集群计算——Spark-Spark Core 、Spark Streaming、Spark SQL、MLlib、Spark集群管理器
Spark发源于美国美国加州伯克利分校AMPLab的大数据分析平台,它立足于于内存计算,从多迭代批量处理出发,兼顾数据仓库、流处理和图计算等多种计算范式,是大数据系统邻域的全栈计算平台。Spark当下成为Apache基金会的顶级开源项目。
Spark扩展了MapReduce计算模型,并且高效的支持更多的计算模式。由于速度很快,这意味着可以交互式的数据操作(否则每次操作就需要等待数分钟甚至数个小时)。Spark基于内存计算,提高了在大数据环境下处理的实时性,因而更能体现速度上的优势。该框架对资源调度,任务的提交、执行和跟踪节点间的通信以及数据并行处理的内在底层操作都进行了抽象。它提供了一个更高级别的API用于处理分布式数据。从这方面说,它与Apache Hadoop等分布式处理框架类似,但在底层架构上,Spark 又与它们有所不同。本节主要对概念和原理进行了简单的介绍与讨论,帮助读者更好地理解Spark的相关知识。
7.1.1 Spark 简介
Spark是由一个强大而活跃的开源社区开发和维护的,日前已经成为Apache 软件基金会
旗下的顶级开源项目。Spark 起源初期,加州大学伯克利分校正关注分布式机器学习算法的
应用情况,因此,Spark从一开始便为应对迭代式应用的高性能需求而设计。在这类应用
中,相同的数据会被多次访问。该设计主要利用数据集的内存缓存以及启动任务时的低延
迟和低系统开销来实现高性能。再加上其容错性、灵活的分布式数据结构和强大的函数式
编程接口,Spark 在各类基于机器学习和迭代分析的大规模数据处理任务上有广泛的应用,
也表明了其实用性。
下面是Spark1. 2. 0版本前的发展历程。
●2009年:由Berkeley's AMPLab开始编写最初的源代码。
●2010年:开放源代码。
●2013年6月: Apache孵化器项目。
●2014年2月:Apache顶级项目。
●2014年2月:大数据公司Cloudera宣称加大Spark框架的投入来取代MapReduce。
●2014年4月:大数据公司MapR投人Spark阵营,使用Spark 作为计算引擎。
●2014年5月: Pivotal Hadoop集成Spark全栈。
●2014年5月30日: Spark 1.0.0发布。
●2014年6月: Spark 2014峰会在旧金山召开。
●2014年7月: Hive on Spark项目启动。
●2014年12月:Spark1.2.0发布
Spark项目包含多个紧密集成的组件。 Spark的核心是一个计算机引擎,它对由很多计算任务组成的、运行在多个工作机器或者是一个计算机集群上的应用,进行调度、分发以及监控。
目前AMPLab和Databricks负责整个项目的开发维护,另外很多公司,如Yahoo、Intel 等也参与到Spark的开发中,同时很多开源爱好者也积极参与Spark的更新与维护。AMPLab开发以Spark为核心的数据分析栈时提出的目标是: one stack to nule thern all,也就是说在一套软件栈内完成各种大数据分析任务。相较于MapReduce上的批量计算、迭代型计算以及基于Hive的SQL 查询,Spark可以带来上百倍的性能提升。目前Spark的生态系统日趋完善,Spark SQL的发布、Hive on Spark项目的启动以及大量大数据公司对Spark全栈的支持,让Spark的数据分析范式更加丰富。
Spark的核心引擎速度快且通用,支持为各种不同应用场景专门涉及的高级组件,比如和机器学习等。这种组件间密切的涉及原理有很多的优点:首先,软件栈中所有的程序库高级组件都可从下层的改进中获益;其次,运行整个软件栈代价减小,一个机构只需一 套软社系统即可,省去了系统部署、维护、测试等成本;最后,可以构建出无缝整合不同处理模型的应用。
Spark生态圈以Spark Core为核心 MESS YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序计算。这些用程序可以来自不同的组件,如spark shell/Spark Submit的批处理,Spark Streaming的实时处理应用、Spark SQL的实时查询、BinKDB的权衡查询、MLlib/MILbase的机器学习、GraphX的图处理和SparkR的数学计算等。
一. Spark Core
