论文阅读:Audio-Driven Emotional Video Portraits
文章目录
-
-
- 任务简介
- 方法
-
- 整体框架
- 交叉重构解耦-数据处理
- 交叉重构解耦-训练过程
- 目标自适应人脸合成
-
- audio to landmark
- 3D-Aware Keypoint Alignment
- edge to video
- 实验
-
- 衡量指标
-
任务简介
通过将声音分解为与持续时间无关的情绪空间和与持续时间相关的内容空间 可以都得到动态的2d landmark
然后作者提出了 Target-Adaptive Face Synthesis technique(目标自适应人脸合成技术)可以缩小推断的landmark和目标视频的自然头部姿态之间的gap
为了实现交叉重建训练,应该提供相同内容, 相同长度的不同情绪的成对句子, 但是现实场景中是不可能的,为此使用Dynamic Time Warping (DTW) 帮助使用对齐的不等长语料库形成伪训练对。
方法
整体框架
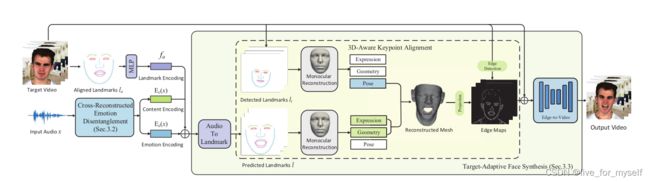
首先从音频信号中提取分离的内容和情感信息。是通过DTW算法生成的伪训练对,然后用交叉重构损失来学习解耦。
算法的第二部分是目标自适应人脸合成, 它将从音频中推断的landmark适配到目标视频中。具体是设计了一种3D-Aware Keypoint Alignment算法, 在三维空间中旋转landmarks,从而使landmarks能够适应各种姿势和运动。最后通过edge合成图片
可以把最后的edge变成cycle形式的
交叉重构解耦-数据处理
从音频信号中提取两个独立的潜在音频空间:i)与持续时间无关的空间情感编码;ii)与持续时间相关的空间,它对音频的语音内容进行编码。
但是这样的训练对比较难得,所以需要首先构建伪训练对。然后再进行交叉重构。
MEAD这个数据集满足相同内容不同情绪, 但是不同的情绪的语音速率是不同的, 所以采用temporal alignment*(时间对齐算法)来对齐长度不均匀的语音。

这块后续看看代码
交叉重构解耦-训练过程
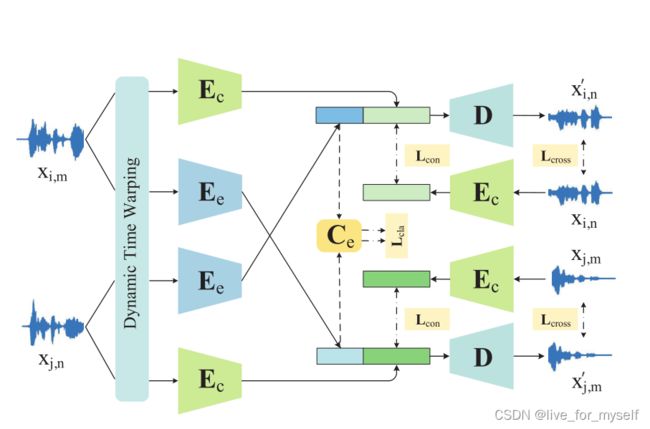
x_im 代表内容i, 情绪m, E_c是内容编码, E_e是情绪编码
假如情绪完全解开的时候, 可以通过对x_im的内容编码 ,即E_c(x_im), 和x_in的情绪编码, 即E_e(x_in)来重构出 x_in, 当然需要通过解码器D.
给定4个样本, 分别如下
![]()
情绪和内容互换了两次
用一个损失函数来监督训练过程,包括四个部分:交叉重建损失、自我重建损失、分类损失和内容损失。
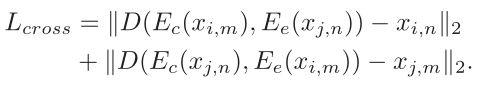
使用不同内容, 不同情绪的两个样本分别对情绪和内容进行重构
下面是自我重构:
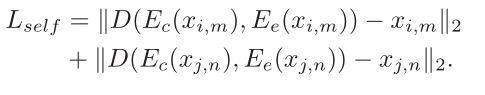
这个很容易理解.
为了促进情绪编码器 E e E_e Ee 把具有相同情绪的样本映射到latent space的clustered groups,为情绪embeding增加了一个分类器
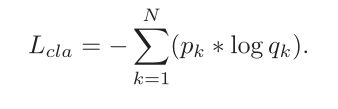
N是情绪的个数, p_k是是否使用情感标签,q_k是相应的网络预测概率, 此外还限制内容embedding
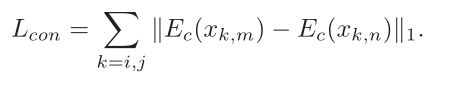

总的损失就是这样, 还有参数控制权重
目标自适应人脸合成
一般说来我们通过音频得到的landmark不能直接使用, 因为是通过音频内容得到的, 头部姿态啥的没有, 要是直接用到图像转换上, 看起来就很奇怪.
所以这里先将生成的landmark和3d空间的点对齐(align our generated landmarks with guidance landmarks in the 3D space). 然后将处理过的landmark和目标图像的边缘图合并, 通过图片到图片得到最终结果
audio to landmark
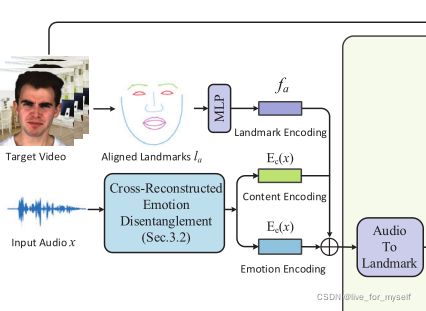
这里的f_a是从对齐的landmark中提取身份信息. 然后f_a和内容编码及情绪编码一块送入这个模块.
通过LSTM预测landmarks位移, 损失如下:
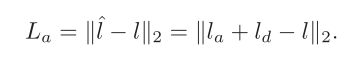
l为真值, l^为预测的
3D-Aware Keypoint Alignment
这部分是使用3D模型进行姿势对齐
![]()
l_p是投影后的2d landmark
edge to video
使用边缘检测算法提取人脸区域外的边缘,并用对齐的landmarks替换原始的。然后连接相邻的面部landmarks来创建面部草图。条件GAN架构图片到图片生成。(主要用了pix2pix的升级, video2video)
实验
面部视频为25帧, 音频采样为16khz, 音频是参考论文(Hierarchical cross-modal talking face generation with dynamic pixel-wise loss)里的设计, 提取和视频每帧对应的28*12维MFCC, 这里我可以使用deepspeech, 同时还可以使用3D人脸的预测。
在训练解耦模块之前,通过情绪分类任务对情绪编码器进行预训练
(A new approach of audio emotion recognition.)
内容编码器在LRW数据集进行了预训练。
衡量指标
-
Landmark Distance(LD)
LD表示生成的landmark和记录的landmark之间的平均欧氏距离。 -
Landmark Velocity Difference(LVD)指连续帧之间地标位置的差异,因此LVD表示两个序列之间地标运动的平均速度差异。
在口腔和面部区域采用LD和LVD来评估合成视频分别代表准确的嘴唇运动和面部表情的程度。
为了进一步评估不同方法生成的图像的质量,我们比较了SSIM、PSNR和FID分数。