基于LSTM、KNN等模型的平安银行股价预测对比研究(python)
摘要:
股票市场易受到诸多不确定性因素的影响,因此股价预测问题挑战巨大,自提出以来就是数字金融中的热门研究领域。传统简单的K线、十字线法操作简单,但预测准确率难以令人满意。随着该研究领域的不断深入,各种模型方法层出不穷。为比较各类模型的性能,本文选取了四种代表模型,线性模型中的移动平均、线性回归,传统机器学习模型KNN,深度学习模型LSTM,分别使用四种模型对深股平安银行的股价进行拟合预测。综合对比发现,深度网络以其独有的优势在高噪声、波动大、非线性的金融时序数据上表现出色,深度学习为股价的预测提供了新的思路。最后本文使用LSTM模型对平安银行未来30个工作日的股价走势进行预测并对投资者提出相关建议。
一、数据来源及预处理
1.1 数据来源
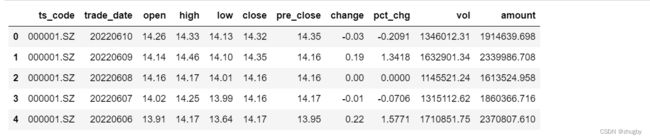
本文使用的数据集为2012年12月31日至2022年6月10日的深交个股平安银行的日线历史行情数据,共2290条。通过调用数据接口从tushare pro平台上获取,tushare是一个python的金融数据接口包,当前开源免费,帮助数据分析师在数据获取上减轻了很多压力。主要由上交所、深交所、腾讯财经、新浪、凤凰财经等向tushare提供的一些股票证券方面的数据,其中包括历史数据、实时数据、分类数据、基本面数据、宏观经济数据、网络舆情、新闻事件数据等等,为金融市场的数据分析和金融产品的开发提供了很好的工具。本文的数据就是由深圳交易所提供,真实可靠。数据集中共有股票代码(ts_code)、交易日期(trade_date)、开盘价(open)、最高价(high)、最低价(low)、收盘价(close)、昨收价(pre_close)、涨跌额(change)等11种变量。如图一所示:

1.2数据预处理
本文中数据预处理的工作主要包括检查数据中是否存在缺失值,将字符型的日期转换成Datatime日期型。因数据集较为干净整洁,减少了大量预处理工作。
代码实现:
import tushare as ts
token='******' #此处写自己的api接口token
pro = ts.pro_api(token)
#平安银行股票数据下载
df = pro.daily(ts_code='000001.SZ', start_date='20121231', end_date='20220612')
df.to_csv('平安银行历史行情1.csv')#import packages
import pandas as pd
import numpy as np
#to plot within notebook
import matplotlib.pyplot as plt
%matplotlib inline
#setting figure size
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20,10
#for normalizing data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
#read the file
df = pd.read_csv('平安银行历史行情1.csv',index_col=0)
#print the head
df.head()otput:
#定义将int类型日期转换成dataframe类型
def string_to_date(string: str) -> str:
"""字符串转日期格式"""
from datetime import datetime
shift_datetime = datetime.strptime(string, '%Y%m%d') # 字符串 -> 时间
shift_date = shift_datetime.strftime("%Y-%m-%d") # 时间 -> 任意时间格式
return shift_date
def convert_date_from_int(time_series: pd.Series):
"""整形的series -> pandas时间格式"""
time_series = time_series.astype('str').apply(string_to_date)
