周志华《机器学习》西瓜书 小白Python学习笔记(七) ———— 第六章 支持向量机SVM
周志华《机器学习》西瓜书 小白Python学习笔记(七) ———— 第六章 支持向量机SVM
- 什么是SVM
- SVM求解过程
-
- 转化为Lagrange对偶问题
- Lagrange对偶问题求解
-
- 1. min w , b L ( w , b , α ) \min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha}) minw,bL(w,b,α)
- 2. max α i { min w , b L ( w , b , α ) } \max_{\alpha_i}\{\min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha})\} maxαi{minw,bL(w,b,α)}
- 核函数
- 软间隔
什么是SVM
支持向量机(support vector machines,SVM)的基本定义为在特征空间上的间隔最大的线性分类器,那么什么是间隔最大的线性分类器呢?
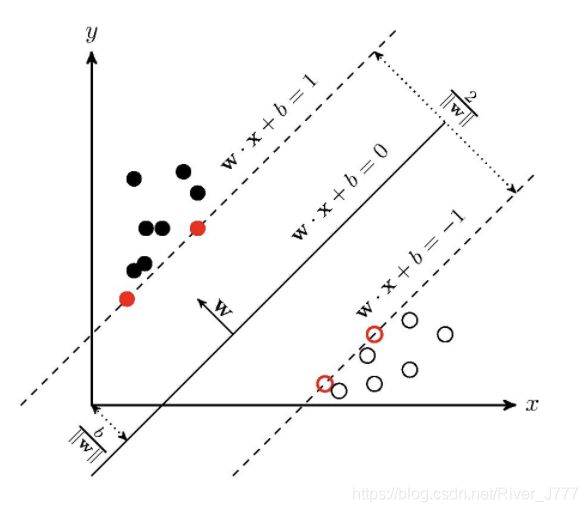
看这张图,样本空间为 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)}n个点, y y y表示标签取值为-1或1,即图中的黑、白两类点,我们试图找到一个超平面将两类点分隔开,如图,设超平面的表达式为 w x + b = 0 \boldsymbol {wx} +b=0 wx+b=0
那么对于黑、白两种点分别有:
{ w x i + b > 0 w x i + b < 0 \left\{\begin{aligned}\boldsymbol {wx_i} +b>0 \\ \boldsymbol {wx_i} +b<0 \end{aligned} \right. {wxi+b>0wxi+b<0
经过 w \boldsymbol w w和 b b b的放缩可以整理成
{ w x i + b ≥ 1 , y i = 1 w x i + b ≤ − 1 , y i = − 1 \left\{\begin{aligned} & \boldsymbol {wx_i} +b\geq 1,y_i=1& \\ &\boldsymbol {wx_i} +b\leq-1,y_i=-1& \end{aligned} \right. {wxi+b≥1,yi=1wxi+b≤−1,yi=−1
使得两类点中距离这个超平面最近的点有 w x i + b = 1 , − 1 \boldsymbol {wx_i} +b=1,-1 wxi+b=1,−1(即图片中标红的的点),这些点对应的就是支持向量。
根据数学知识,样本空间内任意一个点 x i \bf x_i xi到这个超平面的距离为
d i = ∣ w x i + b ∣ ∥ w ∥ d_i=\frac{|\boldsymbol {wx_i} +b|}{\|\boldsymbol{w}\|} di=∥w∥∣wxi+b∣
研究支持向量对应的点到超平面的距离时,就变成了
d = 1 ∥ w ∥ d=\frac1{\|\boldsymbol{w}\|} d=∥w∥1
刚才所说的间隔最大的线性分类器中的“间隔”就是指的这个啦!
