异构内存及其在机器学习系统的应用与优化
第四范式深耕于人工智能领域,在人工智能相关算法、应用、系统和底层架构设计等有兼具广度和深度的理解。
随着近几年先进存储技术的飞速发展,涌现出了具有颠覆性的存储技术,比如非易失性存储、SSD等。基于此类技术的异构内存架构,正在颠覆传统应用程序的设计和优化模式。
第四范式在异构内存架构上抢先布局,进行了若干创新性探索研发和落地实践,比如参数服务器[ 第四范式推出业界首个基于持久内存、支持毫秒级恢复的万亿维线上预估系统:https://www.163.com/tech/article/FGCFSO4N00099A7M.html ]、内存数据库等[ 英特尔、第四范式联合研究成果入选国际顶会 VLDB 傲腾™ 持久内存加持 优化万亿维特征在线预估系统:https://newsroom.intel.cn/news-releases/the-joint-research-results-of-intel-and-4paradigm-were-selected-into-the-vldb-international-conference/]。
此篇文章将介绍异构内存架构的技术背景,以及在自动机器学习系统上的技术实践。
异构内存架构
传统上,我们所说的内存一般是指动态随机存储,即DRAM。此外,在CPU中还会存在小容量的快速存储器件,我们一般会称他们为CPU缓存(即L1/L2 cache)。具有持久性的慢速存储器件则构成了外存,比如磁盘等。因此,外存、内存、和CPU缓存,构成了整个存储架构金字塔。但是,随着具有革命性意义的非易失性内存技术的商业化落地,使得这个金字塔中的内存不再由DRAM单一组成,而是由DRAM和非易失性内存构成了异构内存架构。
此外,非易失性内存的出现也模糊了内存和外存之间的功能边界,使得内存数据持久化成为了可能。今天,非易失性内存技术已经完全成熟,由英特尔于2019年发布的英特尔® 傲腾™ 持久内存(简称持久内存或者PMem),即是此技术的代表性产品。
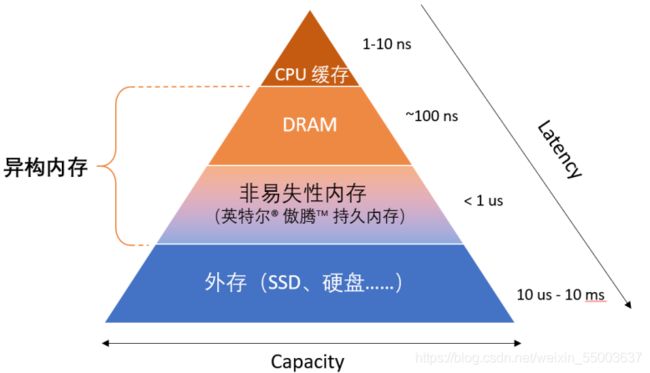
图 1. 基于异构内存的存储架构金字塔
图 1显示了包含有异构内存的存储架构金字塔。可以看到,在本质上,持久内存处于金字塔中DRAM和外存之间,其在容量、性能、成本都是处于两者之间。甚至在功能上,它亦是一个DRAM和外存的混合体。它既可以直接当做内存使用(内存模式),也可以当作一个持久化设备使用(App Direct 模式,简称AD模式)。
在内存模式中,持久内存对操作系统透明,其容量直接反应为整体的可用内存容量;AD模式则将存储层级暴露,由开发者完全掌控。因此,由于持久内存的特殊存在,现代内存架构不仅仅是在层级上变得更为复杂,在功能上也出现了革命性的变化,对于如何利用好异构内存架构,开发人员需要思考更多的问题,比如:
- 多级存储的优化。持久内存提供了一个性能接近于DRAM,但是成本更低的内存方案,非常有利于对于内存消耗巨大的应用。但是,多级存储架构的引入也为性能优化带来了更高的挑战。我们知道,高性能缓存在性能调优中有重大意义。一方面现实数据中往往存在热点,缓存可以有效提升热点数据的访问性能;另一方面,缓存敏感数据结构(cache
