吴恩达机器学习作业笔记-ex1单变量线性回归
学习b站【吴恩达《机器学习》作业讲解集合篇!干货适合囤!囤!囤!-哔哩哔哩】https://b23.tv/OpO1FU的笔记
完整代码放最后
1.显示数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = 'ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
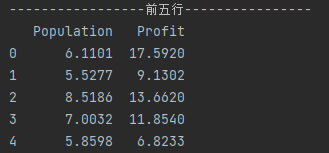
#展示前5行
print('-----------------前五行----------------')
data.head()
print(data.head())
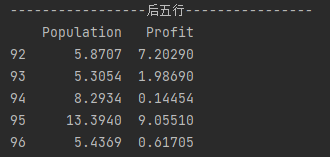
#展示后5行
print('-----------------后五行----------------')
print(data.tail(5))
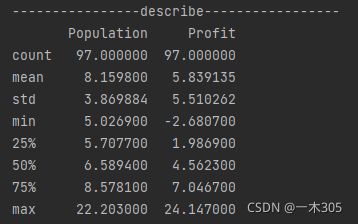
#展示数据细节
data.describe()
print('----------------describe-----------------')
print(data.describe())
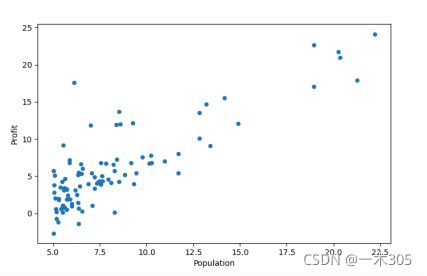
#数据可视化
data.plot(kind='scatter', x='Population', y='Profit', figsize=(8,5))
plt.show()显示结果:
2.数据处理
(1)将b写为theta0*1,统一格式,在x1,x2等的前面加上1即可
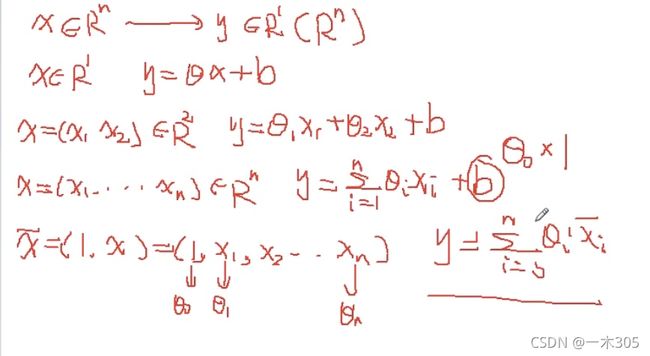
#数据处理
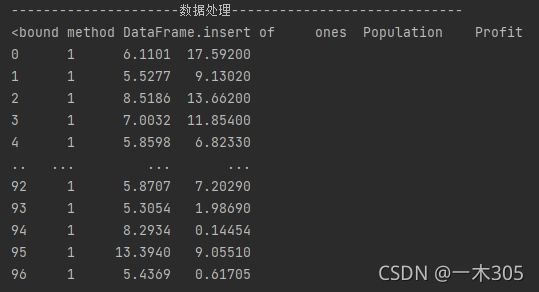
print('---------------------数据处理-----------------------------')
data.insert(0,'ones',1)#0:在第一列前面插入一列,名称为one的一列,值为1
print(data.insert)
#显示数量
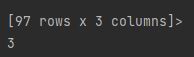
cols = data.shape[1]#1为列,0表示行,此处表明列数为3
print(cols)显示结果:
#显示数量
cols = data.shape[1]#1为列,0表示行,此处表明列数为3
print(cols)显示结果:
(2)按照上面的分析,分离出x和y
#抽取iloc,左闭右开
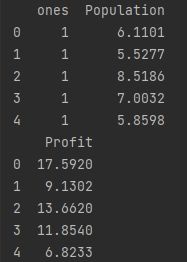
x = data.iloc[:,0:cols-1]#逗号前为行,逗号后为列,大于等于0小于2,此处抽取0,1列
x.head()#head默认是观察前5列
print(x.head())
y=data.iloc[:,cols-1:cols]#大于等于2小于3,抽取第2列
y.head()
print(y.head())显示结果:
#将上面抽取的x,y都转换为矩阵
#np.matrix()函数用于从类数组对象或数据字符串返回矩阵
#np.array()函数用于创建一个数组
x = np.matrix(x.values)
y = np.matrix(y.values)
#将里面初始化的二维数组强制变换为一个矩阵
theta = np.matrix(np.array([0,0]))#theta是一个(1,2)数组,一行两维
print(theta)
print(x.shape,y.shape,theta.shape)
#x为97个数,2维,y为97个数,1维(97行一列)显示结果:
![]()
3、定义代价函数,显示代价函数初始值
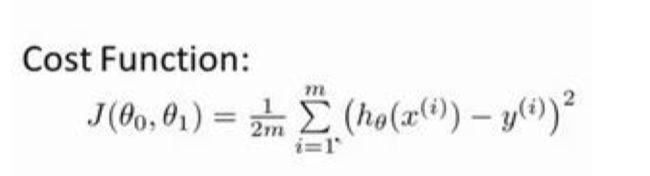

#定义代价函数J
def costFunction(x,y,theta) :
# np.power(x,y)表示求x的y次方
inner = np.power(((x*theta.T)-y),2)
return np.sum(inner)/(2*len(x))
#计算代价函数J
print(costFunction(x,y,theta))#计算初始的x,y,theta
#theta刚刚开始为0,0,算的是y1的平方加到yn的平方除以2m显示结果:
![]()
4、梯度下降计算theta0,theta1


#使用梯度下降法
#求J的最小值,优化theta0和theta1
def gradientDscent(x,y,theta,alpha,iters): #iters为迭代的次数
temp = np.matrix(np.zeros(theta.shape))#构建临时矩阵,跟theta大小一样(1,2)