实现Spark的基本功能,如任务调度、内存管理、错误恢复与存储系统交互等模块。Spark Core还包括对弹性分布式数据集(RDD)的API(一些预先定义的接口)定义。RDD是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,RDD可以看作是Spark的一个对象,它本身运行与内存中,是spark主要的编程对象。Spark Core提供了创建和操作这些集合的多个API。RDD表示只读分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs 之间存在依赖关系) RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
RDD基本概念
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算
RDD 具有容错机制,并且只读不能修改,可以执行确定的转换操作创建新的 RDD。具体来讲,RDD 具有以下几个属性。
只读:不能修改,只能通过转换操作生成新的 RDD。
分布式:可以分布在多台机器上进行并行处理。
弹性:计算过程中内存不够时它会和磁盘进行数据交换。
基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
RDD 实质上是一种更为通用的迭代并行计算框架,用户可以显示控制计算的中间结果,然后将其自由运用于之后的计算。
在大数据实际应用开发中存在许多迭代算法,如机器学习、图算法等,和交互式数据挖掘工具。这些应用场景的共同之处是在不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。
RDD 正是为了满足这种需求而设计的。虽然 MapReduce 具有自动容错、负载平衡和可拓展性的优点,但是其最大的缺点是采用非循环式的数据流模型,使得在迭代计算时要进行大量的磁盘 I/O 操作。
通过使用 RDD,用户不必担心底层数据的分布式特性,只需要将具体的应用逻辑表达为一系列转换处理,就可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 I/O 和数据序列化的开销。这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。
RDD 基本操作
RDD 的操作分为转化(Transformation)操作和行动(Action)操作。转化操作就是从一个 RDD 产生一个新的 RDD,而行动操作就是进行实际的计算。
RDD 的操作是惰性的,当 RDD 执行转化操作的时候,实际计算并没有被执行,只有当 RDD 执行行动操作时才会促发计算任务提交,从而执行相应的计算操作。
参考:
Spark RDD是什么?_大数据基础学习-CSDN博客_rdd
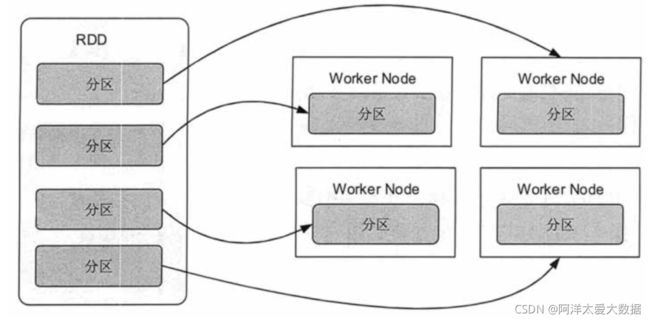
1.分区
RDD在逻辑上是分区的,每个分区的数据都是抽象存在的,它在计算时会通过一个 Compute 函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则Compute函数读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则Compute函数执行转换逻辑将其他RDD的数据进行转换。
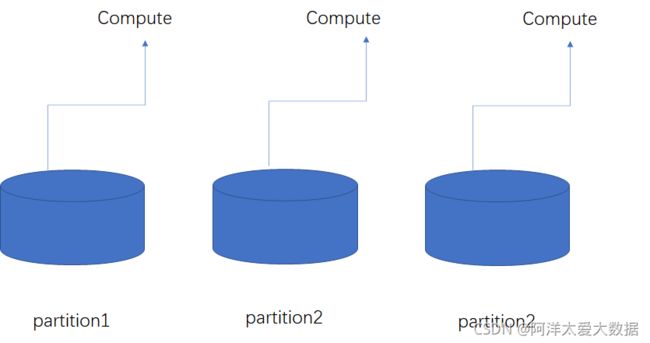
2.只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce函数了。
RDD的操作算子包括两类,一类叫transformation,它用来将RDD进行转化,构建RDD的血缘关系;另一类叫做action,用来触发RDD计算,得到RDD的相关计算结果或者将RDD保存到文件系统中。
转化(Transformation)操作:
RDD 的转换操作是返回新的 RDD 的操作。转换出来的 RDD 是惰性求值的,只有在行动操作中用到这些 RDD 时才会被计算。
许多转换操作都是针对各个元素的,也就是说,这些转换操作每次只会操作 RDD 中的一个元素,不过并不是所有的转换操作都是这样的。表 1 描述了常用的 RDD 转换操作
行动(Action)操作:
行动操作用于执行计算并按指定的方式输出结果。行动操作接受 RDD,但是返回非 RDD,即输出一个值或者结果。在 RDD 执行过程中,真正的计算发生在行动操作。表 2 描述了常用的 RDD 行动操作。

