论文笔记(十一)【yolov4】详细解析 YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOV4结构解析
- 1,YOLOV4改进的部分(不完全)
- 2、主干特征提取网络Backbone
- 3、特征金字塔
- 4、YoloHead利用获得到的特征进行预测
- 5,补充
-
- 5.1 yolov4可视化结构(很长)
- 5.2 yolov3结构何yolov4结构对比
- 5.4 yolov4 思维导图
- 5.3 Mish:一个新的state of the art的激活函数,ReLU的继任者
- 5.4 SPP
- 5.5 CSPNet
参考:
睿智的目标检测29——Keras搭建YoloV4目标检测平台
Mish:一个新的state of the art的激活函数,ReLU的继任者
目标检测面试指南之YOLOv4
1,YOLOV4改进的部分(不完全)
1)、主干特征提取网络:DarkNet53 => CSPDarkNet53
2)、特征金字塔:SPP,PAN
3)、分类回归层:YOLOv3(未改变)
4)、训练用到的小技巧:Mosaic数据增强、Label Smoothing平滑、CIOU、学习率余弦退火衰减
5)、激活函数:使用Mish激活函数
以上并非全部的改进部分,还存在一些其它的改进,由于YOLOV4使用的改进实在太多了,很难完全实现与列出来,这里只列出来了一些我比较感兴趣,而且非常有效的改进。
YOLOv4 = CSPDarkNet53 + SPP + path-aggregation neck (PANet) + YOLOv3-head
还有一个重要的事情:
论文中提到的SAM,作者自己的源码也没有使用。
还有其它很多的tricks,不是所有的tricks都有提升,我也没法实现全部的tricks。
整篇BLOG会结合YOLOV3与YOLOV4的差别进行解析
2、主干特征提取网络Backbone
当输入是416x416时,特征结构如下:
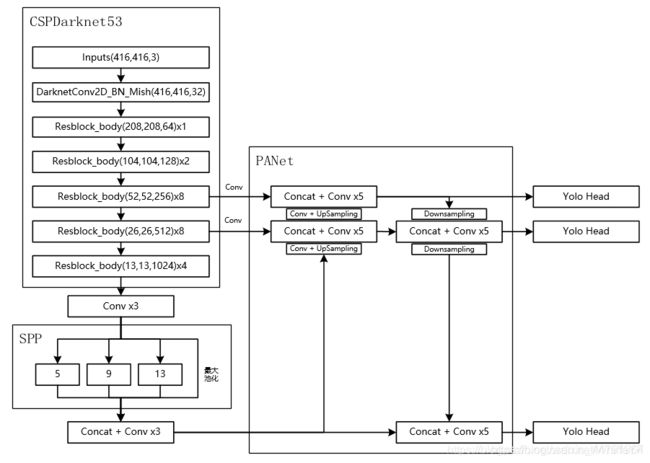
当输入是608x608时,特征结构如下:
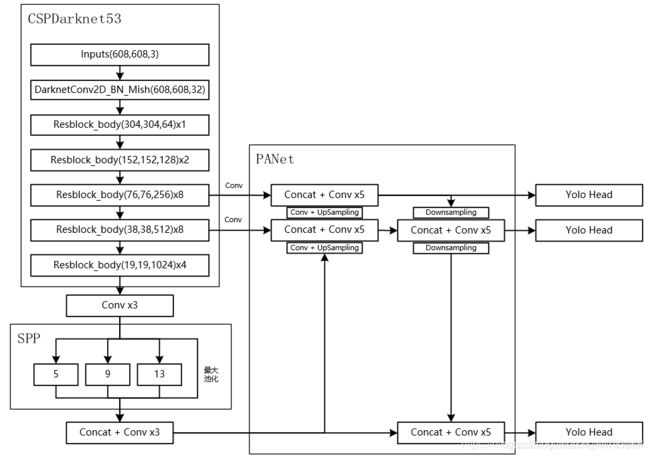
主干特征提取网络Backbone的改进点有两个:
a).主干特征提取网络:DarkNet53 => CSPDarkNet53
b).激活函数:使用Mish激活函数