return pd.to_datetime(time_series)output:

二、特征选取及数据划分
2.1 特征选取
简单分析各变量代表意义,股票的开票价和收盘价代表某一天该股的起始价和最终价;最高价、最低价表示某一天股票成交最高价和最低价;涨跌额和涨跌幅是相对于前一天相比该股收盘价的变动额和变动幅度;成交量代表该天交易的股票总数;成交额代表某公司该天的营业额。数据中记录的是工作日股票交易数据,因此会存在一些日期的缺失,不需要额外进行填充处理,处理后反而会影响预测结果。一般来说,股票的涨跌损益是由收盘价来决定的,因此股票预测的目标变量是收盘价。我们分析的是金融时序数据,因此自变量是时间。
首先观察收盘价的趋势图:
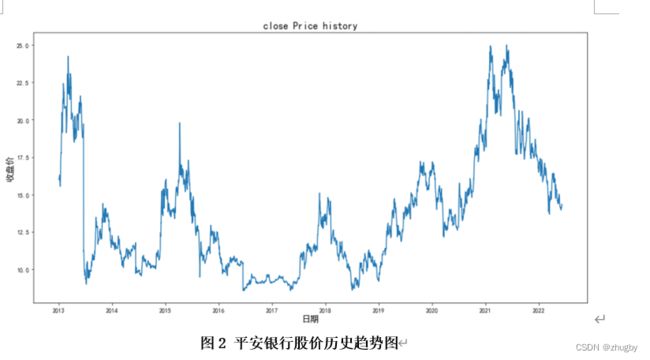
代码实现:
df['trade_date']= convert_date_from_int(df['trade_date'])
df.index = df['trade_date']
#setting index as date
#plot
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(16,8))
plt.plot(df['close'], label='close price history')
plt.title('close Price history',fontsize=16)
plt.xlabel('日期',fontsize=14)
plt.ylabel('收盘价',fontsize=14)2.2 划分训练测试集
时间序列数据的预测需要划分训练测试集,本文中将2012-12-31至2021-12-31日十年的数据作为训练集,将2022-01-04至2022-06-10的数据作为测试集。如下图所示:
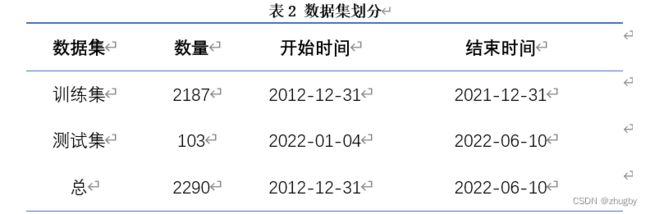
代码实现:
#creating dataframe with date and the target variable
data = df.sort_index(ascending=True, axis=0)
new_data = df[['trade_date', 'close']].sort_index(ascending=True, axis=0)
new_data.head()
#splitting into train and validation
valid = new_data[2187:]
train = new_data[:2187]
观察测试训练集大小和起始时间:
new_data.shape, train.shape, valid.shapeoutput:

train['trade_date'].min(), train['trade_date'].max(), valid['trade_date'].min(), valid['trade_date'].max()output:

三、模型及求解
3.1 LSTM模型
LSTM模型于1997年由Hochreiter & Schmidhuber [1]提出,是RNN的一种变体,全称Long short-Term Memory,即长短时记忆人工神经网络模型[2]。顾名思义,它是一个具有长短期信息存储能力的神经网络。经过多年的发展,加上深度学习热潮掀起之后学者们的不断改善,当前LSTM网络已经形成了较为系统完善的架构,并且广泛应用于多个领域。
循环神经网络(RNN)、BP神经网络都会面临当网络层加深之后反向传播产生梯度消失或梯度爆炸的问题,难以表示长期依赖关系。为了解决这种长期依赖问题,LSTM在传统RNN的基础上引入了门控单元(gate)来控制信息的传递,包含三个门:遗忘门![]() ,输入门
,输入门![]() ,输出门
,输出门![]() 。遗忘门决定了上一个细胞状态
。遗忘门决定了上一个细胞状态![]() 的信息多少需要丢弃,输入门决定保存细胞状态
的信息多少需要丢弃,输入门决定保存细胞状态![]() 的哪些新生信息,输出门决定在该时刻
的哪些新生信息,输出门决定在该时刻![]() 需要输出到外部的信息[3]。
需要输出到外部的信息[3]。
LSTM通过三个门来处理时序数据,首先通过遗忘门,遗忘门数学表达式如下:
![]()
(1)
其中,![]() 和
和![]() 分别表示遗忘门的权重和偏置参数。
分别表示遗忘门的权重和偏置参数。
通过![]() 和
和![]() 输出一个0到1之间的向量,决定上一个细胞状态多少信息需要遗忘,0表示全部丢弃,1表示全部接受。
输出一个0到1之间的向量,决定上一个细胞状态多少信息需要遗忘,0表示全部丢弃,1表示全部接受。
然后信息被传递到输入门,输入门包括两部分,1)sigmoid激活得到更新状态it 2)tanh激活得到候选状态![]() ,公式如下:
,公式如下:
![]()
(2)
![]()
(3)
其中,![]() 、
、![]() 表示权重参数,
表示权重参数,![]() 、
、 ![]() 表示偏置参数
表示偏置参数
经输入门后,上一个细胞信息![]() 更新为
更新为![]() ,最后通过输出门决定要输出哪些信息。输出门同样包含两个部分,1)sigmoid 层2)tanh层,与输出门不同的是,sigmoid 层决定要输出细胞状态中的哪些部分,tanh层变换调整细胞状态值得到0-1之间的向量再乘以细胞状态Ct
,最后通过输出门决定要输出哪些信息。输出门同样包含两个部分,1)sigmoid 层2)tanh层,与输出门不同的是,sigmoid 层决定要输出细胞状态中的哪些部分,tanh层变换调整细胞状态值得到0-1之间的向量再乘以细胞状态Ct![]() 得到最终的输出。具体数学表达式如下:
得到最终的输出。具体数学表达式如下:
![]()
(4)
![]()
(5)
其中,![]() 代表sigmoid激活函数层的权重参数,
代表sigmoid激活函数层的权重参数,![]() 代表sigmoid激活函数层的偏置参数。
代表sigmoid激活函数层的偏置参数。![]() 代表sigmoid激活函数层的输出,
代表sigmoid激活函数层的输出,![]() 代表该时刻记忆单元的输出,即隐含状态。
代表该时刻记忆单元的输出,即隐含状态。
门控单元原理图如下所示:
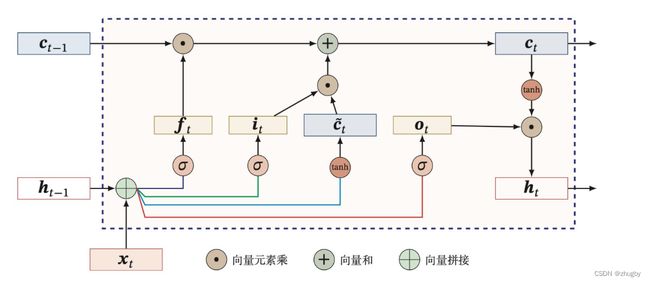
图3 LSTM门控单元原理图
将各个细胞/门控单元连接起来就变成了LSTM的整体架构,如下图所示:
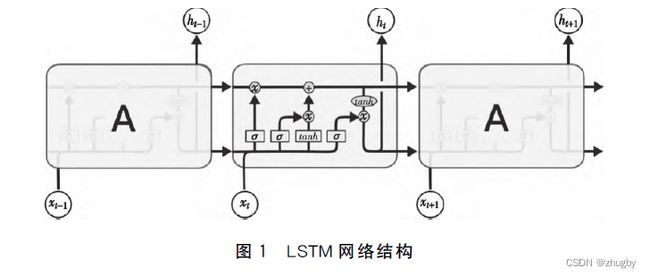
图4 LSTM网络结构
3.2 评价指标
本文中使用均方误差RMSE作为模型评价的指标,均方误差RMSE衡量的是模型的预测值和真实值的差异,经常用做机器学习预测结果衡量的标准。如公式(1)所示:
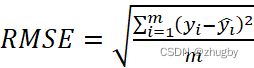
(6)
3.3模型预测及分析
计算均方误差,得RMSE=0.5793,用可视化图形展示预测结果。
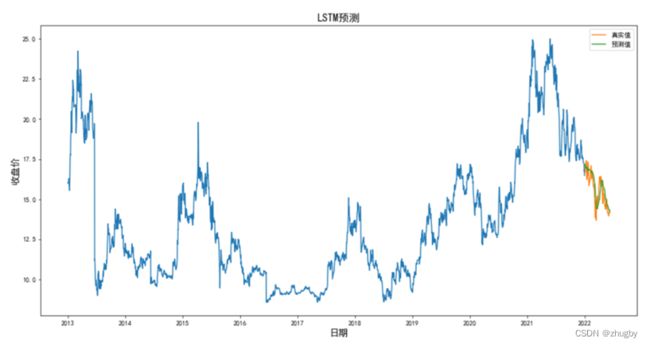
结合RMSE值和图形,LSTM算法拟合程度高,在预测准确率上表现出色。
代码实现:
#importing required libraries
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
#setting index
data = df.sort_index(ascending=True, axis=0)
new_data = data[['trade_date', 'close']]
new_data.index = new_data['trade_date']
new_data.drop('trade_date', axis=1, inplace=True)
new_data.head()
#creating train and test sets
dataset = new_data.values
train= dataset[0:2187,:]
valid = dataset[2187:,:]
#converting dataset into x_train and y_train
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=1)
#predicting 246 values, using past 60 from the train data
