独家 | 给初级数据科学家的8点建议(附学习资源)
作者:Robert Chang
翻译:苏金六
本文长度为5300字,建议阅读10分钟
Robert Chang曾在Twitter供职,如今在Airbnb也已经工作了两年。回顾自己成为高级数据科学家,他为刚踏入数据科学家这条道路的新人写下了数条意见,覆盖道路的选择、工具的选择以及学习计划的制定等方面。
动机
两年前,我分享了在行业内做数据科学工作的一些经验(https://medium.com/@rchang/my-two-year-journey-as-a-data-scientist-at-twitter-f0c13298aee6)。本来只是我个人的回忆总结,以庆祝我在Twitter整两周年。但后来我还是发布在了Medium上,因为我相信这些总结能帮助那些有抱负的数据科学家。
转眼就来到2017年,我在Airbnb也工作了将近两年。最近我终于成为了高级数据科学家。这个称号用来表明一个人已经获得一定水平的专业知识了。当我回顾我的职业生涯,并展望下一步规划,我再次写下在我职业生涯的早期就应该知道的经验。
如果我早期教程帖的目标读者是那些有志于数据科学的新人,那么这篇文章是写给那些已经步入数据科学行业但还只是刚刚起步的人们。我写这篇教程贴一方面是为了督促自己别忘记那些重要的学习心得,另一方面也是想勉励刚步入数据科学的奋斗者。
你在哪条主流道路上?
Philip Guo是一位学术成就斐然的博主。他回忆总结了他作为学生、实习生和研究员期间和各位导师的交流经验。在他的帖子《你在哪条主流道路上》(http://www.pgbovine.net/critical-path.html)里,他这么写的:
“如果我为了事业发展而站在导师的主流道路上,那么他们会竭尽全力来帮助我。相反的,我只能孤零零的靠自己了。所以当你站在别人的主流道路上,你就能把自己的成功和别人的成功捆在一起,依靠别人的资源,一起努力,一起成功。”

照片来源:Daniel Han
这种工作机制非常简单直观。我希望我在职业生涯早期,像在选项目、选团队甚至斟酌为哪个导师或公司工作的时候,就已经深知此理。
例如,还在Twitter工作的时候,我一直就想研究机器学习。但是我的团队尽管非常依赖数据,却更需要数据科学家关注实验设计和产品分析。我竭尽全力却仍然不能将个人想法和团队计划融合起来。
因此,我一到Airbnb就目标明确,就是要加入一个机器学习会起重大作用的项目或团队。我和我的经理一起确认了好几个有前途的项目,其中一个就是为Airbnb的客户终身价值(LTV)评估建模。
这个项目不仅对我们的工作很重要,还对我个人职业发展也很重要。我学习了很多机器学习大规模建模(https://medium.com/airbnb-engineering/using-machine-learning-to-predict-value-of-homes-on-airbnb-9272d3d4739d)的流程知识。没有什么学习方法比直接投身于解决具体的商业问题中更有效了。
毫无疑问,我很幸运能找到一个项目,既能实现我的抱负,又能培养我的技能。我相信站在导师主流道路上来选项目的方法能让我们越来越“幸运”,能将我们的抱负和从事的项目完美的结合在一块。
我学到的经验:我们都有自己想去培养发展的技能和兴趣爱好。因此一定要权衡好我们的抱负和主流道路的关系。找项目、团队和公司的时候,要确保主流道路和你的抱负相匹配。
为问题选择正确的工具
在进Airbnb之前,我一直用R和dplyr(https: //github.com/tidyverse/dplyr)在编程。开始着手LTV项目后,我很快发现我应当交付的不应该是一段分析代码,而是一个机器学习生产工作流。考虑使用Python语言能更容易地在Airflow(https://medium.com/the-astronomer-journey/airflow-and-the-future-of-data-engineering-a-q-a-266f68d956a9)中建立复杂的工作流,我陷入了两难处境——我该不该从R转到Python?

