初识BoTNet:视觉识别的Bottleneck Transformers
初识BoTNet:视觉识别的Bottleneck Transformers

杂谈
最近,我的思想有点消极,对自己的未来很迷茫,不知道要从事什么,又在担心行业的内卷严重,有几篇论文看完了也没有写文章总结,这也是为什么我有时候不怎么更新的原因。一边否定自己,一边又给自己力量。也许科研道路就是要黑暗中前行,我们需要给自己一束灯光,或做自己的太阳。在消极的时候,我一般会看点书,电视剧或电影,出去散步或者锻炼。人生宝贵,也许有些事情我们无法改变。但如何提升自己却可以由我们自己决定。未来还有无数美好,在等着与更好的你相遇。请相信,那些你流过的汗,读过的书,走过的路,兴国的山,最终都会回馈到自己身上。
前言
Bottleneck Transformers for Visual Recognition
代码
BoTNet:一种简单却功能强大的backbone,该架构将自注意力纳入了多种计算机视觉任务,包括图像分类,目标检测和实例分割。该方法在实例分割和目标检测方面显著改善了基线,同时还减少了参数,从而使延迟最小化。
创新点

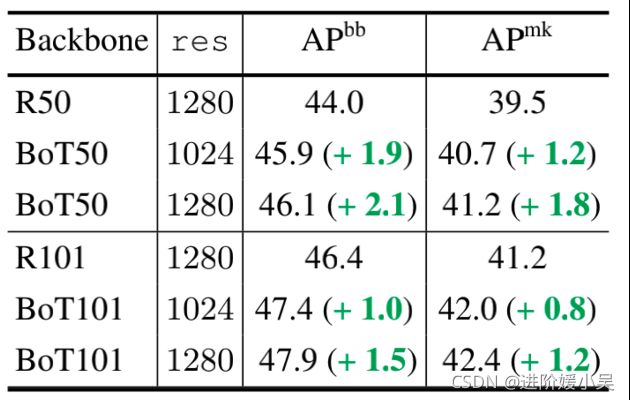
左边的是ResNet的bottleneck结构,右边的是引入multi-head self-attention的bottleneck,称作BoT。两者唯一的不同在3*3的卷积和MHSA,其它的没有任何区别。在Mask RCNN中的ResNet50加入BoT,并且其它超参不变的情况下,COCO实例分割的beachmark的mask AP提升了1.2%。
论文就是修改经典网络ResNet,用Multi-Head Self-Attention替换ResNet Bottleneck中的3*3卷积,其他不进行修改。这一个简单的改变,就能使性能提升。

BoTNet是一个混合模型(CNN + Transformer)。近期华为诺亚也使用这种混合模型提出了CMT。
CMT: Convolutional Neural Networks Meet Vision Transformers
代码
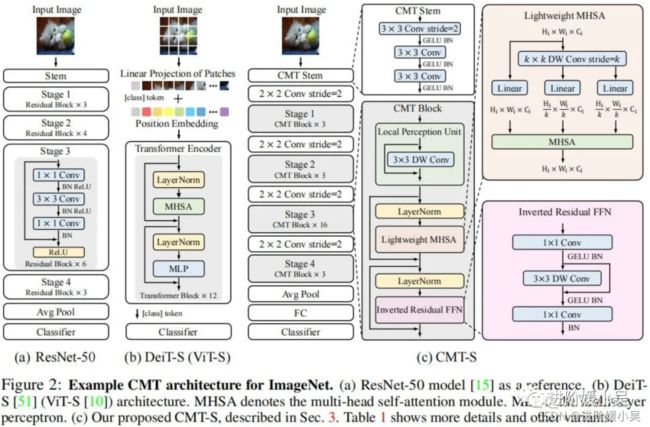
DeiT直接将输入图像拆分为非重叠图像块,图像块的结构信息则通过线性投影方式弱建模。采用类似ResNet的stem架构,它由三个3*3卷积构成,但激活函数采用了GELU,而非ResNet的ReLU。
类似经典CNN(如ResNet)架构设计,所提CMT包含四个阶段以生成多尺度特征(这对于稠密预测任务非常重要)。为生成分层表达,在每个阶段开始之前采用卷积降低特征分辨率并提升通道维度。在每个阶段,堆叠多个CMT模块进行特征变换同时保持特征分辨率不变,每个CMT模块可以同时捕获局部与长距离依赖关系。在模型的尾部,我们采用GAP+FC方式进行分类。
上表给出了所提方法与其他CNN、Transformer的性能对比,从中可以看到:
- 所提CMT取得了更佳的精度,同时具有更少的参数量、更少的计算复杂度;
- 所提CMT-S凭借4.0B FLOPs取得了83.5%的top1精度,这比DeiT-S高3.7%,比CPVT高2.0%;
- 所提CMT-S比EfficientNet-B4指标高0.6%,同时具有更低的计算复杂度。
回顾ResNet
带你读论文系列之计算机视觉–ResNet
ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。

