【机器学习】基于生成对抗网络的黑白图片上色
本文内容
阅读须知:
- 阅读本文需要有一定的机器学习与深度学习知识基础,需要大致了解模型训练的前向传播、后向传播以及训练过程
- 本文大部分为理论讲解;模型及训练、测试代码将以附录形式给出,不在文中呈现
本文将介绍:
- 生成对抗网络基本概念
- 基于生成对抗网络的图片处理统一方案Pix2Pix
- 该方案的特例:黑白图片上色
最终结果
先看最终的模型训练成果,下组图片从左到右分别是真实图片和两个不同生成对抗网络模型由灰度数据生成的图片,两个模型只在生成器部分有所不同:
- 上色结果1:Dynamic U-Net + Res 18( 4 8 t h \rm 48^{th} 48th epoch)
- 上色结果2:Res U-Net( 2 9 t h \rm 29^{th} 29th epoch)
如果此时对这些概念不熟悉并没有关系,本文将重点介绍基于生成对抗网络以及以上两种模型的黑白图片上色方案。
| 真实图片 | 上色结果1 ( 4 8 t h \rm 48^{th} 48th epoch) | 上色结果2 ( 2 9 t h \rm 29^{th} 29th epoch) |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
生成对抗网络
模型简述
道高一尺魔高一丈的“对抗”模型,由生成器G和鉴别器D两个子网络组成。
- 生成器G以“素材”作为输入,输出伪造照片。
- 鉴别器D以“图象”作为输入,输出为判别输入图象真假性(是真实还是捏造)的结果。
对抗原理

上图解释了生成对抗网络的基本原理。生成器G以素材 x x x作为输入,生成捏造的图片 G ( x ) G(x) G(x),而鉴别器D遇到虚假的图片 G ( x ) G(x) G(x),应该输出假(fake);然而,如果鉴别器D遇到真实的输入 y y y,应该输出真(real)。
鉴别器D通过不断比较真实图片与虚假图片的特征从而提高自身的鉴别能力;而生成器G为了更好地生成可以逃避鉴别器D鉴别的图片,也会不断学习特征,期望可以生成更有欺骗性的图片以绕过检测,即相当于两个竞争方通过良性竞争,不断学习从而逐渐变强。
Pix2Pix
生成对抗网络是一个广泛使用的模型,在不同领域可以有不同的模型实现,此处主要一个图像生成相关的通用项目Pix2Pix。该项目的相关文献及源码可从这里获取。
项目简介
在该项目出现之前,所有生成图像的模型的训练方法都是单独、孤立的,而生成图像这一问题事实上只是从一个图像经历某种处理 f ( x ) f(x) f(x)迁移至另一图像罢了。
生成对抗网由深层次的抽象出发,其实就可以胜任这种图像迁移的操作(只要给出对应的输入与预期输出进行训练),因此该项目旨在给出一个借助生成对抗网络解决一切(包括图像生成、上色、修复、风格转移等)问题的统一模型训练方案,这也是Pix2Pix(Pixel to Pixel,从像素到像素)名字的来由。
对抗模型
生成器
生成器顾名思义是生成伪造图片的模型,也是最终产生我们所需结果的模型。
图象生成其中一个隐含子问题是图象分割,鉴于编码-译码网络(U-Net)对局部特征的提取效果较好,因此常用U-Net作为生成器网络。
该网络每个模块都是较常规的卷积神经网络,但它将编码层的输出直接叠加至相应译码层的输出,以此更好地描述局部特征。

鉴别器
由于卷积网络对局部特征比较敏感,因此在一般情况下,任意卷积网络都可作为图像生成问题的鉴别器。
然而,传统的鉴别器只输出一个处于 [ 0 , 1 ] [0, 1] [0,1]的单值,表示整张图片的真假性。但有时生成器也许在图像某区域还原的比较真实,某些区域比较失真,此时如果只评估整个图像的真实度是比较武断的,较好的做法应该是具体位置具体分析。
局部鉴别器
为了解决上述的问题,作者提出了一种“局部鉴别器”,其输出是一个元素值域位于 [ 0 , 1 ] [0, 1] [0,1]的矩阵,每个元素表示图中某个局部区域的真假性。
而除了输出的规模以外,鉴别器模型本身的选择方面则尽量从简,只要是卷积网络就可以。
鉴别器输入
传统的鉴别器只以真实图片或虚假图片作为输入,这种做法可以,但不充分。若给予鉴别器更多的信息:比如在给予图片输入的基础上,同时告诉它生成的“素材”依据(例如对于图片上色而言即灰度数据),应该会使鉴别器的判别标准更加充分合理。
损失函数
损失函数是调整模型权值的依据。
由于没有直接标准,生成器难以与原图直接比较计算出误差,因此对抗网络中生成器与鉴别器最终的误差都是以鉴别器输出作为媒介的。鉴别器处理的是一个判别性的问题,很容易通过交叉熵计算出误差。但是对于生成器的优化,则需要以“欺骗”的角度看待鉴别器的输出。
