精通八大排序算法系列:二、堆排序算法
精通八大排序算法系列:二、堆排序算法
作者:July 、二零一一年二月二十日
本文参考:Introduction To Algorithms,second edition。
-------------------
此精通排序算法系列,前一节,已讲过了一、快速排序算法,其中,快速排序每一趟比较用时O(n),要进行lgn次比较,才最终完成整个排序。所以快排的复杂度才为O(n*lgn)。而本节,我们要讲的是堆排序算法。据我所知,要真正彻底认识一个算法,最好是去查找此算法的原发明者的论文或相关文献。
ok,此节,咱们开始吧。
一、堆排序算法的基本特性
时间复杂度:O(nlgn)...
//等同于归并排序
最坏:O(nlgn)
空间复杂度:O(1).
不稳定。
二、堆与最大堆的建立
要介绍堆排序算法,咱们得先从介绍堆开始,然后到建立最大堆,最后才讲到堆排序算法。
2.1、堆的介绍
如下图,
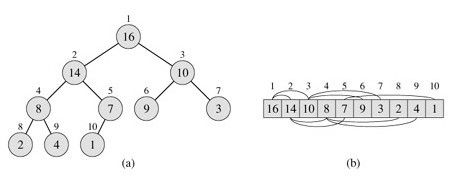
a),就是一个堆,它可以被视为一棵完全二叉树。
每个堆对应于一个数组b),假设一个堆的数组A,
我们用length[A]表述数组中的元素个数,heap-size[A]表示本身存放在A中的堆的元素个数。
当然,就有,heap-size[A]<=length[A]。
树的根为A[1],i表示某一结点的下标,
则父结点为PARENT(i),左儿子LEFT[i],右儿子RIGHT[i]的关系如下:
PARENT(i)
return |_i/2_|
LEFT(i)
return 2i
RIGHT(i)
return 2i + 1
二叉堆根据根结点与其子结点的大小比较关系,分为最大堆和最小堆。
最大堆:
根以外的每个结点i都不大于其根结点,即根为最大元素,在顶端,有
A[PARENT(i)] (根)≥ A[i] ,
最小堆:
根以外的每个结点i都不小于其根结点,即根为最小元素,在顶端,有
A[PARENT(i)] (根)≤ A[i] .
在本节的堆排序算法中,我们采用的是最大堆;最小堆,通常在构造最小优先队列时使用。
由前面,可知,堆可以看成一棵树,所以,堆的高度,即为树的高度,O(lgn)。
所以,一般的操作,运行时间都是为O(lgn)。
具体,如下:
The MAX-HEAPIFY:O(lgn) 这是保持最大堆的关键.
The BUILD-MAX-HEAP:线性时间。在无序输入数组基础上构造最大堆。
The HEAPSORT:O(nlgn) time, 堆排序算法是对一个数组原地进行排序.
The MAX-HEAP-INSERT, HEAP-EXTRACT-MAX, HEAP-INCREASE-KEY, HEAP-MAXIMUM:O(lgn)。
可以让堆作为最小优先队列使用。
2.2.1、保持堆的性质(O(lgn))
为了保持最大堆的性质,我们运用MAX-HEAPIFY操作,作调整,递归调用此操作,使i为根的子树成为最大堆。
MAX-HEAPIFY算法,如下所示(核心):
MAX-HEAPIFY(A, i)
1 l ← LEFT(i)
2 r ← RIGHT(i)
3 if l ≤ heap-size[A] and A[l] > A[i]
4 then largest ← l
5 else largest ← i
6 if r ≤ heap-size[A] and A[r] > A[largest]
7 then largest ← r
8 if largest ≠ i
9 then exchange A[i] <-> A[largest]
10 MAX-HEAPIFY(A, largest)
如上,首先第一步,在对应的数组元素A[i], 左孩子A[LEFT(i)], 和右孩子A[RIGHT(i)]中找到最大的那一个,将其下标存储在largest中。如果A[i]已经就是最大的元素,则程序直接结束。否则,i的某个子结点为最大的元素,将其,即A[largest]与A[i]交换,从而使i及其子女都能满足最大堆性质。下标largest所指的元素变成了A[i]的值,会违反最大堆性质,所以对largest所指元素调用MAX-HEAPIFY。如下,是此MAX-HEAPIFY的演示过程(下图是把4调整到最底层,一趟操作,但摸索的时间为LogN):
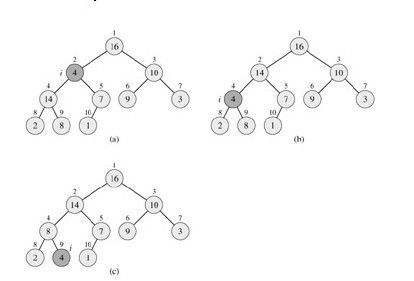
由上图,我们很容易看出,初始构造出一最大堆之后,在元素A[i],即16,大于它的俩个子结点4、10,满足最大堆性质。所以,i下调指向着4,小于,左子14,所以,调用MAX-HEAPIFY,4与其子,14交换位置。但4处在了14原来的位置之后,4小于其右子8,又违反了最大堆的性质,所以再递归调用MAX-HEAPIFY,将4与8,交换位置。于是,满足了最大堆性质,程序结束。
2.2.2、MAX-HEAPIFY的运行时间
MAX-HEAPIFY作用在一棵以结点i为根的、大小为n的子树上时,其运行时间为调整元素A[i]、A[LEFT(i)],A[RIGHT(i)]的关系时所用时间为O(1),再加上,对以i的某个子结点为根的子树调用MAX-HEAPIFY所需的时间,且i结点的子树大小至多为2n/3,所以,MAX-HEAPIFY的运行时间为
T (n) ≤ T(2n/3) + Θ(1).