图片来源:quickmeme.com
(除了R和Python以外,Excel也是一个有力的竞争者)
这在数据科学家当中是个非常普遍的问题,因为大家都在纠结于选择哪一种语言。对我来说,中途更换编程语言的成本明显太大。我权衡利弊,思前想后,但是想的越多,反而思维越瘫痪。这是一篇关于选择R还是Python的有趣分析(https://blog.dominodatalab.com/video-huge-debate-r-vs-python-data-science/)最终,Reddit上的回复(https://www.reddit.com/r/Python/ comments/2tkkxd/considering_putting_my_efforts_into_python/)让我摆脱了困惑:
“与其去纠结选择学习哪一种编程语言,不如去想想哪一种语言能够提供最好的领域特定语言(DSL),从而来解决你的问题。”
工具是否合适总是取决于环境和问题属性的。问题不是我该不该学习Python,而是Python是否适合我的工作。为了更好的阐述这个观点,下面是一些例子:
如果你的目标是想应用最前沿最高端的统计方法,R应该是你最好的选择。为什么了?因为R就是统计学家设计出来的,也是为统计学家服务的。如今,学者们不仅仅在论文中,还在R包中发布他们的研究成果。每一周都会有很多有趣新颖的R包在CRAN(https://cran.r-project.org/ mirrors.html)上发布,例如此篇(https://github.com/susanathey/causalTree)。
另一方面,Python特别适合建立生产数据工作流,因为它是一个通用编程语言。例如你可以用Python UDF(http://www.florianwilhelm.info /2016/10/python_udf_in_hive/)来打包scikit-learn模型(http://scikit-learn.org/stable/),从而在Hive中做分布式评分(Distributed Scoring),可以用复杂逻辑来编写Airflow DAG,也可以写一个Flask网页app用来在浏览器中展示模型的输出值。
对于我自己的项目,我需要建立一个批量机器学习工作流。如果我用Python的话,那么我的工作肯定会容易很多。最终,我卷起袖管,开始了新的挑战。
我学到的经验:与其死盯着一种技术或编程语言,不如多问问自己,什么工具或技术最能帮我解决问题?关注问题的解决,那么工具自来。
建立学习项目
虽然我之前从来没有使用Python做过数据科学工作,但还是或多或少接触过Python语言(https://medium.com/@rchang/learning-how-to-build-a-web-application-c5499bd15c8f)。不过,我的确从来没有接受过Python的基础知识学习。因此,每当代码组织成一个个类(https://jeffknupp. com/blog/2014/06/18/improve-your-python-pythonclasses-and-object-oriented-programming/)的时候,我都很惶恐,经常不知道__init__.py是用来干啥的(https://stackoverflow.com /questions/448271/what-is-init-py-for)。
这次为了学好基础,我从Anders Ericsson关于刻意训练(https://www.amazon.com/Peak-Secrets-New-Science-Expertise/dp/1531864880)的研究中寻找灵感:
“刻意训练是专门为了有效提高个人特定方面的表现而一般由老师设计的训练。”
考虑到我是我自己的老师,Dr. Ericsson的观点对我帮助很大。例如,我首先整合了一套与用Python来做机器学习的相关程度最高的材料来开始学习项目。我花费了好几周的时间才确定了个人学习大纲(https://github.com/robert8138 /python-deliberate-practice)。为了确保大纲的有效性,我让Python大牛帮我检查了大纲。所有的准备工作都是为了确保我在正确的学习道路上。
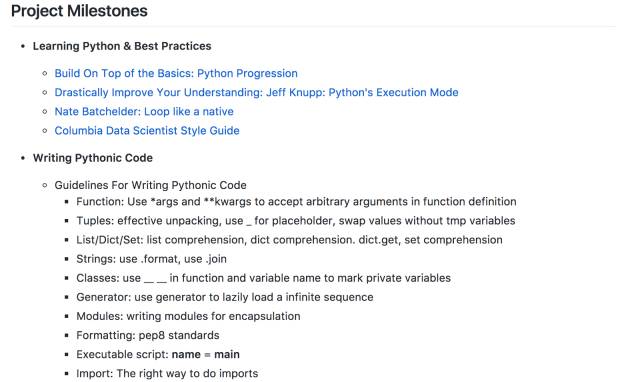
我的个人学习大纲的一部分
一旦我制定了明确的大纲,我就会把如下这些策略运用在刻意训练上:
-
反复训练:我强迫自己用Python而不是用R来进行大量枯燥的、无明确目的的分析。这降低了我的工作效率,但是却让我更加熟悉Pandas(http://pandas.pydata.org/)的基础API。当然也不必受困于紧急的截止日期。
-
建立反馈圈:我找机会来看别人的代码,必要时也会去修补几个bug。例如,我努力在使用以前先去理解Python标准库是怎么设计的。当我写自己的代码的时候,我会不断的重构,让更多的人能够看懂。
-
通过整合和回忆来学习:每周结尾,我都会写下每周进程(https://github.com /robert8138/python-deliberate-practice/blob/master/Planning.md),包含着我的学习资源,我学习的概念和重要思考内容。通过回忆学过的材料,我能更好的消化概念。
渐渐地我每周的状态都在变好,虽然过程很艰难。好多次我都要查阅R和Python的基本语法,因为我得在两种语言之间来回转换。我告诉自己,这是一个长期投资,当我投身机器学习项目后一定会有好的回报的。
我学到的经验:很多现场试验(https://qz.com/978273 /a-stanford-professors-15-minute-study-hack-improves-test-grades-by-a-third-of-a-grade/)证明了一点,在投入项目之前,提前规划会有助于训练更深度。重复、整合、回忆和收集反馈都是用来强化学习的重要途径。
和数据科学大牛合作
刻意训练的关键因素之一就是能够收到及时准确的反馈。没有哪个运动员、音乐家或数学家能够不接受培训和反馈就能取得成功。
我从那些有强烈的成长型思维(https://www.ted. com/talks/carol_dweck_the_power_of_believing_that_you_can_improve/up-next)的人身上发现了一个特点,就是他们不会羞愧与自己在某方面的无知,而是经常寻求他人给予反馈。
回顾我的个人学术和职业生涯,我多次自检我的问题纯粹是因为我不想让自己显得很无知。然而,我渐渐发现这种心态是相当不好的。从长期来看,多次的自检出的问题都是学习的好机会,而不是用来羞愧的。

图片来源:edutopia——拥有成长型思维非常重要!
在这个项目之前,我对如何将机器学习应用到生产(https://www.slideshare.net/mobile /SharathRao6/lessons-from-integrating-machine-learning-models-into-data-products)知之甚少。为了项目我做过很多决定,其中最好的决定就是坦荡清楚向同事说明我对机器学习的所知甚少和强烈的学习欲望。我向他们保证,我学到的知识越多,就能越帮助他们。
这成为了一个非常好的策略,因为人们一般喜欢分享他们的知识,特别是当他们知道了教学相长的道理。下面几个例子就说明了如果没有我同伴的指导我自己不会学习的那么快:
-
Scikit-Learn工作流( http://scikit-learn. org/stable/modules/generated/sklearn.pipeline.Pipeline.html):我的同事建议我去使用Scikit-Learn 工作流来使我的编码更加模块化。本质上,工作流定义了一系列贯穿于训练和评分(Scoring)而一直不变的数据转换。这个工具使我的编码更加清晰,更有用,和其他生产模型更兼容。
-
