本文作者为中国移动云能力中心大数据团队软件开发工程师孙大鹏,本文结合 2.0.0 版本的 Kafka 源码,详细介绍了 Kafka 分区副本重分配的流程和逻辑,供大家参考。
一、前言
Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,旨在提供一个统一的、高吞吐、低延迟的实时数据处理平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
在 Kafka 中,用 topic 来对消息进行分类,每个进入到 Kafka 的信息都会被放到一个 topic 下,同时每个 topic 中的消息又可以分为若干 partition 以此来提高消息的处理效率。存储消息数据的主机服务器被命名为 broker。通常为了保证数据的可靠性,数据是以多副本的形式保存在不同 broker 的不同磁盘上的。对于每一个 topic 的每一个 partition,如果多个副本之间完成了数据同步,保证了数据的一致性,则此时的多个副本所在的 broker 的集合称为 Isr。同一时间,某个 topic 的某个 partition 的多个副本中仅有一个对外提供服务,此时对外提供服务的 broker 被认定为该 partition 的 leader,客户端的请求都集中到 leader 上。
对于 2 副本 3 分区的 topic 其描述信息及存储状态如下所示:
test的描述信息: Topic:test PartitionCount:3 ReplicationFactor:2 Configs:min.insync.replic as=1 Topic: test Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1 Topic: test Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0 Topic: test Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
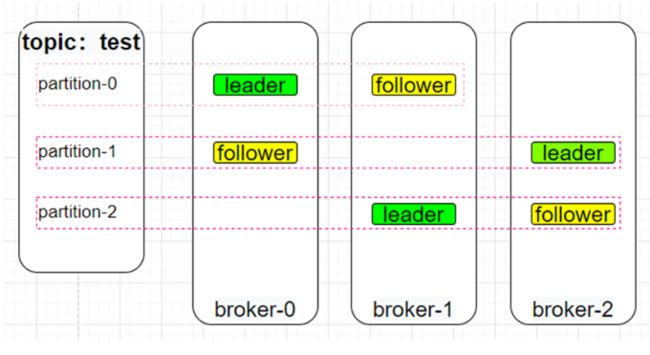
test的副本分布
健康状态的 Kafka 集群,对于每个 topic 的每个 partition,其 Isr 都应该等于预期的副本集合(后面均已 Replicas 表示),但在实际场景中,不可避免的存在磁盘/主机故障,或者 由于某些原因需要将部分 broker 节点下线的情况,此时就需要将故障/要下线的 broker 从 Replicas 中移除。对此 Kafka 提供了 kafka-reassign-partitions 工具来进行手动的分区副本迁移。
二、工具的使用
在 Kafka 的根路径下,通过执行如下命令,来完成分区副本的重分配:
./bin/kafka‐reassign‐partitions.sh ‐‐zookeeper localhost:2181/kafka ‐‐reassignment‐json‐file reassign‐topic.json ‐‐execute
其中:reassign‐topic.json 文件指定了分区副本的分布情况,示例如下:
{
"version": 1,
"partitions": [
{
"topic": "test",
"partition": 2,
"replicas": [
2,
1
],
"log_dirs": [
"any",
"any"
]
}
}
文件中指明了将 topic=test,partition=2 的分区的两副本分别移动到 brokerId=2 和 brokerId=1 的节点的任意磁盘路径上。
下面将结合 2.0.0 版本的 Kafka 源码简单的介绍下 Kafka 分区副本重分配的流程和逻辑。
三、元数据管理及协调器
在开始之前先简单介绍下在 Kafka 分区副本重分配中涉及到的两个概念:ZooKeeper 和 Kafka Controller。
3.1 ZooKeeper
Kafka 的元数据,是存储在 ZooKeeper 中的。Apache ZooKeeper 是一个提供高可靠性的分布式协调服务框架。它使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。该结构上的每个节点被称为 znode,用来保存一些元数据协调信息。同时 ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,或是 znode 所存的数据本身变更, ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端以便客户端 触发对应的处理操作。
3.2 Kafka Controller
Kafka Controller 是 Apache Kafka 的核心组件,它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责。
四、分区重分配流程分析
Kafka 的分区重分配就是在 client、broker 和 controller 的协同运行下完成的。即:
1. 客户端发起分区重分配任务,在 ZooKeeper 中创建/admin/reassign_partitions 节点,然 后向涉及的 broker 发送 alterReplicaLogDirs 请求
2. controller 监测到 ZooKeeper 中/admin/reassign_partitions 的变化,触发 Kafka 分区元 数据的变更维护操作
3. broker 接收到客户端发送的 alterReplicaLogDirs 请求,根据具体任务内容在服务端实际完成分区副本移动
流程总结如下图所示:
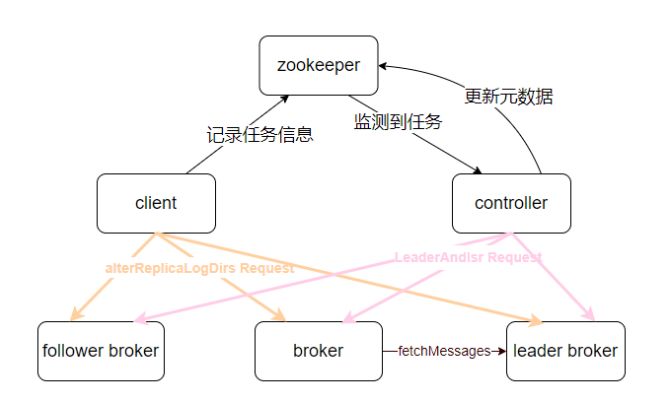
下面将针对这三部分分别展开介绍:
4.1 kafka-reassign-partitions 客户端
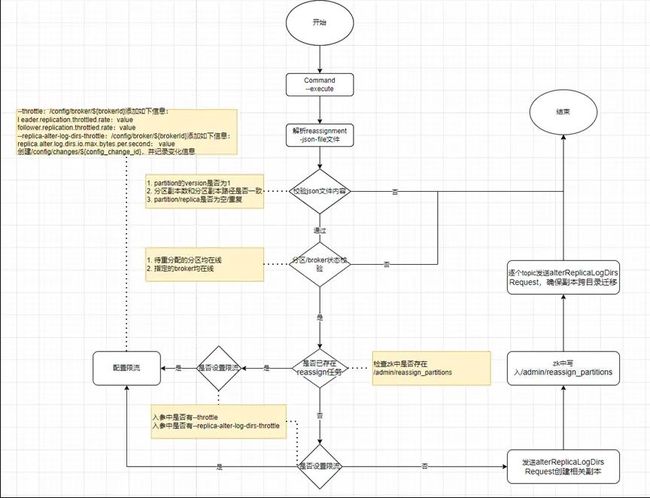
分区重分配任务是由客户端发起的,其入口主类为 ReassignPartitionsCommand.scala 中,调用 executeAssignment 方法。客户端的 executeAssignment 方法主要完成了如下操作:
1.解析 json 文件并进行相关校验
•读取 json 文件内容,校验“partitions”的“version”,仅为 1 时,继续执行副本重分 配
•校验分区副本数和副本数据路径数是否一致
•校验 partition/replica 是否为空/重复
2.检查待重分配的分区在集群中是否存在(根据 zk 中的/brokers/topics/${topic})
3.检查确认所有目标 broker 均在线(zk 中/brokers/ids 的子 znode 列表)
4.检查是否已存在分区副本重分配任务,如果已存在相关任务,则退出
5.将分区重分配任务记录到 zk 中,即在 zk 中创建/admin/reassign_partitions,以便 controller 可以发现并协调 broker 进行相关操作
6.根据解析的 json 内容,逐个 topic 向相关的 broker 发送 alterReplicaLogDirs 请求
客户端的处理逻辑可总结为如下流程图:
4.2 controller 维护分区的元数据信息
在 controller 启动时会创建 partitionReassignmentHandler,kafkaController 主线程回调 onControllerFailover 时,检测到/admin/reassign_partitions 发生变化时,触发分区副本重分配操作,在 maybeTriggerPartitionReassignment 中通过调用 onPartitionReassignment 真正执行分区副本重分配。在 onPartitionReassignment 中定 义了三个概念:
•RAR:指定的分区副本放置策略
•OAR:原始的分区副本放置策略