1. 价值函数
价值函数与误差函数有相似的意义,但前者偏向于理论,后者才是具体能用的实现。因此首先从对抗网络的价值函数入手,由价值函数的定义引出误差函数的计算。
基本定义
设输入为 x x x,标准输出为 y y y,噪音干扰输入为 z z z(若问题不引入噪音,为全0)
则生成器的输出为: G ( x , z ) G(x, z) G(x,z)
鉴别器的输出为: D ( x , y ) D(x, y) D(x,y)和 D ( x , G ( x , z ) ) D(x, G(x, z)) D(x,G(x,z)) (根据上述“鉴别器输入”提及,需要提供 x x x)
则生成对抗网络的价值函数定义为:
L c G A N ( G , D ) = E x , y [ log D ( x , y ) ] + E x , z [ log ( 1 − D ( x , G ( x , z ) ) ) ] L_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log D(x,y)]+\mathbb{E}_{x,z}[\log (1-D(x,G(x,z)))] LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
其中:
- E \mathbb{E} E指数学期望,下同
从D的角度:
前半项:D在遇到真实输入 y y y时, D ( x , y ) D(x,y) D(x,y)应输出1,前半项的结果为0
后半项:D在遇到虚假输入 G ( x , z ) G(x,z) G(x,z)时, D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z))应输出0,因此后半项的结果为0
其中任意一项出现错误,都会使期望倾向负无穷,因此D的目标是最大化上式的值(趋于0)
从G的角度:
后半项:G希望D在遇到自己的虚假输入时,检测失败, D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z))应输出1,因此后半项的结果为 − ∞ -∞ −∞
因此G的目标是最小化上式的值(趋于 − ∞ -∞ −∞)
最终定义
此外,为了更好地引导G往原始输入的方向下降,在价值函数上额外加入距离项:
L L 1 ( G ) = E x , y , z [ ∥ y − G ( x , z ) ∥ 1 ] L_{L1}(G)=\mathbb{E}_{x,y,z}[\left \| y-G(x,z) \right \|_1] LL1(G)=Ex,y,z[∥y−G(x,z)∥1]
因此最终的价值函数为:
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) + λ L L 1 ( G ) G^*=\mathrm{arg}\,\underset{G}{\mathrm{min}}\,\underset{D}{\mathrm{max}}\,L_{cGAN}(G,D) +\lambda L_{L1}(G) G∗=argGminDmaxLcGAN(G,D)+λLL1(G)
虽然价值函数没办法直接作为误差的计算,但相同的思想可以类比至损失函数的设计。
2. 鉴别器的误差
对鉴别器而言,只有 G ∗ G* G∗中的前一项有影响。根据价值函数的思想,可以用以下式子作为D的损失函数:
L o s s D = L o s s B C E ( D ( x , y ) , 1 ) + L o s s B C E ( D ( x , G ( x , z ) ) , 0 ) Loss_D=Loss_{BCE}(D(x,y),1)+Loss_{BCE}(D(x,G(x,z)),0) LossD=LossBCE(D(x,y),1)+LossBCE(D(x,G(x,z)),0)
其中:
- G作为常量输入
- B C E BCE BCE指二进制交叉熵
与价值函数所描述的一样,当遇到正确输出时,标准输出为1;
遇到虚假输出时,标准输出为0,任何的错误都会导致D的误差变大。
3. 生成器的误差
对生成器而言, G ∗ G* G∗的两项都有影响。虽然无法直接表示G在价值函数中的作用,但仍然可以通过价值函数的意义,结合鉴别器的损失函数进行表示:
L o s s G = L o s s B C E ( D ( x , G ( x , z ) ) , 1 ) + λ L o s s L 1 ( y , G ( x , z ) ) Loss_G=Loss_{BCE}(D(x,G(x,z)),1)+\lambda Loss_{L1}(y,G(x,z)) LossG=LossBCE(D(x,G(x,z)),1)+λLossL1(y,G(x,z))