模型诊断:考虑到我们的预测问题涉及时间,我的同事告诉我经典交叉验证方法并不管用,因为我们存在用未来的数据来验证过去的风险。而一个更好的办法就是时序交叉验证。(https://robjhyndman.com/ hyndsight/tscv/)我还学习了很多不同的诊断技术,例如lift chart(https://www.ana lyticsvidhya.com/blog/2016/02/7-important-model-evaluation-error-metrics/),像SMAPE(https://en.m.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error)的各种评估矩阵等。
-
机器学习基础架构:在机器学习基础架构工程师的帮助下,我学会了如何通过virtualenvs来管理包的相互依赖,如何通过pickling(https://docs.python.org/3/library/pickle.html)来序列化模型,如何使用Python UDF(http://www.florianwilhelm.info/2016/10/python_udf_in_hive/Udf)来确保模型可以运用到评分(scoring)中。所有这些都是我以前所不知道的数据工程技能。
我学习了很多新概念之后,我不仅能将他们运用到我自己的项目中,我还能和机器学习基础架构团队进行深入探讨,从而让他们能够为数据科学家建立更好的机器学习工具。这形成了一个良性循环,因为分享给我的知识让我能够成为一个更好的合作者。
我学到的经验:长期来看,多数自检出的问题都是用来学习的好机会,而不是用来羞愧。清楚坦荡的展示你的学习欲望,让你变得越来越好,越来越有用。
教学和宣讲
当我越来越能将我的模型运用到生产上,我发现我掌握的很多技能对我们团队其他数据科学家很有价值。当了本科毕业生导师好几年,我对教学一直充满热情。当我成为老师的时候,我对知识本身也更加熟悉。诺贝尔奖得主,也是一个优秀的老师(https://m.youtube.com/watch?v=0KmimDq4cSU),理查德-弗雷曼阐述了他的教学观:
曾经加州理工学院一个教员问理查德-弗雷曼如何解释粒子1/2自旋是符合费米统计的。接受了这个挑战后,他说到,“关于这个,我会准备一场入门级别的讲座。”但是几天之后,他告诉教员,“我实在做不到,我没有办法把讲座简单化到入门级别。这意味着我们还没有实际搞懂它。”
这个故事很有启发。如果你不能把一个问题简化到核心,从而让别人也能够理解,那么这就意味着你还没有真正理解。知道教学相长这个道理后,我寻找机会来证明我的模型,鼓励其他人尝试我的模型。这是一个双赢的局面,因为宣讲能提升重视度,好在团队当中运用开来。
在九月底,我开始和我们内部的数据大学(https://medium.com/airbnb-engineering/how-airbnb-democratizes-data-science-with-data-university-3eccc71e073a)团队开始准备一系列关于机器学习内部工具的课程。我并不是很清楚这会走到哪一步,但是我很开心能够在Airbnb工作期间开展更多的教学工作。
最终,我以推特上Hadley Wickham (https://mobile. twitter.com/hadleywickham)的帖子来总结下:

(https://mobile.twitter.com/hadleywickham/status/890107458219368448)
我学到的经验:教学是检验你对知识的理解程度和提高技能的最有效办法。当你学到了有价值的东西后,记得和别人分享。你也不必总是想着要去创造新的软件,解释目前现有工具怎么运行的也很有价值。
在第K步时,想想第K+1步
从一开始只关注我自己的任务,到后来和机器学习基础架构团队合作,再后来帮助其他数据科学家更多地了解机器学习工具,我非常开心,因为我的项目领域相比于前几个月扩大了很多。我承认我一开始并没有想到会这样。
当我回头反思项目发展过程,一个有别与我之前项目的地方就是我对于现状总有一点不满意,我总希望能够再好一点。Claude Shannon的文章(https://medium.com/the-mission/a-genius-explains-how-to-be-creative-claude-shannons-long-lost-1952-speech-fbbcb2ebe07f)最能阐明此点:

图片来源:A Mind at Play:How Claude Shannon Invented the Information Page封面
“有一种心态叫永不满足。我说的不是那种对世界的悲观式不满,我也不希望那样。我指的是一种具有建设意义的不满。不满可以用文字表达,这没问题,但是我觉得事情可以做的更好。一定有更加简洁的方法。事情一定能得到改善。换句话说,当事情看起来不那么完美的时候,总有一股轻微的愤怒。我觉得对现状的不满是优秀科学家的重要驱动力。”
我还算不上是一个合格的科学家,虽然我有一个高级数据科学家的头衔。但是我相信这种不满足感的性格特点能够决定一个人是否能够扩大项目的影响力。整个项目中,当我在第K步时,我会自然的开始想着第K+1步该怎么做。而且:
-
从“我不知道怎么建模,让我来探索下”到“我觉得工具可以再优化下,这是我的思考成果,关于如何优化工具的一些建议和反馈”,我把自己从一个顾客改造成了机器学习基础架构团队的合作者。
-
从“让我来学习这些工具,好让我熟练操作”到“让我们来修改下这些工具,让更多的有志于机器学习的数据科学家能够使用这些工具”,我把自己从一个合作者改造成了一个宣传者。
我觉得这种思维方式极有帮助。用你的好品味和不满足感来推动你持之以恒的努力。也就是说,我不认为这种不满足感是可以凭空制造的,它只能来自于你对关心问题的处理过程中。
我学到的经验:为了一个项目奋斗的时候,要关注你内心的不满足感。那是你提高技能和提升项目到更高阶段的秘诀。
割舍思维:你和你的工作
最近,我偶然听到了来自Richard Hamming(https://en.m.wikipedia.org/wiki/Richard_Hamming)的讲座。Richard Hamming是众所周知的数学家,有很多科学贡献,例如汉明码和汉明距离。讲座的标题是“你和你的研究”(https://m.youtube.com/watch?v=a1zDuOPkM
Sw),不过Richard Hamming说标题也可以命名为“你和你的事业”。
当他分享他的故事的时候,几点想法映入我的脑海:
“如果你正在做的事情不重要,以后也不可能重要,那么你为什么还要去做这些事情了?你必须做重要的事情。好多年我都会在周五的下午来思考在我的领域什么问题是重要的,这占据了我所有工作时间的10%。”
让我来提醒你什么是重要的问题。重要指的不是结果,一些问题不重要是因为你还没有受到别人的抨击。很大程度上,问题是否重要取决于你是否有方法来解决问题。
“整个课程我都是在试着告诉你关于风格和品味的道理,好让你有一点感觉,知道什么时候问题才是对的,什么问题才是对的,怎么去解决这个问题。在正确的时间用正确的方法去解决正确的问题才是最重要的,别的都可忽略。”
当Hamming博士说到重要性的时候,这是因人而异的。对他自己来说,科学问题很重要。对我们大多数,可能就是别的问题很重要。他还谈到抨击的重要性。如果你连抨击的想法都没有,那么无论结果怎么重大,问题都不重要。最后,他还提到要用自己的风格和品味去做事情。
他做事的标准极高,但这是值得追求的。当你找到自己的重要问题时,你就会自然而然的想着把它做好,让它更有影响力。你会想法设法的告诉别人它的重要性,你会花时间去从牛人身上学习来建立自己的知识体系。
在你奋斗道路上,什么问题对你很重要了?
原文链接:
https://medium.com/@rchang/advice-for-new-and-junior-data-scientists-2ab02396cf5b
原文标题:
Advice For New and Junior Data Scientists----What I Would Have Told Myself a Few Years ago

苏金六,安徽大学应用物理专业本科生,东南大学英语口译专业硕士生。四年的物理理论知识学习和系统的物理实验扎实了我的物理基础。兴趣使然又让我走上口译之路。自我评价为综合性人才。主要擅长科技文献翻译。希望在THU数据派的工作能进一步提升自我,也认识更多的朋友。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至[email protected]


点击“阅读原文”加入组织~