•AR:当前的分区副本放置策略
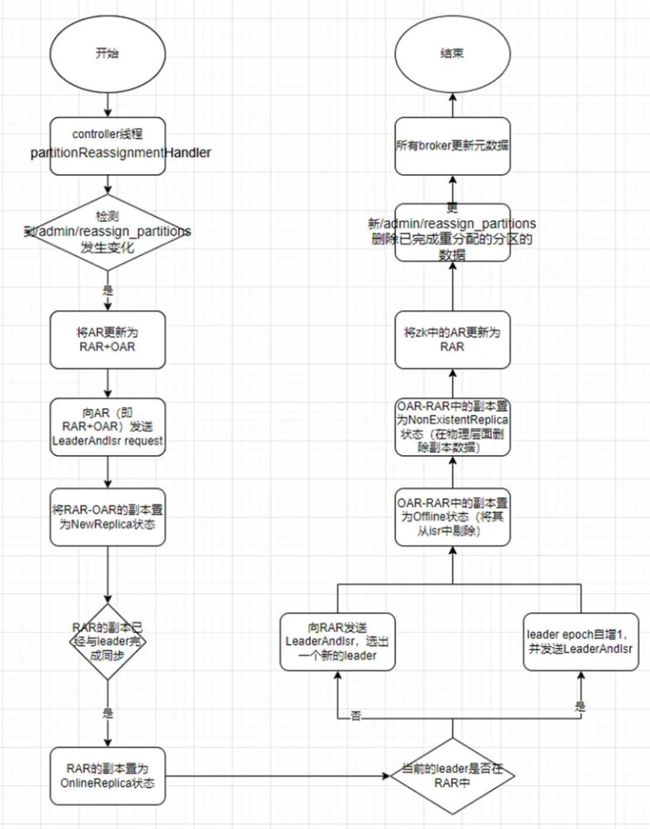
onPartitionReassignment 的执行过程可以总结为如下步骤:
检查指定的分区副本是否处在 isr 中,如果不在则执行以下前 3 步,否则直接执行第 4 步
1.在 zk 中将 AR 更新为 RAR+OAR (/broker/topics/${topicName})
2.向所有副本(RAR+OAR)中发送 LeaderAndIsr 请求
3.将 RAR-OAR 的副本状态置为 NewReplica,等待 NewReplica 中的数据与 leader 中的数据 完成同步
4.等待直到所有 RAR 中的副本完成与 leader 的同步
5.将所有 RAR 的副本置为 OnlineReplica 状态
6.将 RAR 作为 AR
7.如果当前的 leader 不在 RAR 中,发送 LeaderAndIsr Request 从 RAR 中选出一个新的 leader;如果当前 leader 在 RAR 中,检查 leader 状态,如果 leader 健康则更新 LeaderEpoch,否则重新选择 leader
8.将 OAR-RAR 的副本置为 Offline 状态
9.将 OAR-RAR 的副本置为 NonExistentReplica 状态(真实删除对应的分区副本)
10.将 zk 中的 AR 置为 RAR(/brokers/topics/${topicName}数据格式:{"version":1,"partitions":{"0":[${brokerId}]}})
11.更新 zk 中/admin/reassign_partitions 的值,将完成迁移的分区删除
12.同步所有 broker,更新元数据信息
逻辑流程图如下:
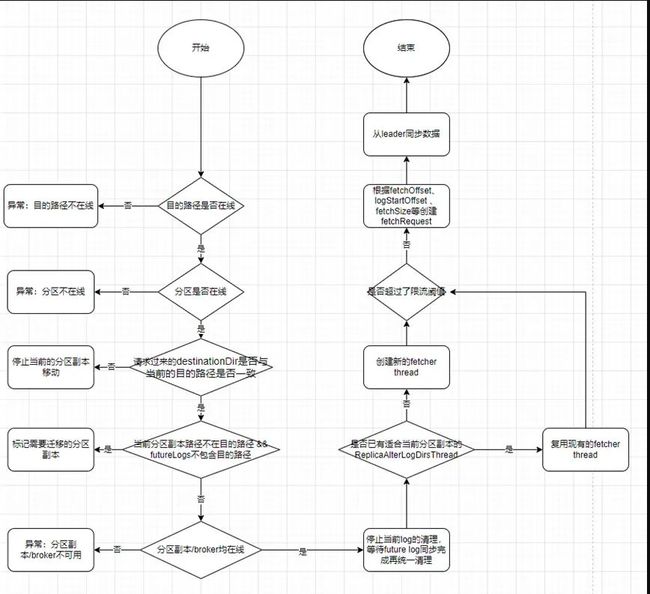
4.3 broker 端数据跨路径迁移
底层数据跨路径迁移,是由 broker 端完成的,broker 接收到客户端发来的 ALTER_REPLICA_LOG_DIRS 请求后,调用 alterReplicaLogDirs 方法,相关流程如下:
1.确保目的路径/待移动分区在线
2.如果当前分区副本的 log 路径不存在给定的目的路径并且 futureLogs(用于跨路径数据迁移的中间过程)也不包含目的路径,则在内存中记录当前分区副本和目的 logDir,即标记那些需要进行迁移的分区副本路径
3.对于需要移动的分区副本,目的 broker 的路径中创建 future Log
4.停止当前 Log 的清理工作,等待 future Log 同步完再清理
5.创建 ReplicaAlterLogDirsThread,逐个 topic 逐个 partition 获取 fetchOffset、 logStartOffset 、fetchSize 等数据构造 Fetch 请求
6.通过 ReplicaManager.fetchMessages 从分区副本 leader 获取数据,完成数据同步
更详细的处理流程如下图所示:
五、总结
Kafka 分区重分配,通过 kafka-reassign-partitions 启动任务,将任务记录在元数据管理器 ZooKeeper 中,Kafka controller 通过对 ZooKeeper 的监测,发现相关任务通过和 broker 的交互按序处理相关的迁移任务,同时 controller 实时维护 ZooKeeper 中的元数据信息并进行相关变化的记录,保证在重分配过程中,不影响 topic 分区的正常使用,在任务完成后,再由 controller 负责 ZooKeeper 中重分配任务标记的清理,以便客户端验证重分配任务的结果。
到此这篇关于Apache Kafka 分区重分配的实现原理解析的文章就介绍到这了,更多相关Apache Kafka 分区重分配内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!