其中:
- G与D均作为变量输入
- B C E BCE BCE指二进制交叉熵
- L 1 L1 L1指最小绝对偏差
- λ \lambda λ按经验法则取100
第一项与鉴别器误差的第二项非常相似,但它的标准输出变为1。意味着G希望D在遇到自身时,把虚假输出误判为正确,这也就体现了价值函数中G的根本目的;
而第二项,则是上面提到的 L 1 L1 L1引导项,此处不多赘述。
黑白图片上色
黑白图片上色是Pix2Pix中的其中一个用途,可以使用Pix2Pix直接训练。但本文将其看作一个特例,只保留其生成对抗网络的主要思路,且对输入输出进行改动,以训练更直接、更具针对性的生成对抗网络模型。
输入输出
不同的色彩空间以不同的方式记录图像,输入输出的选择其实就是色彩空间的选择。
RGB色彩空间
我们所熟知的RGB颜色空间是使用R(红)、G(绿)、B(蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色。
但由于RGB三条都是色彩通道,这导致要用三条颜色通道表示输入的灰度图像,且输出三条色彩通道作为最终的输出。
Lab色彩空间
Lab色彩空间则是由亮度通道(L)与两个颜色通道(a:红-绿; b:黄-蓝)组成的另一种色彩表示法。

与RGB颜色空间相比:Lab颜色空间的色域更加宽阔,它能表示出前者无法表现的色彩。
更重要的是,Lab在模型运算时更直接、简便:图像上色是由灰度数据到彩色数据的过程。在Lab色彩空间中,亮度通道L就是灰度数据,这意味着L通道数据可直接用于模型训练输入;且只需要学习生成ab两个代表彩色数据的通道。
而RGB色彩空间的做法则需要生成灰度图像(3通道)作为输入;彩色图象(3通道)作为输出。
因此使用Lab色彩空间进行训练。
数据处理
主要为创建自定义数据集:
- 读入RGB图象
- 将RGB图象转换为LAB
- 将通道数据归一化至 [ − 1 , 1 ] [-1,1] [−1,1]
- 将L通道输出为“输入(input)”
- 将AB通道输出为“标准输出(correct output)”
模型构建
生成器
上章节提到,计算机视觉中常用U-Net作为生成器。但U-Net存在几个训练上的问题,为了使训练结果更加准确,此处使用的是U-Net的一个变形:残差U型网(Residual U-Net),相比传统U-Net,它的优势有:
- 模型占用空间小
- 模型复杂度更低
- 可缓解梯度消失
这意味着残差U型网更加容易收敛,且占用更少的空间。
实现1:残差U型网
残差U型网的直接实现如下图所示。它的结构在U-Net的基础上,还将每个卷积块换成了“残差块”,即每块的输入直接叠加至该块的卷积结果一并作为输出:

实现2:动态U型网+残差网络
一种更灵活地将U型网与残差网络融合于一体的方式便是使用动态U型网(Dynamic U-Net)。它是一个通用的U型网络,它允许使用任意一个卷积网络作为编码层,此处使用的是Res18;但它的译码层是固定的亚像素卷积网络(Pixel Shuffle)
输入输出
由于使用Lab色彩空间,生成器以L通道作为输入,ab通道作为输出。
鉴别器
实现
上章节提到,鉴别器的选择方面尽量从简,只要是卷积网络就可以,因此使用比较普通的做法:
| 模块 | 次数 | 结构 |
|---|---|---|
| 输入模块 | 1 | 4 ∗ 4 C o n v ( F i l t e r s = 64 , S t r i d e 2 ) → L e c k y r e L U \mathrm{4*4\, Conv(Filters=64,\,Stride 2) \to Lecky\,reLU} 4∗4Conv(Filters=64,Stride2)→LeckyreLU |
| 中间模块 | 3 | 4 ∗ 4 C o n v ( F i l t e r s ∗ = 2 ) → B a t c h N o r m → L e c k y r e L U \mathrm{4*4\, Conv(Filters*=2) \to Batch Norm \to Lecky\,reLU} 4∗4Conv(Filters∗=2)→BatchNorm→LeckyreLU |
| 输出模块 | 1 | 4 x 4 C o n v ( F i l t e r s = 1 ) \mathrm{4x4\, Conv(Filters=1)} 4x4Conv(Filters=1) |
输入输出
