一、前言
这里主要讲springboot整合redis的个人搜索记录与热搜、敏感词过滤与替换两个功能,下面进行环境准备,引入相关maven依赖
org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-test test org.springframework.boot spring-boot-starter-data-redis 2.7.0 org.apache.commons commons-lang3 3.12.0
application.yml配置为
spring:
redis:
#数据库索引
database: 0
host: 192.168.31.28
port: 6379
password: 123456
lettuce:
pool:
#最大连接数
max-active: 8
#最大阻塞等待时间(负数表示没限制)
max-wait: -1
#最大空闲
max-idle: 8
#最小空闲
min-idle: 0
#连接超时时间
timeout: 10000
最后敏感词文本文件放在resources/static目录下,取名为word.txt,敏感词文本网上很多,这里就随便贴一个:github敏感词
二、不雅文字过滤
1、实现原理
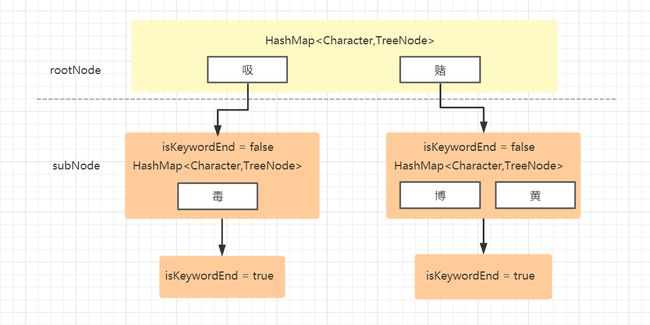
简单原理如下图所示,使用了DFA算法,创建结点类,里面包含是否是敏感词结束符,以及一个HashMap,哈希里key值存储的是敏感词的一个词,value指向下一个结点(即指向下一个词),一个哈希表中可以存放多个值,比如赌博、赌黄这两个都是敏感词。
2、实现方法
2.1 敏感词库初始化
敏感词库的初始化,这里主要工作是读取敏感词文件,在内存中构建好敏感词的Map节点
/**
* @author shawn
* @version 1.0
* @ClassName SensitiveWordInit
* Description:屏蔽一些无关紧要的警告。使开发者能看到一些他们真正关心的警告。从而提高开发者的效率
* 屏蔽敏感词初始化
* @date 2022/6/22 18:20
*/
@Configuration
@SuppressWarnings({ "rawtypes", "unchecked" })
public class SensitiveWordInit {
// 字符编码
private String ENCODING = "UTF-8";
// 初始化敏感字库
public Map initKeyWord() throws IOException {
// 读取敏感词库 ,存入Set中
Set wordSet = readSensitiveWordFile();
// 将敏感词库加入到HashMap中//确定有穷自动机DFA
return addSensitiveWordToHashMap(wordSet);
}
// 读取敏感词库 ,存入HashMap中
private Set readSensitiveWordFile() throws IOException {
Set wordSet = null;
ClassPathResource classPathResource = new ClassPathResource("static/word.txt");
InputStream inputStream = classPathResource.getInputStream();
//敏感词库
try {
// 读取文件输入流
InputStreamReader read = new InputStreamReader(inputStream, ENCODING);
// 文件是否是文件 和 是否存在
wordSet = new HashSet();
// StringBuffer sb = new StringBuffer();
// BufferedReader是包装类,先把字符读到缓存里,到缓存满了,再读入内存,提高了读的效率。
BufferedReader br = new BufferedReader(read);
String txt = null;
// 读取文件,将文件内容放入到set中
while ((txt = br.readLine()) != null) {
wordSet.add(txt);
}
br.close();
// 关闭文件流
read.close();
} catch (Exception e) {
e.printStackTrace();
}
return wordSet;
}
// 将HashSet中的敏感词,存入HashMap中
private Map addSensitiveWordToHashMap(Set wordSet) {
// 初始化敏感词容器,减少扩容操作
Map wordMap = new HashMap(wordSet.size());
for (String word : wordSet) {
Map nowMap = wordMap;
for (int i = 0; i < word.length(); i++) {
// 转换成char型
char keyChar = word.charAt(i);
// 获取
Object tempMap = nowMap.get(keyChar);
// 如果存在该key,直接赋值
if (tempMap != null) {
nowMap = (Map) tempMap;
}
// 不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
else {
// 设置标志位
Map newMap = new HashMap();
newMap.put("isEnd", "0");
// 添加到集合
nowMap.put(keyChar, newMap);
nowMap = newMap;
}
// 最后一个
if (i == word.length() - 1) {
nowMap.put("isEnd", "1");
}
}
}
return wordMap;
}
}
2.2 敏感词过滤器
敏感词过滤器,主要功能是初始化敏感词库,敏感词的过滤以及替换
/**
* @author shawn
* @version 1.0
* @ClassName SensitiveFilter
* Description:敏感词过滤器:利用DFA算法 进行敏感词过滤
* @date 2022/6/22 18:19
*/
@Component
public class SensitiveFilter {
/**
* 敏感词过滤器:利用DFA算法 进行敏感词过滤
*/
private Map sensitiveWordMap = null;
/**
* 最小匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国]人
*/
public static int minMatchType = 1;
/**
* 最大匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国人]
*/
public static int maxMatchType = 2;
/**
* 敏感词替换词
*/
public static String placeHolder = "**";
// 单例
private static SensitiveFilter instance = null;
/**
* 构造函数,初始化敏感词库
*/
private SensitiveFilter() throws IOException {
