transformer学习之多头注意力机制
文章目录
-
-
- 题目
- 注意力机制
- 多头注意力机制
- 为什么要使用多头注意力机制
- 代码实现
-
题目
transformer学习之多头注意力机制
注意力机制
详细了解 ➡️ 注意力机制
之前我们也学习过了Seq2Seq,知道了把注意力机制加入到它后会使模型学习的更有效率,那么现在到了全部都由注意力机制构成的Transformer,它和Seq2Seq中加入的注意力有什么不同呢?
不同点
| Seq2Seq里的Attention | Transformer |
|---|---|
| s ( Q , K ) = Q T K s(Q,K)=Q^TK s(Q,K)=QTK | s ( Q , K ) = Q T K d k s(Q,K)=\frac{Q^TK}{\sqrt{d_k}} s(Q,K)=dkQTK |
| 单一头注意力机制 | 多头注意力机制 |
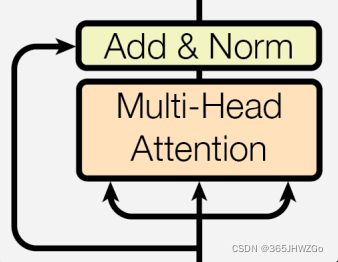
多头注意力机制
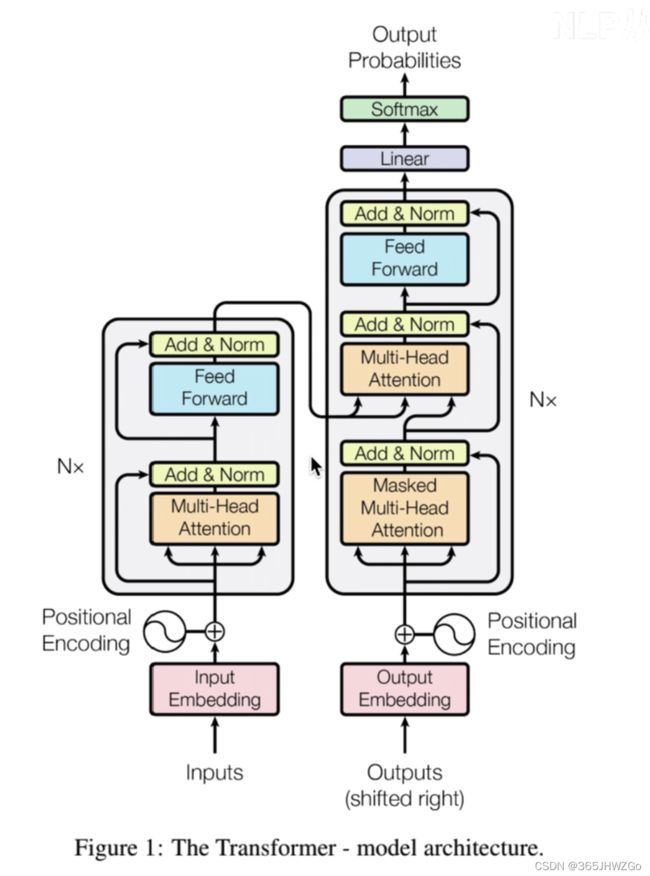
!!!多头注意力机制在encoder和decoder中的机制是不一样的。
因为在decoder中要根据前面的信息进行预测输出,所以就必须把当前单词后的信息给隐藏掉,需要使用Mask来进行遮挡。

注意上图的mask是opt【可选的】
就好比,你要猜测你的好友去哪里玩了,你让他说关键词你来猜,如果你已经知道地址了就用不着猜了,对吧!所以需要要在朋友说出答案前猜出!
具体实现过程,请看后续~
这里只需要知道,两者是不同的。
多头它的意思就是使用不同的W参数
i.e.假设一句话有10个单词,使用8头注意力机制
那么Q的参数矩阵就有8个,分别为 W Q = { W Q 1 , W Q 2 , W Q 3 , W Q 4 . . . W Q 8 } W_Q =\{W_{Q1},W_{Q2},W_{Q3},W_{Q4}...W_{Q8}\} WQ={WQ1,WQ2,WQ3,WQ4...WQ8}
同理
K的参数矩阵就有8个,分别为 W K = { W K 1 , W K 2 , W K 3 , W K 4 . . . W K 8 } W_K =\{W_{K1},W_{K2},W_{K3},W_{K4}...W_{K8}\} WK={WK1,WK2,WK3,WK4...WK8}
V的参数矩阵就有8个,分别为 W V = { W V 1 , W V 2 , W V 3 , W V 4 . . . W V 8 } W_V=\{W_{V1},W_{V2},W_{V3},W_{V4}...W_{V8}\} WV={WV1,WV2,WV3,WV4...WV8}
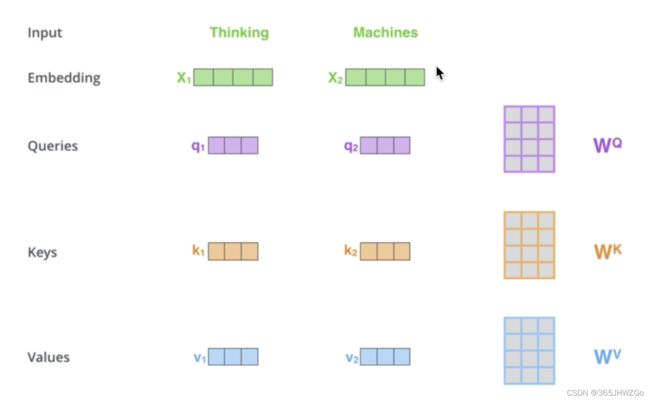
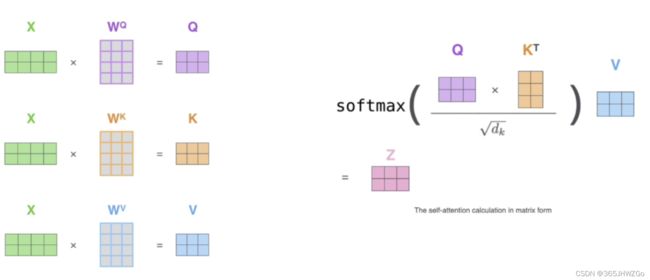
下图是一头注意力机制下 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV的计算
下图是多头注意力机制下 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV的计算
平铺展开

