模型部署 利用Tensorflow Serving部署模型
文章目录
- Tensorflow Serving
- 实战
-
- 安装Tensorflow serving
- 准备YOLOX模型
- 部署YOLOX模型
- 测试YOLOX模型
- 多模型多版本部署
- 模型的热部署
- 参考
Tensorflow Serving
使用Tensorflow框架训练好模型后,想把模型部署到生产环境可以使用Tensorflow Serving进行部署。Tensorflow Serving具有以下作用:
- 兼容Tensorflow训练的模型,提供gRPC和RESTful API服务
- 便于实现,自带版本管理,支持模型热更新,可同时部署多个版本模型等优点
- 使用docker进行部署,方便快捷
Docker Hub上的tensorflow/serving repo存在多个版本的的tensorflow serving docker 镜像,除tensorflow版本不同外,存在四种镜像版本号,分别为:
:latest:带有编译好的Tensorflow Serving的原始镜像,无法进行任何修改latest-devel:devel指的是development,可开启镜像容器bash修改配置,然后使用docker commit制作新镜像latest-devel-gpu:GPU版本的latest-devel
关于Tensorflow的部署过程如下,摘自:Tensorflow Serving Github
# Download the TensorFlow Serving Docker image and repo
docker pull tensorflow/serving
git clone https://github.com/tensorflow/serving
# Location of demo models
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
# Start TensorFlow Serving container and open the REST API port
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
# Query the model using the predict API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
在整个过程中运行docker时需要挂载宿主模型目录(一般在XXX/serving//tensorflow_serving/servables/tensorflow/testdata/your_model_path_name)到容器里面(/models/your_model_path_name)。这个时候就会产生疑问,假设需要部署多个模型怎么办?某个模型有多个版本该如何做版本控制?接下来以实战介绍如何玩转Tensorflow serving,该例子以部署YOLOX为例。
实战
该部分以部署YOLOX为例,介绍如何部署YOLOX的多个版本模型以及部署多个不同的YOLOX模型。
安装Tensorflow serving
根据上面的操作步骤,安全并运行tensorflow-serving,然后进行测试

测试运行成功

准备YOLOX模型
准备YOLOX的pb模型
模型的路径:

使用saved_model_cli查看模型的信息:
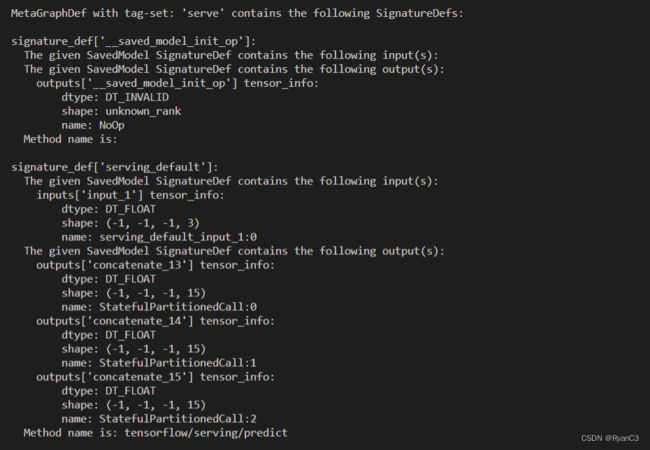
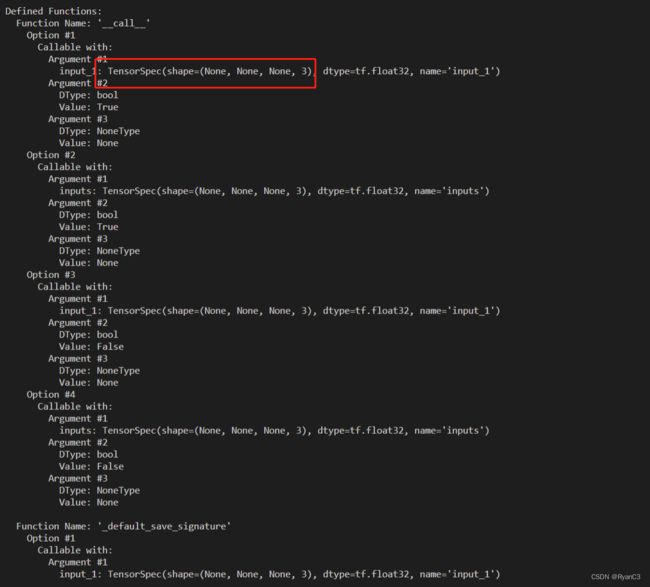

标记红框的是模型的输入输出,忽略名字。
部署YOLOX模型
部署YOLOX的Tensorflow Serving。这里遇到一个问题:我执行以下命令
docker run -t --rm -p 8501:8501 \
-v /home/***/model/yolox_model:/models/yolox_model" \
-e MODEL_NAME=yolox_model\
tensorflow/serving &
出现以下错误:
2022-06-20 08:46:28.357370: W tensorflow_serving/sources/storage_path/file_system_storage_path_source.cc:268] No versions of servable yolox_model found under base path /models/yolox_model. Did you forget to name your leaf directory as a number (eg. '/1/')?

这个提示说你没有声明版本,对比一下tensorflow serving Demo文件的异同,发现yolox的文件下没有版本信息,即001、002之类,版本可以自定义。

最终的文件夹下的结构:

修改完成后运行:

访问:http://[your host ip]:8501/v1/models/yolox_model

访问http://[your host ip]:8501/v1/models/yolox_model/metadata

测试YOLOX模型
为了方便起见,以下用Python测试Tensorflow serving的Rest Api服务。
调用也比较简单,具体如下。最终结果返回的是boxes,由于yolox不是end2end,所以还需要做进一步的后处理,这里不详细讲述了,具体可以参考我的github代码:tfx_inference

多模型多版本部署
这一块比较简单,主要是学会配置文件即可。以下是文件结构:

model.config配置文件内容如下:

这里要注意一点:config文件中的base_path并不是设定你服务器上的路径,而是容器里面模型的位置。 关于config文件可以参考:serving_config。
完成后执行以下命令:
docker run -p 8501:8501 -v /home/****/model:/models/model -t tensorflow/serving --model_config_file=/models/model/model.config
访问yolox_model1的模型:http://your ip:8501/v1/models/yolox_model_1,同理也可以访问yolox_model_2。
模型的热部署
在已有模型的服务已启动的情况下,想要在不停止原服务的情况下新增一个模型,可以通过配置模型配置文件定期检查时间,来支持热部署。
主要是在运行的时候添加参数:--model_config_file_poll_wait_seconds=60
参考
- Tensorflow serving
- TensorFlow Serving + Docker + Tornado机器学习模型生产级快速部署
- 使用tensorflow serving部署keras模型(tensorflow 2.0.0)
- Tensorflow Serving With Docker
- 如何将TensorFlow Serving的性能提高超过70%?