conscious)为了压榨硬件性能,常常有精巧的设计。那么,持久内存的出现使得这个存储层级更为复杂,对多级缓存机制、数据结构和算法的设计都提出了更高的要求。 - 持久化机制的利用。持久内存使得外存不再是存储数据的唯一选择。持久内存提供了远比传统外存器件更高的持久化性能,但是其容量相对较小。在某些场景中如何有效的发挥高性能持久化的特点,成为了应用落地需要思考的新问题。比如,对于需要全天候保证服务质量的在线服务应用,内存数据持久化即能提供离线以后的快速恢复能力;另外,原本磁盘IO为性能瓶颈的场景,也可以利用持久内存来作为存储介质,来提升整体系统性能。
为了让大家进一步了解异构内存架构如何在实际场景中发挥价值,我们将抛砖引玉,分享第四范式在异构内存架构上的实践经验。
自动机器学习系统在异构内存上的优化
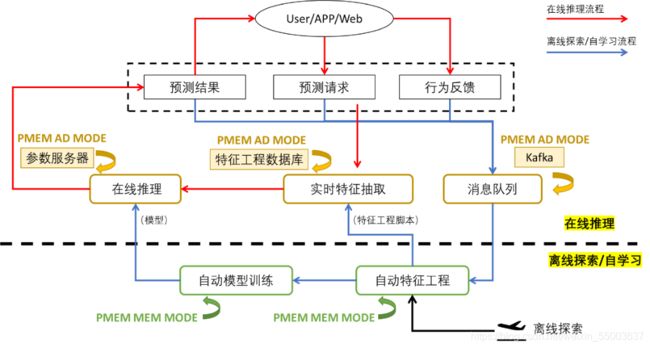
图 2显示了一个第四范式产品中一个典型的自动机器学习(AutoML)全流程。其主体上包含了离线探索以及线上推理部分。离线探索通过自动特征工程和模型训练,产出可以上线的特征工程脚本以及模型。线上推理服务在接受到用户请求以后,经过实时特征抽取和模型推理,拿到预测结果。同时消息队列在整个系统中起到了数据搜集和分发的关键作用。
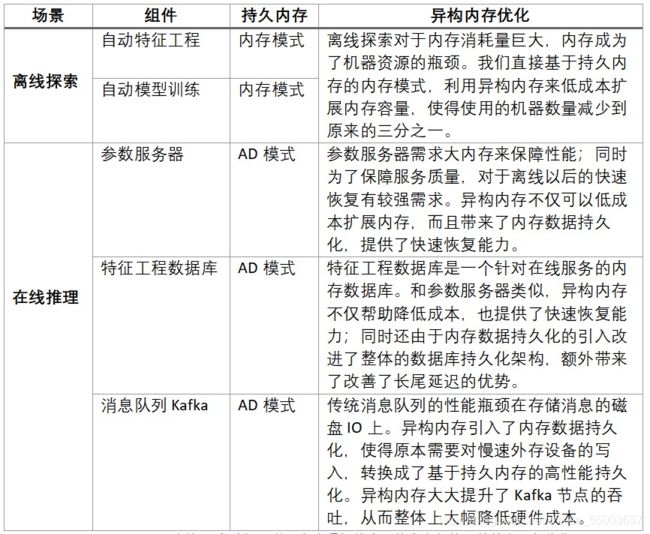
从表格 1可以看到,在异构内存架构下,持久内存在不同组件中有不同的使用方法,从而达到不同的优化目的。总体来说,内存模式可以用来实现快速的低成本内存容量扩展,AD模式则带来了更多的益处,包括快速恢复能力、提升数据存储性能等。
第四范式已经将基于异构内存优化的关键技术组建进行了解耦,并且贡献到了开源社区,目前主要包含两个项目:高性能消息队列系统Pafka(https://github.com/4paradigm/pafka),以及针对AI负载优化的高性能KV存储引擎 PmemStore(https://github.com/4paradigm/pmemstore) 。以下主要展开介绍Pafka。
Pafka:基于异构内存优化的高性能消息队列系统
Kafka是一个开源的分布式事件流/消息队列系统,用于高效,可靠地处理实时数据流,在工业界中有非常广泛的落地应用场景。 但是,由于其持久化逻辑的存在,其性能(吞吐和延迟)常常受到外存设备(HDD/SSD)的制约。在实际使用场景中,为了增加 Kafka 集群的总体吞吐量,企业不得不扩大集群规模,增加了企业的总成本。
持久内存具有高速持久化的特性,能达到几倍甚至几十倍于传统硬盘和SSD的持久化性能。因此,基于异构内存架构的 Kafka 的优化版本 — Pafka,正是利用了高速持久化的特性,大幅提升单节点吞吐,从而优化在集群上的总投入成本。总体来说,相比较于传统的Kafka解决方案,Pafka带来了如下优势:
- 比较于目前数据中心常见的 SATA SSD 的配置,基于异构内存的Pafka改进节点吞吐和延迟均达20倍。
- 由于大幅提升了节点吞吐,因此在集群规模总投资上,相比较于 Kafka,Pafka可以减少硬件投入成本 10 倍以上。
- Pafka直接基于Kafka优化,用户原有的基于 Kafka 的业务代码无需修改,可以零代码改造成本迁移到Pafka系统。
我们对于 Kafka 的优化集中于造成性能瓶颈的数据落盘部分。原Kafka原有的架构中,数据持久化只发生在外存(磁盘/SSD)这一层级;经过优化以后的Pafka版本,基于异构内存架构,同时把持久内存和外存用来做数据持久化。
具备高性能持久化能力的持久内存作为持久化层级的第一级,而容量更大但性能较差的外存则作为第二级持久化介质,两者通过一定的缓存机制进行管理。
由于消息队列的生产者/消费者的使用模式,大部分场景下数据的存取都会发生在高性能的持久内存中。