sensitiveWordMap = new SensitiveWordInit().initKeyWord();
}
/**
* 获取单例
*/
public static SensitiveFilter getInstance() throws IOException {
if (null == instance) {
instance = new SensitiveFilter();
}
return instance;
}
/**
* 获取文字中的敏感词
*/
public Set getSensitiveWord(String txt, int matchType) {
Set sensitiveWordList = new HashSet<>();
for (int i = 0; i < txt.length(); i++) {
// 判断是否包含敏感字符
int length = CheckSensitiveWord(txt, i, matchType);
// 存在,加入list中
if (length > 0) {
sensitiveWordList.add(txt.substring(i, i + length));
// 减1的原因,是因为for会自增
i = i + length - 1;
}
}
return sensitiveWordList;
}
/**
* 替换敏感字字符,使用了默认的替换符合,默认最小匹配规则
*/
public String replaceSensitiveWord(String txt) {
return replaceSensitiveWord(txt, minMatchType ,placeHolder);
}
/**
* 替换敏感字字符,使用了默认的替换符合
*/
public String replaceSensitiveWord(String txt, int matchType) {
return replaceSensitiveWord(txt, matchType,placeHolder);
}
/**
* 替换敏感字字符
*/
public String replaceSensitiveWord(String txt, int matchType,
String replaceChar) {
String resultTxt = txt;
// 获取所有的敏感词
Set set = getSensitiveWord(txt, matchType);
Iterator iterator = set.iterator();
String word = null;
String replaceString = null;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 获取替换字符串
*/
private String getReplaceChars(String replaceChar, int length) {
StringBuilder resultReplace = new StringBuilder(replaceChar);
for (int i = 1; i < length; i++) {
resultReplace.append(replaceChar);
}
return resultReplace.toString();
}
/**
* 检查文字中是否包含敏感字符,检查规则如下:
* 如果存在,则返回敏感词字符的长度,不存在返回0
* 核心
*/
public int CheckSensitiveWord(String txt, int beginIndex, int matchType) {
// 敏感词结束标识位:用于敏感词只有1的情况结束
boolean flag = false;
// 匹配标识数默认为0
int matchFlag = 0;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
char word = txt.charAt(i);
// 获取指定key
nowMap = (Map) nowMap.get(word);
// 存在,则判断是否为最后一个
if (nowMap != null) {
// 找到相应key,匹配标识+1
matchFlag++;
// 如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
// 结束标志位为true
flag = true;
// 最小规则,直接返回,最大规则还需继续查找
if (SensitiveFilter.minMatchType == matchType) {
break;
}
}
}
// 不存在,直接返回
else {
break;
}
}
// 匹配长度如果匹配上了最小匹配长度或者最大匹配长度
if (SensitiveFilter.maxMatchType == matchType || SensitiveFilter.minMatchType == matchType){
//长度必须大于等于1,为词,或者敏感词库还没有结束(匹配了一半),flag为false
if(matchFlag < 2 || !flag){
matchFlag = 0;
}
}
return matchFlag;
}
}
2.3 测试使用
最后进行测试,这里有两种方式可以获取,因为容器初始化时会默认执行无参构造
@RestController
public class SensitiveController {
private static Logger logger = LoggerFactory.getLogger(SensitiveController.class);
@Autowired
SensitiveFilter sensitiveFilter;
@GetMapping("/sensitive")
public String sensitive(String keyword){
String s = sensitiveFilter.replaceSensitiveWord(keyword);
return s;
}
// 两种方式都可以
public static void main(String[] args) throws IOException {
String searchKey = "傻逼h";
String placeholder = "***";
//非法敏感词汇判断
SensitiveFilter filter = SensitiveFilter.getInstance();
String s = filter.replaceSensitiveWord(searchKey, 1, placeholder);
System.out.println(s);
int n = filter.CheckSensitiveWord(searchKey,0,2);
//存在非法字符
if(n > 0){
logger.info("这个人输入了非法字符--> {},不知道他到底要查什么~ userid--> {}",searchKey,1);
}
}
}
三、Redis搜索栏热搜
1、前言
使用java和redis实现一个简单的热搜功能,具备以下功能:
- 搜索栏展示当前登陆的个人用户的搜索历史记录,删除个人历史记录
- 用户在搜索栏输入某字符,则将该字符记录下来 以zset格式存储的redis中,记录该字符被搜索的个数以及当前的时间戳 (用了DFA算法)
- 每当用户查询了已在redis存在了的字符时,则直接累加个数, 用来获取平台上最热查询的十条数据。(可以自己写接口或者直接在redis中添加一些预备好的关键词)
- 最后还要做不雅文字过滤功能。
代码实现热搜与个人搜索记录功能,主要controller层下几个方法就行了 :
- 向redis 添加热搜词汇(添加的时候使用下面不雅文字过滤的方法来过滤下这个词汇,合法再去存储
- 每次点击给相关词热度 +1
- 根据key搜索相关最热的前十名
- 插入个人搜索记录
- 查询个人搜索记录
2、代码实现
2.1 创建RedisKeyUtils 工具类
管理redis的键,防止太乱了
public class RedisKeyUtils {
/**
* 分隔符号
*/
private static final String SPLIT = ":";
private static final String SEARCH = "search";
private static final String SEARCH_HISTORY = "search-history";
private static final String HOT_SEARCH = "hot-search";
private static final String SEARCH_TIME = "search-time";
/**
* 每个用户的个人搜索记录hash
*/
public static String getSearchHistoryKey(String userId){
return SEARCH + SPLIT + SEARCH_HISTORY + SPLIT + userId;
}
/**
* 总的热搜zset
*/
public static String getHotSearchKey(){
return SEARCH + SPLIT + HOT_SEARCH;
}
/**
* 每个搜索记录的时间戳记录:key-value
*/
public static String getSearchTimeKey(String searchKey){
return SEARCH + SPLIT + SEARCH_TIME + SPLIT + searchKey;
}
}
2.2 核心搜索文件
两个文件是一起的
@Service("redisService")
public class RedisService {
private Logger logger = LoggerFactory.getLogger(RedisService.class);
/**
* 取热搜前几名返回
*/
private static final Integer HOT_SEARCH_NUMBER = 9;
/**
* 多少时间内的搜索记录胃热搜
*/
private static final Long HOT_SEARCH_TIME = 30 * 24 * 60 * 60L;
@Resource
private StringRedisTemplate redisSearchTemplate;
/**
* 新增一条该userid用户在搜索栏的历史记录
*/
public Long addSearchHistoryByUserId(String userId, String searchKey) {
try{
String redisKey = RedisKeyUtils.getSearchHistoryKey(userId);
// 如果存在这个key
boolean b = Boolean.TRUE.equals(redisSearchTemplate.hasKey(redisKey));
if (b) {
// 获取这个关键词hash的值,有就返回,没有就新增
Object hk = redisSearchTemplate.opsForHash().get(redisKey, searchKey);
if (hk != null) {
return 1L;
}else{
redisSearchTemplate.opsForHash().put(redisKey, searchKey, "1");
}
}else{
// 没有这个关键词就新增
redisSearchTemplate.opsForHash().put(redisKey, searchKey, "1");
}
return 1L;
}catch (Exception e){
logger.error("redis发生异常,异常原因:",e);
return 0L;
}
}
/**
* 删除个人历史数据
*/
public Long delSearchHistoryByUserId(String userId, String searchKey) {
try {
String redisKey = RedisKeyUtils.getSearchHistoryKey(userId);
// 删除这个用户的关键词记录
return redisSearchTemplate.opsForHash().delete(redisKey, searchKey);
}catch (Exception e){
logger.error("redis发生异常,异常原因:",e);
return 0L;
}
}
/**
* 获取个人历史数据列表
*/
public List getSearchHistoryByUserId(String userId) {
try{
List stringList = null;
String redisKey = RedisKeyUtils.getSearchHistoryKey(userId);
// 判断存不存在
boolean b = Boolean.TRUE.equals(redisSearchTemplate.hasKey(redisKey));
if(b){
stringList = new ArrayList<>();
// 逐个扫描,ScanOptions.NONE为获取全部键对,ScanOptions.scanOptions().match("map1").build() 匹配获取键位map1的键值对,不能模糊匹配
Cursor> cursor = redisSearchTemplate.opsForHash().scan(redisKey, ScanOptions.NONE);
while (cursor.hasNext()) {
Map.Entry map = cursor.next();
String key = map.getKey().toString();
stringList.add(key);
}
return stringList;
}
return null;
}catch (Exception e){
logger.error("redis发生异常,异常原因:",e);
return null;
}
}
/**
* 根据searchKey搜索其相关最热的前十名 (如果searchKey为null空,则返回redis存储的前十最热词条)
*/
public List getHotList(String searchKey) {
try {
Long now = System.currentTimeMillis();
List result = new ArrayList<>();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
Set value = zSetOperations.reverseRangeByScore(RedisKeyUtils.getHotSearchKey(), 0, Double.MAX_VALUE);
//key不为空的时候 推荐相关的最热前十名
