协同过滤推荐ALS PySpark.mllib库
啥是协同过滤?
就是用户对所有产品打分,然后根据分数来给用户分组,那同一个组内的用户喜欢的东西应该是相似的。
其他的推荐算法例如内容推荐,就是先给产品分类(根据一些乱七八糟的),在将用户分类,然后把新来的产品(网页,东西)分类,在将这个产品推荐给感兴趣这个分类的用户。
协同过滤有啥优缺点
| 优点d |
缺点 |
|
1.没有历史数据的话,就没法分析(冷启动问题) 2. 对于新用户,如果他没评分,那他就没有分组,就没法发知道喜好 |
对于评分系统,那我们得到的数据就是这样的
| A | B | C | D | E |
|
| User1 | 2 | 1 | 5 | ||
| User2 | 1 | 3 | 1 | 1 | |
| User3 | 3 | 4 | |||
| User4 | 2 | 2 | 1 | 2 | |
| User5 | 1 | 1 | 1 | 4 | 1 |
随着数据越来越多,那就会有很多位置是空的,就会有稀疏矩阵, 稀疏矩阵过大浪费内存,处理就会很浪费时间
处理稀疏矩阵就需要矩阵分解:将原本A(m*n)的矩阵 分解成X(m*D)和Y(D*m),这样分解的A大概等于 X*Y
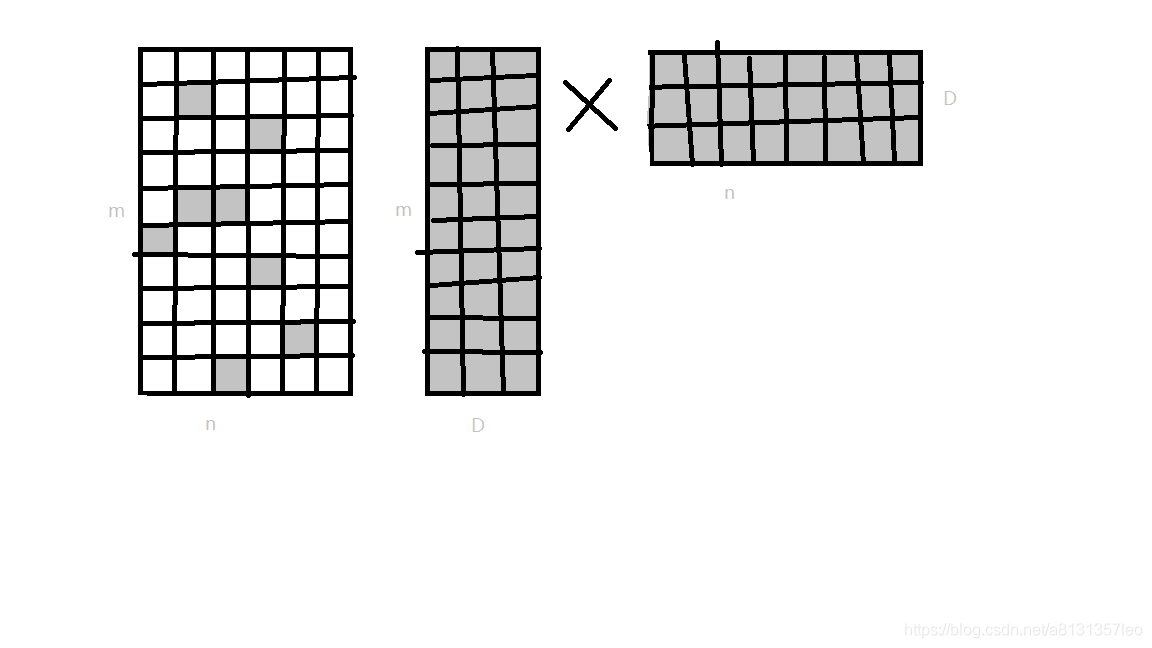
1.首先下载数据
https://grouplens.org/datasets/movielens/ 我用的是20M的
2.上传到HDFS上
![]()
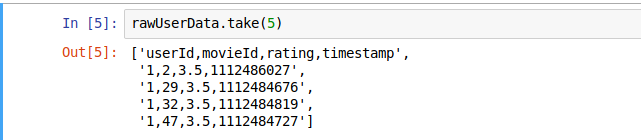
3.查看数据
4.提取Header
header = rawUserData.first()
rawUserData = rawUserData.filter(lambda x: x != header)
rawUserData.take(5)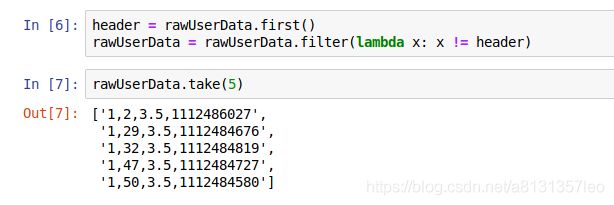
5.ALS算法训练使用 RatingRDD的数据结构, RatingRDD的数据结构为
Rating(user,product,rating), tuple格式
rawRatings = rawUserData.map(lambda line: tuple(line.split(",")[:3]))
rawRatings.take(5)
6. 训练模型
ALS分为两种训练模型, 显式评分(Explicat Rating),隐式评分(Implicit Rating)
#显式评分
ALS.train(ratings,rank,iteration=5,lambda_=0.01)
#隐式评分
ALS.trainImplicit(ratings,rank,iterations=5,lambda_=0.01)
ratings: RatingsRDD 数据结构
rank:当进行矩阵分解时,把原本矩阵 A(M*N) 分解成 X(M*rank) Y(rank*N)
iteration:ALS算法的迭代次数
lambda:正则化系数,越大方差越小偏差越大
7. 电影评价是显式评分 用ALS
model = ALS.train(rawRatings,10,iteration=5,lambda_=0,01)
给一个用户,预测他的推荐
model.recommendProduct(100,5)至于调参,就得自己写了