立体叠放

为什么要使用多头注意力机制
好处
- 论文作者在实验中得到证明,多头注意力机制下的实现效果更好
- 多头,意味着对同一个单词进行多次映射,每当映射到一个空间时,这个单词就被赋予了新的含义,使得Transformer注意到子空间的信息。
代码实现
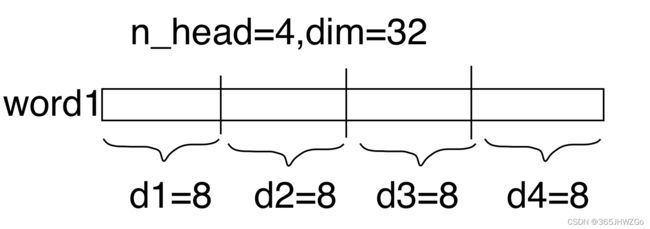
实现的是下图所示代码
class MultiHead(nn.Module):
def __init__(self, n_head, model_dim, drop_rate):
# n_head 有几层注意力机制
# model_dim 模型的维度
# drop_rate 随机丢弃率
super().__init__()
self.head_dim = model_dim // n_head # 32//4=8
self.wq = nn.Linear(model_dim, n_head * self.head_dim) # [4*8]
self.wk = nn.Linear(model_dim, n_head * self.head_dim)
self.wv = nn.Linear(model_dim, n_head * self.head_dim)
self.o_dense = nn.Linear(model_dim, model_dim)
self.o_drop = nn.Dropout(drop_rate)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, q, k, v, mask, training):
# residual connect
# q=k=v=[batch_size,seq_len, emb_dim]=[32,11,32]
residual = q # 残差
# linear projection
key = self.wk(k) # [batch_size,seq_len, num_heads * head_dim]
value = self.wv(v) # [batch_size,seq_len, num_heads * head_dim]
query = self.wq(q) # [batch_size,seq_len, num_heads * head_dim]
# 将头分离出来
# [step,n_head,n,head_dim] = [batch_size,头的数量,seq_len,每个头的维度]
query = self.split_heads(query) # [32,4,11,8]
key = self.split_heads(key) # [32,4,11,8]
value = self.split_heads(value) # [32,4,11,8]
# 自注意力机制 点乘
context = self.scaled_dot_product_attention(
query, key, value, mask) # [batch_size,seq_len, model_dim]
# 再经过一个线性变化
o = self.o_dense(context) # [batch_size,seq_len, model_dim]
# 随机使得一些权重失效
o = self.o_drop(o)
# layer normalization
o = self.layer_norm(residual+o)
return o
def split_heads(self, x):
x = torch.reshape(
x, (x.shape[0], x.shape[1], self.n_head, self.head_dim))
# x = [step,n_head,n,head_dim]
return x.permute(0, 2, 1, 3)
def scaled_dot_product_attention(self, q, k, v, mask=None):
# [32,4,11,11]
# dk = 8
dk = torch.tensor(k.shape[-1]).type(torch.float)
score = torch.matmul(q, k.permute(0, 1, 3, 2)) / (torch.sqrt(dk) + 1e-8) # [step, n_head, n, n]=[32, 4, 11, 11]
if mask is not None:
score = score.masked_fill_(mask, -np.inf)
self.attention = softmax(score, dim=-1) # [32, 4, 11, 11]
context = torch.matmul(self.attention, v) # [step, num_head, n, head_dim]
context = context.permute(0, 2, 1, 3) # [batch_size,seq_len, num_head, head_dim]
context = context.reshape((context.shape[0], context.shape[1], -1))
return context # [batch_size,seq_len, model_dim]
注意:
代码在实现过程中并不是用的我上述讲的方法【用n_head个W矩阵进行乘积】
它是利用一个单词的维度【dim=32】将其分为4个头【n_head】,每个头的维度为8,这样做的好处是避免多次循环,可以一次性完成运算。
实现过程如下图所示