对在运动的刘耕宏进行抠图(含单帧与视频的分割算法应用)
使用MediaPipe
1.单帧图像
代码讲解(1)
# 导包
import cv2
import mediapipe as mp
import matplotlib.pyplot as plt
if __name__ == '__main__':
# 导入分割模块
seg = mp.solutions.selfie_segmentation.SelfieSegmentation(model_selection=0)
# read img BGR to RGB
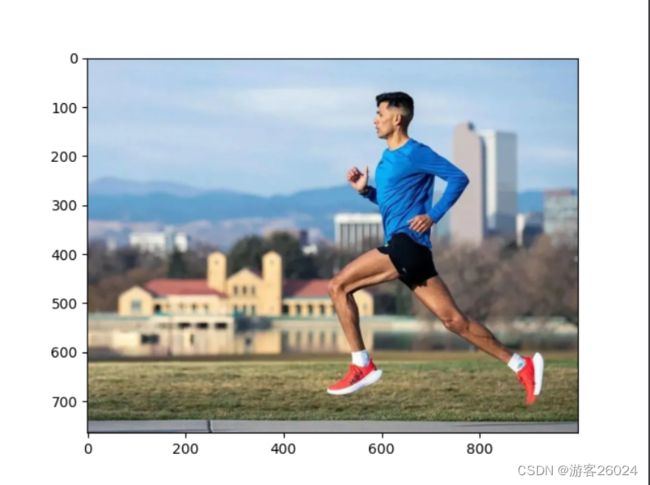
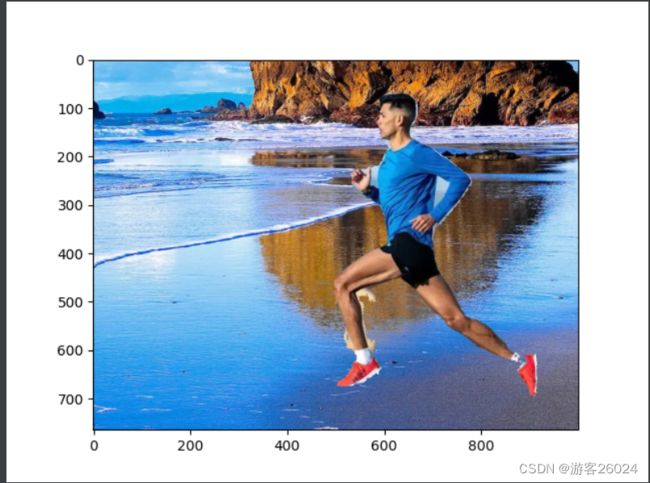
img = cv2.imread("1.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()对应结果
代码讲解(2)
# 处理图像
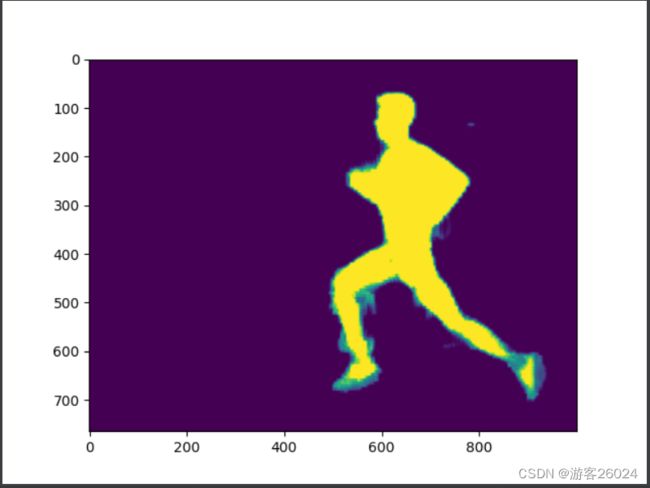
results = seg.process(img)
# results的segmentation_mask提取mask
mask = results.segmentation_mask
plt.imshow(mask)
plt.show()对应结果
代码讲解(3)
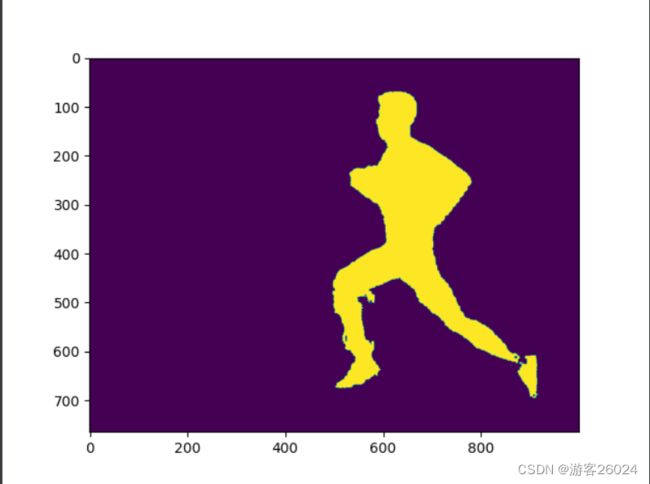
# 将其转化False与True,以便处理
mask = mask > 0.5
plt.imshow(mask)
plt.show()对应结果
代码讲解(4)
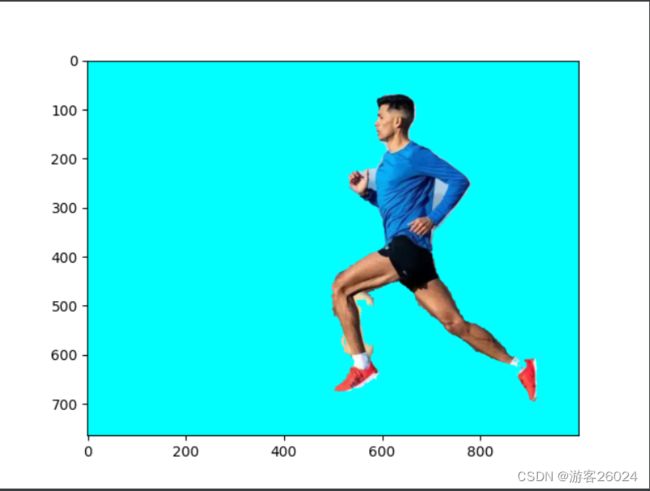
# 将其叠加成三通道
mask_channels = np.stack([mask, mask, mask], axis=-1)
# 背景的颜色定义
MASK_COLOR = [0, 255, 255]
# 背景大小与原图大小一致
fg_img = np.zeros(img.shape, dtype=np.uint8)
fg_img[:] = MASK_COLOR
# 如果mask_channels为True则显示img,如果为False则显示背景
FG_img = np.where(mask_channels, img, fg_img)
# 显示从原图中抠出人体,但是背景为我们重新设置的颜色
plt.imshow(FG_img)
plt.show()对应结果
代码讲解(5)
# 如果~mask_channels为True则显示img(mask_channels为False),如果为False则显示背景
# mask_channels为False显示img,如果mask_channels为True显示fg_img
BG_img = np.where(~mask_channels, img, fg_img)
# 保留背景扣掉人
plt.imshow(BG_img)
plt.show()对应结果
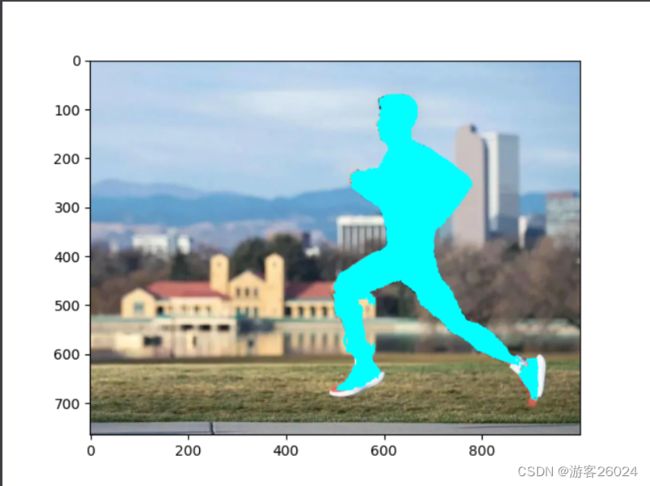
代码讲解(6)
# 单独替换一张新的背景
bg_img = cv2.imread("2.jpg")
bg_img = cv2.cvtColor(bg_img, cv2.COLOR_BGR2RGB)
plt.imshow(bg_img)
plt.show()对应结果

代码讲解(7)
print(bg_img.shape)
BOTTOM = bg_img.shape[0]
TOP = BOTTOM - img.shape[0]
print(TOP)
# 从中间开始取,这样更好对称
LEFT = bg_img.shape[1] // 2 - img.shape[1] // 2
print(LEFT)
RIGHT = LEFT + img.shape[1]
# left top : (TOP, LEFT)
# right bottom: (BOTTOM, RIGHT)
# 将背景大小换成适合原图大小
new_bg = bg_img[TOP:BOTTOM, LEFT:RIGHT, :]
print(new_bg.shape)
# 将原图背景替换成
BG_img = np.where(mask_channels, img, new_bg)
plt.imshow(BG_img)
plt.show()对应结果
完整代码
import cv2
import numpy as np
import mediapipe as mp
import matplotlib.pyplot as plt
if __name__ == '__main__':
seg = mp.solutions.selfie_segmentation.SelfieSegmentation(model_selection=0)
# read img BGR to RGB
img = cv2.imread("1.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print(img.shape)
plt.imshow(img)
plt.show()
results = seg.process(img)
# results的segmentation_mask提取mask
mask = results.segmentation_mask
plt.imshow(mask)
plt.show()
# 将其转化False与True,以便处理
mask = mask > 0.5
plt.imshow(mask)
plt.show()
# 将其叠加成三通道
mask_channels = np.stack([mask, mask, mask], axis=-1)
# 背景的颜色定义
MASK_COLOR = [0, 255, 255]
# 背景大小与原图大小一致
fg_img = np.zeros(img.shape, dtype=np.uint8)
fg_img[:] = MASK_COLOR
# 如果mask_channels为True则显示img,如果为False则显示背景
FG_img = np.where(mask_channels, img, fg_img)
# 显示从原图中抠出人体,但是背景为我们重新设置的颜色
plt.imshow(FG_img)
plt.show()
# 如果~mask_channels为True则显示img(mask_channels为False),如果为False则显示背景
# mask_channels为False显示img,如果mask_channels为True显示fg_img
BG_img = np.where(~mask_channels, img, fg_img)
# 保留背景扣掉人
plt.imshow(BG_img)
plt.show()
# 单独替换一张新的背景
bg_img = cv2.imread("2.jpg")
bg_img = cv2.cvtColor(bg_img, cv2.COLOR_BGR2RGB)
plt.imshow(bg_img)
plt.show()
print(bg_img.shape)
BOTTOM = bg_img.shape[0]
TOP = BOTTOM - img.shape[0]
print(TOP)
# 从中间开始取,这样更好对称
LEFT = bg_img.shape[1] // 2 - img.shape[1] // 2
print(LEFT)
RIGHT = LEFT + img.shape[1]
# left top : (TOP, LEFT)
# right bottom: (BOTTOM, RIGHT)
# 将背景大小换成适合原图大小
new_bg = bg_img[TOP:BOTTOM, LEFT:RIGHT, :]
print(new_bg.shape)
# 将原图背景替换成
BG_img = np.where(mask_channels, img, new_bg)
plt.imshow(BG_img)
plt.show()2.视频
公用代码部分
import os
import sys
import time
import cv2
import numpy as np
import mediapipe as mp
BASE_DIR = os.path.dirname((os.path.abspath(__file__)))
print(BASE_DIR)
sys.path.append(BASE_DIR)
seg = mp.solutions.selfie_segmentation.SelfieSegmentation(model_selection=0)处理每帧的函数
1.将背景扣掉
def process_frame_fg(img):
start = time.time()
img = cv2.flip(img, 1)
img.flags.writeable = False
results = seg.process(img)
mask = results.segmentation_mask.astype("uint8")
# 将其叠加成三通道
mask_channels = np.stack((mask, mask, mask), axis=-1) * 255
mask_channels = mask_channels > 0.5
# 背景的颜色定义
MASK_COLOR = [0, 255, 255]
# 背景大小与原图大小一致
fg_img = np.zeros(img.shape, dtype=np.uint8)
fg_img[:] = MASK_COLOR
# 如果mask_channels为True则显示img,如果为False则显示背景
FG_img = np.where(mask_channels, img, fg_img)
# 显示从原图中抠出人体,但是背景为我们重新设置的颜色
end = time.time()
FPS = 1 / (end - start)
FG_img = cv2.putText(FG_img, 'FPS' + str(int(FPS)), (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 3)
return FG_img2.将前景扣掉
def process_frame_bg(img):
start = time.time()
img = cv2.flip(img, 1)
img.flags.writeable = False
results = seg.process(img)
mask = results.segmentation_mask.astype("uint8")
# 将其叠加成三通道
mask_channels = np.stack([mask, mask, mask], axis=-1) * 255
mask_channels = mask_channels > 0.5
# 背景的颜色定义
MASK_COLOR = [0, 255, 255]
# 背景大小与原图大小一致
fg_img = np.zeros(img.shape, dtype=np.uint8)
fg_img[:] = MASK_COLOR
# 如果~mask_channels为True则显示img(mask_channels为False),如果为False则显示背景
# mask_channels为False显示img,如果mask_channels为True显示fg_img
BG_img = np.where(~mask_channels, img, fg_img)
end = time.time()
FPS = 1 / (end - start)
# 保留背景扣掉人
BG_img = cv2.putText(BG_img, 'FPS' + str(int(FPS)), (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 3)
return BG_img3.替换背景
def process_frame_newbg(img):
start = time.time()
img = cv2.flip(img, 1)
img.flags.writeable = False
results = seg.process(img)
mask = results.segmentation_mask.astype("uint8")
# 将其叠加成三通道
mask_channels = np.stack([mask, mask, mask], axis=-1) * 255
mask_channels = mask_channels > 0.5
bg_img = cv2.imread("2.jpg")
BOTTOM = bg_img.shape[0]
TOP = BOTTOM - img.shape[0]
# 从中间开始取,这样更好对称
LEFT = bg_img.shape[1] // 2 - img.shape[1] // 2
RIGHT = LEFT + img.shape[1]
# left top : (TOP, LEFT)
# right bottom: (BOTTOM, RIGHT)
# 将背景大小换成适合原图大小
new_bg = bg_img[TOP:BOTTOM, LEFT:RIGHT, :]
# 将原图背景替换成
BG_img = np.where(mask_channels, img, new_bg)
end = time.time()
FPS = 1 / (end - start)
BG_img = cv2.putText(BG_img, 'FPS' + str(int(FPS)), (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 3)
return BG_img实时摄像头捕捉
if __name__ == '__main__':
t0 = time.time()
cap = cv2.VideoCapture(0)
cap.open(0)
while cap.isOpened():
success, frame = cap.read()
if frame is None:
print('ERROR')
break
if success == True:
frame = process_frame_bg(frame)
cv2.imshow("segmentation", frame)
if ((time.time() - t0) // 1) == 30:
sys.exit(0)
cv2.waitKey(1)
cap.release()
cv2.destroyAllWindows()亲测3个函数都能正常运行!
实时视频
if __name__ == '__main__':
t0 = time.time()
video_dirs = os.path.join(BASE_DIR, "1.mp4")
cap = cv2.VideoCapture(video_dirs)
while cap.isOpened():
success, frame = cap.read()
if frame is None:
print('ERROR')
break
if success == True:
frame = process_frame_fg(frame)
cv2.imshow("segmentation", frame)
cv2.waitKey(1)
cap.release()
cv2.destroyAllWindows()运行结果
1.将背景扣掉
背景扣掉
2.将前景扣掉
前景扣掉
3.替换背景
背景替换
实时视频优化
选择一个函数进行优化(扣掉背景的)
完整代码
import cv2
import time
import numpy as np
from tqdm import tqdm
import mediapipe as mp
mp_pose = mp.solutions.pose
seg = mp.solutions.selfie_segmentation.SelfieSegmentation(model_selection=0)
def process_frame_fg(img):
start = time.time()
img.flags.writeable = False
results = seg.process(img)
mask = results.segmentation_mask.astype("uint8")
# 将其叠加成三通道
mask_channels = np.stack((mask, mask, mask), axis=-1) * 255
mask_channels = mask_channels > 0.5
# 背景的颜色定义
MASK_COLOR = [255, 255, 255]
# 背景大小与原图大小一致
fg_img = np.zeros(img.shape, dtype=np.uint8)
fg_img[:] = MASK_COLOR
# 如果mask_channels为True则显示img,如果为False则显示背景
FG_img = np.where(mask_channels, img, fg_img)
# 显示从原图中抠出人体,但是背景为我们重新设置的颜色
end = time.time()
FPS = 1 / (end - start)
FG_img = cv2.putText(FG_img, 'FPS' + str(int(FPS)), (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 3)
return FG_img
def out_video(input):
file = input.split("/")[-1]
output = "out-seg-" + file
print("It will start processing video: {}".format(input))
cap = cv2.VideoCapture(input)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# # create VideoWriter,VideoWriter_fourcc is video decode
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
out = cv2.VideoWriter(output, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
# the progress bar
with tqdm(range(frame_count)) as pbar:
while cap.isOpened():
success, frame = cap.read()
if not success:
break
try:
frame = process_frame_fg(frame)
out.write(frame)
pbar.update(1)
except:
print("ERROR")
pass
pbar.close()
cv2.destroyAllWindows()
out.release()
cap.release()
print("{} finished!".format(output))
if __name__ == '__main__':
video_dirs = "1.mp4"
out_video(video_dirs)运行结果
分割视频优化