如果大家对YOLOV3比较熟悉的话,应该知道Darknet53的结构,其由一系列残差网络结构构成。在Darknet53中,其存在resblock_body模块,其由一次下采样和多次残差结构的堆叠构成,Darknet53便是由resblock_body模块组合而成。
而在YOLOV4中,其对该部分进行了一定的修改。
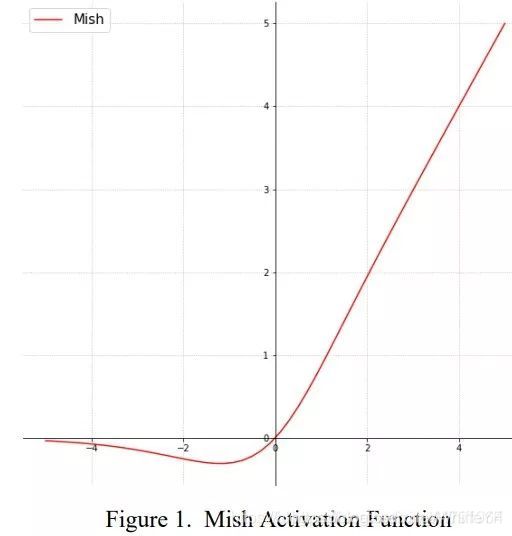
1、其一是将DarknetConv2D的激活函数由LeakyReLU修改成了Mish,卷积块由DarknetConv2D_BN_Leaky变成了DarknetConv2D_BN_Mish。
Mish函数的公式与图像如下:
M i s h = x × t a n h ( l n ( 1 + e x ) ) Mish=x×tanh(ln(1+e^x)) Mish=x×tanh(ln(1+ex))
2、其二是将resblock_body的结构进行修改,使用了CSPnet结构。此时YOLOV4当中的Darknet53被修改成了CSPDarknet53。
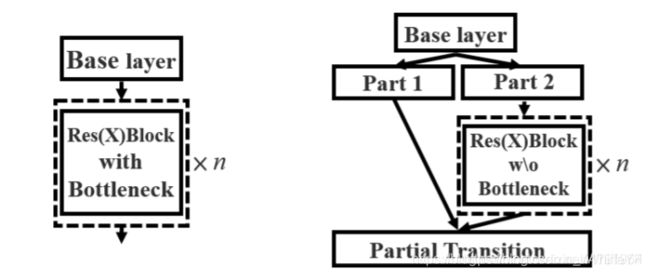
CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:
1)主干部分继续进行原来的残差块的堆叠;
2)另一部分则像一个残差边一样,经过少量处理直接连接到最后。
因此可以认为CSP中存在一个大的残差边。
3、特征金字塔
在特征金字塔部分,YOLOV4结合了两种改进:
a).使用了SPP结构。
b).使用了PANet结构。
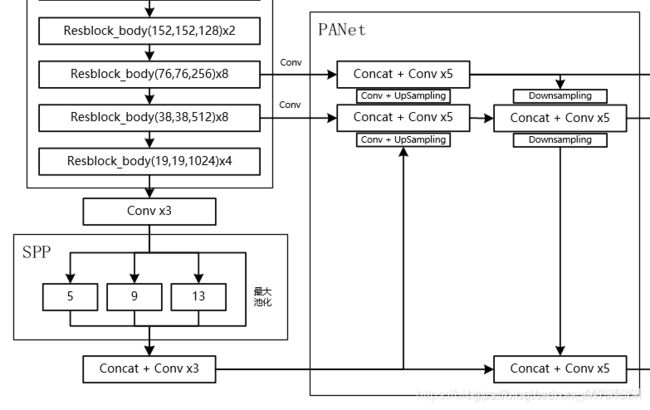
在yolov4结构中,除去CSPDarknet53和Yolo Head的结构外,都是特征金字塔的结构。
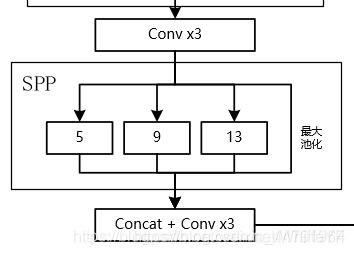
1、SPP结构参杂在对CSPdarknet53的最后一个特征层的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)
其可以它能够极大地增加感受野,分离出最显著的上下文特征。
2、PANet是2018的一种实例分割算法,其具体结构由反复提升特征的意思。

上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取。