paramaters = int(theta.ravel().shape[1]) #paramaters表示参数个数theta0和theta1,paramaters=2
# ravel()将数组维度拉成一维数组
cost = np.zeros(iters)#j矩阵,维度为保证每次迭代后的cost
for i in range(iters):#0到iters-1的遍历
error = (x * theta.T)-y
for j in range(paramaters): #便利0-1,j=0或者1
term=np.multiply(error,x[:,j])#x[:,j]表示抽x所有行,第j列
#np.multiply表数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致
temp[0,j] = theta[0,j]-((alpha/len(x))*np.sum(term))#theta的梯度更新
#len(x))*np.sum(term))表示J对theta0,theta1求偏导
theta = temp#更新后的theta赋值
cost[i]= costFunction(x,y,theta) #将更新后的存入cost
return theta,cost
print('-----------给alpha,iters赋值------------------------')
alpha = 0.01
iters = 1500
theta, costs = gradientDscent(x, y, theta, alpha, iters)
print(theta)
print(costFunction(x,y,theta))显示结果:

5、显示拟合函数和代价函数的结果
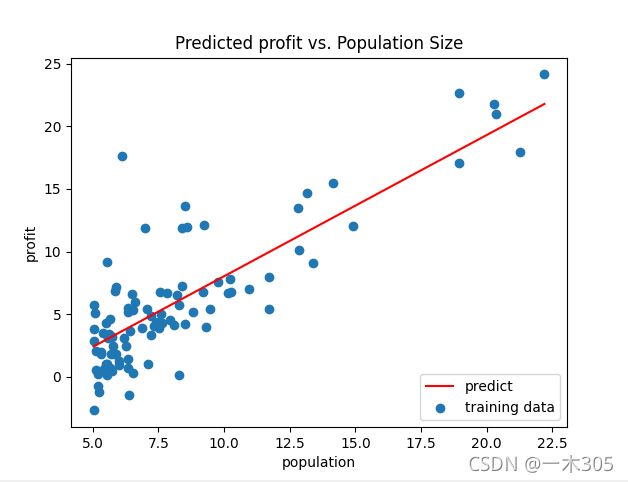
print('---------------拟合函数可视化--------------------')
x=np.linspace(data.Population.min(),data.Population.max())#在最大最小值里面取100个样本
y=theta[0,0]+(theta[0,1]*x) #theta[0,0]表示theta0,theta[0,1]表示theta1
fig,ax=plt.subplots()
ax.plot(x,y,'r',label='predict')
ax.scatter(data.Population,data.Profit,label='training data')
ax.legend(loc=4)#显示标签位置
ax.set_xlabel('population')
ax.set_ylabel('profit')
ax.set_title('Predicted profit vs. Population Size')
plt.show()显示结果:
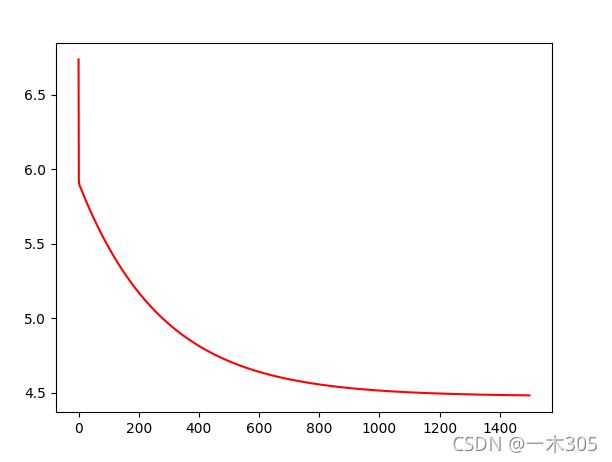
print('---------------代价函数可视化--------------------')
fig,ax=plt.subplots()
ax.plot(np.arange(iters),costs,'r')
ax.set_xlabel='Iterations'
ax.set_ylabel='Costs'
ax.set_title='Error vs. Traing Epoch'
plt.show()显示结果:
完整的代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path = 'ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
#展示前5行
print('-----------------前五行----------------')
data.head()
print(data.head())
#展示后5行
print('-----------------后五行----------------')
print(data.tail(5))
#展示数据细节
data.describe()
print('----------------describe-----------------')
print(data.describe())
#数据可视化
data.plot(kind='scatter', x='Population', y='Profit', figsize=(8,5))
plt.show()
#数据处理
print('---------------------数据处理-----------------------------')
data.insert(0,'ones',1)#0:在第一列前面插入一列,名称为one的一列,值为1
print(data.insert)
#显示数量
cols = data.shape[1]#1为列,0表示行,此处表明列数为3
print(cols)
#抽取iloc,左闭右开
x = data.iloc[:,0:cols-1]#逗号前为行,逗号后为列,大于等于0小于2,此处抽取0,1列
