在以前的文章中,我们讨论过Transformer并不适合时间序列预测任务。为了解决这个问题Google创建了Hybrid Transformer-LSTM模型,该模型可以实现SOTA导致时间序列预测任务。
但是我实际测试效果并不好,直到2022年3月Google研究团队和瑞士AI实验室IDSIA提出了一种新的架构,称为Block Recurrent Transformer [2]。
从名字中就能看到,这是一个新型的Transformer模型,它利用了lstm的递归机制,在长期序列的建模任务中实现了显著改进。
@``
在介绍它之前,让我们简要讨论与LSTMS相比,Transformer的优势和缺点。这将帮助你了解这个新架构的工作原理。
Transformer vs LSTM
Transformer 最显著的优点总结如下
并行性
LSTM实现了顺序处理:输入(比如说句子)逐字处理。
Transformer 使用非顺序处理:句子是作为一个整体处理的,而不是一个字一个字地处理。
图1和图2更好地说明了这种比较。
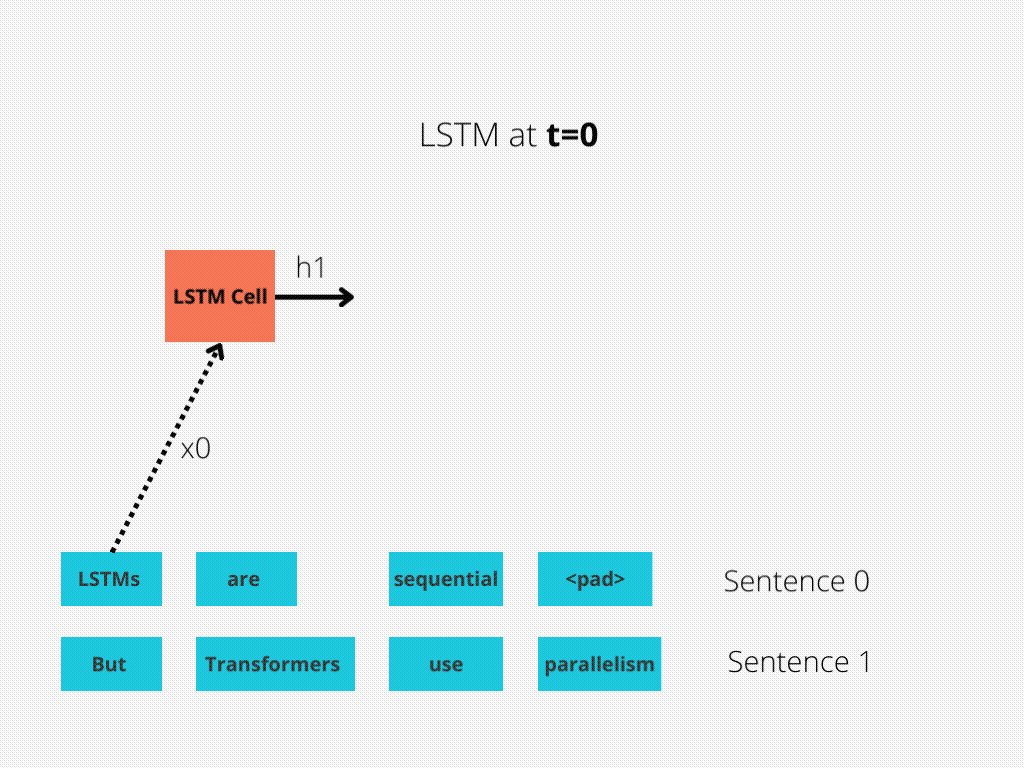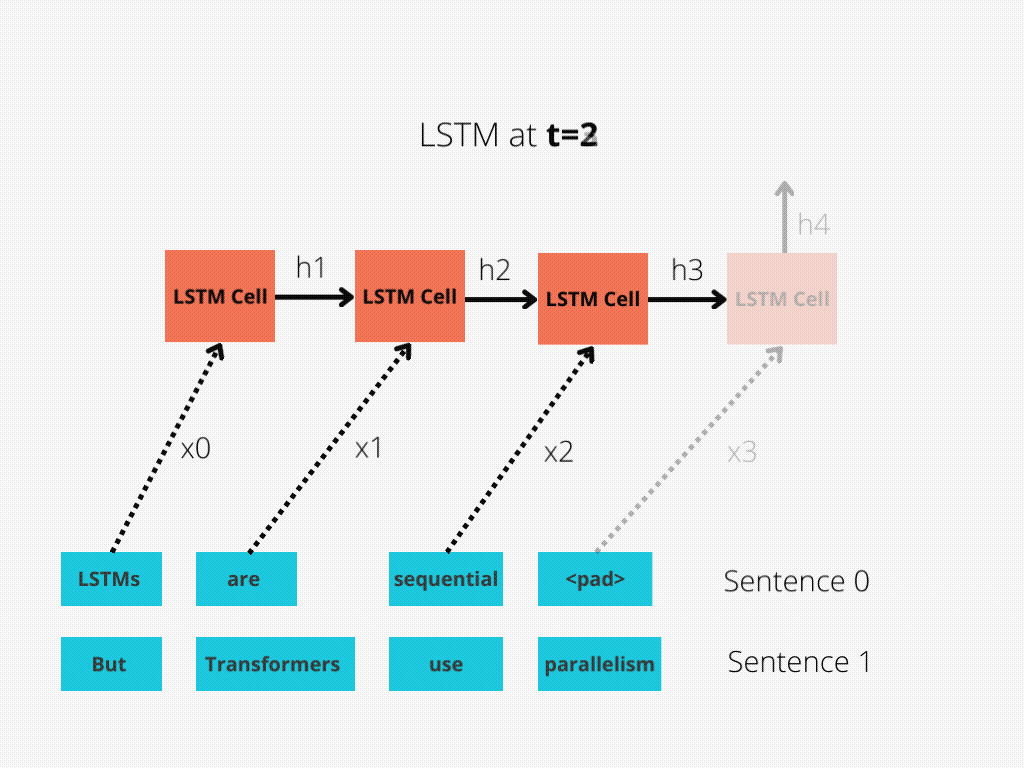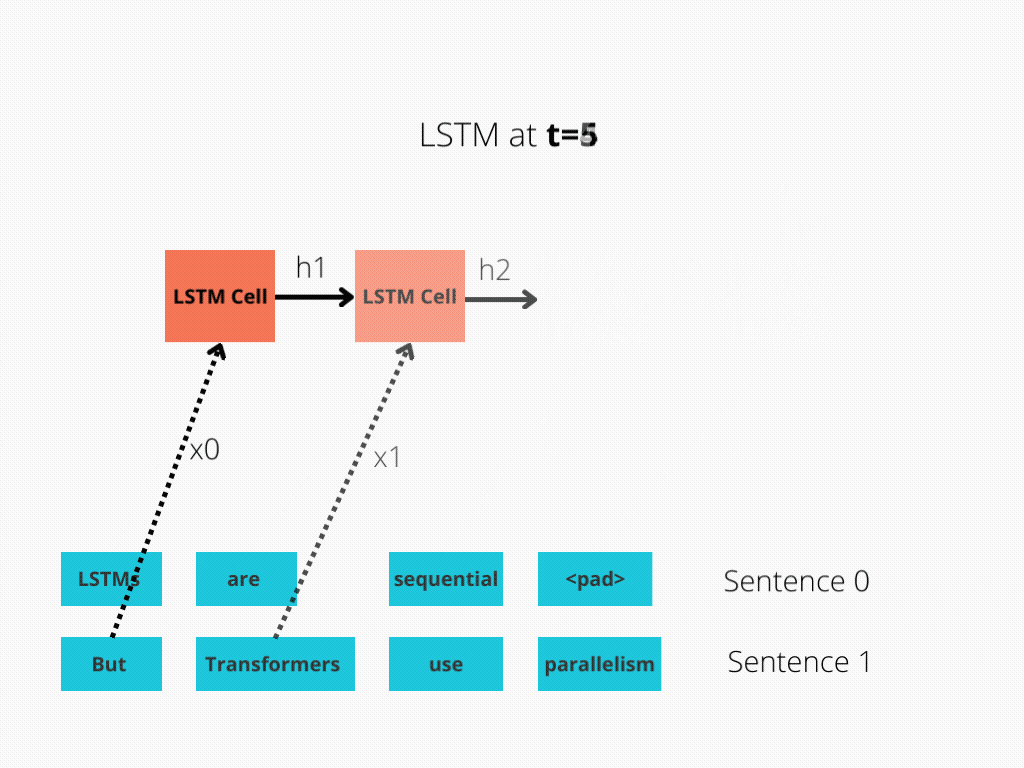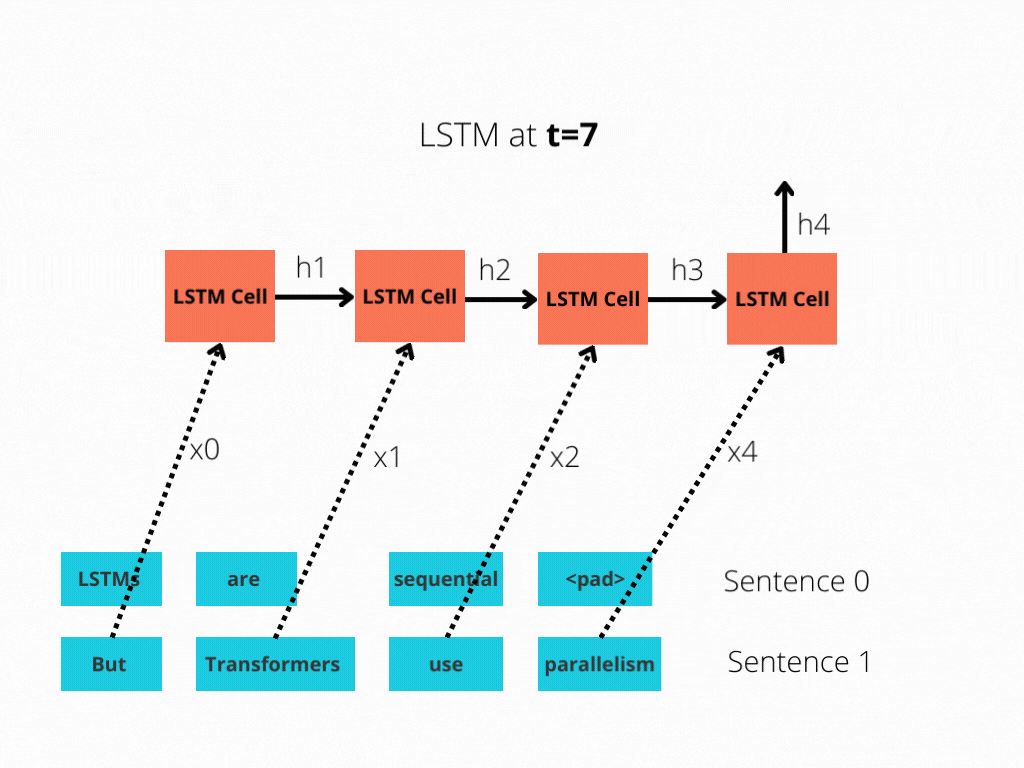
图1:序列长度为4的LSTM单元。
图2:Bert体系结构(简化)
LSTM需要8个时间步来处理句子,而BERT[3]只需要2个时间步!所以BERT能够更好地利用现代GPU加速所提供的并行性。
上面两个插图都经过了简化:假设批大小为1。另外也没有考虑BERT的特殊令牌,比如它需要2个句子等等。
长期记忆
在移动到未来的令牌之前,LSTM被迫将它们学习到的输入序列表示状态向量。虽然LSTMs解决了梯度消失的问题,但他仍然容易发生梯度爆炸。
Transformer有更高的带宽,例如在Encoder-Decoder Transformer[4]模型中,Decoder可以直接处理输入序列中的每个令牌,包括已经解码的令牌。如图3所示:
图3:Transformer中的编码和解码