if(StringUtils.isNotEmpty(searchKey)){
for (String val : value) {
if (StringUtils.containsIgnoreCase(val, searchKey)) {
//只返回最热的前十名
if (result.size() > HOT_SEARCH_NUMBER) {
break;
}
Long time = Long.valueOf(Objects.requireNonNull(valueOperations.get(val)));
//返回最近一个月的数据
if ((now - time) < HOT_SEARCH_TIME) {
result.add(val);
} else {//时间超过一个月没搜索就把这个词热度归0
zSetOperations.add(RedisKeyUtils.getHotSearchKey(), val, 0);
}
}
}
}else{
for (String val : value) {
//只返回最热的前十名
if (result.size() > HOT_SEARCH_NUMBER) {
break;
}
Long time = Long.valueOf(Objects.requireNonNull(valueOperations.get(val)));
//返回最近一个月的数据
if ((now - time) < HOT_SEARCH_TIME) {
result.add(val);
} else {
//时间超过一个月没搜索就把这个词热度归0
zSetOperations.add(RedisKeyUtils.getHotSearchKey(), val, 0);
}
}
}
return result;
}catch (Exception e){
logger.error("redis发生异常,异常原因:",e);
return null;
}
}
}
接上一个
@Service("redisService")
public class RedisService {
private Logger logger = LoggerFactory.getLogger(RedisService.class);
@Resource
private StringRedisTemplate redisSearchTemplate;
/**
* 新增一条热词搜索记录,将用户输入的热词存储下来
*/
public int incrementScoreByUserId(String searchKey) {
Long now = System.currentTimeMillis();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
List title = new ArrayList<>();
title.add(searchKey);
for (int i = 0, length = title.size(); i < length; i++) {
String tle = title.get(i);
try {
if (zSetOperations.score(RedisKeyUtils.getHotSearchKey(), tle) <= 0) {
zSetOperations.add(RedisKeyUtils.getHotSearchKey(), tle, 0);
valueOperations.set(RedisKeyUtils.getSearchTimeKey(tle), String.valueOf(now));
}
} catch (Exception e) {
zSetOperations.add(RedisKeyUtils.getHotSearchKey(), tle, 0);
valueOperations.set(RedisKeyUtils.getSearchTimeKey(tle), String.valueOf(now));
}
}
return 1;
}
/**
* 每次点击给相关词searchKey热度 +1
*/
public Long incrementScore(String searchKey) {
try{
Long now = System.currentTimeMillis();
ZSetOperations zSetOperations = redisSearchTemplate.opsForZSet();
ValueOperations valueOperations = redisSearchTemplate.opsForValue();
// 没有的话就插入,有的话的直接更新;add是有就覆盖,没有就插入
zSetOperations.incrementScore(RedisKeyUtils.getHotSearchKey(), searchKey, 1);
valueOperations.getAndSet(RedisKeyUtils.getSearchTimeKey(searchKey), String.valueOf(now));
return 1L;
}catch (Exception e){
logger.error("redis发生异常,异常原因:",e);
return 0L;
}
}
}
2.3 测试使用
以下只是简单的测试,上面的核心函数可以自己组合,一般组合加上敏感词过滤
@RestController
public class SearchHistoryController {
@Autowired
RedisService redisService;
@GetMapping("/add")
public String addSearchHistoryByUserId(String userId, String searchKey) {
redisService.addSearchHistoryByUserId(userId, searchKey);
redisService.incrementScore(searchKey);
return null;
}
/**
* 删除个人历史数据
*/
@GetMapping("/del")
public Long delSearchHistoryByUserId(String userId, String searchKey) {
return redisService.delSearchHistoryByUserId(userId, searchKey);
}
/**
* 获取个人历史数据列表
*/
@GetMapping("/getUser")
public List getSearchHistoryByUserId(String userId) {
return redisService.getSearchHistoryByUserId(userId);
}
/**
* 根据searchKey搜索其相关最热的前十名 (如果searchKey为null空,则返回redis存储的前十最热词条)
*/
@GetMapping("/getHot")
public List getHotList(String searchKey) {
return redisService.getHotList(searchKey);
}
}
参考文章
Redis6.0学习笔记
到此这篇关于SpringBoot 热搜与不雅文字过滤的实现的文章就介绍到这了,更多相关SpringBoot 热搜与不雅文字过滤内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!