inputs = new_data[len(new_data) - len(valid) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
closing_price = model.predict(X_test)
closing_price1 = scaler.inverse_transform(closing_price)
rms=np.sqrt(np.mean(np.power((valid-closing_price1),2)))
rms
#v=new_data[2187:]
valid1['Pre_Lstm'] = closing_price1
train=new_data[:2187]
plt.figure(figsize=(16,8))
plt.plot(train['close'])
plt.plot(valid1['close'],label='真实值')
plt.plot(valid1['Pre_Lstm'],label='预测值')
plt.title('LSTM预测',fontsize=16)
plt.xlabel('日期',fontsize=14)
plt.ylabel('收盘价',fontsize=14)
plt.legend(loc=0)
四、模型性能对比
为了更加清晰的展现lstm模型性能,本文选取了四种代表模型,线性模型中的移动平均、线性回归,传统机器学习模型KNN,深度学习模型LSTM,分别使用四种模型对深股平安银行的股价进行拟合预测。表4展示了四个模型的部分预测数值,图12对比展示了四个模型的股价预测趋势,表5展示了四个模型的RSME值。
表4 部分测试集模型预测数值
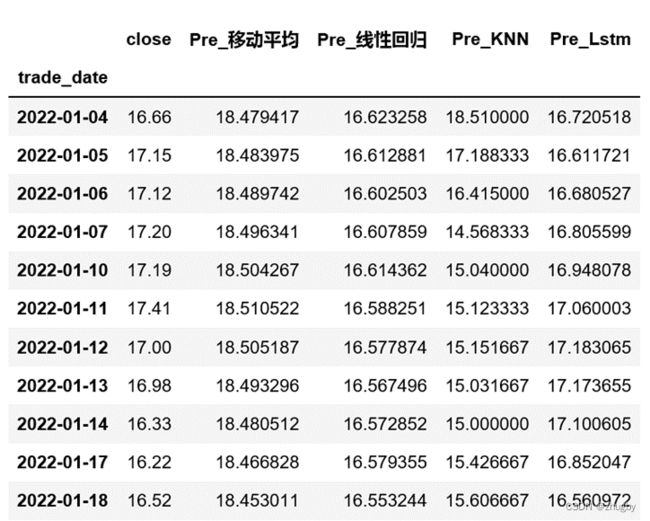
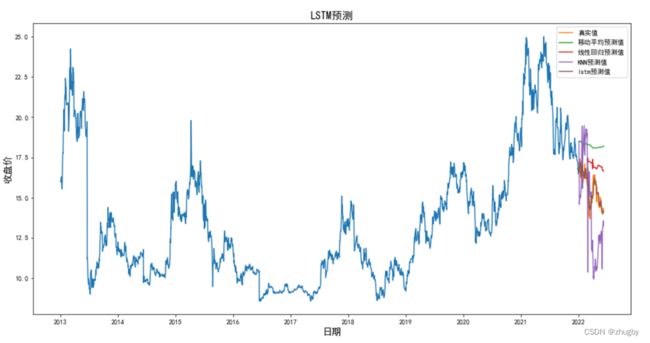 图12 测试集4种模型股价预测趋势比价
图12 测试集4种模型股价预测趋势比价
表5 模型RSME值
| 模型 |
移动平均 |
线性回归 |
KNN |
LSTM |
| RMSE |
2.8579 |
1.7651 |
2.9326 |
0.4424 |
(因篇幅问题,另外三种模型的实现代码没有放出来,需要的可以私戳。)
综合图表结果分析得出,在准确率方面,LSTM表现最佳,其次是线性回归,移动平均法和KNN算法模型表现最差;在预测未来股价的涨跌趋势方面,移动平均和线性回归的表现要稍微优于KNN,主要是因为他们消除了数据的波动性从而展示数据长期的趋势。移动平均单纯依靠前几天的行情数据预测下一个交易日的股价,线性回归和KNN依靠日期特征拟合回归模型,传统的线性模型和机器模型都不具有挖掘数据隐含信息的能力,在股票这种波动大、噪声强的非线性数据上很难有令人满意的表现。
而深度学习模型具备的一些特征使得他天生适合处理预测金融时序数据,如:1)深度学习模型不受维度限制,可以将所有与因变量相关的特征数据都纳入模型当中,得到更完善的表征;2)具备很好的非线性拟合能力,适合拟合无规律波动大的时序数据;3)不容易陷入模型过拟合及局部最优;4)与线性回归和传统机器学习相比不需要人工手动的构造特征,通过多层神经网络提取数据隐含特征,深度网络表达能力更强等。且本文选取的LSTM网络具备长期记忆的功能,对高噪声的金融股票数据的预测效果会更好。
五、LSTM预测
由于LSTM模型拟合效果很好,现使用LSTM模型预测未来短期内股价的走势。考虑到周末深圳交易所休息,因此在预测时需要剔除双休及节假日,本文中使用LSTM模型对未来30个工作日平安银行的股价走势进行预测,结果如下图所示:
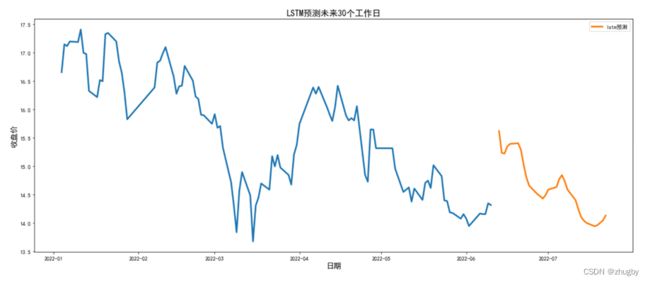
图中存在中断的一部分是因为我们真实的数据是截止2020-06-10,6月10日是周五,下一个工作日是6月12,因此预测日期中间会空出两天,表现在图形上就呈现出一小块中断。
观察接下来一个月左右的股价走势,未来一段时间总体上平安银行的股价有下降的趋势。投资者在6月10日周五时可以选择加仓平安银行的股票,在下一周股价上升到15.5左右的时候抛售留底,观察股市动向,由于整体上下降趋势,等到股市行情稳定之后可以考虑慢慢加仓。
