Python3,听说这个第三方库竟碾压python自带JSON库。
orjson
- 1、引言
- 2、示例实战
-
- 2.1 安装
- 2.2 序列化
- 2.3 反序列化
- 2.4 OPTION选项
-
- 2.4.1 OPT_INDENT_2
- 2.4.2 OPTION组合
- 2.4.3 OPT_SERIALIZE_NUMPY
- 2.4.4 OPT_SERIALIZE_UUID
- 2.4.5 OPT_SORT_KEYS
- 2.5 自定义处理策略
-
- 2.5.1 对数据进行脱敏
- 2.5.2 日期自定义转换
- 3、总结
1、引言
小屌丝:鱼哥,学习python,必须要掌握哪些库?
小鱼:这要看你从事哪方面的开发了。
小屌丝:这还有关系呢?
小鱼:那肯定的啊,
- 如果你学习AI,就需要掌握Scikit-learn库、Pytorch、Tensorflow等,
- 如果你学习数据分析,那需要掌握Pandas、Numpy 等
- 如果学习爬虫开发,那就需要掌握request、BeautifulSoup、lxml、re等
小屌丝:鱼哥,那你说,我把json库玩的特别溜,我能不能从事python后端开发??
小鱼:嗯?? 你确定你json库玩的特别溜吗?
小屌丝:那还有假,倒背如流。
小鱼:那正好,有个粉丝提问,json库存储能力差,如何能解决这个问题呢?
小屌丝:额…
小鱼:“略带微笑”… 想一想,该如何回答?

小屌丝:…这个问题,正好是我也想问你的。
小鱼:…好吧。
关于粉丝提问的如何解决json库性能差,功能少等问题,
我们可以换一个思路来理解,
是否有一个第三方josn库,可以解决这些问题呢?
答案是,肯定的。
例如:ujson库、rapidjson、simplejson、orjson等等。
但是在这些json第三方库中,又有一个,性能是碾压其他库的,
小屌丝:难道是 orjson库?
小鱼:嗯,你可算是说对一次了。
接下来,我们就来介绍orjson库。
2、示例实战
因为orjson支持 python版本:3.7 ~ 3.10的所有64的版本。
2.1 安装
凡是涉及第三方库,必须需要安装
老规矩,pip 安装:
pip install orjson
其它安装方式,直接看这两篇:
- 《Python3,选择Python自动安装第三方库,从此跟pip说拜拜!!》
- 《Python3:我低调的只用一行代码,就导入Python所有库!》
2.2 序列化
- orjson 序列化结果是 bytes型
- json 序列化结果 是 str型
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import json
import orjson
import random
import time
'''
序列化
orjson 序列化结果是 bytes型
json 序列化结果 是 str型
'''
# 序列化100W个典元素的列表进行序列化
demo_json = [
{
'id' : 99999,
'value': random.uniform(0,1000)
}
for i in range(1000000)
]
运行结果

我们可以看到,json运行结果1.73s
orjson运行结果191ms
结果跟我们的预期一样,奈斯。
2.3 反序列化
将JSON数据转换为Python对象的过程我们称之为反序列化,使用orjson.loads()进行操作,可接受bytes、str型等常见类型,
我们依然使用上面的代码示例。
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import json
import orjson
import random
import time
'''
反序列化
'''
# 序列化100W个典元素的列表进行序列化
demo_json = [
{
'id' : 99999,
'value': random.uniform(0,1000)
}
for i in range(1000000)
]
运行结果