我们,可以证得此式子的递归解为T(n)=O(lgn)。具体证法,可参考算法导论第6章之6.2节,这里,略过。
2.3.1、建堆(O(N))
BUILD-MAX-HEAP(A)
1 heap-size[A] ← length[A]
2 for i ← |_length[A]/2_| downto 1
3 do MAX-HEAPIFY(A, i) //建堆,怎么建列?原来就是不断的调用MAX-HEAPIFY(A, i)来建立最大堆。
BUILD-MAX-HEAP通过对每一个其它结点,都调用一次MAX-HEAPIFY,
来建立一个与数组A[1...n]相对应的最大堆。A[(|_n/2_|+1) ‥ n]中的元素都是树中的叶子。
因此,自然而然,每个结点,都可以看作一个只含一个元素的堆。
关于此过程BUILD-MAX-HEAP(A)的正确性,可参考算法导论 第6章之6.3节。
下图,是一个此过程的例子(下图是不断的调用MAX-HEAPIFY操作,把所有的违反堆性质的数都要调整,共N趟操作,然,摸索时间最终精确为O(N)):
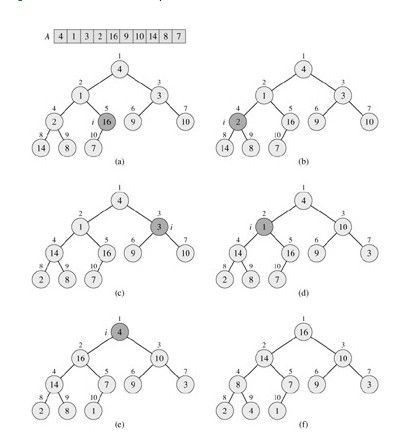
2.3.2、BUILD-MAX-HEAP的运行时间
因为每次调用MAX-HEAPPIFY的时间为O(lgn),而共有O(n)次调用,所以BUILD-MAX-HEAP的简单上界为O(nlgn)。算法导论一书提到,尽管这个时间界是对的,但从渐进意义上,还不够精确。
那么,更精确的时间界,是多少列?
由于,MAX-HEAPIFY在树中不同高度的结点处运行的时间不同,且大部分结点的高度都比较小,
而我们知道,一n个元素的堆的高度为|_lgn_|(向下取整),且在任意高度h上,至多有|-n/2^h+1-|(向上取整)个结点。
因此,MAX-HEAPIFY作用在高度为h的结点上的时间为O(h),所以,BUILD-MAX-HEAP的上界为:O(n)。具体推导过程,略。
三、堆排序算法
所谓的堆排序,就是调用上述俩个过程:一个建堆的操作、BUILD-MAX-HEAP,一个保持最大堆的操作、MAX-HEAPIFY。详细算法如下:
HEAPSORT(A) //n-1次调用MAX-HEAPIFY,所以,O(n*lgn)
1 BUILD-MAX-HEAP(A) //建最大堆,O(n)
2 for i ← length[A] downto 2
3 do exchange A[1] <-> A[i]
4 heap-size[A] ← heap-size[A] - 1
5 MAX-HEAPIFY(A, 1) //保持堆的性质,O(lgn)
如上,即是堆排序算法的完整表述。下面,再贴一下上述堆排序算法中的俩个建堆、与保持最大堆操作:
BUILD-MAX-HEAP(A) //建堆
1 heap-size[A] ← length[A]
2 for i ← |_length[A]/2_| downto 1
3 do MAX-HEAPIFY(A, i)
MAX-HEAPIFY(A, i) //保持最大堆
1 l ← LEFT(i)
2 r ← RIGHT(i)
3 if l ≤ heap-size[A] and A[l] > A[i]
4 then largest ← l
5 else largest ← i
6 if r ≤ heap-size[A] and A[r] > A[largest]
7 then largest ← r
8 if largest ≠ i
9 then exchange A[i] <-> A[largest]
10 MAX-HEAPIFY(A, largest)
以下是,堆排序算法的演示过程(通过,顶端最大的元素与最后一个元素不断的交换,交换后又不断的调用MAX-HEAPIFY以重新维持最大堆的性质,最后,一个一个的,从大到小的,把堆中的所有元素都清理掉,也就形成了一个有序的序列。这就是堆排序的全部过程。):
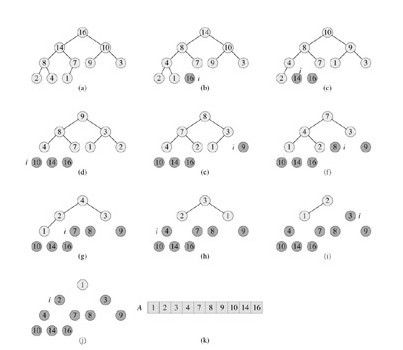
上图中,a->b,b->c,....之间,都有一个顶端最大元素与最小元素交换后,调用MAX-HEAPIFY的过程,我们知道,此MAX-HEAPIFY的运行时间为O(lgn),而要完成整个堆排序的过程,共要经过O(n)次这样的MAX-HEAPIFY操作。所以,才有堆排序算法的运行时间为O(n*lgn)。
后续:把堆想象成为一种树,二叉树之类的。所以,用堆做数据查找、删除的时间复杂度皆为O(logN)。 那么是一种什么样的二叉树列?一种特殊的二叉树,分为最大堆,最小堆。最大堆,就是上头大,下头小。最小堆就是上头小,下头大。
完。
本人July对本博客所有任何文章、内容和资料享有版权。
转载务必注明作者本人及出处,并通知本人。二零一一年二月二十一日。