在(a)里面是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。
而在YOLOV4当中,其主要是在三个有效特征层上使用了PANet结构。
4、YoloHead利用获得到的特征进行预测
1、在特征利用部分,YoloV4提取多特征层进行目标检测,一共提取三个特征层,分别位于中间层,中下层,底层,三个特征层的shape分别为(76,76,256)、(38,38,512)、(19,19,1024)。
2、输出层的shape分别为(19,19,75),(38,38,75),(76,76,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,YoloV4只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(19,19,255),(38,38,255),(76,76,255)
5,补充
5.1 yolov4可视化结构(很长)
5.2 yolov3结构何yolov4结构对比
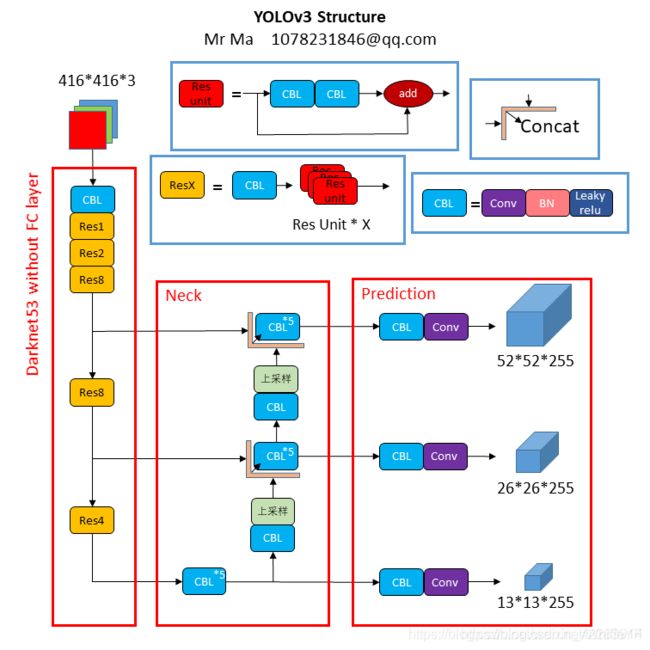
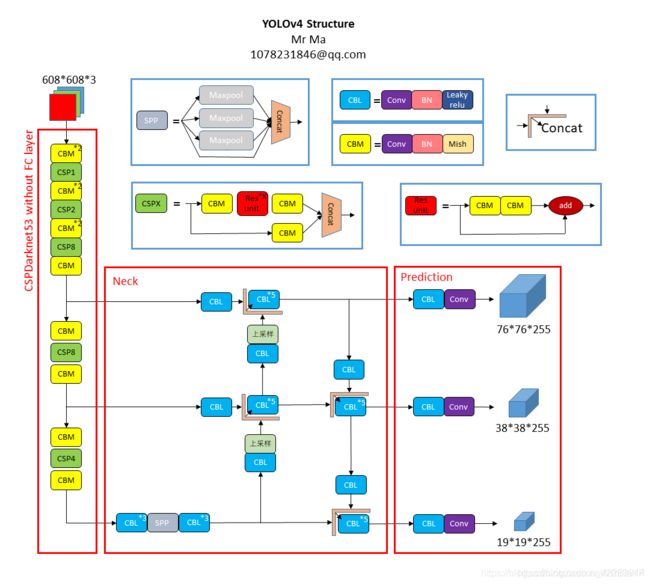
5.4 yolov4 思维导图

5.3 Mish:一个新的state of the art的激活函数,ReLU的继任者
对激活函数的研究一直没有停止过,ReLU还是统治着深度学习的激活函数,不过,这种情况有可能会被Mish改变。
Diganta Misra的一篇题为“Mish: A Self Regularized Non-Monotonic Neural Activation Function”的新论文介绍了一个新的深度学习激活函数,该函数在最终准确度上比Swish(+.494%)和ReLU(+ 1.671%)都有提高。
5.4 SPP
在下面这篇博客已经解释了:
论文笔记(九)【论文中概念解释】1x1卷积核的作用、机器学习中的正负样本、消融实验、ROIpooling、空间金字塔池化(Spatial Pyramid Pooling, SPP)、backbone
5.5 CSPNet
在下面这篇博客已经解释了:
论文笔记(十二)【CSPNet】CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN