aurora_8b10b通信
讲述aurora8b10B 的各种模式,以及控制方式
概述
本课内容讲解XILINX 官方的Aurora 8B/10B IP core的使用。以下内容大部分是基于官方datasheet的翻译。有不少不完善之处,建议读者和英文datsheet一起对比阅读。
这个IP支持Kintex®-7, Virtex®-7 FPGA GTX 和GTH 收发器,Artix®-7 FPGA GTX 收发器, Zynq®-7000 GTX and GTX收发器。Aurora 8B/10B IP core可以工作于单工或者全双工模式。IP CODE 的使用也非常简单,支持AMBA®总线的AXI4-Stream协议。本课是用过外部的光纤线链接的,实际使用中也可以直接用在开发板之间链接,实现板子到板子的通信。本课程内容可以参考XILINX 官方文档PG046。
图2-1-1是Aurora 8B/10B IP core简单的一个应用方式。对于用户来说,从应用角度,我们主要掌握IP CORE的使用以及正确编写用户逻辑代码。
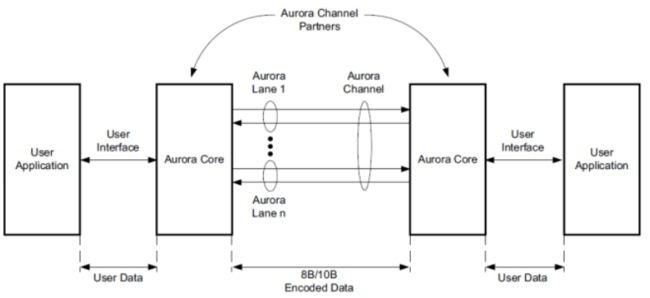
图2-1-1 Aurora 8B/10B Channel Overview
Aurora 8B/10B IP core具备很多优点,当一条通道联通的时候,它会自动初始化这条通路,并且以帧或者数据流的方式,发送一些测试数据。而且在正常通信的过程中,可以发送任意大小的帧,以及数据可以再任何时候中断。传输过程中有效数据字节之间的间隙会自动填充空闲,以保持锁定并防止过多的电磁干扰。流量控制可用于降低传入数据的速率或通过通道发送简短的高优先级消。Stream流传输是单一的,无限的帧。 在没有数据的情下,传送空闲以保持链接活着。 Aurora 8B/10B内核使用8B/10B编码规则检测单位和大多数多位错误。 过多的位错误,断开连接或设备故障导致内核复位并尝试重新初始化新通道。
Aurora 8B/10B IP的用途:
1)、芯片到芯片的链路:
替换高速串行连接的芯片之间的并联连接可以显着减少PCB上所需的迹线和层数。 核心提供了使用GTX,GTX和GTH收发器所需的逻辑,FPGA资源成本最低。
2)、板对板和背板连接:
IP CORE使用标准的8B / 10B编码,使其与现有的电缆和背板硬件标准兼容。 Aurora 8B / 10B内核可以在线速率和通道宽度上进行缩放,以便在新的高性能系统中使用便宜的传统硬件。
- 、单向连接(单向):
Aurora协议提供了替代方法执行单向通道初始化,使GTX,GTX和GTH收发器在没有反向通道的情况下使用,并降低由于未使用的全双工资源而造成的成本。
2.2 Aurora 8B/10B IPCORE 描述

图2-2-1 Aurora 8B/10B Core Block Diagram
Lane Logic(通道逻辑):
每个GTX,GTX或GTH收发器(以下称为收发器)由通道逻辑模块的实例驱动,其初始化每个单独的收发器并处理控制字符的编码和解码以及错误检测。
Global Logic(全局逻辑):
全局逻辑模块执行通道初始化的绑定和验证阶段。 在运行期间,模块会生成Aurora协议所需的随机空闲字符,并监视所有通道逻辑模块的错误。
RX User Interface(RX接收端口):
AXI4-Stream RX接收端口将数据从通道移动到应用程序,并执行流量控制功能。
TX User Interface(TX发送端口):AXI4-Stream TX发送端口将数据从应用程序移动到通道,并执行流量控制TX功能。 标准时钟补偿模块嵌入在内核中。 该模块控制时钟补偿(CC)字符的周期性传输。
2.2.1性能表现(Performance)
最高频率: 参见XILINX Performance and Resource Utilization web
Latency(延迟):
通过Aurora 8B/10B内核的延迟是由通过协议引擎(PE)和收发器的流水线延迟引起的。 随着AXI4-Stream接口宽度的增加,PE流水线延迟增加。 收发器延迟取决于所选收发器的特性和属性。
本节概述了Aurora 8B/10B核心AXI4-Stream用户端口对于2-byte-per-lane和4-byte-per-lane设计的user_clk周期的预期延迟。 为了说明延迟,Aurora 8B/10B模块被分为收发器逻辑和协议引擎(PE)逻辑,其在FPGA可编程逻辑中实现。
注意:这些数字不包括由于Aurora 8B / 10B通道的每一侧之间的串行连接长度而引起的延迟。
下图说明了默认配置的数据路径的延迟。 延迟可以根据设计中使用的收发器和IP配置而有所不同。

图2-2-1-1 Latency of the Data Path
从s_axi_tx_tvalid到m_axi_rx_tvalid的两字节成帧设计的最小延迟在默认核心配置的功能仿真中大约为37个user_clk周期如下图所示

图2-2-1-2 Aurora 8B/10B 2-Byte Latency
从s_axi_tx_tvalid到m_axi_rx_tvalid的默认四字节帧设计的最小延迟在功能仿真中大约为41个user_clk周期。
流水线延迟被设计为保持时钟速度。如果没有依赖关系,请检查延迟是否可以通过其他可选功能添加。
Throughput(吞吐量):
Aurora 8B/10B核心吞吐量取决于收发器的数量和线速度。 单通道设计到16通道设计的吞吐量分别为0.4Gb/s到84.48Gb/s。 通过Aurora 8B/10B协议编码和0.5Gb/s至6.6 Gb/s线路速率范围的20%开销来计算吞吐量。
2.2.2 端口说明 (Port Descriptions)
用于生成每个Aurora 8B/10B内核的参数决定了可用于该特定内核的接口。 接口在IP符号中可见,如图下图所示。 在IP符号中,如果左键单击界面旁边的+号,可以看到分组在其中的端口。 在本节中,也就是端口描述,一般来说,界面显示为单行条目,后面是分组在其中的端口。 例如,在表2-1(TX)中,USER_DATA_S_AXIS_TX是接口,s_axi_tx_ *端口分组到该接口中。 核心有四到六个接口。

图2-2-2-1`
注意:
1.选择小端点支持选项时,使用[n:0]总线格式。
2.选择大端支持选项时,使用[0:n]总线格式。
3.端口为高电平,除非另有说明。
用户接口(User Interface):
Aurora 8B/10B内核可以通过成帧或流用户数据接口生成。 该接口包括流或帧数据传输所需的所有端口。帧用户接口符合AMBA®AXI4流协议规范,包括发送和接收成帧用户数据所需的信号。流接口允许数据要发送没有帧分隔符,这样操作更简单,并且使用比帧接口少的资源。 数据端口宽度取决于通道宽度和所选通道数。
Top-Level Architecture(顶级架构)
Aurora 8B / 10B核心顶层(块级)文件实例化了车道逻辑模块,TX和RX AXI4-Stream模块,全局逻辑模块和收发器的包装器。 在示例设计中也实例化了时钟,复位电路,帧生成器和检测器模块。
下图展示了双工配置的Aurora 8B/10B内核顶层。 顶级文件是用户设计的起点。

图2-2-2-2 Aurora 8B/10B Core Block Diagram
本节提供了流和框架界面的详细信息。 用户接口逻辑应设计为符合相应接口的时序要求,如此处所述。
AXI4数据流位排序(AXI4-Stream Bit Ordering):
Aurora 8B / 10B内核采用升序排列。 它们首先发送和接收最高有效字节的最高有效位。 下图显示了Aurora 8B / 10B内核的AXI4-Stream数据接口的n字节示例。

图2-2-2-3 Top-Level Architecture
用户端口(User Interface Ports):
下表列出了双工和单工核心模块AXI4-Stream TX和RX数据端口的描述。
表2-2-2-1 User I/O Ports (TX)

表2-2-2-2 User I/O Ports (RX)

注:1.如果选择了流式接口选项,此端口不可用。
2.2.3 框架界面(Framing Interface)
下图显示了Aurora 8B/10B内核的成帧用户界面,AXI4-Stream兼容端口用于TX和RX数据。

2-2-3 Aurora 8B/10B Core Framing Interface (AXI4-Stream)
数据传输(Transmitting Data)
为了传输数据,用户应用程序操纵控制信号以使核心模块做到如下描述:
•从s_axi_tx_tdata总线上的用户端口获取数据
•s_axi_tx_tvalid和s_axi_tx_tready信号被断言。
•在Aurora 8B / 10B通道中划分数据。
•使用s_axi_tx_tvalid信号传输数据。 用户应用程序可以设置s_axi_tx_tvalid=0,以此插入空闲(引入停顿或暂停)。
•暂停数据(即插入空闲)(s_axi_tx_tvalid被取消置位)。
接收数据(Receiving Data)
当IPCORE接到数据时,它执行以下操作:
•检测和丢弃控制字节(空闲,时钟补偿,通道PDU(SCP),通道协议数据单元结(ECPDU)和PAD)。
•断开成帧信号(m_axi_rx_tlast)并指定有效字节数最后一个数据节拍(m_axi_rx_tkeep)。
•从车道恢复数据
•通过断言m_axi_rx_tvalid信号来组合数据以呈现给m_axi_rx_tdata总线上的用户接口。
只有当s_axi_tx_tready和s_axi_tx_tvalid都被断言时,Aurora 8B / 10B内核才能采样(高)。
AXI4-Stream数据仅在框架时有效。 帧外的数据将被忽略。 要启动一个帧,在s_axi_tx_tdata端口上的第一个数据字处于assert s_axi_tx_tvalid时。 要结束一个帧,在s_axi_tx_tdata端口上的数据的最后一个字(或部分字)上使用s_axi_tx_tlast,并使用s_axi_tx_tkeep来指定最后一个数据节拍中的有效字节数。
在单个字长或更短的帧的情况下,s_axi_tx_tvalid和s_axi_tx_tlast同时被断言。
2.2.3 Aurora 8B/10B 帧(Frames)
TX子模块将每个接收的用户帧通过TX接口转换为Aurora 8B / 10B帧。 帧开始(SOF)通过在帧开始处添加2字节的SCP代码组来指示。 帧结束(EOF)是通过在帧的末尾添加一个2字节的信道结束通道协议(ECP)码组来确定的。 数据不可用时插入空闲代码组。 代码组是8B / 10B编码字节对,所有数据都作为代码组发送,因此具有奇数个字节的用户帧具有称为PAD的控制字符,附加到帧的末尾以填写最终的代码组。 表2-3显示了具有偶数数据字节的典型Aurora 8B / 10B帧。
Length
用户应用程序通过操纵s_axi_tx_tvalid和s_axi_tx_tlast信号来控制通道帧长度。 Aurora 8B / 10B内核分别响应帧起始帧和帧结束顺序集,分别为/ SCP /和/ ECP,如表2-3所示。
表2-2-3-1:Typical Channel Frame
![]()
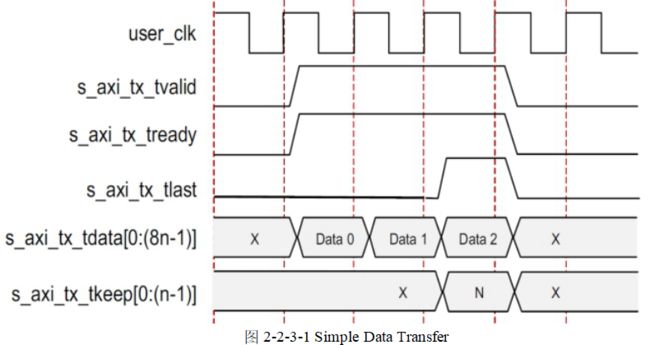
Example A: Simple Data Transfer(简单数据传输)
图2-2-3-1显示了一个宽度为n字节的AXI4-Stream接口上的简单数据传输示例。 在这种情况下,发送的数据量为3n字节,因此需要三次数据节拍。 s_axi_tx_tready被断言,表示AXI4-Stream接口准备好传输数据。
用户应用程序在前n个字节期间断言s_axi_tx_tvalid开始数据传输。 一个/ SCP /有序集放置在通道的前两个字节上,以指示帧的启动。 然后,第一个n-2个数据字节被放置在通道上。 由于/ SCP /所需的偏移量,每个数据节拍中的最后两个字节总是延迟一个周期,并在通道的下一个节拍的前两个字节上传输。
要结束数据传输,用户应用程序将在s_axi_tx_tkeep总线上断言s_axi_tx_tlast,最后的数据字节以及适当的值。 在这个例子中,s_axi_tx_tkeep在演示的波形中设置为N,表示所有字节在最后一个数据节拍中有效。 当s_axi_tx_tlast被断言时,s_axi_tx_tready在下一个时钟周期中被断言,并且核心使用数据流中的间隙来发送最终偏移数据字节和/ ECP /有序集,指示帧的结束。 s_axi_tx_tready在下一个循环中被重新生成,以允许数据传输继续。
Example B: Data Transfer with Pad(使用Pad进行数据传输)
图2-2-3-2显示了需要使用Pad的(3n-1)字节数据传输的示例。Aurora 8B / 10B内核根据协议要求为一个具有奇数个字节的帧附加一个Pad字符。 3n-1数据字节的传输需要两个完整的n字节数据字和一个部分数据字。 在此示例中,s_axi_tx_tkeep设置为N-1,以指示最后一个数据字中的n-1个有效字节。