x.head()#head默认是观察前5列
print(x.head())
y=data.iloc[:,cols-1:cols]#大于等于2小于3,抽取第2列
y.head()
print(y.head())
#将上面抽取的x,y都转换为矩阵
#np.matrix()函数用于从类数组对象或数据字符串返回矩阵
#np.array()函数用于创建一个数组
x = np.matrix(x.values)
y = np.matrix(y.values)
#将里面初始化的二维数组强制变换为一个矩阵
theta = np.matrix(np.array([0,0]))#theta是一个(1,2)数组,一行两维
print(theta)
print(x.shape,y.shape,theta.shape)
#x为97个数,2维,y为97个数,1维(97行一列)
#定义代价函数J
def costFunction(x,y,theta) :
# np.power(x,y)表示求x的y次方
inner = np.power(((x*theta.T)-y),2)
return np.sum(inner)/(2*len(x))
#计算代价函数J
print(costFunction(x,y,theta))#计算初始的x,y,theta
#theta刚刚开始为0,0,算的是y1的平方加到yn的平方除以2m
#使用梯度下降法
#求J的最小值,优化theta0和theta1
def gradientDscent(x,y,theta,alpha,iters): #iters为迭代的次数
temp = np.matrix(np.zeros(theta.shape))#构建临时矩阵,跟theta大小一样(1,2)
paramaters = int(theta.ravel().shape[1]) #paramaters表示参数个数theta0和theta1,paramaters=2
# ravel()将数组维度拉成一维数组
cost = np.zeros(iters)#j矩阵,维度为保证每次迭代后的cost
for i in range(iters):#0到iters-1的遍历
error = (x * theta.T)-y
for j in range(paramaters): #便利0-1,j=0或者1
term=np.multiply(error,x[:,j])#x[:,j]表示抽x所有行,第j列
#np.multiply表数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致
temp[0,j] = theta[0,j]-((alpha/len(x))*np.sum(term))#theta的梯度更新
#len(x))*np.sum(term))表示J对theta0,theta1求偏导
theta = temp#更新后的theta赋值
cost[i]= costFunction(x,y,theta) #将更新后的存入cost
return theta,cost
print('-----------给alpha,iters赋值------------------------')
alpha = 0.01
iters = 1500
theta, costs = gradientDscent(x, y, theta, alpha, iters)
print(theta)
print(costFunction(x,y,theta))
print('---------------拟合函数可视化--------------------')
x=np.linspace(data.Population.min(),data.Population.max())#在最大最小值里面取100个样本
y=theta[0,0]+(theta[0,1]*x) #theta[0,0]表示theta0,theta[0,1]表示theta1
fig,ax=plt.subplots()
ax.plot(x,y,'r',label='predict')
ax.scatter(data.Population,data.Profit,label='training data')
ax.legend(loc=4)#显示标签位置
ax.set_xlabel('population')
ax.set_ylabel('profit')
ax.set_title('Predicted profit vs. Population Size')
plt.show()
print('---------------代价函数可视化--------------------')
fig,ax=plt.subplots()
ax.plot(np.arange(iters),costs,'r')
ax.set_xlabel='Iterations'
ax.set_ylabel='Costs'
ax.set_title='Error vs. Traing Epoch'
plt.show()