HIVE 生成过多小文件的问题
HIVE 生成大量小文件
-
-
- 小文件的危害
- 为什么会生成多个小文件
- 不同的数据加载方式生成文件的区别
- 解决小文件过多的问题
-
今天运维人员突然发来了告警,有一张表生成的小文件太多,很疑惑,然后排查记录了下
HIVE的版本 2.x,使用的引擎是 MR;
注意:HIVE ON SPARK 或 SPARK-SQL 生成的小文件的方式不同,该篇文章针对 MR 引擎的 HIVE
小文件的危害
① 增加 TASK 的数量
当我们执行表查询时,每个文件都会生成一个 MapTask,在文件内容比较小的时候,过多的 Task 数量反而会降低查询的性能(因为 MapTask 的启动时间可能大于逻辑执行时间);同时每个JOB 生成的 MAP TASK 的数量是有限制的,可能会影响到其他JOB
② 增加 NameNode 的负担
我们知道,在 HADOOP 启动的时候,会通过 fsImage文件和edits文件 加载出所有文件的元数据信息,然后保存在 NameNode 节点的内存中,每个HDFS文件元信息(位置,大小,分块等)对象约占150字节,如果小文件过多,会占用大量内存,直接影响NameNode的性能。因此大量的小文件会严重占用 NameNode 的内存,有可能影响整个 Hadoop 集群的性能,因此,减少小文件的数量很有必要
为什么会生成多个小文件
HIVE 生成的小文件过多,指的是该表在 HDFS 目录下,有多个文件,且文件的磁盘占用比较小;
表的文件一般是向表插入数据的时候生成的,所以我们应该分析下插入数据的方式
不同的数据加载方式生成文件的区别
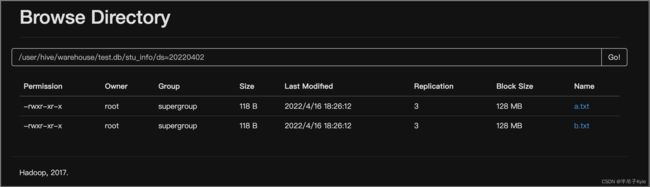
① 通过文件向表中加载数据
使用 LOAD 方式可以导入文件或文件夹,当导入一个文件时,HIVE 表就有一个文件,当导入文件夹时,HIVE 表的文件数量为文件夹下所有文件的数量
-- 导入文件
load data local inpath '/opt/data/cust_info.txt' overwrite into table cust_info
-- 导入文件夹
load data local inpath '/opt/data/cust_info' overwrite into table cust_ifno
② 直接向表中插入数据
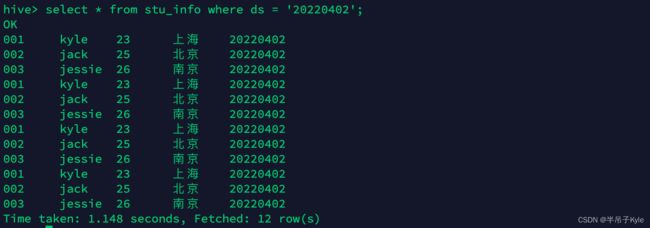
每次插入时都会产生一个文件,多次插入少量数据就会出现多个小文件
-- 执行两次看下结果
insert into table stu_info partition(ds = '20220405') values ('001','kyle', '22', 'beijing'),('002', 'lisa', '23', 'shanghai');

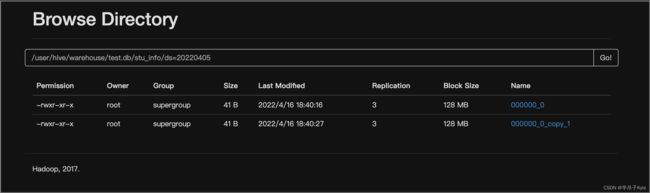
③ 通过查询方式加载数据
INSERT 导入数据时会启动 MR 任务,MR中 Reduc Task 有多少个就输出多少个文件;
文件数量=ReduceTask数量 * 分区数
insert into table stu_info partition(ds = '20220405')
select user_id, user_name from user_info;
解决小文件过多的问题
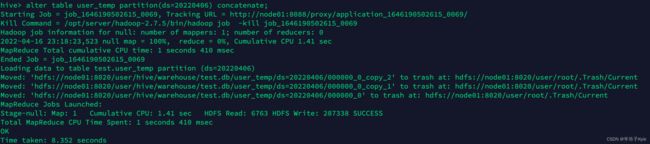
① 使用 HIVE 自带的 concatenate 命令,自动合并小文件
-- 非分区表合并小文件
alter table user_temp concatenate;
-- 分区表合并小文件
alter table user_temp partition(ds=20220406) concatenate;
# 注意
1、concatenate 命令只支持 RCFILE 和 ORC 文件类型
2、使用 concatenate 命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令
3、当多次使用 concatenate 后文件数量不再变化,和参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小 size
-- 插入数据
insert into table user_temp partition(ds = '20220406') values ('001','kyle', 'A', '9600120', 'abc');