图2-2-3-2 Data Transfer with Pad
Example C: Data Transfer with Pause(具有暂停的数据传输)
图2-2-3-3显示了在帧传送过程中用户端口如何暂停数据传输。 在这个例子中,用户应用程序在前n个字节之后暂停数据流,取消s_axi_tx_tvalid,并发送空闲。 暂停继续,直到s_axi_tx_tvalid被取消置位。
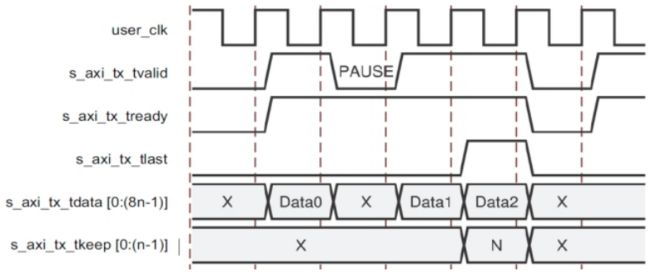
图2-2-3-3 Data Transfer with Pause
Example D: Data Transfer with Clock Compensation(带时钟补偿的数据传输)
当Aurora 8B / 10B内核发送时钟补偿序列时,会自动中断数据传输。 时钟补偿序列每10,000字节加上每个通道的12字节开销。
图2-2-3-4显示了Aurora 8B / 10B内核在时钟补偿序列期间如何暂停数据传输。
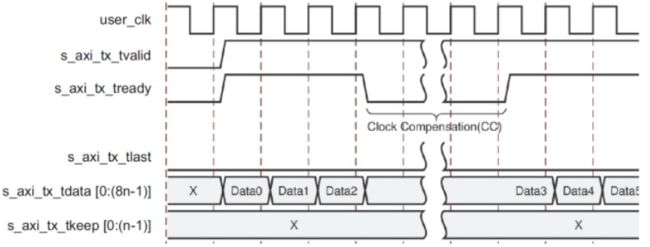
2-2-3-4 Data Transfer Paused by Clock Compensation
由于每通道需要每10,000字节的时钟补偿(每个通道设计的2个字节为5,000个时钟;每个通道设计为4个字节的2,500个时钟),因此您不能连续发送数据,也不能连续接收数据。 在时钟补偿期间,数据传输暂停六或三个时钟周期。
Receiving Data
RX子模块没有用于用户数据的内置弹性缓冲区。 因此,RX AXI4-Stream接口上没有m_axi_rx_tready信号。 用户应用程序控制来自Aurora 8B / 10B通道的数据流的唯一方法是使用核心可选流量控制功能之一。
m_axi_rx_tvalid信号与Aurora 8B / 10B内核的每帧的第一个字同时被断言。 m_axi_rx_tlast与每个帧的最后一个字或部分字同时断言。 m_axi_rx_tkeep端口指示每个帧的最终字中的有效字节数。m_axi_rx_tkeep信号仅在m_axi_rx_tlast被断言时有效。
即使在帧内,Aurora 8B / 10B内核也可以随时取消放置m_axi_rx_tvalid。即使帧最初传输没有暂停,内核也可能会偶尔解除m_axi_rx_tvalid。 这些暂停是框架字符剥离和左对齐过程的结果。
图2-2-3-5显示了由暂停中断的3n个字节的接收数据。 数据表示在m_axi_rx_tdata总线上。 当第一个n个字节被放置在总线上时,m_axi_rx_tvalid被断言,以指示数据为用户应用程序准备就绪。 内核在第一个数据节拍后的时钟周期内取消忽略m_axi_rx_tvalid,以指示数据流中的暂停。
在暂停之后,内核断言m_axi_rx_tvalid并继续组合m_axi_rx_tdata总线上的剩余数据。 在帧结束时,内核断言m_axi_rx_tlast。 核心还计算m_axi_rx_tkeep总线的值,并根据帧的最终字中的有效字节总数将其呈现给用户应用程序。

图2-2-3-5 Data Reception with Pause
影响Aurora 8B / 10B内核框架效率的因素有两个:
•框架尺寸
•数据通路的宽度
每个通道每隔10,000个字节使用12个字节的CC序列消耗总通道带宽的大约0.12%。Aurora 8B / 10B内核中的所有字节均以双字节代码组发送。 具有偶数字节的极光8B / 10B帧具有四个字节的开销,两个字节用于SCP(起始帧),两个字节用于ECP(帧结束)。具有奇数个字节的数据的8B / 10B帧有五个 字节的开销,四字节的成帧开销加上一个附加字节的pad字节。
IP CORE仅在通道的特定通道中传输帧分隔符。 SCP仅在最左侧(MSB)的车道中传输,ECP仅在最右边(LSB)的车道中传输。 最后一个代码组与数据之间的通道中的任何空格与ECP代码组填充空闲。 结果是降低了设计的资源成本,牺牲了最小的附加吞吐量成本。 尽管SCP和ECP可以针对额外的吞吐量进行优化,但是在大多数情况下,由用户用户强加的每个周期限制的单个帧将使得此改进无法使用。
下表它显示了8字节,4通道通道的效率,并说明了效率随着通道帧长度的增加而增加。
表2-2-3-1:Efficiency Example

表2-2-3-1显示了在四个通道中传输256字节的帧数据时,8字节的4通道通道的开销。 由于起始和结束字符,结果数据单元长度为264字节,并且由于填充通道所需的空闲。 这相当于发射机的3.03%的开销。 另外,每隔10,000个字节,每个通道上会发生一个12字节的时钟补偿序列,这样就增加了一大部分的开销。 接收器可以处理稍微更有效的数据流,因为它不需要任何空闲模式。
表2-2-3-2:Typical Overhead for Transmitting 256 Data Bytes

表2-2-3-3:s_axi_tx_tkeep的值和开销的相应字节

当在Vivado集成设计环境(IDE)中选择Little Endian选项时,s_axi_tx_tkeep位排序从MSB更改为LSB。
2.2.4数据流接口(Streaming Interface)
前面介绍的是Frame形式的传输,这里讲解Streaming 接口。

图2-2-4-1 Aurora 8B/10B Core Streaming User Interface
Transmitting and Receiving Data(发送和接收数据)
流式接口允许将Aurora 8B/10B通道用作管道。 初始化后,通道始终可用于写入,除非发送时钟补偿序列。 核心数据传输符合AXI4-Stream协议。
当s_axi_tx_tvalid被取消置位时,在字之间创建间隙,并且保留间隙,除非发送时钟补偿序列。
当数据到达Aurora 8B/10B通道的RX侧时,它显示在m_axi_rx_tdata总线上,并且m_axi_rx_tvalid被断言。 数据必须立即读取或丢失。 如果这是不可接受的,缓冲区必须连接到RX接口来保存数据直到可以使用。
Example A: TX Streaming Data Transfer(TX流数据传输)
图2-14显示了流数据的典型示例。 Aurora 8B / 10B内核表示可以通过断言s_axi_tx_tready传输数据。 一个周期之后,用户逻辑表示准备通过断言s_axi_tx_tdata总线和s_axi_tx_tvalid信号来传输数据。 因为两个就绪信号现在被断言,数据D0从用户逻辑传输到Aurora 8B / 10B内核。 数据D1在以下时钟周期进行传输。 在本例中,Aurora 8B / 10B内核取消了其准备就绪信号s_axi_tx_tready,并且在s_axi_tx_tready信号被断言的情况下,直到下一个时钟周期才会传输数据。 然后,用户逻辑在下一个时钟周期取消s_axi_tx_tvalid,并且在两个就绪信号被置位之前不传输任何数据。

图2-2-4-2 Typical Streaming Data Transfer
Example B: RX Streaming Data Transfer(RX流数据传输)
图2-2-4-3显示了数据传输的接收端。

图2-2-4-3 Typical Data Reception
2.2.5流量控制(Flow Control)
本节介绍如何使用Aurora 8B/10B流量控制。 使用框架接口的内核上提供了两个可选的流控制接口。 本地流控制(NFC)调节全双工信道接收端的数据传输速率。 用户流控制(UFC)容纳用于控制操作的高优先级消息。
User Flow Control Interface(用户流控制接口)
UFC接口是在启用UFC生成IPCORE时创建的(如图2-2-5-1 ).UFC s_axi_ufc_tx_tvalid和TX侧的s_axi_ufc_tx_tready端口启动UFC消息,3位s_axi_ufc_tx_tdata端口指定消息的长度。 使用s_axi_ufc_tx_tready断言,UFC消息可以提供给数据端口。

图2-2-5-1 Aurora 8B/10B Core UFC Interface
UFC接口的RX侧由一组AXI4-Stream端口组成,允许UFC消息被读取为一个帧。 Simplex模块仅保留在支持的方向发送数据所需的接口。
表2-2-5-1 UFC I/O Ports