出于上文“鉴别器输入”考虑,鉴别器将以灰度数据L、色彩数据ab同时作为输入。某种意义上鉴别器的输入保持为完整的3通道Lab图片。而输出则是一个代表局部真假的 [ 0 , 1 ] [0,1] [0,1]矩阵
模型训练
将使用Pytorch进行训练,该节所提及的所有技术都是可在Pytorch中实现的。
1. 损失函数
在Pytorch中使用到的误差函数:
- BCEWithLogitsLoss(带Sigmoid优化的二进制交叉熵)
- L1Loss(平均绝对偏差)
2. 优化器
- 较常用的Adam优化器
3. 梯度计算
按上文 “损失函数” 部分的误差定义,分别以 L o s s G Loss_G LossG和 L o s s D Loss_D LossD进行误差计算,但不输入噪音 z z z。
需要注意,在优化D时需要锁定G的权值,即G应以常量作为输入。
模型校验
并没有太好的办法可以用于该问题,因为:
-
校验误差无效
a) 这是无定解问题,不能奢望模型毫无差错地还原色彩
b) 从误差函数不难看出,G和D的误差是相对的,因此无法直观从误差看出实际效果
备注:也曾尝试过使用校验误差,它确实如a)所述,是发散的。 -
图象对比度等参数也难以说明事实
a) 生成图与原图或许颜色、甚至风格都不同,但这并不代表图像不好看。这种情况下,按照图象参数计算的误差会非常大,但是“观感”误差却很小(如下图所示)
| 真实图片 | 生成图片 |
|---|---|
 |
 |
因此最后使用了肉眼校验的做法:
- 结果本身就是给人看的
- 人的审美目前还是机器所不能比拟的
- (鉴别器)过拟合在输出图片上的表示就是黑白,没有颜色,容易判断
但这也意味着模型校验并不能起不到太多的作用,这种做法基本无法进行超参数的调节(除了学习率这种简单的),唯一较大的作用就是评估模型是否过拟合(观察到校验图象在连续几个epoch输出异常,特别是颜色暗淡),然后执行早停止了。
训练结果
训练参数
| 参数名称 | 参数值 |
|---|---|
| 学习率 | 均为2e-4 |
| 数据集 | COCO 2017 |
| 图象规模 | 10万张,256*256 |
| 批处理大小 | 16 |
| Adam Beta1 | 0.5 |
| Adam Beta2 | 0.999 |
| λ(平均绝对误差的权重) | 100 |
| epochs | 40 (Res-Unet) ; 50 (Dynamic Unet+Res18) |
耗时
| 使用的生成器 | 时间(小时) | epochs |
|---|---|---|
| 残差U型网(Res-Unet) | 47 | 40 |
| 动态U型网+残差网(Dynamic Unet+Res18) | 40 | 50 |
训练误差
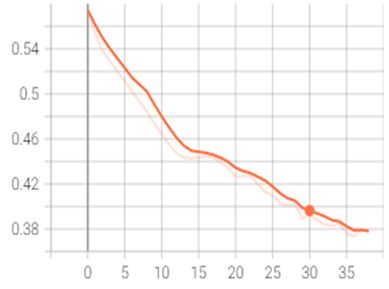
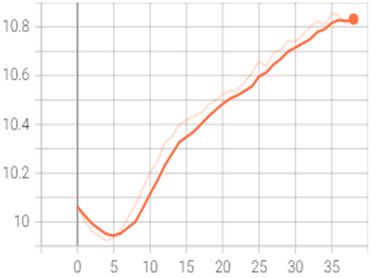
残差U型网(Res-Unet)
| 鉴别器误差 | 生成器误差 |
|---|---|
 |
 |
动态U型网+残差网(Dynamic Unet+Res18)
| 鉴别器误差 | 生成器误差 |
|---|---|
 |
 |
由于生成器和鉴别器是对抗关系,所以大部分时候两者误差的单调性是相反的。
因为同时存在两个子模型,所以其实单纯看误差并不能得出太多直观的信息,但根据训练经验可以从中归纳出两个现象:
- 生成器误差下降往往是好事
- 相反的,如果鉴别器误差下降太快,特别是收敛至0,生成器往往输出暗淡的图片
结果展示
以肉眼找出了两个生成器模型表现(大概是)最好的epoch
优秀的结果已经在文章开头部分给出,此处只展示差强人意的结果。
与开头的展示顺序一样,除原图外,两个结果只在生成器上有区别,分别为:
- 上色结果1:Dynamic U-Net + Res 18( 4 8 t h \rm 48^{th} 48th epoch)
- 上色结果2:Res U-Net( 2 9 t h \rm 29^{th} 29th epoch)
| 真实图片 | 上色结果1 ( 4 8 t h \rm 48^{th} 48th epoch) | 上色结果2 ( 2 9 t h \rm 29^{th} 29th epoch) |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
不足之处
1. 难控制收敛速度
在模型训练中,我们最希望两个模块分别缓慢收敛。但结果往往是一个误差减少,另一个误差变大。
之前也提及过,在G呈下降趋势时结果往往比较好。而Res U-Net的训练中,G是呈上升趋势的(所以虽然训练了40epoch,但最后只取了第29的结果)。其间也尝试过抑制D的学习率,从而间接让G的误差下降。