2.4 OPTION选项
2.4.1 OPT_INDENT_2
orjson的序列化操作中,可以通过参数option来配置诸多额外功能,
例如:
配置option=orjson.OPT_INDENT_2,
可以为序列化后的JSON结果添加2个空格的缩进美化效果,从而弥补其没有参数indent的不足,
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import json
import orjson
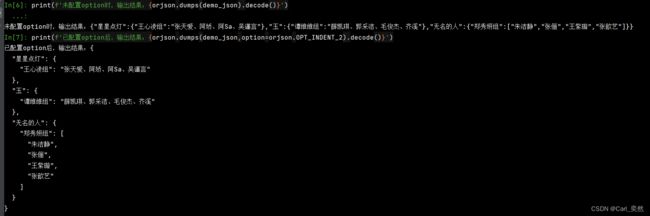
demo_json = {"星星点灯":{"王心凌组":"张天爱、阿娇、阿Sa、吴谨言"},"玉":{"谭维维组":"薛凯琪、郭采洁、毛俊杰、齐溪"},"无名的人":{"郑秀妍组":["朱洁静","张俪","王紫璇","张歆艺"]}}
#默认输出结果
print(f'未配置option时,输出结果:{orjson.dumps(demo_json).decode()}')
#设置OPT_INDENT_2
print(f'已配置option后,输出结果:{orjson.dumps(demo_json,option=orjson.OPT_INDENT_2).decode()}')
运行结果
2.4.2 OPTION组合
当序列化操作需要涉及多种option功能时,则可以使用|运算符来组合多个option参数即可:
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import numpy as np
import json
import orjson
'''
组合多种option
'''
demo_json = {
'zz':np.random.randint(1,10,(2,3)),
'xx':np.random.randint(1,10,(2,3)),
'aa':np.random.randint(1,10,(2,3))
}
print(orjson.dumps(demo_json,option=orjson.OPT_SERIALIZE_NUMPY | orjson.OPT_SORT_KEYS))
运行结果
![]()
2.4.3 OPT_SERIALIZE_NUMPY
orjson的一大重要特性是其可以将包含numpy中数据结构对象的复杂对象,兼容性地转换为JSON中的数组,配合option=orjson.OPT_SERIALIZE_NUMPY即可:
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import numpy as np
import json
import orjson
'''
OPT_SERIALIZE_NUMPY
'''
demo_json = {
'np':np.random.randint(1,10,(5,10))
}
demo_json
orjson.dumps(demo_json,option=orjson.OPT_SERIALIZE_NUMPY)
运行结果

2.4.4 OPT_SERIALIZE_UUID
除了可以自动序列化numpy对象外,orjson还支持对UUID对象进行转换,在orjson 3.0之前的版本中,需要配合option=orjson.OPT_SERIALIZE_UUID,
但是小鱼用的是3.9的版本,所以不需要额外配置参数。
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import numpy as np
import uuid
import json
import orjson
'''
OPT_SERIALIZE_UUID
'''
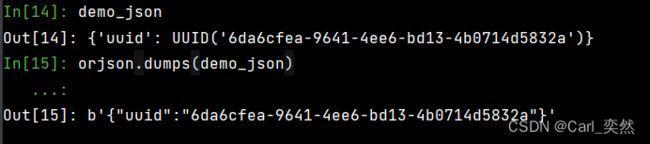
demo_json = {
'uuid':uuid.uuid4()
}
demo_json
orjson.dumps(demo_json)
运行结果
2.4.5 OPT_SORT_KEYS
通过配合参数option=orjson.OPT_SORT_KEYS,可以对序列化后的结果自动按照键进行排序。
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import json
import orjson
'''
OPT_SORT_KEYS
'''
#未设置排序
orjson.dumps({"c":1,"b":11,"a":6})
#设置排序
orjson.dumps({"c":1,"b":11,"a":6},option=orjson.OPT_SORT_KEYS)
运行结果

2.5 自定义处理策略
2.5.1 对数据进行脱敏
如果需要序列化的对象中涉及到dataclass自定义数据结构时,
可以使用orjson.OPT_PASSTHROUGH_DATACLASS,
再通过对default参数传入自定义处理函数,来实现更为自由的数据转换逻辑。
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
from dataclasses import dataclass
import uuid
import orjson
@dataclass
class User:
id:str
tel_numb:int
def default(obj):
if isinstance(obj,User):
tel_numb_st = str(obj.tel_numb)
return {
'id':obj.id,
'tel_numb':f'{tel_numb_st[:3]}xxxx{tel_numb_st[-4:]}'
}
raise TypeError
demo_json = {
'user':User(id=str(uuid.uuid4()),tel_numb=13666667777)
}
orjson.dumps(demo_json,
option=orjson.OPT_PASSTHROUGH_DATACLASS,
default=default)
运行结果
![]()
2.5.2 日期自定义转换
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-07-03
# @Author : carl_DJ
import orjson
from datetime import datetime
def default(obj):
if isinstance(obj,datetime):
return obj.strftime('%Y年%m月%d日')
raise TypeError
demo_json = {
'now':datetime.now()
}
orjson.dumps(demo_json,
option=orjson.OPT_PASSTHROUGH_DATETIME,
default=default).decode()
运行结果

3、总结
看到这里,今天的分享差不多就要结束了。
关于orjson库的知识,也讲的差不多了。
如果orjson能解决的问题,还是建议使用orjson这个第三方库。
因为不管是从性能、自由组合配置等都是吊打json库的,
但是,
对数据的处理没有那么高的要求,就是小数据量的处理,那就保持原样即可。
不管怎样,能在工作中解决掉问题,即可。
最后,再唠叨一句:
关注小鱼博客,带你学习更多关于python第三方库的知识。