Transmitting UFC Messages发送UFC消息
UFC消息可以携带从2到16的偶数数据字节。用户应用程序通过在s_axi_ufc_tx_tdata端口上驱动SIZE代码来指定消息的长度。 UFC消息的合法SIZE代码值如表2-2-5-2所示。
表2-2-5-2

要发送UFC消息,用户应用程序在使用所需的SIZE代码驱动s_axi_ufc_tx_tdata端口时会断言s_axi_ufc_tx_tvalid。必须保持s_axi_ufc_tx_tvalid信号,直到Aurora 8B / 10B IPCORE断言s_axi_ufc_tx_tready信号。UFC消息的数据必须放在s_axi_tx_tdata端口上,从s_axi_ufc_tx_tready被断言后的第一个周期开始。当s_axi_tx_tdata端口用于UFC数据时,核心模块将取消s_axi_tx_tready s_axi_tx_tready。
注意:只有在完成当前UFC请求后才应给予UFC请求; 背靠背UFC请求可能不会被IP所支持。
Number of Data Beats Required to Transmit UFC Messages(发送UFC消息所需的节拍数)

图2-2-5-2 Data Switching Circuit
表2-2-5-3显示了根据AXI4-Stream数据接口的宽度传输不同大小的UFC消息所需的周数。在所有消息数据可用之前,不应启动UFC消息。 与常规数据不同,在s_axi_ufc_tx_tready已被确认直到当前UFC消息完成之前,UFC消息不能被中断。
表2-2-5-3 Number of Data Beats Required to Transmit UFC Messages


Example A: Transmitting a Single-Cycle UFC Message(发送单周期UFC消息)
发送单周期UFC消息的过程如图2-2-5-3所示。 在这种情况下,4字节的消息正在4字节的接口上发送。
注意:s_axi_ufc_tx_tready信号被断言两个周期。 Aurora 8B / 10B内核使用
这个差距在数据流中传输UFC头和消息数据。

图2-2-5-3 Transmitting a Single-Cycle UFC Message
Example B: Transmitting a Multicycle UFC Message(发送多周期UFC消息)
发送双周期UFC消息的过程如图2-2-5-4所示。 在这种情况下,用户应用程序使用2字节接口发送一个4字节的消息。 s_axi_tx_tready被断言三个周期:在s_axi_ufc_tx_tready周期期间发送的UFC头的一个周期,以及UFC数据的两个周期。

图2-2-5-4 Transmitting a Multicycle UFC Message
Receiving User Flow Control Messages(接收用户流控制消息)
当Aurora 8B/10B内核接收到UFC消息时,它将通过专用UFC AXI4-Stream接口将数据传递给用户应用程序。数据显示在m_axi_ufc_rx_tdata端口上; m_axi_ufc_rx_tvalid表示消息数据的开始,m_axi_ufc_rx_tlast表示结束。m_axi_ufc_rx_tkeep用于在消息的最后一个周期中显示m_axi_ufc_rx_tdata上的有效字节数。
Example A: Receiving a Single-Cycle UFC Message(接收单周期UFC消息)
图2-2-5-5显示了一个4位数据接口接收4字节UFC消息的Aurora 8B/10B内核。核心通过断言m_axi_ufc_rx_tvalid和m_axi_ufc_rx_tlast来指示单个周期框架将该数据提供给用户应用程序。 m_axi_ufc_rx_tkeep设置为4'hF,仅指示接口的四个最高有效字节有效。

图2-2-5-5 Receiving a Single-Cycle UFC Message
Example B: Receiving a Multicycle UFC Message(接收多个UFC消息)
上图显示了一个4字节接口接收8字节消息的Aurora 8B/10B内核模块。
注意:结果帧是两个周期长,第二个周期的m_axi_ufc_rx_tkeep设置为4'hF,表示数据的所有四个字节都有效。
2.2.6本地流量控制(Native Flow Control)
Aurora 8B/10B协议包括本地流控制(NFC)接口(图2-2-6-1),其允许接收机通过指定必须放入数据流的空闲数据跳数来控制接收数据的速率。 甚至可以通过请求发送器临时发送空闲(XOFF)来完全关闭数据流.NFC通常用于防止FIFO溢出条件。有关NFC操作和代码的详细说明,请参阅Aurora 8B/10B协议规范(SP002)。

图2-2-6-1 Aurora 8B/10B Core NFC Interface
当NFC选项启用时生成IPCORE时,就会创建NFC接口。该接口包括用于发送NFC消息的请求(s_axi_nfc_tx_tvalid)和确认(s_axi_nfc_tx_tready)端口以及4位s_axi_nfc_tx_tdata端口,以指定所请求的空闲周期数。 表2-2-6-1列出了NFC接口的端口,仅在全双工Aurora 8B/10B内核中可用。
表2-2-6-1:NFC I/O Ports

表2-2-6-2显示了本机流量控制(NFC)的代码。 这些值以大端格式的位[0:3]和小端格式的[3:0]驱动。
表2-2-6-2:NFC Codes
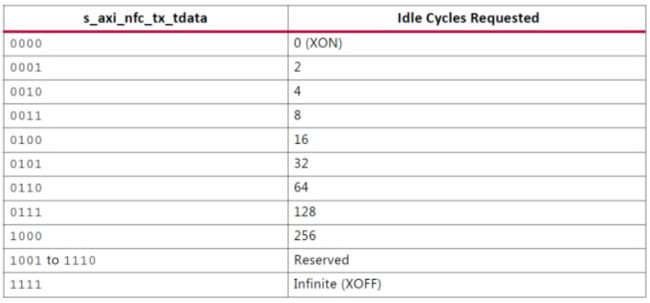
用户应用程序断言s_axi_nfc_tx_tvalid并将NFC代码写入s_axi_nfc_tx_tdata。 NFC代码指示频道合作伙伴应在其TX数据流中插入的最小空闲周期数。 用户应用程序必须保存s_axi_nfc_tx_tvalid和s_axi_nfc_tx_tdata,直到s_axi_nfc_tx_tready被断言。 Aurora 8B / 10B内核在发送NFC消息时无法传输数据。 在s_axi_nfc_tx_tready断言之后的周期上,s_axi_tx_tready总是被取消置位。
示例A:发送NFC消息
图2-2-6-2示出了当用户应用向通道伙伴发送NFC消息时的发送定时的示例。 s_axi_nfc_tx_tready信号被断言一个周期(假设n至少为2),以在NFC消息的数据流中创建间隙。

图2-2-6-2 Transmitting an NFC Message
Example B: Receiving a Message with NFC Idles Inserted(接收带有NFC空闲的消息插入)
图2-2-6-3显示了当接收到NFC消息时,TX用户界面上的信号示例。 在这种情况下,NFC消息具有0001的代码,请求两个空闲数据跳动。 内核在用户界面上取消s_axi_tx_tready,直到发送足够的空闲来满足请求。 在这个例子中,核心正在立即进入NFC模式,NFC空闲时间立即被插入。 Aurora 8B / 10B内核也可以在完成模式下工作,其中NFC空闲仅插入帧之间。 如果完成模式核心在发送帧时收到NFC消息,则在取消s_axi_tx_tready以插入空闲之前完成发送帧。

2-2-6-3 Receiving a Message with NFC Idles Inserted
2.2.7状态,控制和收发器接口
(Status, Control, and the Transceiver Interface)
Aurora 8B/10B IPCORE的状态和控制端口允许应用程序监视通道并使用收发器的内置功能。 本节提供状态和控制界面,收发器串行I / O接口以及专用于单工模块的边带初始化端口的图表和端口说明。
状态和控制端口
Aurora 8B/10B内核的状态和控制端口的功能如表表2-2-7-1所示。 收发器端口如表表2-2-7-3所示。
表2-2-7-1 Status and Control Ports

表2-2-7-1 接续
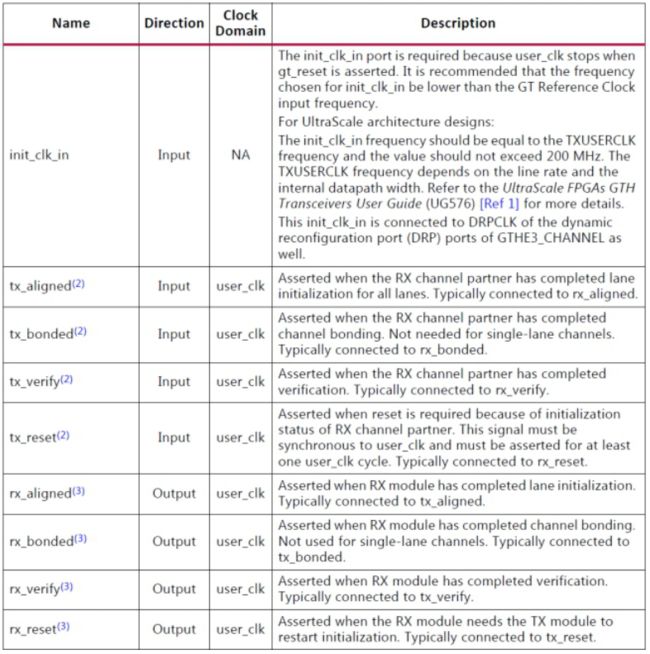
注:
1.m是收发器的数量。 有关详细信息,请参阅错误状态信号。
- 仅在TX只有单工数据流模式和边带作为后通道核心配置。
- 仅适用于仅限于RX的单工数据流模式和边带作为后通道核心配置。
Full-Duplex Cores全双工IP CORE
Full-Duplex Status and Control Ports(全双工状态和控制端口)
全双工内核提供TX和RX Aurora 8B/10B通道连接。 全双工Aurora 8B/10B内核的状态和控制界面如图2-2-7-1所示。

图2-2-7-1 Status and Control Interface for Full-Duplex Cores
错误状态信号
在Aurora 8B/10B通道操作中,设备问题和通道噪声可能会导致错误。8B/10B编码允许Aurora 8B/10B内核检测通道中出现的所有单位错误和大多数位错误,并在每个周期内断言soft_err。TX单工内核不包括一个soft_err端口。除非发生设备问题,否则所有传输数据都被认为是正确的。
IPCORE还监控每个收发器的硬件错误,如缓冲区溢出/下溢和锁定失败,并断言hard_err信号。使用rx_hard_err信号报告单工内核的RX侧硬错误。灾难性的硬件错误也可以表现为一连串的软错误。核心使用Aurora 8B/10B协议规范(SP002)中描述的泄漏桶算法来检测在短时间内发生的大量软错误,并断言hard_err或rx_hard_err信号。
每当检测到硬错误时,内核自动重置自身,并尝试重新初始化。一旦导致硬错误的硬件问题得到解决,这就允许频道重新初始化并重新建立。软错误不会导致复位,除非它们在短时间内发生。
具有AXI4-Stream数据接口的Aurora 8B/10B IPCORE还可以检测Aurora 8B/10B帧中的错误并声明frame_err信号。帧错误可以是没有数据,连续起始帧符号和连续帧结束符号的帧。此信号不适用于单工TX内核。如果可用,该信号通常被认定为接近于soft_err断言,其中软错误是帧错误的主要原因。
表2-2-7-2总结了Aurora 8B / 10B内核可以检测的错误情况以及用于提醒用户应用的错误信号。
表2-2-7-2Error Signals in Cores