更好的注意力机制
transformer使用了一种名为Self-Attention的特殊注意力机制:这种机制允许输入中的每个单词引用输入中的每个其他单词。所以可以使用大的注意窗口(例如512,1048)。因此,它们非常有效地捕获了长范围内顺序数据中的上下文信息。
让我们看看Transformer的缺点:
自注意力的计算成本o(n²)
这其实Transformer最大的问题。初始BERT模型的极限为512 令牌。解决此问题的粗爆的方法是直接截断输入句子。为了解决这个问题可以使用surpass的方法,将令牌扩充到到4096。但是关于句子的长度,自注意力的命中成本也是二次的
所以可伸缩性变得非常具有挑战性。这也是为什么后面有许多想法来重组原始的自注意力机制:
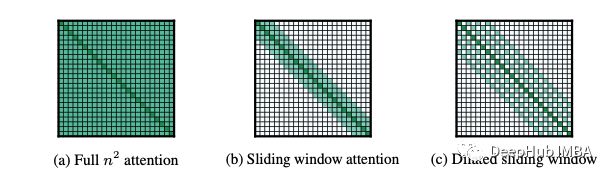
图4:不同类型自注意力的成本矩阵
Longformer[6]和Transformer XL[7]等模型针对长格式文本进行了优化,并取得了显著的改进。
但是挑战仍然存在:我们能否在不牺牲效率的前提下进一步降低计算成本?
时间序列的挑战性
虽然Transformer在NLP领域占了主导地位,但它们在时序数据方面的成功却有限。为什么呢?时间序列不也是连续数据吗?
Transformer可以更好地从长期历史中计算时间步长的输出,而不是当前输入和隐藏状态。这对于本地时态依赖项来说效率较低。总来来说就是短期记忆和长期记忆对时间序列来说同样重要。
这就是为什么谷歌研究人员发布了一个用于时间序列预测的混合深度学习模型[1]:该模型使用了Attention,但也包括一个LSTM编码器-解码器堆栈,它在捕获局部时间依赖性方面发挥了重要作用。
最后,时间序列可以是多元的,不仅包含静态数据,还有季节性,趋势等等。它们通常需要更特殊的处理。
Block-Recurrent Transformer
该模型的主要突破是循环单元:他是一个修改的Transformer层,但是它以循环的方式工作。
让我们快速概述主要特征,然后我们将深入研究模型的体系结构。
- 块级并行性:块中的循环单元的过程令牌和块内的所有令牌都并行处理。
- 大注意力窗口:由于该模型将输入分解为块,因此可以使用很大的注意力窗口(已测试可以达到4096个令牌)。因此,这个模型属于长距离Transformer的家族(例如Longformer)。
- 线性复杂性:由于循环单元打将输入进行了分割,所以模型使用Sliding Self-Attention将注意力计算的时间复杂度减少到了O(n)。
- 更稳定的训练:处理块中的顺序对于在长距离内传播信息和梯度可能很有用,并且不会出现灾难性遗忘问题。
- 信息扩散:块循环在状态向量的块而不是单个向量(例如RNNS)上运行。该模型可以充分利用循环的特征并更好地捕获过去的信息。
- 互操作性:循环单元可以与常规Transformer层连接。
- 模块化:循环单元可以水平堆叠或垂直堆叠,因为循环单元可以以两种模式运行:水平(用于循环)和垂直(用于堆叠层)。。
- 操作成本:添加循环就像添加额外的层一样简单,并且不会引入额外的参数。
- 效率:与其他长距离的Transformer相比,该模型显示出显着改善。
以下两个将详细介绍Block-Recurrent Transformer的两个主要组成部分:循环单元Recurrent Cell 结构和带有循环特性的滑动自注意力Sliding Self-Attention with Recurrence。
循环单元结构
循环单元时该模型的主干。但是不要被其描述为“单元”的特征感到困惑。这其实是一个Transformer层,但是却通过循环的方式调用
循环单元将接收以下类型的输入类型:
- 一组带有块大小令牌嵌入W。
- 一组“当前状态”向量S。
输出是:
- 输出令牌的嵌入W_out。
- 一组“下一个状态”嵌入向量。

图5显示了循环单元结构。该体系结构非常简单,并且重新使用了许多现有的Transformer代码,我们甚至可以更加“简单”的总结就是把LSTMCell替换为Transformer Cell。
下面将逐步解释图5所示的每个组件:
Self-Attention和Cross-Attention
循环单元支持两种类型的操作:自注意力和交叉注意力。更具体地说:
- Self-Attention在相同嵌入(K、V和Q矩阵)中生成的键、值和查询上执行。
- Cross-Attention是从其他嵌入生成的K、V中执行的本身嵌入生成Q进行查询。
回想一下原始的Transformer编码器-解码器模型[4],编码器执行自注意力,而解码器中的“编码器-解码器注意力”层执行交叉注意力。这是因为查询Q来自前一个Decoder层,而K和V来自Encoder输出。循环单元在同一层执行这两种操作。换句话说:
循环单元同时进行自我注意(编码)和交叉注意(解码)!
水平与垂直模式
如图5所示。之前提到的循环单元有两种运作模式:
垂直(堆叠):在这种模式下,模型对输入嵌入执行自注意,对循环状态执行交叉注意。
水平(循环):与垂直相反,模型在循环状态上执行自注意,在输入嵌入上执行交叉注意。
位置偏差
在图5中一个名为Learned State id的方框(浅黄色)。让我们解释一下这是什么,以及为什么需要它。
循环单元之间的状态转移不是单个向量(例如RNN),而是大量状态向量。由于对每个状态向量应用相同的MLP层(一种标准做法),会导致状态向量无法区分。经过几个训练轮次后,它们往往会变得相同。
为了防止这个问题,作者在状态向量中添加了一组额外的可学习的“状态IDS”。作者称这种现象为功能性位置偏差。这类似于位置编码,普通Transformer将其应用于输入嵌入。Block-Recurrent Transformer的作者将这种技术应用于循环状态向量,这就是为什么他们使用一个不同的名称以避免混淆。
位置编码
Block-Recurrent Transformer不会将常规的位置编码应用于输入,因为它们在长序列中不太好。取而代之的是作者使用了T5体系结构中引入的著名技巧[8]:它们在垂直模式下的输入嵌入中添加了位置相对偏置向量。偏置向量是键和查询之间相对距离的学习函数。
门配置
循环单元与其Transformer模型之间的另一个区别是残差连接的使用。
Block Recurrent Transformer的作者尝试了以下配置:
- 用门代替残差连接。(如图5所示)。
- 在 fixed gate和LSTM gate之间进行选择。
作者进行了几项实验以找到最佳配置。有关更多详细信息,请检查原始论文。
带有循环特性的滑动自注意力
Block Recurrent Transformer的注意力机制可以说是革命性的探索,可梳理以下概念:
- 产生的QK^TV矩阵变为“线性化”操作。
- 用O(n)逐步替换O(n²)。
- 可以循环调用。
前两个概念已经在相关工作中被提出[6],[9]。由于它们的发现Attention实现了计算量的缩减,但是会非常长的文档中失去效果。Block Recurrent Transformer将前两种思想与循环结合在一起,这一概念借鉴自传统的RNN。
线性矩阵产生
在Transformer的生态系统中,注意力围绕着3个矩阵:查询Q、键K和值v。
传统的注意力如下图所示:
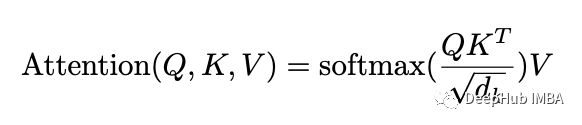
Block-Recurrent Transformer 以不同的方式计算注意力评分:首先删除了softmax操作。然后根据[9]将其重新排列为Q(K^TV)(如图5所示),并以线性化的方式计算。
滑动自注意力
给定长序列的N个令牌s,一个滑动窗口应用了一个因果掩码,因此令牌s只能计入自身和先前的W 令牌。(W是块大小)。
我们可视化注意矩阵如下:
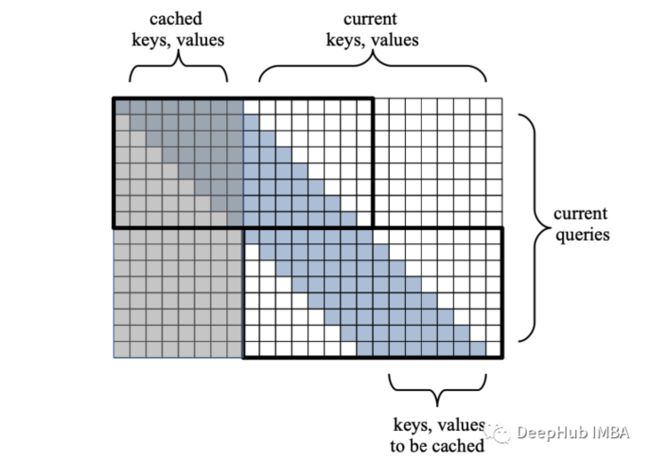
图6:单个训练步骤的优化注意力矩阵。只计算2个黑色图块内部的分数,而不是计算完整矩阵。)
在图6中,一个窗口大小W = 8和序列langth n = 16。在先前的训练步骤中计算并缓存了第一个W遮蔽令牌。其余的N个未遮蔽令牌来自当前输入。
输入序列中的每个令牌都以滑动方式连续地关注上一个W = 8的令牌。因此在每一行中都会有W次计算。矩阵的高度为n(我们句子中的长度)。总成本为o(nw),而不是全部矩阵O(n(w+n))。zheyang 相对于序列n的成本是线性的,而不是二次!
