Pytorch:激活函数及其梯度
(1)sigmoid函数

sigmoid函数曲线平滑,可以很好的使用,但是如果数据长时间不更新,会出现失去梯度的状况,也叫梯度弥散。
求sigmoid函数的梯度
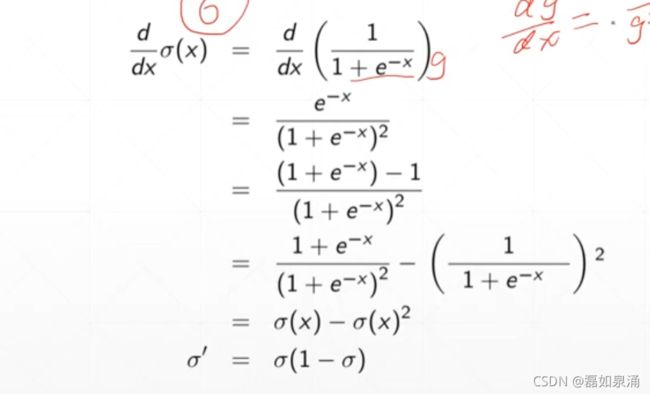
当然,我们可以使用pytorch实现sigmoid函数。代码如下。
import torch
a=torch.linspace(-100,100,10)
torch.sigmoid(a)
'''得到结果为
tensor([0.0000e+00, 1.6655e-34, 7.4564e-25, 3.3382e-15, 1.4945e-05, 9.9999e-01,
1.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00])
'''(2)Tanh函数

可以将Tanh函数视为sigmoid函数的一种线性变化,所以同样存在梯度弥散的现象。
其梯度为

对于Tanh函数,我们也可以通过代码实现
import torch
b=torch.linspace(-1,1,10)
torch.tanh(b)
tensor([-0.7616, -0.6514, -0.5047, -0.3215, -0.1107, 0.1107, 0.3215, 0.5047,
0.6514, 0.7616])为了消除梯度弥散现象,我们推出了Relu激活函数。
(3)Relu函数
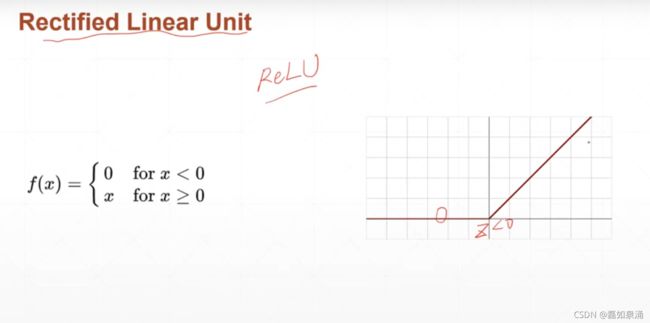
relu函数在z>0的时候,梯度恒为1。
我们利用代码实现Relu函数,有两种方法可以
import torch
from torch.nn import functional as F
a=torch.linspace(-1,1,10)
torch.relu(a)#第一种方法
tensor([0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1111, 0.3333, 0.5556, 0.7778,
1.0000])
F.relu(a)#第二种方法
tensor([0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1111, 0.3333, 0.5556, 0.7778,
1.0000])(4)Mean Squared Error(均方差)
简写为MSE,公式为Loss=![]() =
=![]()
L2-norm=![]() =
=![]()
loss=norm![]()
当我们对MSE进行求梯度操作

用程序进行对MSE的梯度计算
第一种方法,使用autograd包里的函数
#模型pred=x*w+b
import torch
from torch.nn import functional as F
x=torch.ones(1)#x初始化为1
w=torch.full([1],2)#w初始化为dim为1,长度为1,值为2的tensor
mse=F.mse_loss(torch.ones(1),x*w)
torch.autograd.grad(mse,[w])#对于这个模型,mse接受pred,[w]接收w1,w2等等
#但是这里会报错,说w不需要求导,我们求了,所以我们需要对w的数据进行更新
w.requires_grad_()#对w数据进行更新
torch.autograd.grad(mse,[w])#再次报错,因为没有更新图
mse=F.mse_loss(torch.ones(1),x*w)#使用这个把图重新计算一遍
torch.autograd.grad(mse,[w])
另一种方法,使用loss.backward
#模型pred=x*w+b
import torch
from torch.nn import functional as F
x=torch.ones(1)#x初始化为1
w=torch.full([1],2)#w初始化为dim为1,长度为1,值为2的tensor
mse=F.mse_loss(torch.ones(1),x*w)
mse=F.mse_loss(torch.ones(1),x*w)#使用这个把图重新计算一遍
mse.backward()#自动从后往前传播,完成这条路径上所有的需要梯度的tensor的计算,计算后的grad不会再返回出来
w.grad
#输出tensor([2.])
(5)Cross Entropy Loss(常用于二分类,多分类)
使用:<1>二分类
<2>多分类
<3>和softmax激活函数同时使用
(6)softmax(适用于多分类)
我们把数据分类时的出现频率转化为概率,把概率最大的情况作为我们的预测值,当我们使用softmax函数进行压缩为概率时,还应要求所有出现的情况加起来概率等于1。(而sigmoid不太准确,会出现加起来等于3的情形。)

softmax函数求导时
当i=j时

当i不等于j的时候

使用代码实现softmax
#softmax
import torch
from torch.nn import functional as F
a=torch.rand(3)#随机生成dim为1,长度为3的tensor
a.requires_grad_()#标注一下grad函数
p=F.softmax(a,dim=0)
torch.autograd.grad(p[1],[a],retain_graph=True)
torch.autograd.grad(p[2],[a])
#结果为
# (tensor([-0.1537, -0.0906, 0.2443]),)