于是把D的学习率降低了一半,结果发现不仅没有抑制D的学习速度,反而是让D收敛的更快了,而G的误差也随之上升的更快了……
2. 肉眼校验差强人意
虽然无可奈何使用了人为鉴别,但其实我也不太认同这种做法。其实还有一个想法,不过由于时间和水平的关系没有纳入考虑范围。
前面也提及到,使用U-Net的原因是因为:上色问题中其中一个子问题是图像分割——因为必须先把图象按物体分块,才能正确对各块物体上色。这就引出了一个有固定解的图像分割问题。
换言之,我们也许无法对最终的上色进行评估,但是有机会对其中的图像分割子问题进行校验。COCO数据集本身也带有图象分割的标准输出,因此标准输出也不会成为问题。
但是最大的问题是……怎么从生成器输出切实提取其中暗含的分割信息呢?毕竟它最终的输出只有2条颜色通道。难道要另外训练一个色彩分割的模型进行识别吗?那这岂不是变成三元对抗问题了?
网上也没有这种想法的相关信息(可能有些论文但没有翻到),于是决定暂时搁置,以后有机会再具体考虑。
资源
所有资源均在Kaggle Notebook中
源代码
训练代码
可从Image colorization using GAN(Version 21)获取训练过程的完整代码。
生成器
- Res U-Net:位于ResUnet块下
- Dynamic U-Net+Res Net 18:位于模型训练块下的注释部分
鉴别器
- 位于Discriminator块下
测试代码
可从GAN Colorization Test (Newest Version)获取测试使用的代码。
测试参数
- 改变seed以改变输出的图片
- Best epoch指定两个模型分别的生成器版本
- Res U-Net: 提供1~40 epochs
- Dynamic U-Net + Res Net 18: 提供21~50 epochs
数据集
上面两个Notebook已加入COCO 2017数据集,
可以直接在kaggle使用数据集进行训练或测试。
若实在需要下载该数据集,可以访问这个链接
预训练模型
测试用模型
测试代码中已包含预训练模型作为输入,其中:
Res-Unet: 提供1~40epoch的生成器模型。
Dynamic Unet + Res Net 18: 提供21~50epoch的生成器模型。
直接运行测试代码就可以使用测试模型。
若实在需要下载模型,可以在下面这两个链接下载:
GAN colorization ResUnet model
GAN colorization DynUnet+Res18 model
训练用模型
Res U-Net
训练代码中已包含Res U-Net的预训练模型作为输入,其中:
命名中带netG是生成器。
命名中带netD是鉴别器。
命名中带opt的是对应的优化器。
如果需要继续训练模型,需要同时载入权值和优化器。
如果实在需要下载模型,可以在Data->Output中找到模型下载。
如果需要下载较前epochs的模型,可以在Notebook找到Version,切换前面版本下载。
Dynamic Unet + Res Net 18
这个实现的模型位于另一个Branch,地址如下:
Image colorization using GAN 011d48(Version 13)
其余说明同上。
更多结果
在测试代码中可以看到结果
拷贝该Notebook后,更改其中的Seed参数或者ImageCount可以查看更多结果
在Data->Output中可以下载到输出的图包(output.zip)
参考文献
[1] Isola P , Zhu J Y , Zhou T , et al. Image-to-Image Translation with Conditional Adversarial Networks. 2017.
[2] Ronneberger O , Fischer P , Brox T . U-Net: Convolutional Networks for Biomedical Image Segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer International Publishing, 2015.
[3] Zhang Z , Liu Q , Wang Y . Road Extraction by Deep Residual U-Net[J]. IEEE Geoscience and Remote Sensing Letters, 2017, PP(99):1-5.