insert into table user_temp partition(ds = '20220406') values ('003','jack', 'C', '9600122', 'ded');
insert into table user_temp partition(ds = '20220406') values ('004','flack', 'D', '9600124', 'fas');

![]()
② 调整参数减少 Map Task 数量
-- 设置 MAP 输入合并小文件的相关参数
-- 将 MapTask 中多个文件合成一个 split 作为输入(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
-- 每个Map最大输入大小(这个值决定了合并后文件的数量),256M
set mapred.max.split.size=256000000;
-- 每个节点上split至少的大小(这个值决定了多个DataNode上的文件是否需要合并),100M
set mapred.min.split.size.per.node=100000000;
-- 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并),100M
set mapred.min.split.size.per.rack=100000000;
-- 设置Map端输出进行合并,默认为true
set hive.merge.mapfiles=true;
-- 设置reduce端输出进行合并,默认为FALSE
set hive.merge.mapredfiles=true;
-- 设置合并文件的大小,256M
set hive.merge.size.per.task=256*1000*1000;
-- 当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件Merge,16M
set hive.merge.smallfiles.avgsize=16000000;
-- 启用压缩
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;
③ 减少ReduceTask 的数量
-- ReduceTask 的个数决定了输出的文件的个数,可以调整 ReduceTask 的个数控制 HIVE 表的文件数量
-- HIVE 中的分区函数 distribute by 可以控制 MR 中 partition 分区, 通过设置 ReduceTask 的数量,结合分区函数让数据均衡的进入每个ReduceTask即可。
-- 第一种: 直接设置 ReduceTask 的数量
set mapreduce.job.reduces=1;
-- 第二种: 设置每个 Reduce 的大小,Hive会根据数据总大小猜测确定一个reduce个数
-- 默认是1G,设置为5G
set hive.exec.reducers.bytes.per.reducer=5120000000;
-- 示例: 设置固定数量的 ReduceTask, 通过随机数将数据分发到不同的 ReduceTask
-- 设置ReduceTask数量为10,使用 rand(), 随机生成一个数 x % 10 , 这样数据就会随机进入 ReduceTask 中, 尽量使数据均匀分发
set mapreduce.job.reduces=10;
insert overwrite table stu_info partition(ds)
select *
from user_info
distribute by rand();
④ 文件归档
Hadoop 归档后的文件格式为 Har(一种存储格式) 文件,是一个单独的文件,可以直接访问,但是 HAR 文件并非是压缩的,因此也不会节约存储空间,但是可以减少小文件的数量
注意:归档的分区可以查询,但是不能插入数据,插入数据前必须先 unarchive 解除归档
-- 开启归档
set hive.archive.enabled=true;
-- Hive在创建归档时可以设置父目录
set hive.archive.har.parentdir.settable=true;
-- 控制需要归档文件的大小
set har.partfile.size=1099511627776;
-- 对 20220302 分区进行归档
alter table cust_info archive partition(ds='20220302');