注意:主分支与shortcut的输出特征矩阵shape必须相同。
ResNet-34层网络结构

网络中的亮点:
- 超深的网络结构(突破1000层)
- 提出Residual模块
- 使用Batch Normalization加速训练(丢弃Dropout)
网络并不是越深越好。
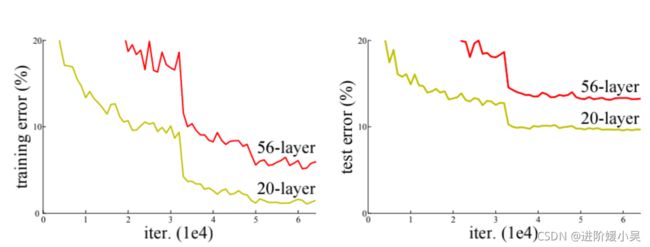
原因:
- 梯度消失或梯度爆炸
- 退化问题
可以通过对数据的标准化,权重初始化和BN处理,解决梯度消失或梯度爆炸的问题。而退化问题能通过残差结构不断加深网络获得更好的效果。
BotNet详解

左边可以看作是传统的Transformer模型,中间就是本文主角BoTNet,右图就是一个BoT block。
带有MHSA层的ResNet botlteneck可以被看作是具有bottleneck的Transformer块。,但有一些细微的差别,如剩余连接、归一化层的选择等等。
Transformer中的MHSA和BoTNet中的MHSA的区别:
1、 归一化,Transformer使用 Layer Normalization,而BoTNet使用 Batch Normalization。
2、非线性激活,Transformer仅仅使用一个非线性激活在FPN block模块中,BoTNet使用了3个非线性激活。
3、输出投影,Transformer中的MHSA包含一个输出投影,BoTNet则没有。
4、优化器,Transformer使用Adam优化器训练,BoTNet使用sgd+ momentum
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 这样的发展历程。
算法固然美好,数据才是根本。
先用Adam快速下降,再用SGD调优
-
什么时候切换优化算法?——如果切换太晚,Adam可能已经跑到自己的盆地里去了,SGD再怎么好也跑不出来了。 -
切换算法以后用什么样的学习率?——Adam用的是自适应学习率,依赖的是二阶动量的累积,SGD接着训练的话,用什么样的学习率?
优化算法的选择和使用方面的一些tricks
1、首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑 SGD+Nesterov Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam);
2、 选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
3、 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
4、根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
5、先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size. [2])因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
6、 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
7、数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
8、训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
9、 制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。

上图是ResNet-50和BoTNet-50的区别,唯一的不同在c5。而且BoTNe-50t的参数量只有ResNet-50的0.82倍,但是steptime略有增加。
只将ResNet的c5 block中的残差结构替换为MHSA结构。
实验结果
BoTNet vs ResNet
设置训练策略:一个训练周期定义为12个epoch,以此类推。

Multi-Scale Jitter对BoTNet的帮助更大

就是对分辨率的一个多尺度变化。从上图可以得出图像分辨率越大,它提升的性能越高。
加入 relative position encodings ,还能进一步提升性能!