Full-Duplex Initialization(全双工初始化)
全双工IPCORE在上电,复位或硬错误后自动初始化,并执行Aurora 8B / 10B初始化过程,直到通道准备就绪。 lane_up总线指示通道中哪条通道已经完成了通道初始化过程。 该信号可用于帮助在多通道通道中调试设备问题。 只有在核心完成整个初始化过程之后,才会声明channel_up。
Aurora 8B/10B IPCORE无法接收channel_up之前的数据。 应使用用户界面上的m_axi_rx_tvalid信号来限定传入数据。 channel_up可以被反转并用于重置驱动全双工通道TX侧的模块,因为在通道_up之前不会发生任何传输。 如果在数据接收之前需要复位用户应用模块,则可以将lane_up信号之一反转并使用。 在所有的lane_up信号被置位之后才能接收数据。
注:channel_init_sm模块中可以使用WATCHDOG_TIMEOUT参数来控制通道初始化过程中出现的看门狗定时器。
Simplex Cores(单工IPCORE)
单工TX状态和控制端口
单工TX允许用户应用程序将数据传输到单工RX。他们没有RX连接。单片TX IPCORE的状态和控制界面如图2-2-7-2所示。

图2-2-7-2 Status and Control Interface for Simplex TX Core
单工接收状态和控制端口
单工RX IPCORE允许用户应用从单工TXIPCORE接收数据。 单片RXIPCORE的状态和控制界面如图图2-2-7-3 所示。
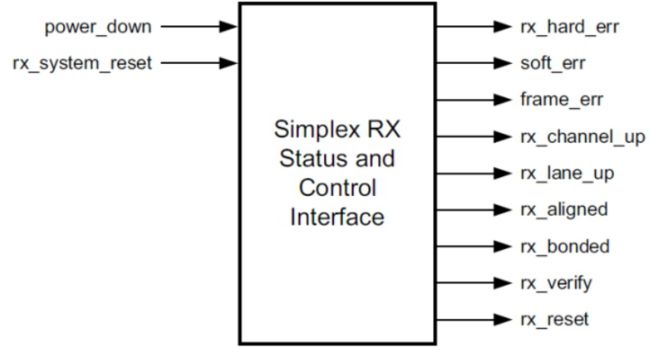
图2-2-7-3 Status and Control Interface for Simplex RX Core
单工IPCORE的初始化
单工IPCORE不依赖于Aurora 8B/10B通道的信号进行初始化。
相反,单工通道的TX和RX侧通过一组边带初始化信号传送其初始化状态:对齐,绑定,验证和复位; 一个为TX侧设置TX_前缀,一个为RX侧设置一个RX_前缀。 绑定端口仅用于多通道内核。有两种方式可以使用边带初始化信号初始化单工模块:
•将RX边带初始化端口的信息发送到TX边带初始化端口
•使用定时初始化间隔,独立于RX边带初始化端口驱动TX边带初始化端口
以下部分将介绍两种初始化方法。
使用返回通道
在RX和TX之间没有通道的情况下,返回通道是初始化和维护单工通道的最安全的方式。 返回通道只需向TX侧传送消息,以指示在信号变化时哪些边带初始化信号被断言。
包含在简单的Aurora 8B/10B内核的example_design目录中的示例设计显示了一个简单的侧面通道,在设备上使用三个或四个I / O引脚。
使定时器
如果不能使用后置通道,可以使用一组定时器驱动TX单工初始化来初始化串行通道。 定时器必须仔细设计,以满足系统的需要,因为初始化的平均时间取决于许多通道特定条件,例如时钟速率,通道延迟,通道之间的偏移和噪声。C_ALIGNED_TIMER,C_BONDED_TIMER和C_VERIFY_TIMER分别用于断言tx_aligned,tx_bonded和tx_verify信号的定时器。 这些定时器使用从角箱功能模拟获得的最坏情况值,并在
注意:这些信号不会在通道的实际状态上更新,但在定时器到期后。
Aurora 8B/10B模块中的一些初始化逻辑使用看门狗定时器来防止死锁。这些看门狗定时器用于通道的RX侧,并可能干扰TX初始化定时器的正确操作。如果RX单工模块从对齐,绑定或验证复位,请确保不是因为TX逻辑在其中一个状态下花费太多时间。如果需要特别长的定时器来满足系统的需要,则可以通过编辑模块来调整看门狗定时器。在大多数情况下,这是不必要的,不推荐。
Aurora 8B/10B通道通常只有在故障的情况下才能重新初始化。当没有反向通道可用时,对于大多数错误,事件触发的重新初始化是不可能的,因为通常,RX侧在TX侧必须处理该条件时检测到故障。解决方案是定时驱动的TX单工模块定期重新初始化。如果发生灾难性错误,则在下一个重新初始化时间到达后,通道将重新设置并再次运行。系统设计人员应平衡重新初始化所需的平均时间与其系统可以容忍不工作通道的最大时间,以确定其系统的最佳重新初始化时间。
注意:在tx_channel_init_sm / rx_channel_init_sm模块中可以使用WATCHDOG_TIMEOUT参数来控制通道初始化过程中出现的看门狗定时器。
收发器接口(Transceiver Interface)
该接口包括收发器的串行I / O端口,以及控制和状态。
表2-2-7-2 Transceiver Ports


表2-2-7-2 继续


表2-2-7-2 继续


表2-2-7-2 继续


表2-2-7-2 继续

注意:
1.m是收发器的数量。
2.如果在Vivado IDE中选择了附加收发器控制和状态端口复选框选项,则可以启用收发器调试端口。
3.
4.对于使用UltraScale设备的设计,单通道内核的可选收发器调试端口的前缀从gt
有关收发器调试端口的更多信息,请参阅相关收发器用户指南。
6.具有双工和仅限TX的单工配置。
7.具有双工和仅限RX的单工配置,仅适用于7系列FPGA GTX收发器。
8.仅适用于双工和仅限RX的单工配置,仅适用于7系列FPGA GTX和GTH收发器。
9.具有双工和仅限RX的单工配置。
10.不支持UltraScale设备。
11. 7系列设备中不可用。
12.有关DRP端口的更多信息,请参阅相关的UG收发器指南。
时钟接口
时钟接口具有用于收发器参考时钟的端口,以及Aurora 8B/10B核心与应用逻辑共享的并行时钟。
Aurora 8B/10B IPCORE时钟端口如表2-2-7-3所示。
Aurora 8B/10B IPCORE的时钟端口
表2-2-7-3 Clock Ports for Aurora 8B/10B Core

表2-2-7-4提供了由于选择共享逻辑选项而导致的端口更改的详细信息。
表2-2-7-4 Port Changes Due to Shared Logic Option

表2-2-7-4 续


表2-2-7-4 续

注意:
1.来自GTXE2_COMMON的端口仅适用于Artix-7 FPGA GTX收发器设计。
2. GTXE2_COMMON / GTHE2_COMMON端口仅适用于7系列FPGA GTX / GTH收发器
设计。
3.对于每个选定的四通道,这些端口被启用。 指的是从1到12编号的收发器。
2.2.8 CRC
CRC模块提供16位或32位CRC,用于用户数据。CRC模块端口如表2-2-8-1所示。
表2-2-8-1 CRC Module Ports

2.3基于Aurora 8B/10B IPCORE的设计
本章包括指南和附加信息,使设计与核心更容易。
通用设计指南
本节介绍使用用户应用程序逻辑将Aurora 8B / 10B IPCORE转换为完全正常运行的设计所需的步骤。 并不是所有的实现都需要这里列出的所有设计步骤。 请仔细阅读本手册中的逻辑设计指南。
使用示例设计作为起点
所创建的Aurora 8B/10B内核的每个实例都具有可在FPGA中进行仿真和实现的示例设计。该设计可以作为您自己设计的起点,如有必要,可以用于对用户应用程序进行故障排除。
1)知道难度
Aurora 8B/10B核心设计在任何技术和程度上都具有挑战性
困难进一步受到以下因素的影响
•最大系统时钟频率
•目标设备架构
•用户应用程序的性质
所有Aurora 8B / 10B核心实现都需要注意系统性能要求。 流水线,逻辑映射,布局约束和逻辑重复都是有助于提高系统性能的方法。
2)信号寄存
为了简化FPGA设计中的时序并提高系统性能,可以将用户应用程序和IPCORE之间的所有输入和输出注册到各自的时钟域中。 注册信号可能对所有路径都是不可能的,但这样做可以简化时序分析,并使Xilinx工具更容易放置和路由设计。
3)识别时序关键信号
IPCORE示例设计提供的XDC文件标识了应该应用的关键信号和时序约束。 仅允许修改Aurora 8B / 10B IPCORE不会被用户修改。 任何修改可能会对系统时序和协议遵从性产生不利影响。 Aurora 8B / 10BIPCORE的支持用户配置只能通过从Vivado®集成设计环境(IDE)中选择选项来进行。
4)串行收发器参考时钟接口
内核需要高质量,低抖动的参考时钟来驱动收发器中的高速TX时钟和时钟恢复电路。 它还需要至少一个频率锁存并行时钟,用于与用户应用程序的同步操作。 Aurora 8B / 10B内核配置了UltraScale™和UltraScale +™系列中的通道锁相环(CPLL),Virtex®-7,Kintex®-7和Zynq®-7000系列设计。
2.3.1 Aurora 8B/10B内核的时钟接口端口
有关时钟接口上收发器端口的说明,请参见表2-2-7-3 。
从相邻收发器四边形的时钟
Xilinx实现工具可以根据需要对南北路由和引脚交换到收发器时钟输入进行必要的调整,以将时钟从一个四线到另一个。
重要信息:共享参考时钟时必须遵守以下规则,以确保满足高速设计的抖动余量:
•7系列FPGA中由外部时钟引脚对(mgtrefclkn / mgtrefclkp)采集的GTX或GTH收发器四分之一的总数不能超过三个四分之一(一个四分之一和一个四分之一)或12个GTXE2_CHANNEL / GTHE2_CHANNEL收发器。 7系列FPGA中超过12个收发器或超过3个四极的设计应使用多个外部时钟引脚。
•UltraScale架构FPGA中由外部时钟引脚对(mgtrefclkn / mgtrefclkp)采集的收发器四分之一的总数不得超过五个四分位数(下面两个四分之一和两个四分之一)或20个GTHE3_CHANNEL收发器。
重要信息:不推荐手动编辑,但可以使用UltraScale FPGA GTH收发器用户指南(UG576)[参考文献1]和7系列FPGA GTX / GTH收发器用户指南(UG476)[参考文献3]中的建议。
2.3.2复位和掉电
重启
复位信号用于将Aurora 8B / 10B IPCORE设置为已知的启动状态。 在复位时,内核停止任何当前操作并重新初始化新通道。
在全双工模块上,复位信号复位通道的TX和RX侧。在单工模块中,tx_system_reset复位TX通道,rx_system_reset复位RX通道。 gt_reset信号复位最终复位内核的收发器。
注意:tx_system_reset与单工边带接口上使用的tx_reset和rx_reset信号分开。
用例1:双工核心中的复位断言双工核心中的复位置位应至少为6个user_clk时间段。 结果,如图3-1所示,channel_up在三个user_clk周期后被置为无效。

用例2:在双工核心中的gt_reset断言
图2-3-2-2显示了双工IPCORE中的gt_reset断言,并且应至少为六个init_clk_in时间段。 因此,在几个时钟周期之后,user_clk停止,因为收发器中没有txoutclk,并且随后将channel_up置为无效。

图2-3-2-2 gt_reset assertion in a duplex core
图2-3-2-3显示了在系统中连接的simplex-TX内核和simplex-RX内核。TX_IP和RX_IP可以在相同或多个设备中。