最优化函数即为
m a x 1 ∥ w ∥ max\frac1{\|\boldsymbol{w}\|} max∥w∥1
条件是 w w w能将两类点分隔开,即 w x i + b \boldsymbol {wx_i} +b wxi+b与 y i y_i yi同号,又因为 ∣ w x i + b ∣ ≥ 1 , y = 1 , − 1 |\boldsymbol {wx_i} +b|\geq1,y=1,-1 ∣wxi+b∣≥1,y=1,−1,所以可以表示为
y i ( w x i + b ) ≥ 1 , i = 1 , … , n y_{i}\left(w x_{i}+b\right) \geq 1, i=1, \ldots, n yi(wxi+b)≥1,i=1,…,n
这就是支持向量机的由来。
SVM求解过程
转化为Lagrange对偶问题
回到之前得到的目标函数:
m a x 1 ∥ w ∥ max\frac1{\|\boldsymbol{w}\|} max∥w∥1
s . t . y i ( w x i + b ) ≥ 1 , i = 1 , … , n s.t. y_{i}\left(w x_{i}+b\right) \geq 1, i=1, \ldots, n s.t.yi(wxi+b)≥1,i=1,…,n
可以转化成:
m i n 1 2 ∥ w ∥ 2 min \frac1{2}{\|\boldsymbol{w}\|}^2 min21∥w∥2
s . t . y i ( w x i + b ) ≥ 1 , i = 1 , … , n s.t. y_{i}\left(\boldsymbol{w x}_{i}+b\right) \geq 1, i=1, \ldots, n s.t.yi(wxi+b)≥1,i=1,…,n
对于这个凸二次规划问题,可以通过拉格朗日对偶性质,将其转化为原问题的对偶问题进行求解。首先根据拉格朗日乘子法得到:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i ( y i ( w x i + b ) − 1 ) \mathcal{L}(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left(y_{i}\left(w x_{i}+b\right)-1\right) L(w,b,α)=21∥w∥2−∑i=1nαi(yi(wxi+b)−1)
其中 α i ≥ 0 , i = 1 , 2 , . . . , n \alpha_i\geq0,i=1,2,...,n αi≥0,i=1,2,...,n
我们令
θ ( w ) = max α i ≥ 0 L ( w , b , α ) \theta(w)=\max_{\alpha_i\geq0}\mathcal{L}(w, b, \alpha) θ(w)=αi≥0maxL(w,b,α)
易知,只有当这个超平面将两类样本全部分隔开即所有约束条件都满足,即 y i ( w x i + b ) ≥ 1 , i = 1 , … , n y_{i}\left(w x_{i}+b\right) \geq 1, i=1, \ldots, n yi(wxi+b)≥1,i=1,…,n时, θ ( w ) = 1 2 ∥ w ∥ 2 \theta(w)=\frac{1}{2}\|w\|^{2} θ(w)=21∥w∥2
所以
θ ( w ) = { 1 2 ∥ w ∥ 2 , 约 束 均 成 立 + ∞ , 其 他 \theta(w)=\left\{\begin{aligned}&\frac{1}{2}\|w\|^{2},&约束均成立\\ &+\infty, &其他 \end{aligned} \right. θ(w)=⎩⎨⎧21∥w∥2,+∞,约束均成立其他
因此,此时只需要对 θ ( w ) \theta(w) θ(w)关于 w , b w,b w,b求最小值就可以回到原目标函数了:
min w , b θ ( w ) = min w , b max α i ≥ 0 L ( w , b , α ) = p ∗ \min _{\boldsymbol{w}, b} \theta(\boldsymbol{w})=\min _{\boldsymbol{w}, b} \max _{\alpha_{i} \geq 0} L(\boldsymbol{w}, b, \boldsymbol{\alpha})=p^{*} w,bminθ(w)=w,bminαi≥0maxL(w,b,α)=p∗
若将求最大最小值交换顺序,设求得的最优值 d ∗ d^* d∗:
max α i ≥ 0 min w , b L ( w , b , α ) = d ∗ \max _{\alpha_{i} \geq 0}\min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha})=d^{*} αi≥0maxw,bminL(w,b,α)=d∗
根据对偶问题的性质, p ∗ ≥ d ∗ p^{*}\geq d^{*} p∗≥d∗
而 p ∗ = d ∗ p^{*}=d^{*} p∗=d∗的条件有两个:
- 优化问题是凸优化问题
- 满足KKT条件
(KKT详见)
Lagrange对偶问题求解
当满足KKT条件时,对偶问题函数为:
max α i ≥ 0 min w , b L ( w , b , α ) \max _{\alpha_{i} \geq 0}\min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha}) αi≥0maxw,bminL(w,b,α)
1. min w , b L ( w , b , α ) \min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha}) minw,bL(w,b,α)
第一步是关于 w w w和 b b b求最小值,此时 α i \alpha_i αi看作常数。