第一行是R50什么夜不加,原始的ResNet;第二行只加了自注意力机制,提升了0.6;第三行只加了相对位置编码。相对位置编码比自注意力机制提神的性能要高一点。第四行,加入了自注意力机制和相对位置编码,性能提升了1.5;第五行加入了自注意力机制和绝对位置编码只提高了0.4。
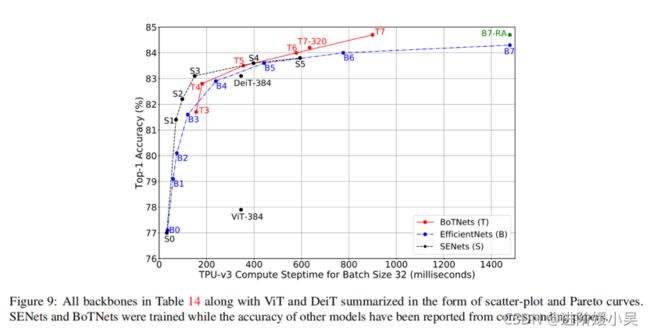
这个图是几个网络性能的对比图。BoTNet是红色线,SENet是黑色线,EfficientNet是蓝色线。T3和T4的性能比SENet差一点,而在T5的时候两者性能差不多。这可以得出纯卷积模型在准确率上可达到83%。T7准确率达到84.7%,与EfficientNet B7的精度相当,效率提升了1.64倍,BoTNet的性能优于DeiT-384。
BoTNet要替换ResNet中的3*3的卷积部分代码

MHSA的部分代码


总结
- 在没有任何附加条件的情况下,BoTNet使用Mask R-CNN框架在COCO实例分割基准上取得了44.4%的MaskAP和49.7%的Box AP;
- 卷积和混合(卷积和self-attention)模型仍然是很强的模型;
- 在ImageNet上BoTNet高达84.7%的top-1精度,性能优于SENet、EfficientNet等
与这篇论文思路相似的论文,还有京东AI开源的ResNet变体CoTNet–即插即用的视觉识别模块。
论文
代码


京东AI研究院梅涛团队在自注意力机制方面的探索,不同于现有注意力机制仅采用局部或者全局方式进行上下文信息获取,他们创造性的将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块,它可以直接替换现有ResNet架构Bottleneck中的卷积并取得显著的性能提升。无论是ImageNet分类,还是COCO检测与分割,所提CoTNet架构均取得了显著性能提升且参数量与FLOPs保持同水平。比如,相比EfficientNet-B6的84.3%,所提SE-CoTNetD-152取得了84.6%同时具有快2.75倍的推理速度。

用"CoT模块",它可以直接替换现有ResNet架构Bottleneck中的卷积并取得显著的性能提升。无论是ImageNet分类,还是COCO检测与分割,所提CoTNet架构均取得了显著性能提升且参数量与FLOPs保持同水平。比如,相比EfficientNet-B6的84.3%,所提SE-CoTNetD-152取得了84.6%同时具有快2.75倍的推理速度。

具体来说,CoTNet-50直接采用CoT替换Bottlenck中的卷积;类似的,CoTNeXt-50采用CoT模块替换对应的组卷积,为获得相似计算量,对通道数、分组数进行了调整:CoTNeXt-50的参数量是ResNeXt-50的1.2倍,FLOPs则是1.01倍。
可以看到:
- 所提CoTNet、CoTNeXt均具有比其他ResNet改进版更优的性能;
- 相比ResNeSt-50,ResNeSt-101,所提CoTNeXt-50与CoTNeXt-101分别取得了1.0%与0.9%的性能提升;
- 相比BoTNet,所提CoTNet同样具有更优的性能;甚至于,SE-CoTNetD-152(320)取得了比BoTNet-S1-128(320)、EfficientNet-B7更优的性能。