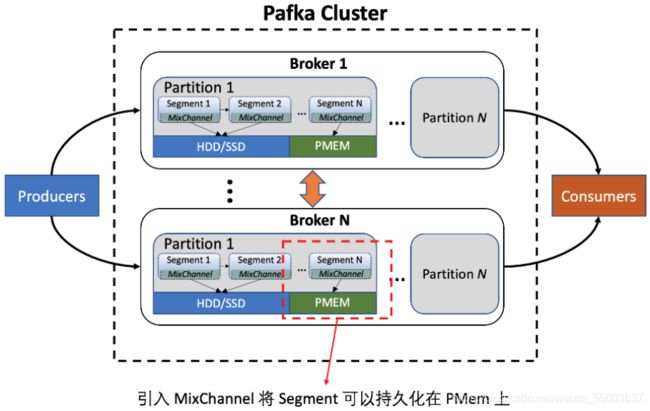
图 3. Pafka集群架构
如图 3所示,一个 Kafka 服务器集群由几个至上百上千个的 brokers组成。Brokers 内部划分为了不同的 partitions,进一步划分为 segments,来进行消息存储。我们对于 Kafka 的改造主要集中在 segment 的存储数据结构上的改造。原来的 segment 只能存储在 HDD/SSD 等外存设备上,我们使用 PMDK 来进行基于异构内存的持久化操作,引入 MixChannel 的概念,来实现 segment 既能存储在 HDD/SSD 的外存设备,也能在持久内存上。
具体来说,MixChannel将普通的文件接口和持久内存的接口统一管理,其底层存储介质对于上层组件是透明的。为了支持基于持久内存的存储,我们为MixChannel引入了数据结构PMemChannel,其主要功能是把持久内存的MemoryBlock对象封装成满足FileChannel API的接口,从而可以让MixChannel方便的选择基于传统文件的FileChannel接口,还是基于持久内存的PMemChannel。这里我们使用了pmdk llpl的PersistentMemoryBlock,会自动为每次写入的数据进行持久化。同时,为了支持zero-copy,我们还为llpl的MemoryBlock,通过直接映射持久内存的地址到ByteBuffer,实现了zero-copy的ByteBuffer接口,从而避免了内存的多次拷贝,提升性能。
为了维护segment和持久内存上数据的对应关系,我们为每个segment分配一个持久内存的MemoryBlock,映射关系通过pmdk pcj的ObjectDirectory来维护。
此外,为了避免MemoryBlock在Pafka正常运行时动态分配的开销,我们会在初始化的时候预先分配固定一定比例的内存池空间,用于写数据的时候MemoryBlock的快速分配。
性能比较

图 4显示,相比较于数据中心中常用的基于SATA SSD进行持久化的Kafka,基于异构内存优化的Pafka在吞吐和延迟的性能表现上均可以达到20倍的改进。
成本比较
假设我们的目标是提供20 GB /秒的整体吞吐率,我们将异构持久内存的 Pafka 与基于 SATA SSD 的Kafka 进行了比较。图 5显示,为了实现20 GB /秒的总吞吐率,基于 SATA SSD 的服务器和基于异构内存的服务器的数量分别为 45 和 3。 此外,就硬件成本而言,传统的Kafka(SATA SSD)需要花费为 45 万美元,而我们的Pafka解决方案仅需花费 4.05 万美元。Pafka解决方案将硬件成本大大降低到传统Kafka解决方案的9%。

图 5. 20 GB/sec 吞吐的性能下,Pafka和Kafka方案的成本比较
更多信息
Pafka为第四范式的开源项目,具体使用方式、技术支持、以及完整性能报告可以通过以下渠道了解更多:
-代码Github repo:https://github.com/4paradigm/pafka
-Slack channel:https://join.slack.com/t/memarkworkspace/shared_invite/zt-o1wa5wqt-euKxFgyrUUrQCqJ4rE0oPw
-MemArk 异构存储技术论坛:https://discuss.memark.io/