对 w w w和 b b b分别求偏导,令偏导为0,得:
∂ L ∂ w = w − ∑ i = 1 n α i y i x i = 0 ⇒ w = ∑ i = 1 n α i y i x i \frac{\partial \mathcal{L}}{\partial w}=w-\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i}=0 \Rightarrow w=\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i} ∂w∂L=w−i=1∑nαiyixi=0⇒w=i=1∑nαiyixi
∂ L ∂ b = ∑ i = 1 n α i y i = 0 ⇒ ∑ i = 1 n α i y i = 0 \frac{\partial \mathcal{L}}{\partial b}= \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \Rightarrow \sum_{i=1}^{n} \alpha_{i} y_{i}=0 ∂b∂L=i=1∑nαiyi=0⇒i=1∑nαiyi=0
带入原式,得到
L ( w , b , α ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i y i ( ( ∑ j = 1 N α j y j x j ) ⋅ x i + b ) + ∑ i = 1 N α i = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) + ∑ i = 1 N α i L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}\right)-\sum_{i=1}^{N} \alpha_{i} y_{i}\left(\left(\sum_{j=1}^{N} \alpha_{j} y_{j} \boldsymbol{x}_{j}\right) \cdot \boldsymbol{x}_{i}+b\right)+\sum_{i=1}^{N} \alpha_{i}=-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}\right)+\sum_{i=1}^{N} \alpha_{i} L(w,b,α)=21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαiyi((j=1∑Nαjyjxj)⋅xi+b)+i=1∑Nαi=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
2. max α i { min w , b L ( w , b , α ) } \max_{\alpha_i}\{\min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha})\} maxαi{minw,bL(w,b,α)}
第二步,关于 α i \alpha_i αi求最大值,即:
max α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) + ∑ i = 1 N α i \max_ {\alpha_i}-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}\right)+\sum_{i=1}^{N} \alpha_{i} αimax−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
稍微变形后,可以转化为:
min α i 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i \min_ {\alpha_i}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}\right)-\sum_{i=1}^{N} \alpha_{i} αimin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
s . t . ∑ i = 1 n α i y i = 0 , α i ≥ 0 , i = 1 , 2 , ⋯ , p s.t. \sum_{i=1}^{n} \alpha_{i} y_{i}=0,\alpha_i\geq0,i=1,2,\cdots,p s.t.i=1∑nαiyi=0,αi≥0,i=1,2,⋯,p
对于这个问题,我们通常采用的是序列最小化算法(SMO),得到 α ∗ \boldsymbol\alpha^* α∗,根据 α ∗ \boldsymbol\alpha^* α∗得到 w ∗ \boldsymbol w^* w∗和 b ∗ b^* b∗。
(最小序列算法SMO:详见)
最终我们可以得到最优解对应的超平面为:
w ∗ x + b ∗ = 0 \boldsymbol w^*\boldsymbol x+b^*=0 w∗x+b∗=0
那么我们就可以得到最终的目标分类函数为:
f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(\boldsymbol x)=sign(\boldsymbol w^*·\boldsymbol x+b^*) f(x)=sign(w∗⋅x+b∗)
核函数
我们以上讨论的都还是线性可分的数据,然而,绝大多数情况下数据并不是线性可分的,此时便不存在一个普通意义上的超平面可以将两类样本分隔开来。于是,我们通过引入核函数,将低维数据映射到高维,在高维空间找到一个超平面,以此来解决在原低维空间上线性不可分的问题。
根据上文中对线性可分数据的SVM算法推导,我们在这一过程中的目标函数只是涉及到了内积,所以我们只需要通过用核函数来取代之前的求内积运算。
看到我们上一步所得到的目标函数
min α i 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i \min_ {\alpha_i}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}\right)-\sum_{i=1}^{N} \alpha_{i} αimin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
其中涉及到内积运算的是 ( x i ⋅ x j ) (\boldsymbol{x}_{i} \cdot \boldsymbol{x}_{j}) (xi⋅xj),于是我们将这一部分替换为核函数 κ ( x i , x j ) \kappa\left(x_{i}, x_{j}\right) κ(xi,xj)即可。
min α i 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) − ∑ i = 1 N α i \min_ {\alpha_i}\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \kappa\left(x_{i}, x_{j}\right)-\sum_{i=1}^{N} \alpha_{i} αimin21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)−i=1∑Nαi
s . t . ∑ i = 1 n α i y i = 0 , α i ≥ 0 , i = 1 , 2 , ⋯ , p s.t. \sum_{i=1}^{n} \alpha_{i} y_{i}=0,\alpha_i\geq0,i=1,2,\cdots,p s.t.i=1∑nαiyi=0,αi≥0,i=1,2,⋯,p
原超平面的表示为
f ( x ) = w x + b f(\boldsymbol{x)}=\boldsymbol {wx} +b f(x)=wx+b
且 w = ∑ i = 1 n α i y i x i w=\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i} w=∑i=1nαiyixi
即: f ( x ) = ∑ i = 1 n α i y i x i ⋅ x + b f(\boldsymbol{x)}=\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i} ·\boldsymbol {x} +b f(x)=i=1∑nαiyixi⋅x+b
引入核函数后,即为:
f ( x ) = ∑ i = 1 n α i y i κ ( x i , x ) + b f(\boldsymbol{x)}=\sum_{i=1}^{n} \alpha_{i} y_{i} \kappa\left(x_{i}, x\right)+b f(x)=i=1∑nαiyiκ(xi,x)+b
此时,最终的目标分类函数为:
f ( x ) = s i g n ( ∑ i = 1 n α i ∗ y i κ ( x i , x ) + b ∗ ) f(\boldsymbol x)=sign(\sum_{i=1}^{n} \alpha^*_{i} y_{i} \kappa\left(x_{i}, x\right)+b^*) f(x)=sign(i=1∑nαi∗yiκ(xi,x)+b∗)
常见的核函数有:
- 线性核函数
κ ( x , x i ) = x ⋅ x i κ(x,xi)=x⋅x_i κ(x,xi)=x⋅xi
主要用于线性可分的情况,特征空间到输入空间的维度是一样的。 - 多项式核函数
κ ( x , x i ) = ( ( x ⋅ x i ) + 1 ) d κ(x,xi)=((x⋅x_i)+1)^d κ(x,xi)=((x⋅xi)+1)d
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间, d d d为多项式的次数。 - 高斯核函数
κ ( x , x i ) = exp ( − ∥ x − x i ∥ 2 δ 2 ) \kappa\left(x, x_{i}\right)=\exp \left(-\frac{\left\|x-x_{i}\right\|^{2}}{\delta^{2}}\right) κ(x,xi)=exp(−δ2∥x−xi∥2)
该核函数是应用最广的一个,在不知道用什么核函数的时候,可以优先使用高斯核函数。 - Sigmoid核函数
κ ( x , x i ) = tanh ( η < x , x i > + θ ) \kappa\left(x, x_{i}\right)=\tanh \left(\eta
采用sigmoid核函数,那么SVM实际就是一种多层神经网络。
软间隔
需要注意的是,以上我们讨论的无论是线性可分还是线性不可分的情况,最终的目标都是找到一个超平面将两类样本完全分开,但是这在实际问题中往往很难实现,而且即使找到了一个超平面可以将两类样本完全分开也很有可能会导致过拟合等后果。
于是,合理的做法是我们可以允许超平面在少量的样本的分类上出错,这就是“软间隔”的概念;与此相对的,之前的超平面不允许有分类错误的样本,我们称之为“硬间隔”。
之前的Lagrange对偶函数如下,其后半部分即为“ 硬间隔 ”的要求:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i ( y i ( w x i + b ) − 1 ) \mathcal{L}(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left(y_{i}\left(\boldsymbol{w x}_{i}+b\right)-1\right) L(w,b,α)=21∥w∥2−i=1∑nαi(yi(wxi+b)−1)
将此处不允许有错误改为错误函数(损失函数),并乘一个常数项 C C C,就是软间隔支持向量机啦!
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ℓ 0 / 1 ( y i ( w x i + b ) − 1 ) \min_{w,b}\quad \frac{1}{2}\|w\|^{2}+C\sum_{i=1}^{n} \ell_{0/1}\left(y_{i}\left(\boldsymbol {w x}_{i}+b\right)-1\right) w,bmin21∥w∥2+Ci=1∑nℓ0/1(yi(wxi+b)−1)
其中 ℓ 0 / 1 \ell _{0/1} ℓ0/1为“0/1损失函数”, C C C为事先确定的正常数.
常用的损失函数有:
- hinge 损失: ℓ hinge ( z ) = max ( 0 , 1 − z ) \ell_{\text {hinge}}(z)=\max (0,1-z) ℓhinge(z)=max(0,1−z)
- 指数损失(exponential loss): lexp ( z ) = exp ( − z ) \operatorname{lexp}(z)=\exp (-z) lexp(z)=exp(−z)
- 对率损失(logistic loss): ℓ log ( z ) = log ( 1 + exp ( − z ) ) \ell_{\log }(z)=\log (1+\exp (-z)) ℓlog(z)=log(1+exp(−z))
其中最常用的为hinge损失函数,采用hinge 损失函数目标函数可化为:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n m a x { 0 , 1 − y i ( w x i + b ) } \min_{w,b}\quad \frac{1}{2}\|w\|^{2}+C\sum_{i=1}^{n} max \{0,1-y_{i}\left(\boldsymbol{w x}_{i}+b\right)\} w,bmin21∥w∥2+Ci=1∑nmax{0,1−yi(wxi+b)}
用松弛变量 ξ i ≥ 0 \xi_i\geq0 ξi≥0代替,得:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{w,b}\quad \frac{1}{2}\|w\|^{2}+C\sum_{i=1}^{n} \xi_i w,bmin21∥w∥2+Ci=1∑nξi.
可以理解为由原来的约束条件:
s . t . y i ( w x i + b ) ≥ 1 , i = 1 , … , n s.t. \quad y_{i}\left(\boldsymbol{w x}_{i}+b\right) \geq 1, i=1, \ldots, n s.t.yi(wxi+b)≥1,i=1,…,n
转变成:
s . t . y i ( w x i + b ) ≥ 1 − ξ i , i = 1 , … , n s.t. \quad y_{i}\left(\boldsymbol{w x}_{i}+b\right) \geq 1-\xi_i, i=1, \ldots, n s.t.yi(wxi+b)≥1−ξi,i=1,…,n
所以目标函数为:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{w,b}\quad \frac{1}{2}\|w\|^{2}+C\sum_{i=1}^{n} \xi_i w,bmin21∥w∥2+Ci=1∑nξi.
s . t . y i ( w x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 , i = 1 , … , n s.t. \quad y_{i}\left(\boldsymbol{w x}_{i}+b\right) \geq 1-\xi_i, \xi_i\geq0,i=1, \ldots, n s.t.yi(wxi+b)≥1−ξi,ξi≥0,i=1,…,n
之后跟之前的方法相同,转化为对偶问题求解,过程略,对偶问题为:
max α ∑ i = 1 n α i − 1 2 ∑ i , j = 1 n α i α j y i y j ⟨ x i , x j ⟩ s.t. 0 ≤ α i ≤ C , i = 1 , … , n ∑ i = 1 n α i y i = 0 \begin{aligned} \max _{\alpha} & \sum^n_{i=1} \alpha_{i}-\frac{1}{2} \sum^n_{i, j=1} \alpha_{i} \alpha_{j} y_{i} y_{j}\left\langle x_{i}, x_{j}\right\rangle \\ \text {s.t.} & 0 \leq \alpha_{i} \leq C, i=1, \ldots, n \\ & \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{aligned} αmaxs.t.i=1∑nαi−21i,j=1∑nαiαjyiyj⟨xi,xj⟩0≤αi≤C,i=1,…,ni=1∑nαiyi=0
注:图片源自网络