3.依赖
RDDs通过操作算子进行转换,转换得到新的RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。依赖包括两种:一种是窄依赖,RDDs之间分区是一一对应的;另一种是宽依赖,下游RDD的每个分区与上游RDD(父RDD)的每一个分区都有关,是多对多的关系。通过RDDs之间的这种依赖关系,一个任务流可以描述为DAG(有向无环图),在实际执行过程中宽依赖对应于Shuffle(图中的reduceByKey和join);窄依赖中的所有转换操作,可以通过类似于管道的方式一气呵成执行(图中的map和union可以一一起执行)
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
park是分布式计算,其数据也是分布式的,即所计算的数据可能分为好多个块。有些计算对数据的操作相对简单,即某一块儿的数据处理不需要涉及到其他块的数据,就是对本块数据处理完可以直接输出到下一个数据块,中间不需要更多的过程参与。比如map()算子,本身就是对每个数据进行循环处理,一条数据基本上对应一条输出结果,继而一个数据块儿也是对应的输出一个数据块儿。即父数据块的结果只输出到一个子数据块儿中,这就是所说的窄依赖。如下图所示:
上面三个图中,可以看到父块的数据经过算子处理后都输出到了唯一的子块儿,每一个父块儿数据的产生不需要和其他父块儿的数据进行运算和操作,直接输出到子块儿中。像上图中的map,filter,union都是窄依赖操作的算子,foreach也是,只不过他不会产生下一个rdd,即没有返回值。而join操作可能是窄依赖,就需要看这个join对数据的操作符不符合上面所说的现象,否则就不是窄依赖。
上面说了窄依赖,与其对应的就是宽依赖。宽依赖中,父数据块中的数据会经过处理后会输出到多个子数据块儿。
一个父块儿对应多个子块儿的输出,举个例子:假设有两个数据块,一个数据块中有(one,tow)两个单词,两外一个数据块儿中有(one,tow)两个单词,现在我们需要对这两个块儿的数据进行groupByKey的操作,那么数据的输出结果是两个数据块,one一个,two一个。这个可以看到每个父块儿都需要把自己的数据输出到不同的子块儿之中,这就是宽依赖。
其实更进一步说,宽依赖的实质,就是发生了shffule操作,计算过程中,需要将不同数据块儿的数据先综合一下,进行相关的计算之后,然后再输出到对应的数据块儿中。
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算(属于其他RDD分区的也被计算了);更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。参考:
Spark的宽依赖和窄依赖_things_use的博客-CSDN博客_spark 宽依赖算子
Spark 中的宽依赖和窄依赖_shangpengyu-CSDN博客


4.缓存
如果在应用程序中多次使用同一个RDD,则可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据, 在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关计算,这样就加速了后期的重用。
5.checkpoint (检查站)
RDD的血缘关系天然地可以实现容错,虽然当RDD的某个分区数据失败或丢失时,可以通过血缘关系重建,但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,- - 且在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint 后的RDD 不需要知道它的父RDDS了,它可以从checkpoint处拿到数据。
二. Spark Streaming

Spark Streaming是一个 对实时数据进行高通量、容错处理的流式处理系统,例如生产环境中的Web服务器日志文件(例如Apache Flume和HDFS/S3)、社交媒体数据( 例如Twitter)和各种消息队列中(例如Kafka)的实时数据。在引擎内部,Spark Streaming接收输人的数据流,与此同时将数据进行切分,形成数据片段(Batch), 然后交由Spark引擎处理,按数据片段生成最终的结果流。

流式计算
1.什么是流?
Streaming:是一种数据传送技术,它把客户机收到的数据变成一个稳定连续的
流,源源不断地送出,使用户听到的声音或看到的图象十分平稳,而且用户在
整个文件送完之前就可以开始在屏幕上浏览文件。2.常见的流式计算框架
Apache Storm
Spark Streaming
Apache Samza上述三种实时计算系统都是开源的分布式系统,具有低延迟、可扩展和容错性
诸多优点,它们的共同特色在于:允许你在运行数据流代码时,将任务分配到
一系列具有容错能力的计算机上并行运行。此外,它们都提供了简单的API来
简化底层实现的复杂程度。
Spark Streaming API与Spark Core紧密结合,使得开发人员可以轻松的同时驾驭批处理和流数据
三. Spark SQL
Spark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,可以使用SQL或者Apache Hive版本的SQL语言(HQL) 来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。除了为Spark提供了一一个SQL接口,Spark SQL允许开发人员直接处理RDD,同时也可查询在Apache Hive上存在的外部数据。Spark SQL的一个重要特点就是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。除了Spark SQL外,Catalyst 优化框架允许Spark SQL自动修改查询方案,使得SQL更有效地执行。
在SparkSQL之前,加州大学伯克利分校曾经尝试修改Apache Hive以使其运行在Spark上,当时的项目叫作Shark。现在,由于Spark SQL与Spark引擎和API的结合更紧密,Shark已经被Spark SQL取代。
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
有多种方式去使用Spark SQL,包括SQL、DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点,看你喜欢那种风格。
DataFrame
DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
DataFrame与RDD的区别RDD可看作是分布式的对象的集合,Spark并不知道对象的详细模式信息,DataFrame可看作是分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。DataFrame和普通的RDD的逻辑框架区别如下所示
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。
而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。这样看起来就像一张表了,DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where ...)。
DataFrame与RDD的优缺点
RDD的优缺点:
优点:
(1)编译时类型安全
编译时就能检查出类型错误
(2)面向对象的编程风格
直接通过对象调用方法的形式来操作数据
缺点:
(1)序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
(2)GC的性能开销
频繁的创建和销毁对象, 势必会增加GC
DataFrame通过引入schema和off-heap(不在堆里面的内存,指的是除了不在堆的内存,使用操作系统上的内存),解决了RDD的缺点, Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了;通过off-heap引入,可以快速的操作数据,避免大量的GC。但是却丢了RDD的优点,DataFrame不是类型安全的, API也不是面向对象风格的。
参考:Spark计算引擎之SparkSQL详解_林夕-CSDN博客_sparksql

四. MLlib
Spark中还包含一个提供常见的机器学习(ML) 功能的程序库,MLib 提供了多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导人等额外的支持功能。此外,MLlib 还提供了一些更底层的机器学习原语,包括一个 通用的梯度下降优化方法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。在高层次上,它提供了如下工具。
1) ML算法:通用学习算法,如分类、回归、聚类和协同过滤、特征提取、转换、降维和选择。
2)管道:用于构建、评估和调整ML管道的工具。
3)持久性:保存和加载算法,模型和管道。
4)实用程序:线性代数、统计、数据处理等。
五.spark 集群管理器
Spark的集群管理器大致有三种:一种是自带的Standalone独立集群管理器;一种 是依赖于Hadoop的资源调度器YARN;还有一种是Apache项目的Mesos集群管理器。Spark 依赖于集群管理器来启动Executor节点,有时候也会依赖集群管理器来启动Driver节点。集群管理器是Spark中的可插拔式组件。
在集群管理器中有主节点(Master) 和从节点(Slave) 的概念,这和Driver节点以及Ex-ecutor节点是完全不同的概念。Master节点主要负责集群管理器中接受客户端发送的应用,负责资源的调度以及跟踪从节点的运行状况等。Slave 节点主要负责启动-些任务进程,提供应用执行需要的文件和资源等。也就是说,Driver 和Executor 是要运行在Slave节点上的。比如YARN, Master 节点是资源管理( Resource Manager),Slave 节点是节点管理( Node Manager),当用户提交应用到YARN上时,Resource Manager会在一一个Node Manager 中启动Driver节点,Driver节点启动后会向Resource Manager注册,并申请资源,然后在其他的Node Manager 中启动相应的Executor节点来执行相应的任务。