pytorch学习笔记(六)——pytorch中搭建神经网络
目录
- 一、神经网络基本骨架搭建nn.module
-
- nn.Module的使用
- 二、神经网络中一些神经结构的使用
-
- 1. Convolution Layers 卷积层
-
- (1) 卷积操作示例
- (2) 用代码验证上述卷积操作的正确性(使用F.conv2d)
- (3) 卷积层nn.Conv2d的使用
- (4) 理解卷积层nn.Conv2d的各个参数
- (5) torch.nn.conv2d和torch.nn.functional.conv2d的区别
- 2. Pooling layers池化层
-
- (1) 最大池化层的理解
- (2) 最大池化层作用
- (3) 用pytorch搭建一个最大池化层
- 3. Non-linear Activations非线性激活
-
- 以ReLU为例
- 4. Linear Layer线性层
- 三、搭建一个简单的分类的神经网络
-
- 以CIFAR10数据集为例
- 四、torch.nn中的 Loss Functions损失函数
-
- 1. Loss作用
- 2. 几个Loss的简单用法
- 3. 在自写的神经网络中使用Loss Function
- 五、优化器 torch.optim
-
- 以随机梯度下降SGD优化器为例
- 六、神经网络完整的模型训练和测试套路
一、神经网络基本骨架搭建nn.module
- 神经网络(Nueral Networks) 是由对数据进行操作的一些 层(layer) 或 模块(module) 所组成,而PyTorch 中的每个模块都是 nn.Module 的子类,在调用或自定义时均需继承 nn.Module 类。
同时 torch.nn 包为我们提供了构建神经网络所需的各种模块,当然一个神经网络本身也是一个由其他 模块/层 组成的模块,这种嵌套结构就允许我们构建更为复杂的网络架构。 - 关于神经网络的工具主要在torch.nn里面,nn即neural network
torch.nn的官网API
在开始搭建神经网络之前先了解下 torch.nn 包,它包含了用于搭建神经网络的所有基础模块,其中有些是经常使用的,如卷积层、池化层、激活函数、损失函数等等

nn.Module的使用
import torch
from torch import nn
# 自己搭建的神经网络必须从nn.Module类中继承
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
# 定义了神经网络要做的前向传播的操作 (前向传播就是从输入到输出),应该在所有的子类中都进行重写
def forward(self, input_num):
output_num = input_num + 1
return output_num
# 以Model为模板创建出的一个神经滚网络neural
neural = Model()
x = torch.tensor(1.0)
# nn.Module中的__call__中调用了forward方法
output = neural(x)
print(output)
二、神经网络中一些神经结构的使用
1. Convolution Layers 卷积层
(1) 卷积操作示例
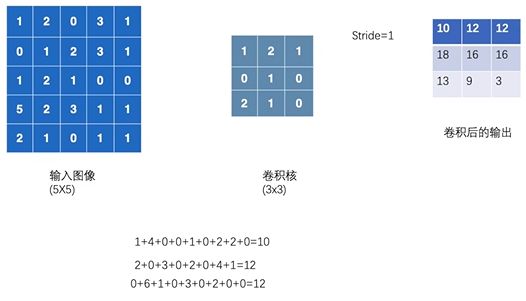
(2) 用代码验证上述卷积操作的正确性(使用F.conv2d)
import torch
import torch.nn.functional as F
# 1.定义输入图像
input_matrix = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 2.定义卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 3.使用pytorch提供的尺寸变换,使输入数据满足卷积函数的输入(N, C, H, W) or (C, H, W),
# 其中N就是batch_size也就是输入图片的数量,C就是通道数而这里的只是一个二维张量所以通道为1,H就是高,W宽,所以是1155
input_matrix = torch.reshape(input_matrix, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input_matrix.shape)
# 4.使用卷积函数
# conv2d:对由多个输入平面组成的输入信号进行二维卷积
output_matrix = F.conv2d(input_matrix, kernel, stride=1)
print(output_matrix)
# stride为卷积操作每次移动的步径大小
output2 = F.conv2d(input_matrix, kernel, stride=2)
print(output2)
# padding:在输入图像的边缘是否进行填充(使卷积核能作用于输入图像的每一个像素点),填充后的空白处默认为0
output3 = F.conv2d(input_matrix, kernel, stride=1, padding=1)
print(output3)
(3) 卷积层nn.Conv2d的使用
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 1.读取CIFAR10数据集,并且放在dataloader中加载
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
# 2.搭建一个简单的神经网络 my_neural(以MyNeural为骨架搭建)
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# 定义一个卷积层名叫conv1
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
# 把x放入卷积层conv1中
x = self.conv1(x)
return x
my_neural = MyNeural()
writer = SummaryWriter("../logs")
step = 0
# 3.把dataloader中加载的每张图像放到神经网络中测试一下
for data in dataloader:
imgs, targets = data
# output即把dataloader中的数据放入神经网络中,经过神经网络中的forward中进行一个卷积操作,然后返回的输出
output = my_neural(imgs)
# torch.Size([64, 3, 32, 32])
print(imgs.shape)
# torch.Size([64, 6, 30, 30])
print(output.shape)
# 用tensorboard更直观的显示一下
writer.add_images("input", imgs, step)
# 注意这里,卷积后输出图像的通道为6,而彩色图像为channel=3是才能显示,所以需要对输出图像处理一下,
# 使[64, 6, 30, 30] -> [xx, 3, 30, 30],其中batch_size不知道写多少的时候就写-1它会进行计算
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
(4) 理解卷积层nn.Conv2d的各个参数

- in_channels:输入的通道数目 【必选】
- out_channels: 输出的通道数目 【必选】
- kernel_size:卷积核的大小,类型为int 或者元组,当卷积是方形的时候,只需要一个整数边长即可,卷积不是方形,要输入一个元组表示 高和宽。【必选】
- stride: 卷积每次滑动的步长为多少,默认是 1 【可选】
- padding: 设置在所有边界增加 值为 0 的边距的大小(也就是在feature map 外围增加几圈 0 ),例如当 padding =1 的时候,如果原来大小为 3 × 3 ,那么之后的大小为 5 × 5 。即在外围加了一圈 0 。【可选】
- dilation:指卷积核的元素之间是否有空是否紧挨着。默认dilation=1,当dilation>1时为空洞卷积
(5) torch.nn.conv2d和torch.nn.functional.conv2d的区别
转载自那记忆微凉的一篇文章
https://blog.csdn.net/BigData_Mining/article/details/103746548
2. Pooling layers池化层
(1) 最大池化层的理解
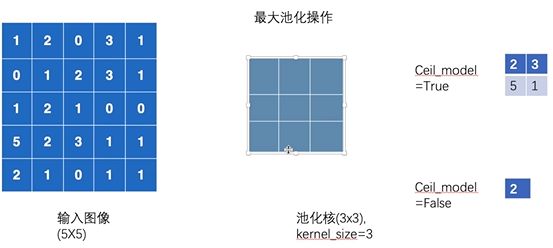
同卷积层⼀样,池化层每次对输⼊数据的⼀个固定形状窗⼝(⼜称池化窗⼝)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。该运算也分别叫做最大池化或平均池化。

(2) 最大池化层作用
为了在保留输入的特征同时把数据量减小,对于整个网络来说进行计算的参数就减少了,为了训练的更快(直观感受1080p池化之后720p,也能满足大多数需要,但是文件尺寸缩小了),马赛克行为
简要理解八个字:压缩数据保留特征
如图,经过池化前后的图片对比

(3) 用pytorch搭建一个最大池化层
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
# 1.获取输入数据
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# 2.构建神经网络
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
my_neural = MyNeural()
# 3.把输入数据放入含有一个池化层的神经网络中执行
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = my_neural(imgs)
writer.add_images("input", imgs, step)
# 池化不会改变通道
writer.add_images("output", output, step)
step = step + 1
writer.close()
3. Non-linear Activations非线性激活
以ReLU为例
import torch
# 1.定义输入数据
from torch import nn
from torch.nn import ReLU
input_matrix = torch.tensor([[1, -0.5],
[-1, 3]])
# 注意这里input一定要指定一个batch_size
input_matrix = torch.reshape(input_matrix, (-1, 1, 2, 2))
# 2.定义神经网络
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# ReLU()的参数inplace,若为true时,则改变后的值赋给原值;若为false,则原值不变,改变后的值赋给新变量
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
my_neural = MyNeural()
# 3.把输入数据放入神经网络当中
output = my_neural(input_matrix)
print(output)
# 结果: tensor([[[[1., 0.],
# [0., 3.]]]])
4. Linear Layer线性层
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
# 1.获取输入图片数据
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# 2.搭建神经网络
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# 196608 = 32 * 32 * 3 * 64
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
my_neural = MyNeural()
# 3.把输入数据放入神经网络中跑
for data in dataloader:
imgs, targets = data
# 把输入展平成一行
output = torch.flatten(imgs)
output = my_neural(output)
print(imgs.shape)
print(output.shape)
三、搭建一个简单的分类的神经网络
以CIFAR10数据集为例
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# padding和stride是根据官网给的公式计算得出
# 使用Sequential把神经网络中的各层写到一起,简化书写
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
my_neural = MyNeural()
print(my_neural)
# 使用torch.ones创建都是1的数,可以测试一下这个神经网络搭建的是否正确
input = torch.ones((64, 3, 32, 32))
output = my_neural(input)
print(output.shape)
writer = SummaryWriter("../logs")
# add_graph可以输出这个网络的结构图以及每层的参数大小
writer.add_graph(my_neural, input)
writer.close()
四、torch.nn中的 Loss Functions损失函数
1. Loss作用
- 定义预测值和真实值之间的差距
- 并且指导我们提升预测值,为更新预测值提供依据(反向传播)
2. 几个Loss的简单用法
L1Loss、MSELoss、CrossEntropyLoss
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
outputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
outputs = torch.reshape(outputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# 1.使用损失函数L1Loss:预测值和真实值直接相减,然后求和或者求均值 (这里使用求和方式)
loss = L1Loss(reduction='sum')
result_l1 = loss(outputs, targets)
# 2.使用损失函数MSELoss:相减后求平方,然后求和或者求均值 (默认是求均值)
loss_mse = MSELoss()
result_mse = loss_mse(outputs, targets)
print(result_l1)
# 输出:2 (1-1 + 2-2 + 5-3 = 2)
print(result_mse)
# 输出:1.333 (1-1^2 + 2-2^2 + (5-3)^2)/3 = 4/3 = 1.333
# 3.使用交叉熵损失函数CrossEntropyLoss
outputs = torch.tensor([0.1, 0.2, 0.3])
targets = torch.tensor([1])
outputs = torch.reshape(outputs, (1, 3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(outputs, targets)
print(result_cross)
3. 在自写的神经网络中使用Loss Function
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# padding和stride是根据官网给的公式计算得出
# 使用Sequential把神经网络中的各层写到一起,简化书写
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
my_neural = MyNeural()
# 使用交叉熵损失函数(根据预测值和真实值的情况选匹配的损失函数?)
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = my_neural(imgs)
result_loss = loss(outputs, targets)
# 使用反向传播result_loss.backward()可以获取梯度
# result_loss.backward()
print(result_loss)
五、优化器 torch.optim
torch.optim官网
以随机梯度下降SGD优化器为例
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class MyNeural(nn.Module):
def __init__(self):
super(MyNeural, self).__init__()
# padding和stride是根据官网给的公式计算得出
# 使用Sequential把神经网络中的各层写到一起,简化书写
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
my_neural = MyNeural()
# 设置损失函数,使用交叉熵损失函数(根据预测值和真实值的情况选匹配的损失函数?)
loss = nn.CrossEntropyLoss()
# 设置优化器,使用随机梯度下降, lr为学习速率,设置的过大时训练起来不稳定,过小训练的过慢
optim = torch.optim.SGD(my_neural.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = my_neural(imgs)
result_loss = loss(outputs, targets)
# 1.把网络模型中每个可以调节的参数调为0
optim.zero_grad()
# 2.得到每一个可以调节的参数对应的梯度
result_loss.backward()
# 3.使用优化器对其中的参数进行优化
optim.step()
running_loss = running_loss + result_loss
# 可以看出每次running_loss都在减小
print(running_loss)
六、神经网络完整的模型训练和测试套路
神经网络完整的模型训练和模型测试套路(以CIFAR10数据集为例)