在我们的例子中,Attention被用于两个大小为Wx2W的tile。让我们来分析一下这一连串的事件:
- 在第一个注意步骤中,输入句子的第一个W个令牌将处理前一个句子中最后缓存的W个键和值。
- 在第二个注意步骤中,输入句子的最后W个令牌将关注输入句子的第一个W个令牌。
- 这将结束我们的训练步骤,并将输入句子的最后一个w键和值缓存,以用于下一个训练步骤。
- 这种滑动模式就是为什么我们称这种机制为滑动自我注意。
注意:当我说令牌X关注令牌Y时,我们并不是指令牌本身:我指的是那些各自令牌的K,Q,V!
循环时如何提供帮助的
滑动自注意力(非循环版本)已经在早期论文[6] [7]中使用,不过有一些不同:
- 在以前的版本中,输入的句子没有分块。使用简单的滑动自我注意的模型是一次获取所有的输入。这就限制了他们能够有效处理的信息量。
- 前面训练步骤中使用的缓存k和v是不可微的——这意味着它们在反向传播期间不会更新。然而在循环版本中,滑动窗口有一个额外的优势,因为它可以在多个块上反向传播梯度。
- 原滑动自注意模型最顶层的理论接受域为W*L,其中L为模型层数。在循环版本中,接收域实际上是无限的!这就是为什么在远程内容中表现出色的原因。
实验结果
最后,对Block-Recurrent Transformer进行了测试。
使用的任务是自回归语言建模,目标是在给定一个句子的情况下预测下一个单词。
该模型在3个数据集上进行测试:PG19、arXiv和Github。它们都包含很长的句子。
作者测试了Block-Recurrent Transformer,并使用Transformer XL作为基线。Block-Recurrent Transformer配置为两种模式:
单循环模式:作者使用了一个12层的Transformer,只有循环在第10层。
循环模式:使用相同的模型,只是这一次第10层不只是循环输出给自己:第10层的输出在处理下一个块时广播给所有其他层。因此,层1-9可以交叉处理输入,使模型更强大,但在计算上更昂贵。
这些模型使用perplexity (语言模型的常用度量标准)进行评估。
对于那些不知道的人:perplexity被定义为P=2^L,其中L是常规熵。
直观上讲在语言建模的环境中,可以这样考虑perplexity:如果perplexity的值是30,那么预测句子中的下一个单词就像猜对一个有30面骰子的结果一样不确定。perplexity越低越好。
实验结果表明,Block-Recurrent Transformer在复杂度和速度方面都明显优于Transformer XL。
反馈模式优于单循环模式。但是作者指出,额外的性能提升并不能弥补额外的复杂性。
论文作者还尝试了各种配置,如添加或跳过门。有关更多信息,请查看原始论文[2]。
总结
Block-Recurrent Transformer是一篇突破性的论文,利用传统的RNN递归来增加长文档中的Transformer。
我强烈建议阅读原始论文[2]并使用本文作为辅助来帮助理解。
由于这篇论文很新作者没有发布任何源代码,但是在Github上有一些非官方的实现,有兴趣的可以自行搜索
引用
- Dosovitskiy et al., An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)
- DeLesley Hutchins et al. Block Recurrent Transformers (March 2022)
- Jacob Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (May 2019)
- A. Vaswani et al. Attention Is All You Need (Jun 2017)
- Kyunghyun et al. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
- Iz Beltagy et al. Longformer: The Long-Document Transformer, Allen Institute for Artificial Intelligence (2020)
- Zihang Dai et al. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (2019)
- Colin Raffel et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2019)
- Angelos Katharopoulos et al. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (2020)
https://avoid.overfit.cn/post/b813e4e85ab9457fa9553230109a37ae
作者:Nikos Kafritsas