽐如你希望相邻的pixel是同样的颜⾊等等,应该可以得到更好的结果