值得注意的是,股价有可能会受到舆论、新闻媒体还有一些不可抗力的影响,比如大型自然灾害、公司的费货币化合并拆分、公司名誉受损等等,这些无法提前预测的无形因素会对股价产生影响。因此,投资者不能完全依赖模型给出的预测结果,要多留意股市风向,谨慎投资。
实现代码
1)实现提取剔除双休的30天工作日日期:
import datetime
def date_by_adding_business_days(from_date, add_days):
business_days_to_add = add_days
current_date = from_date
re=[]
while business_days_to_add > 0:
current_date += datetime.timedelta(days=1)
current_date1=current_date.strftime("%Y-%m-%d")
weekday = current_date.weekday()
if weekday < 5: # sunday = 6
re.append(current_date1)
business_days_to_add -= 1
return re
data_pre=date_by_adding_business_days(datetime.date(2022, 6, 10), 30)2)模型预测:
dataset = new_data.values
train= dataset
#valid = dataset[2187:,:]
#converting dataset into x_train and y_train
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=1)
#predicting 246 values, using past 60 from the train data
inputs = new_data[len(new_data) - 30 - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
closing_price = model.predict(X_test)
closing_price1 = scaler.inverse_transform(closing_price)
#rms=np.sqrt(np.mean(np.power((valid-closing_price1),2)))
#rms
lstm_pre['date']=data_pre
lstm_pre=pd.DataFrame()
lstm_pre['trade_date']=data_pre
lstm_pre['trade_date']=pd.to_datetime(lstm_pre['trade_date'], format="%Y-%m-%d")
lstm_pre['pred']=closing_price1
lstm_pre.index = lstm_pre['trade_date']
#lstm_pre.drop('trade_date', axis=1, inplace=True)
lstm_pre
#plot
train=new_data[2187:]
plt.figure(figsize=(20,8))
plt.plot(train['close'],linewidth=3)
plt.plot(lstm_pre['pred'],label='lstm预测',linewidth=3)
plt.title('LSTM预测未来30个工作日',fontsize=16)
plt.xlabel('日期',fontsize=14)
plt.ylabel('收盘价',fontsize=14)
plt.legend(loc=0)参考文献:
[1] Hochreiter, S, and J. Schmidhuber. “Long short-term memory.” Neural Computation 9.8(1997):1735-1780.
[2] 梁宇佳,宋东峰.基于LSTM和情感分析的股票预测[J].科技与创新,2021,(21):126-127.
[3]许雪晨,田侃.一种基于金融文本情感分析的股票指数预测新方法[J].数量经济技术经济研究,2021,38(12):124-145.DOI:10.13653/j.cnki.jqte.2021.12.009.