手把手搭建经典神经网络系列(2)——VggNet
一、VggNet简介
2014年,牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。
VGGNet探索了卷积神经网络的深度与其性能直接的关系,通过反复堆叠 3*3 的小型卷积核和 2*2 的最大池化层,VGGNet成功的构筑了16~19层深的卷积神经网络。
VggNet 可以看成是加深版本的AlexNet,都由卷积层,全连接层两大部分构成。VggNet探索了卷积神经网络的深度与其性能之间的关系。成功的构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能(但从后来神经网络的发展看来,一味的加深神经网络的深度,并不一定可以得到最优的效果。可能会伴随过拟合,训练时间过长等问题的出现),使错误率大幅下降。
- 论文地址:1409.1556.pdf (arxiv.org)
- 本文代码地址:链接:https://pan.baidu.com/s/1iARC6yFSt94rU34xlUkH1Q 提取码:wr2t
这里十分建议大家有时间的条件下,去自己阅读原文,可能会给您带来不一样的感悟!如果读者需要数据集可以去该系列第一篇文章AlexNet下寻找。
VggNet网络结构
其实作者在论文中设计了多级别的网络结构(6个级别),但究其本质核心思想大致相同。VggNet 中全部使用了 3*3 的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。
下图为VggNet各级别的网络结构图(训练时,输入是大小为224*224的RGB图像):
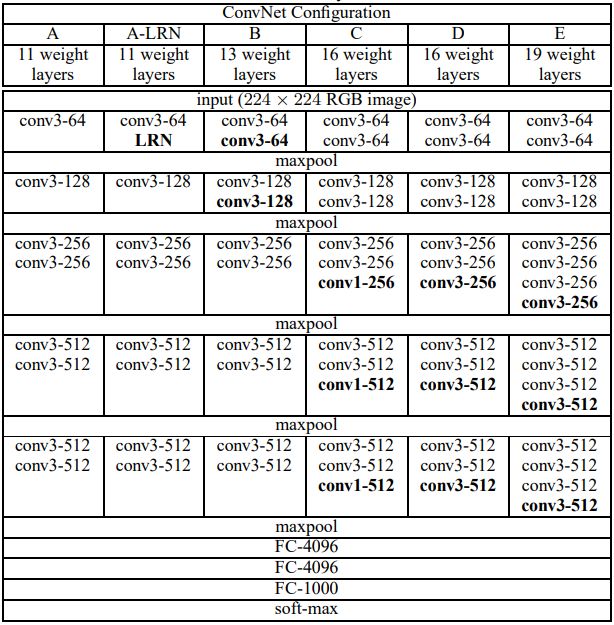
在论文作者中分别使用了A, A-LRN,B, C, D, E这六种网络结构进行测试,这六种网络结构相似,都有5层卷积层,3层全连接层组成,其中区别在于每个卷积层的子层数量不同,从A到E依次增加(子层数量从1到4),总的网络深度从11层到19层(添加的层以粗体显示),表格中的卷积层参数表示为“conv(感受野大小)-通道数”,例如 con3-128,表示使用3*3的卷积核,通道数为128。
虽然从A到E每一级网络逐渐变深,但是网络的参数量并没有增长很多,这是因为参数量主要都消耗在最后3个全连接层。前面的卷积部分虽然很深,但是消耗的参数量不大,不过训练比较耗时的部分依然是卷积,因其计算量比较大。这其中的D,E也即是我们常说的 VGGNet-16和 VGGNet-19。
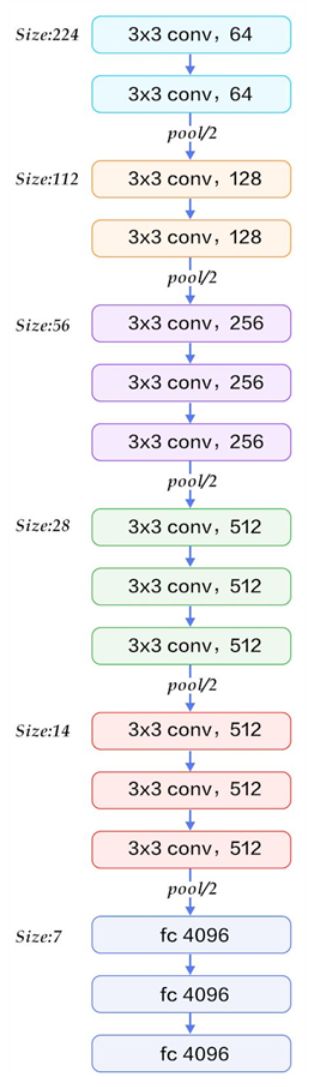
网络结构详解——这里以最为经典的VggNet16(D级别)为例,其立体结构如下:

详解如下:
- 1、输入224x224x3的图片(resize操作),经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
- 2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
- 3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
- 4、作2x2的max pooling池化,尺寸变为56x56x128
- 5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
- 6、作2x2的max pooling池化,尺寸变为28x28x256
- 7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
- 8、作2x2的max pooling池化,尺寸变为14x14x512
- 9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
- 10、作2x2的max pooling池化,尺寸变为7x7x512
- 11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
- 12、通过softmax输出1000个预测结果
逐层网络结构图:
VggNet的创新点
1、小卷积核:
- 首先是两个3x3卷积核可以替代一个5x5卷积核,三个3x3卷积核可以替代一个7x7卷积核。(这一点与AlexNet的区别特别很大,熟悉AlexNet同学都知道,AlexNet网络中充斥着大量的11*11,5*5的卷积核)
- 作用是:
- 减少参数量以及计算量
- 增加激活函数以增加网络的非线性
- 其次是增加了1x1卷积层,作用是:
- 通道之间的特征融合
- 增加激活函数以增加网络的非线性表达能力。
2、小池化核:
- 2x2池化核代替3x3池化核,相比平均池化,max-pooling更能捕捉图像的变化。
VggNet网络结构具有如下特点:
1、结构简单
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大池化)分开,所有隐层的激活单元都采用ReLU函数
2、小卷积核和多卷积子层
Vgg使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数(而且保持了相同的感受野),另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
小卷积核是Vgg的一个重要特点,虽然Vgg是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
3、小池化核
相比AlexNet的3x3的池化核,Vgg全部采用2x2的池化核。
4、通道数多
Vgg网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
5、层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
二、VggNet代码实现
特别说明:笔者以下代码都是基于Pytorch实现的,如若需要其他框架下的代码,可以私聊笔者,笔者无偿提供。
mode.py
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model在model.y文件中,搭建了VggNet的网络结构。代码语义可以查看注释,如有疑问欢迎留言!
train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "./")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 15 #根据自己的电脑进行设置即可,笔者电脑太菜
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 25
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()权重训练文件,本实验选取了较为经典入门的花类识别,同时方便与上一节的AlexNet网络的识别效果进行对比。
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./1.png"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = vgg(model_name="vgg16", num_classes=5).to(device)
# load model weights
weights_path = "./vgg16Net.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()预测函数,用于对图片的识别。
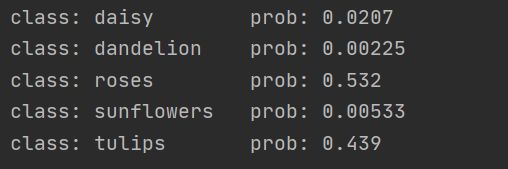
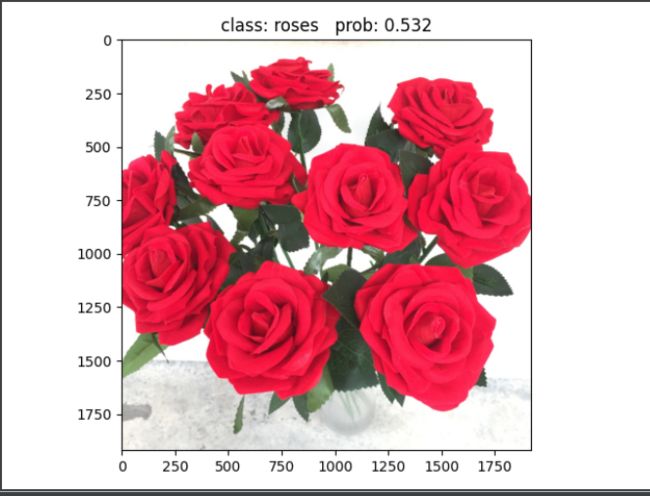
预测结果:
总结:
VggNet的提出带领图像识别技术的进一步发展,其通过增加深度能有效地提升性能给予后来者众多启发;
同时,由于Vgg的极简优势助其有用可以在GPU上进行快速运算。后来于深度学习部署中引入了RepVGG,其单路架构省内存与易剪枝等优势,让其在部署领域大放异彩。这一切都离不开VggNet的出现!!!