图2-3-2-3 System with Simplex Cores
图2-3-2-4显示了simplex内核中tx_system_reset和rx_system_reset断言的推荐过程。
1. tx_system_reset和rx_system_reset被断言至少六个时钟user_clk时间段。
2.在三个user_clk周期后,tx_channel_up和rx_channel_up被置为无效。
3.在tx_system_reset被取消置位之后,rx_system_reset被取消置位(或)释放。
3.在tx_system_reset被取消置位之后,rx_system_reset被取消置位(或)释放。 这确保了simplex-TX内核中的收发器能够更早地开始传输初始化数据,并增强了单工RX核心对准正确数据序列的可能性。
4.在tx_channel_up断言之前,rx_channel_up被断言。必须通过simplex-TX核心和Simplex-TX内核中的单工定时器参数(C_ALIGNED_TIMER,C_BONDED_TIMER和C_VERIFY_TIMER)来满足此条件,以满足此条件。
- 当单片机TX核心在配置的时间内完成Aurora 8B / 10B协议信道初始化序列传输时,tx_channel_up被置位。断言tx_channel_up最后确保simplex-TX内核在Simplex-RX核心准备就绪时发送Aurora初始化序列。

图2-3-2-4 tx_system_reset and rx_system_reset Assertion in the Simplex Core
Aurora 8B / 10B双工上电顺序
在板上电顺序期间,gt_reset和复位信号都必须为高电平。
收发器参考时钟(GT_REFCLK)和无核心运行时钟(INIT_CLK)预计在上电时稳定,以使Aurora 8B / 10B IPCORE正常工作。

图2-3-2-5 Aurora 8B/10B Duplex Power On Sequence
Aurora 8B/10B双工正常工作复位顺序
在正常操作期间,在确定gt_reset信号之前,期望复位信号至少被确定128个user_clk时间周期,以确保在由于用户_clk信号被抑制之前可编程逻辑中的核心部分已经达到已知的复位状态 断言gt_reset(图2-3-2-6)。

图2-3-2-6 Aurora 8B/10B Duplex Normal Operation Reset Sequence
Aurora 8B/10B单工开机序列
在上电期间,TX单工和RX单工内核的gt_reset和复位信号预计为高电平。 预计INIT_CLK和GT_REFCLK在上电期间是稳定的。 TX板上的gt_reset信号必须先被取消置位,然后在RX侧消除gt_reset; 这样可确保RX端的CDR锁定正确(图2-3-2-7)。

图2-3-2-7 Aurora 8B/10B Simplex Power On Reset Sequence
单工上电顺序:
1.Deassert TX-side gt_reset(A)
2.取消旁路RX侧gt_reset(C)
3.与user_clk(D)同步脱扣RX侧复位
4.与user_clk(B)同步脱扣TX侧复位
注意:必须注意确保(D)至(B)时差尽可能小。
Aurora 8B/10B 单工正常工作复位顺序
对于单工配置,建议TX侧复位序列与RX侧复位序列紧密耦合,因为TX和RX链路没有通信反馈路径。请注意,如果RX侧被复位,则没有直接机制来通知TX侧的复位。因此,对于Aurora 8B / 10B单工内核,需要在系统级别处理复位耦合。每个TX侧的复位必须在RX侧后面,如图3-8所示,RX端复位失效和TX侧复位失效之间的时间必须保持尽可能的最小。在确认gt_reset之前,需要至少128个时钟周期,以确保在通过断言gt_reset来抑制user_clk之前,可编程逻辑中的核心部分达到已知的复位状态。 gt_reset的断言时间必须至少为6个init_clk时间段,以满足核心中包含的去跳频电路。

图2-3-2-8 Aurora 8B/10B Simplex Normal Operation Reset Sequence
掉电
这是一个高电平有效信号。当断电功能断开时,Aurora 8B/10B内核中的收发器关闭,将其置于非工作,低功耗模式。当断电功能无效时,内核自动复位。在停电解除断电之后,gt_reset必须被断言,如“收发器用户指南”的指南所示。
警告! 在使用tx_out_clk的内核上断开掉电信号时请小心(参见串行收发器参考时钟接口,第51页)。当GTX,GTX和GTH收发器掉电时,tx_out_clk停止。参考7系列FPGA GTX / GTH收发器用户指南(UG476)[参考文献3],7系列FPGA GTX收发器用户指南(ug482)和UltraScale架构GTH收发器用户指南(UG576)。
2.3.3共享逻辑(Share Logic)
Vivado IDE中的共享逻辑选项配置核心,包括可收集的资源,如收发器四路PLL(QPLL),收发器差分缓冲区(IBUFDS_GTE2)以及核心或示例设计中的时钟和复位逻辑。 当选择了核心选项中的包含共享逻辑时,所有可共享的资源可用于核心的多个实例,从而最小化所需的HDL修改量,同时保留灵活性来解决更多的用例。 共享逻辑层次结构称为
注意:当共享逻辑处于内核时,单端选项将从内核中排除相应的差分时钟缓冲区。
注意:图2-3-3-1和图2-3-3-2中的灰色块指的是IP内核。
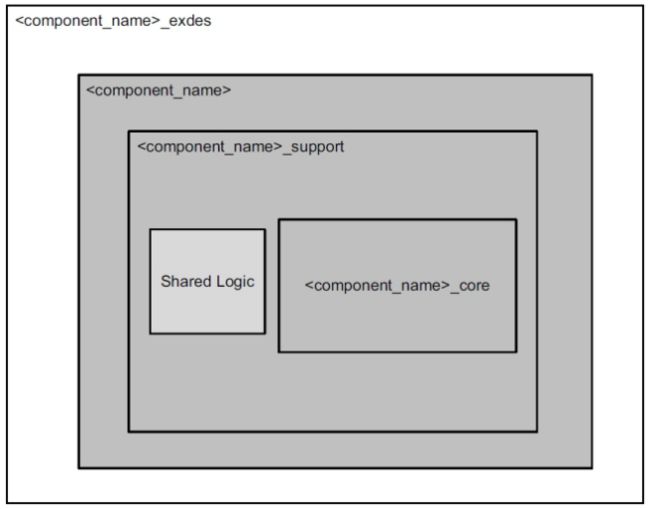

图2-3-3-2 Shared Logic Included in Example Design
共享逻辑的内容取决于物理接口和目标设备。共享逻辑包含收发器差分缓冲器(IBUFDS_GTE2/IBUFDS_GTE3)的实例,支持复位逻辑,以及实例化
注意:Aurora 8B / 10B内核使用CPLL,不使用QPLL(也就是说,
GTXE2_COMMON/ GTHE2_COMMON)。为Zynq-7000和7系列器件提供QPLL,并与共享逻辑实例化,以实现与其他赛灵思串行连接内核的一致性。
表2-3-3-1 Sharable Resources
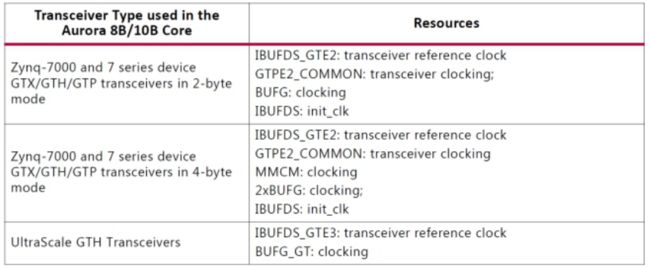
gt_refclk1_out和gt_refclk2_out信号可以由其他收发器共享
在设计中,应遵循收发器时钟指南,以实现连接和收发器四方接近。
图2-3-3-3显示了具有共享逻辑(aurora_8b10b_0)的内核与没有共享逻辑(aurora_8b10b_1)的另一核心实例的可共享资源连接。 某些端口可能会根据核心配置和所选收发器的类型而改变。 表2-2-7-4 ,提供了由于选择共享逻辑选项而导致的端口更改的详细信息。

图2-3-3-3可用资源连接示例使用IP集成器
使用加扰/解扰器
对于具有多项式G(x)= X16 + X5 + X4 + X3 + 1的数据实现的16位加法扰码器/解扰器可在
它确保长时间不发生重复数据。 基于时钟补偿字符的发送和接收,分别对加扰器和解扰器进行同步。
注意:扰码器仅影响数据符号。
使用CRC
在
热插拔逻辑
Aurora 8B/10B中的热插拔逻辑(使用自由运行的init_clk信号)基于接收到的时钟补偿字符。 通过Aurora RX接口接收时钟补偿字符意味着通信通道是活的,不会破坏。 如果在预定时间内未接收到时钟补偿字符,则热插拔逻辑复位核心和收发器。 时钟补偿模块必须用于Aurora 8B/10B设计。
重要信息:为了确保可预测的链接操作,强烈建议热插拔逻辑不被禁用。
时钟补偿
时钟补偿功能允许在Aurora 8B/10B通道的每一侧使用的参考时钟频率高达±100 ppm的差异。标准时钟补偿模块

防止16字节UFC消息与时钟补偿序列冲突所需的先行循环次数取决于通道中的通道数和每个通道的宽度。
本地流控制消息请求在时钟补偿字符传输期间不被确认。 这有助于防止NFC消息和时钟补偿序列的冲突。
重要信息:参数CC_FREQ_FACTOR决定CC序列的频率。 任何增加或减少参数的尝试都应该仔细分析和测试。
•确保选择的持续时间和周期足以纠正所使用时钟频率之间的最大差异。
•不要在八个周期内执行多个时钟校正序列。
•用CC序列代替长时间的空闲序列(小于12个周期)可以降低EMI。
使用小端支持
Aurora 8B/10B内核默认支持大端格式的用户界面。它还支持小端点格式,无缝连接到兼容AXI4-Stream的IP内核。
2.4 Setp By Step搭建FPGA工程
Step1:任意创建一个新的空的工程(创建工程的具体工程如果还不清楚的看我们教程第一季部分),并且进入IP CORE列表 右击CustoMZe ip

Step2:配置IP CORE-Core options

Step3:配置IP CORE-GT Selections

Step4:配置IP CORE-Shared Logic 为include Shared locgic in CORE之后单击OK

Step5:在接下来的对话框中,选择Out of context per IP(后面可以提高编译速度)单击OK

Step6:右击刚刚产生的IPCORE 选择 Open IP EXample Design 这样会根据IP CORE的配置产生自动产生一个demo程序,大大方便我们掌握和学习。
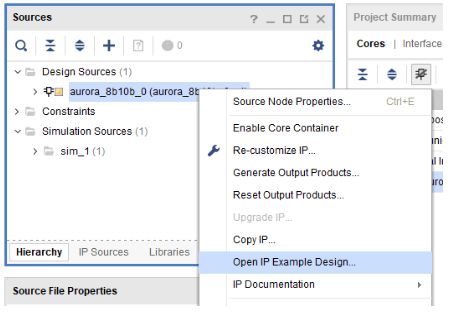
Step7:本步骤会提示选择路径,读者可以自己定义自己的路径

Step8:一切生成完成后的文件

2.5 代码分析
2.5.1 代码功能概述
- Aurora_8b10b_exdes.v 此代码是顶层文件调用了各个子模块。
- Aurora_8b10b.xci此代码就是我们刚才创建的IPCORE.
- Aurora_8b10b_ll_to_axi_exdes.v实现了旧代码(虽然现在AXI总线大行其道,但是我们会发现很多DEMO中是旧代码转AXI协议,估计XILINX公司为了省事,毕竟写好的模块没必要重新写一次)到AXI4总线接口的转换。
- Aurora_8b10b_frame_gen.v产生测试数据并且通过TX接口发送出去
- Aurora_8b10b_axi_to_ll_exdes.v把AXI接口转换成旧接口
- Aurora_8b10b_frame_check.v是接收端口,接收到数据并且进行检测
- vio_7seriers.xci 是虚拟IO 一种调试用的IP可以实时修改一些变量的参数
- Ila_7series.xci 是debug IP 功能就是内嵌的逻辑分析仪
9) aurora_8b10b_cdc_sync_exdes.v 文件是VIO 虚拟IO和via debug 内嵌逻辑分析仪的同步程序
下面仅就关键的代码做分析
2.5.2 Aurora_8b10b_frame_gen.v
FRAME_GEN模块为遵循AXI4-Stream协议的PDU,UFC和NFC接口中的每一个生成用户流量。 该模块包含使用具有特定初始值的线性反馈移位寄存器(LFSR)的伪随机数生成器来生成可预测的数据序列。 FRAME_CHECK模块使用此数据序列来验证Aurora数据通道的完整性。 模块输入为user_clk,reset和channel_up。
这里的设计从IPCORE设置向导可以看到我们没有配置UFC或者NFC流控制接口。
| module aurora_8b10b_FRAME_GEN ( // User Interface TX_D, TX_REM, TX_SOF_N, TX_EOF_N, TX_SRC_RDY_N, TX_DST_RDY_N,
// System Interface USER_CLK, RESET, CHANNEL_UP ); //*****************************Parameter Declarations****************************
//***********************************Port Declarations*******************************
// User Interface output [0:15] TX_D; output TX_REM; output TX_SOF_N; output TX_EOF_N; output TX_SRC_RDY_N; input TX_DST_RDY_N;
// System Interface input USER_CLK; input RESET; input CHANNEL_UP;
//***************************External Register Declarations***************************
reg TX_SRC_RDY_N; reg TX_SOF_N; reg TX_EOF_N;
//***************************Internal Register Declarations***************************
reg [0:15] data_lfsr_r; reg [0:7] frame_size_r; reg [0:7] bytes_sent_r; reg [0:3] ifg_size_r;
//State registers for one-hot state machine reg idle_r; reg single_cycle_frame_r; reg sof_r; reg data_cycle_r; reg eof_r;
wire reset_c; //*********************************Wire Declarations**********************************
wire ifg_done_c;
//Next state signals for one-hot state machine wire next_idle_c; wire next_single_cycle_frame_c; wire next_sof_c; wire next_data_cycle_c; wire next_eof_c;
wire dly_data_xfer; reg [4:0] channel_up_cnt;
//*********************************Main Body of Code**********************************
always @ (posedge USER_CLK) begin if(RESET) channel_up_cnt <= `DLY 5'd0; else if(CHANNEL_UP) if(&channel_up_cnt) channel_up_cnt <= `DLY channel_up_cnt; else channel_up_cnt <= `DLY channel_up_cnt + 1'b1; else channel_up_cnt <= `DLY 5'd0; end
assign dly_data_xfer = (&channel_up_cnt);
//Generate RESET signal when Aurora channel is not ready assign reset_c = RESET || !dly_data_xfer;
//______________________________ Transmit Data __________________________________ //Generate random data using XNOR feedback LFSR //随机数发生器 always @(posedge USER_CLK) if(reset_c) begin data_lfsr_r <= `DLY 16'hABCD; //random seed value end else if(!TX_DST_RDY_N && !idle_r) begin data_lfsr_r <= `DLY {!{data_lfsr_r[3]^data_lfsr_r[12]^data_lfsr_r[14]^data_lfsr_r[15]}, data_lfsr_r[0:14]}; end
//Connect TX_D to the DATA LFSR assign TX_D = {1{data_lfsr_r}};
//Tie DATA LFSR to REM to generate random words assign TX_REM = data_lfsr_r[0:0];
//Use a counter to determine the size of the next frame to send //frame_size_r 帧计数同时也是每一次帧发送的最大数据个数 always @(posedge USER_CLK) if(reset_c) frame_size_r <= `DLY 8'h00; else if(single_cycle_frame_r || eof_r)// 一个循环的开始或者一帧结束计数 frame_size_r <= `DLY frame_size_r + 1;
//Use a second counter to determine how many bytes of the frame have already been sent //bytes_sent_r计数器计数一次帧传输发送的最大数据个数 always @(posedge USER_CLK) if(reset_c) bytes_sent_r <= `DLY 8'h00; else if(sof_r) bytes_sent_r <= `DLY 8'h01; else if(!TX_DST_RDY_N && !idle_r) bytes_sent_r <= `DLY bytes_sent_r + 1;
//Use a freerunning counter to determine the IFG //这个就是一个计数器用来控制ifg_done_c这个变量 always @(posedge USER_CLK) if(reset_c) ifg_size_r <= `DLY 4'h0; else ifg_size_r <= `DLY ifg_size_r + 1;
//IFG is done when ifg_size register is 0 assign ifg_done_c = (ifg_size_r == 4'h0);
//_____________________________ Framing State machine______________________________ //Use a state machine to determine whether to start a frame, end a frame, send //data or send nothing //下面的状态机决定了是启动一个帧传输,还是发送一帧数据,或者发送数据,或者什么都不发送 //State registers for 1-hot state machine always @(posedge USER_CLK) if(reset_c) begin idle_r <= `DLY 1'b1; single_cycle_frame_r <= `DLY 1'b0; sof_r <= `DLY 1'b0; data_cycle_r <= `DLY 1'b0; eof_r <= `DLY 1'b0; end else if(!TX_DST_RDY_N) begin idle_r <= `DLY next_idle_c;//空闲状态 single_cycle_frame_r <= `DLY next_single_cycle_frame_c;//start aframe 第一帧数据的开始 sof_r <= `DLY next_sof_c;//sof 一帧数据的开始 data_cycle_r <= `DLY next_data_cycle_c;//下一帧 eof_r <= `DLY next_eof_c; end
//Nextstate logic for 1-hot state machine
//在bytes_sent_r值为1-15期间锁存包括single_cycle_frame_r,eof_r,idle_r信号到idle_r //满足条件是 ifg_done_c ==0(即bytes_sent_r计数器工作在1-15期间) //以下三种情况将产生idle_r //1)single_cycle_frame_r代表一帧新的数据开始 //2)eof_r代表一帧传送完成 //3)idle_r代表空闲可以传输数据,在这里还起到所存作用 assign next_idle_c = !ifg_done_c &&//ifg_done_c==0 (single_cycle_frame_r || eof_r || idle_r); //满足条件是 ifg_done_c !=0(即bytes_sent_r=0)并且frame_size_r==0(分复位后以及循环计数归0) //以下三种情况将产生single_cycle_frame_r //1)idle_r代表空闲可以传输数据; //2)single_cycle_frame_r 锁存作用 //3)eof_r代表一帧传送完成 assign next_single_cycle_frame_c = (ifg_done_c && (frame_size_r == 0)) && (idle_r || single_cycle_frame_r || eof_r); //在bytes_sent_r值为0的时候锁存包括single_cycle_frame_r,eof_r,idle_信号到sof_c //满足条件是 ifg_done_c !=0(即bytes_sent_r=0)并且frame_size_r!=0 //以下三种情况将产生sof_r //1)idle_r代表空闲; //2)single_cycle_frame_r 代表每个循环第一帧 //3)eof_r代表一帧传送完成 assign next_sof_c = (ifg_done_c && (frame_size_r != 0)) && (idle_r || single_cycle_frame_r || eof_r); // frame_size_r != bytes_sent_r的时候 锁存 sof_r 和data_cycle_r 到data_cycle_r assign next_data_cycle_c = (frame_size_r != bytes_sent_r) && (sof_r || data_cycle_r); //满足条件是 frame_size_r == bytes_sent_r的时候锁存sof_r和data_cycle_r到eof_c //以下两种情况将产生eof_r //1)sof_r代表一帧开始; //2)data_cycle_r 代表每个帧发送阶段 assign next_eof_c = (frame_size_r == bytes_sent_r) &&//一帧发送完毕 (sof_r || data_cycle_r);//
//Output logic for 1-hot state machine always @(posedge USER_CLK) if(reset_c) begin TX_SOF_N <= `DLY 1'b1; TX_EOF_N <= `DLY 1'b1; TX_SRC_RDY_N <= `DLY 1'b1; end else if(!TX_DST_RDY_N) begin TX_SOF_N <= `DLY !(sof_r || single_cycle_frame_r);//axi Stream 总线接口 sof TX_EOF_N <= `DLY !(eof_r || single_cycle_frame_r);//axi Stream 总线接口 eof TX_SRC_RDY_N <= `DLY idle_r;//axi Stream 总线接口valid end endmodule |
2.5.3 Aurora_8b10b_freme_check.v
FRAME_CHECK模块验证RX数据的完整性。 该模块使用与FRAME_GEN模块相同的LFSR和初始值来生成预期的RX帧数据。 将接收的用户数据与本地生成的流进行比较,并根据AXI4-Stream协议报告任何错误。 FRAME_CHECK模块适用于PDU,UFC和NFC接口。
这里的设计从IPCORE设置向导可以看到我们没有配置UFC或者NFC流控制接口
| module aurora_8b10b_FRAME_CHECK ( // User Interface RX_D, RX_REM, RX_SOF_N, RX_EOF_N, RX_SRC_RDY_N,
// System Interface USER_CLK, RESET, CHANNEL_UP,
ERR_COUNT );
//***********************************Port Declarations*******************************
// User Interface input [0:15] RX_D; input RX_REM; input RX_SOF_N; input RX_EOF_N; input RX_SRC_RDY_N;
// System Interface input USER_CLK; input RESET; input CHANNEL_UP;
output [0:7] ERR_COUNT; //***************************Internal Register Declarations*************************** // Slack registers
reg [0:15] RX_D_SLACK; reg RX_REM_1SLACK; reg RX_REM_2SLACK; reg RX_SOF_N_SLACK; reg RX_EOF_N_SLACK; reg RX_SRC_RDY_N_SLACK;
reg [0:8] err_count_r = 9'd0; reg data_in_frame_r; reg data_valid_r; reg [0:15] RX_D_R; reg [0:15] pdu_cmp_data_r; // RX Data registers reg [0:15] data_lfsr_r;
//*********************************Wire Declarations**********************************
wire reset_c; wire [0:15] data_lfsr_concat_w; wire data_valid_c; wire data_in_frame_c;
wire data_err_detected_c; reg data_err_detected_r;
//*********************************Main Body of Code**********************************
//Generate RESET signal when Aurora channel is not ready assign reset_c = RESET;
// SLACK registers
always @ (posedge USER_CLK) begin RX_D_SLACK <= `DLY RX_D; RX_SRC_RDY_N_SLACK <= `DLY RX_SRC_RDY_N; RX_REM_1SLACK <= `DLY RX_REM; RX_REM_2SLACK <= `DLY RX_REM; RX_SOF_N_SLACK <= `DLY RX_SOF_N; RX_EOF_N_SLACK <= `DLY RX_EOF_N; end
//______________________________ Capture incoming data ___________________________ //·is valid when RX_SRC_RDY_N is asserted and data is arriving within a frame //检测到有效数据 assign data_valid_c = data_in_frame_c && !RX_SRC_RDY_N_SLACK; //检测到一帧数据 //Data is in a frame if it is a single cycle frame or a multi_cycle frame has started assign data_in_frame_c = data_in_frame_r || (!RX_SRC_RDY_N_SLACK && !RX_SOF_N_SLACK);
//RX Data in the pdu_cmp_data_r register is valid //only if it was valid when captured and had no error //数据有效信号data_valid_r always @(posedge USER_CLK) if(reset_c) data_valid_r <= `DLY 1'b0; else if(CHANNEL_UP) data_valid_r <= `DLY data_valid_c && !data_err_detected_c; else data_valid_r <= `DLY 1'b0;
//Start a multicycle frame when a frame starts without ending on the same cycle. End //the frame when an EOF is detected //帧有效 always @(posedge USER_CLK) if(reset_c) data_in_frame_r <= `DLY 1'b0; else if(CHANNEL_UP) begin if(!data_in_frame_r && !RX_SOF_N_SLACK && !RX_SRC_RDY_N_SLACK && RX_EOF_N_SLACK) data_in_frame_r <= `DLY 1'b1; else if(data_in_frame_r && !RX_SRC_RDY_N_SLACK && !RX_EOF_N_SLACK) data_in_frame_r <= `DLY 1'b0; end
//Register and decode the RX_D data with RX_REM bus 对应于keep信号 always @ (posedge USER_CLK) begin //对应axi_stream_last信号和axi_stream_vaild信号,同时有效代表最后一个数据 if((!RX_EOF_N_SLACK) && (!RX_SRC_RDY_N_SLACK)) begin case(RX_REM_1SLACK)//RX_REM_1SLACK作用对应于 是axi_stream_keep 1'd0 : RX_D_R <= `DLY {RX_D_SLACK[0:7], 8'b0};//0-7 有效 8-15 1'd1 : RX_D_R <= `DLY RX_D_SLACK;// 0-15有效 default : RX_D_R <= `DLY RX_D_SLACK; endcase end else if(!RX_SRC_RDY_N_SLACK)//读取数据 RX_D_R <= `DLY RX_D_SLACK; end
//Calculate the expected frame data //随机数发生部分的数据寄存,包括有效数据部分 always @ (posedge USER_CLK) begin if(reset_c) pdu_cmp_data_r <= `DLY {1{16'hD5E6}}; else if(CHANNEL_UP) begin if(data_valid_c && !RX_EOF_N_SLACK) begin case(RX_REM_2SLACK) 1'd0 : pdu_cmp_data_r <= `DLY {data_lfsr_concat_w[0:7], 8'b0}; 1'd1 : pdu_cmp_data_r <= `DLY data_lfsr_concat_w; default : pdu_cmp_data_r <= `DLY data_lfsr_concat_w; endcase end else if(data_valid_c) pdu_cmp_data_r <= `DLY data_lfsr_concat_w; end end
//generate expected RX_D using LFSR //产生和发送端口匹配的随机数列 always @(posedge USER_CLK) if(reset_c) begin data_lfsr_r <= `DLY 16'hD5E6; //random seed value end else if(CHANNEL_UP) begin if(data_valid_c) data_lfsr_r <= `DLY {!{data_lfsr_r[3]^data_lfsr_r[12]^data_lfsr_r[14]^data_lfsr_r[15]}, data_lfsr_r[0:14]}; end else begin data_lfsr_r <= `DLY 16'hD5E6; //random seed value end
assign data_lfsr_concat_w = {1{data_lfsr_r}};
//___________________________ Check incoming data for errors __________________________
//An error is detected when LFSR generated RX data from the pdu_cmp_data_r register, //does not match valid data from the RX_D port //比较数据是否和发送的一致 assign data_err_detected_c = (data_valid_r && (RX_D_R != pdu_cmp_data_r));
//We register the data_err_detected_c signal for use with the error counter logic //寄存error一次 always @(posedge USER_CLK) data_err_detected_r <= `DLY data_err_detected_c;
//Compare the incoming data with calculated expected data. //Increment the ERROR COUNTER if mismatch occurs. //Stop the ERROR COUNTER once it reaches its max value (i.e. 255) //error计数器 always @(posedge USER_CLK) if(CHANNEL_UP) begin if(&err_count_r) err_count_r <= `DLY err_count_r; else if(data_err_detected_r) err_count_r <= `DLY err_count_r + 1; end else begin err_count_r <= `DLY 9'd0; end
//Here we connect the lower 8 bits of the count (the MSbit is used only to check when the counter reaches //max value) to the module output assign ERR_COUNT = err_count_r[1:8];
endmodule |
2.5.4 Aurora_8b10b_ll_to_axi_exdes.v
实现了旧信号转换为AXI Stream接口信号
| module aurora_8b10b_LL_TO_AXI_EXDES # ( parameter DATA_WIDTH = 16, // DATA bus width parameter STRB_WIDTH = 2, // STROBE bus width parameter USE_UFC_REM = 0, // UFC REM bus width identifier parameter USE_4_NFC = 0, // 0 => PDU, 1 => NFC, 2 => UFC parameter BC = DATA_WIDTH/8, //Byte count parameter REM_WIDTH = 1 // REM bus width
) (
// LocalLink input Interface LL_IP_DATA, LL_IP_SOF_N, LL_IP_EOF_N, LL_IP_REM, LL_IP_SRC_RDY_N, LL_OP_DST_RDY_N,
// AXI4-S output signals AXI4_S_OP_TVALID, AXI4_S_OP_TDATA, AXI4_S_OP_TKEEP, AXI4_S_OP_TLAST, AXI4_S_IP_TREADY
);
`define DLY #1
//***********************************Port Declarations*******************************
// AXI4-Stream TX Interface output [0:(DATA_WIDTH-1)] AXI4_S_OP_TDATA; output [0:(STRB_WIDTH-1)] AXI4_S_OP_TKEEP; output AXI4_S_OP_TVALID; output AXI4_S_OP_TLAST; input AXI4_S_IP_TREADY;
// LocalLink TX Interface input [0:(DATA_WIDTH-1)] LL_IP_DATA; input [0:(REM_WIDTH-1)] LL_IP_REM; input LL_IP_SOF_N; input LL_IP_EOF_N; input LL_IP_SRC_RDY_N; output LL_OP_DST_RDY_N;
wire [0:(STRB_WIDTH-1)] AXI4_S_OP_TKEEP_i;
//*********************************Main Body of Code**********************************
assign AXI4_S_OP_TDATA = LL_IP_DATA;
assign AXI4_S_OP_TKEEP = AXI4_S_OP_TKEEP_i ;
assign AXI4_S_OP_TVALID = !LL_IP_SRC_RDY_N; assign AXI4_S_OP_TLAST = !LL_IP_EOF_N; assign AXI4_S_OP_TKEEP_i = (LL_IP_REM == 1'b1)? 2'b11:2'b10; assign LL_OP_DST_RDY_N = !AXI4_S_IP_TREADY;
endmodule |
2.5.5 Aurora_8b10b_axi_to_ll_exdes.v
实现了AXI Stream接口信号转换未旧的接口信号
| module aurora_8b10b_AXI_TO_LL_EXDES # ( parameter DATA_WIDTH = 16, // DATA bus width parameter STRB_WIDTH = 2, // STROBE bus width parameter BC = DATA_WIDTH/8, //Byte count parameter USE_4_NFC = 0, // 0 => PDU, 1 => NFC, 2 => UFC parameter REM_WIDTH = 1 // REM bus width ) ( // AXI4-S input signals AXI4_S_IP_TX_TVALID, AXI4_S_IP_TX_TREADY, AXI4_S_IP_TX_TDATA, AXI4_S_IP_TX_TKEEP, AXI4_S_IP_TX_TLAST,
// LocalLink output Interface LL_OP_DATA, LL_OP_SOF_N, LL_OP_EOF_N, LL_OP_REM, LL_OP_SRC_RDY_N, LL_IP_DST_RDY_N,
// System Interface USER_CLK, RESET, CHANNEL_UP );
`define DLY #1
//***********************************Port Declarations*******************************
// AXI4-Stream Interface input [0:(DATA_WIDTH-1)] AXI4_S_IP_TX_TDATA; input [0:(STRB_WIDTH-1)] AXI4_S_IP_TX_TKEEP; input AXI4_S_IP_TX_TVALID; input AXI4_S_IP_TX_TLAST; output AXI4_S_IP_TX_TREADY;
// LocalLink TX Interface output reg [0:(DATA_WIDTH-1)] LL_OP_DATA; output reg [0:(REM_WIDTH-1)] LL_OP_REM; output reg LL_OP_SRC_RDY_N; output reg LL_OP_SOF_N; output reg LL_OP_EOF_N; input LL_IP_DST_RDY_N;
// System Interface input USER_CLK; input RESET; input CHANNEL_UP;
reg new_pkt_r;
wire new_pkt; wire [0:(STRB_WIDTH-1)] AXI4_S_IP_TX_TKEEP_i;
//*********************************Main Body of Code********************************** assign AXI4_S_IP_TX_TREADY = !LL_IP_DST_RDY_N;
always @ (posedge USER_CLK) begin LL_OP_DATA = AXI4_S_IP_TX_TDATA; end
assign AXI4_S_IP_TX_TKEEP_i = AXI4_S_IP_TX_TKEEP;
always @ (posedge USER_CLK) begin LL_OP_SRC_RDY_N = !AXI4_S_IP_TX_TVALID; LL_OP_EOF_N = !AXI4_S_IP_TX_TLAST; LL_OP_REM = (AXI4_S_IP_TX_TKEEP_i == 2'b10) ? 1'b0 : 1'b1; LL_OP_SOF_N = ~ ( ( AXI4_S_IP_TX_TVALID && AXI4_S_IP_TX_TREADY && AXI4_S_IP_TX_TLAST ) ? ((new_pkt_r) ? 1'b0 : 1'b1) : (new_pkt && (!new_pkt_r))); end
assign new_pkt = ( AXI4_S_IP_TX_TVALID && AXI4_S_IP_TX_TREADY && AXI4_S_IP_TX_TLAST ) ? 1'b0 : ((AXI4_S_IP_TX_TVALID && AXI4_S_IP_TX_TREADY && !AXI4_S_IP_TX_TLAST ) ? 1'b1 : new_pkt_r);
always @ (posedge USER_CLK) begin if(RESET) new_pkt_r <= `DLY 1'b0; else if(CHANNEL_UP) new_pkt_r <= `DLY new_pkt; else new_pkt_r <= `DLY 1'b0; end
endmodule |
2.6 代码软件仿真
2.6.1仿真部分程序构架

图2-6-1和图2-6-2展示了本次demo设计的仿真构架,从中可以看出仿真部分调用了2个实例,并且分布把他们的RX 接到TX,TX接到RX实现互联。
2.6.2仿真文件顶层代码
| module aurora_8b10b_TB; //*************************Parameter Declarations************************** parameter SIM_MAX_TIME = 9500000; //To quit the simulation //125.0MHz GT Reference clock parameter CLOCKPERIOD_1 = 8.0 ; parameter CLOCKPERIOD_2 = 8.0 ; //parameter CLOCKPERIOD_1 = 8.0; //parameter CLOCKPERIOD_2 = 8.0; parameter DRP_CLOCKPERIOD = 10.000 ; //GT DRP Clock parameter INIT_CLOCKPERIOD = 20.0 ; // Board/System Clock //************************Internal Register Declarations***************************** //Freerunning Clock reg reference_clk_1_n_r; reg reference_clk_2_n_r; reg drp_clk_r; reg init_clk_p;
//Global signals reg gt_reset_in; reg gsr_r; reg gts_r; reg reset_i; //********************************Wire Declarations********************************** //Freerunning Clock wire reference_clk_1_p_r; wire reference_clk_2_p_r;
wire init_clk_n; //Dut1
//Error Detection Interface wire hard_err_1_i; wire soft_err_1_i; wire frame_err_1_i; //Status wire channel_up_1_i; wire lane_up_1_i;
//GT Serial I/O wire rxp_1_i; wire rxn_1_i;
wire txp_1_i; wire txn_1_i;
// Error signals from the Local Link packet checker wire [0:7] err_count_1_i; //Dut2 //Error Detection Interface wire hard_err_2_i; wire soft_err_2_i; wire frame_err_2_i; //Status wire channel_up_2_i; wire lane_up_2_i; //GT Serial I/O wire rxp_2_i; wire rxn_2_i; wire txp_2_i; wire txn_2_i; // Error signals from the Local Link packet checker wire [0:7] err_count_2_i;
//*********************************Main Body of Code********************************** //_________________________Serial Connections________________ assign rxn_1_i = txn_2_i; assign rxp_1_i = txp_2_i; assign rxn_2_i = txn_1_i; assign rxp_2_i = txp_1_i; //__________________________Global Signals_____________________________ //Simultate the global reset that occurs after configuration at the beginning //of the simulation. Note that both GT smart models use the same global signals. assign glbl.GSR = gsr_r; assign glbl.GTS = gts_r; initial begin gts_r = 1'b0; gsr_r = 1'b1; gt_reset_in = 1'b1; #5000; gsr_r = 1'b0; gt_reset_in = 1'b0; repeat(10) @(posedge init_clk_p); gt_reset_in = 1'b1; repeat(10) @(posedge init_clk_p); gt_reset_in = 1'b0; end //____________________________Clocks____________________________ initial reference_clk_1_n_r = 1'b0;
always #(CLOCKPERIOD_1 / 2) reference_clk_1_n_r = !reference_clk_1_n_r; assign reference_clk_1_p_r = !reference_clk_1_n_r; initial reference_clk_2_n_r = 1'b0; always #(CLOCKPERIOD_2 / 2) reference_clk_2_n_r = !reference_clk_2_n_r; assign reference_clk_2_p_r = !reference_clk_2_n_r; initial drp_clk_r = 1'b0;
always #(DRP_CLOCKPERIOD / 2) drp_clk_r = !drp_clk_r;
initial init_clk_p = 1'b0; always #(INIT_CLOCKPERIOD / 2) init_clk_p = !init_clk_p; assign init_clk_n = !init_clk_p; //____________________________Resets____________________________
initial begin reset_i = 1'b1; #1000 reset_i = 1'b0; end //________________________Instantiate Dut 1 ________________ aurora_8b10b_exdes example_design_1_i ( // User IO .RESET(reset_i), // Error signals from Aurora .HARD_ERR(hard_err_1_i), .SOFT_ERR(soft_err_1_i), .FRAME_ERR((frame_err_1_i)),
// Status Signals .LANE_UP(lane_up_1_i), .CHANNEL_UP(channel_up_1_i), .INIT_CLK_P(init_clk_p), .INIT_CLK_N(init_clk_n), .DRP_CLK_IN(drp_clk_r), .GT_RESET_IN(gt_reset_in),
// Clock Signals .GTXQ2_P(reference_clk_1_p_r), .GTXQ2_N(reference_clk_1_n_r),
// GT I/O .RXP(rxp_1_i), .RXN(rxn_1_i), .TXP(txp_1_i), .TXN(txn_1_i), // Error signals from the Local Link packet checker .ERR_COUNT(err_count_1_i) ); //________________________Instantiate Dut 2 ________________
aurora_8b10b_exdes example_design_2_i ( // User IO .RESET(reset_i), // Error signals from Aurora .HARD_ERR(hard_err_2_i), .SOFT_ERR(soft_err_2_i), .FRAME_ERR((frame_err_2_i)),
// Status Signals .LANE_UP(lane_up_2_i), .CHANNEL_UP(channel_up_2_i), .INIT_CLK_P(init_clk_p), .INIT_CLK_N(init_clk_n), .DRP_CLK_IN(drp_clk_r), .GT_RESET_IN(gt_reset_in), // Clock Signals .GTXQ2_P(reference_clk_2_p_r), .GTXQ2_N(reference_clk_2_n_r), // GT I/O .RXP(rxp_2_i), .RXN(rxn_2_i), .TXP(txp_2_i), .TXN(txn_2_i), // Error signals from the Local Link packet checker .ERR_COUNT(err_count_2_i) );
always @ (posedge channel_up_1_i or posedge channel_up_2_i) begin if((channel_up_1_i == 1'b1) && (channel_up_2_i == 1'b1)) begin $display("\naurora_8b10b_TB : INFO : @Time : %t CHANNEL_UP is asserted in both DUT\n", $time); #5000 $display("\naurora_8b10b_TB : INFO : Test Completed Successfully\n"); $finish; end end
always @ (posedge err_count_1_i[7] or posedge err_count_2_i[7]) begin if((err_count_1_i >= 8'b0000_0001) || (err_count_2_i >= 8'b0000_0001)) begin $display("\nAURORA_TB : ERROR : TEST FAIL\n"); $display("\nAURORA_TB : INFO : ERR_COUNT1 = %b ERR_COUNT2 = %b\n",err_count_1_i,err_count_2_i); #1000 $display("AURORA_TB : INFO : Exiting from simulation ....\n"); $finish; end end
//Abort the simulation when it reaches to max time limit initial begin #(SIM_MAX_TIME) $display("\nAURORA_TB : INFO : Reached max. simulation time limit\n"); $finish; end endmodule |
2.6.3 仿真波形图
如果读者不会仿真可以阅读我们前面的课程内容,另外仿真波形需要在大约2.587MS的地方出现数据,因此需要把仿真时间设置长一点并且耐心等待。
下图中是发送部分的仿真波形图,可以看出来idle_r/single_frame_r/sof_r/
data_cycle_r/data_cycle_r/eof_r 这些有关于状态信号之间的相互关系。在下图的黄线位置,可以看到第一帧数据开始的时候data_lfsr_r/frame_size_r/bytes_sent_r/ifg_size_r和idle_r/single_frame_r/sof_r/data_cycle_r/data_cycle_r/eof_r这些状态信号直接的关系。

图2-6-3-1 仿真波形1
下图的仿真波形更加清晰的展示了这些信号的相互关系。当eof_r信号为1后的下一个时钟,idle_r变为高,直到ifg_size_r=0的时候,同时sof_r和data_cycle_r为1,sof_r只持续一个时钟周期,而data_cycle_r会一直持续到下次的ifg_size_r=0。

图2-6-3-2 仿真波形2
图2-6-3-3和图图2-6-3-4是为了对比发送部分的数据和接收的数据是一致。

图2-6-3-3 仿真波形3

图2-6-3-4 仿真波形4
注意:以上仿真波形并不是完整的,完整的波形需要仿真非常长的时间,我们只是截取了其中一部分,但是已经可以说明问题了。
2.7编译下载测试
2.7.1顶层文件修改
由于程序默认把很多信号引出去,这样需要分配许多IP,这样做需要很多LED指示灯,这样做不是非常有必要,因为可以通过内嵌的逻辑分析仪观察这些信号。所以对这些文件做一些修改。
| module aurora_8b10b_exdes # ( parameter USE_CORE_TRAFFIC = 1, parameter USE_CHIPSCOPE = 1 //pragma translate_off & 0 //pragma translate_on ) ( // User IO sys_rst_n, INIT_CLK_IN, sfp_tx_disable, GTXQ3_P, GTXQ3_N, // GT I/O RXP, RXN, TXP, TXN
); //***********************************Port Declarations******************************* //***********************ADD**************************** output sfp_tx_disable; input sys_rst_n; input INIT_CLK_IN; //***********************ADD_END************************ // Clocks input GTXQ3_P; input GTXQ3_N;
// GT Serial I/O input RXP; input RXN; output TXP; output TXN; //********************************Wire Declarations********************************** //***********************ADD**************************** wire GT_RESET_IN; wire RESET; assign GT_RESET_IN = ~sys_rst_n; assign RESET = ~sys_rst_n; assign sfp_tx_disable = 1'b0; //***********************ADD_END************************ // LocalLink TX Interface
.... //*********************************Main Body of Code**********************************
//***********************ADD**************************** IBUFG init_clk_bufg (.O (init_clk_i), .I (INIT_CLK_IN) ); assign drpclk_i =init_clk_i; //***********************ADD_END************************....
|
2.7.2添加PIN脚约束
| ################################################################################ ## XDC generated for xc7z035-ffg676-2 device # 125.0MHz GT Reference clock constraint create_clock -name GT_REFCLK1 -period 8.0 [get_ports GTXQ3_P] ####################### GT reference clock LOC ####################### set_property LOC U5 [get_ports GTXQ3_N] set_property LOC U6 [get_ports GTXQ3_P]
set_property PACKAGE_PIN H12 [get_ports sys_rst_n] set_property IOSTANDARD LVCMOS18 [get_ports sys_rst_n]
# 10.0 ns period Board Clock Constraint create_clock -name init_clk_i -period 10.0 [get_ports INIT_CLK_IN] set_property PACKAGE_PIN C8 [get_ports INIT_CLK_IN] set_property IOSTANDARD SSTL15 [get_ports INIT_CLK_IN]
set_property PACKAGE_PIN J11 [get_ports sfp_tx_disable] set_property IOSTANDARD LVCMOS15 [get_ports sfp_tx_disable]
###### CDC in RESET_LOGIC from INIT_CLK to USER_CLK ############## set_false_path -to [get_pins -hier *aurora_8b10b_cdc_to*/D]
############################### GT LOC ################################### set_property LOC GTXE2_CHANNEL_X0Y15 [get_cells aurora_module_i/inst/aurora_8b10b_core_i/gt_wrapper_i/aurora_8b10b_multi_gt_i/gt0_aurora_8b10b_i/gtxe2_i]
connect_debug_port dbg_hub/clk [get_nets init_clk_i]
|
2.7.3编译并且在线仿真
Step1:单块板子可以直接用1根光纤把RX和TX环路起来,如图所示。

图1-7-3-1开发板测试连接图
Step2:设置逻辑分析的触发信号

Step3:观察发送部分信号和数据
由于数据没有错误,所以需要手动触发以此以此来观察数据
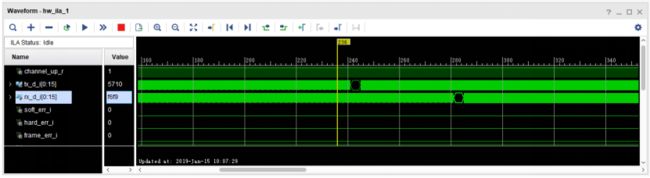
Step4:观察接收信号和数据

Step5:设置vio虚拟IO部分信号调试如下图设置gtreset_vio_i信号为1

之后再观察在线逻辑分析仪串口
