双流网络泛读【Two-Stream Convolutional Networks for Action Recognition in Videos】
目录
0、前沿
1、标题
2、摘要
3、结论
4、重要图表
5、解决了什么问题
6、采用了什么方法
7、达到了什么效果
0、前沿
泛读我们主要读文章标题,摘要、结论和图表数据四个部分。需要回答用什么方法,解决什么问题,达到什么效果这三个问题。 需要了解更多视频理解相关文章可以关注我们视频理解系列目录了解我们当前更新情况。
1、标题
Two-Stream Convolutional Networks for Action Recognition in Videos
基于双流卷积的视频动作识别
2、摘要
We investigate architectures of discriminatively trained deep Convolutional Networks (ConvNets) for action recognition in video. The challenge is to capture the complementary information on appearance from still frames and motion between frames. We also aim to generalise the best performing hand-crafted features within a data-driven learning framework.
我们研究了视频动作识别领域训练的不同深度卷积网络。
发现主要的挑战在于捕捉静止帧中appearance和帧间的motion。
我们也希望建设一个能与最好的手工特征性能相当地数据驱动学习的框架。
Our contribution is three-fold. First, we propose a two-stream ConvNet architecture which incorporates spatial and temporal networks. Second, we demonstrate that a ConvNet trained on multi-frame dense optical flow is able to achieve very good performance in spite of limited training data. Finally, we show that multitask learning, applied to two different action classification datasets, can be used to increase the amount of training data and improve the performance on both.Our architecture is trained and evaluated on the standard video actions benchmarks of UCF-101 and HMDB-51, where it is competitive with the state of the art. It also exceeds by a large margin previous attempts to use deep nets for video classification.
论文的三个贡献。
第一,我们提出了一个包含时空网络的双流网络。
第二,在多帧密集光流上训练的卷积网络能够在训练数据有限的情况下取得非常好的性能。
第三,应用于两个不同动作分类数据集的多任务学习,可以增加训练数据的数量,同时改善在两个数据上的的表现。
我们在UCF-101和HMDB-51数据集上的表现和SOTA差不多,在视频分类领域远超以前的deep nets。
3、结论
We proposed a deep video classification model with competitive performance, which incorporates separate spatial and temporal recognition streams based on ConvNets. Currently it appears that training a temporal ConvNet on optical flow (as here) is significantly better than training on raw stacked frames [14]. The latter is probably too challenging, and might require architectural changes (for example, a combination with the deep matching approach of [30]). Despite using optical flow as input, our temporal model does not require significant hand-crafting, since the flow is computed using a method based on the generic assumptions of constancy and smoothness.
我们提出了一种在视频分类上表现很好的深度学习模型,模型基于卷积网络实现,融合了独立时空流识别流。从我们的实验来看,在光流上训练时间卷积神经网络明显优于在原始堆叠帧的方法上训练。原始堆叠帧的方法可能太具挑战性,可能需要修改网络结构(例如,结合[30]的深度匹配的方法)。尽管使用光流作为输入,我们的时间模型并不需要大量的手工工作,因为光流计算是使用的恒定和平滑的一般假设。
As we have shown, extra training data is beneficial for our temporal ConvNet, so we are planning to train it on large video datasets, such as the recently released collection of [14]. This, however, poses a significant challenge on its own due to the gigantic amount of training data (multiple TBs).
正如我们所示,额外数据有益时间流网络,但训练成本很高。
There still remain some essential ingredients of the state-of-the-art shallow representation [26], which are missed in our current architecture.
The most prominent one is local feature pooling over spatio-temporal tubes, centered at the trajectories. Even though the input (2) captures the optical flow along the trajectories, the spatial pooling in our network does not take the trajectories into account.
Another potential area of improvement is explicit handling of camera motion, which in our case is compensated by mean displacement subtraction.
仍然有些shallow的sota,没有融合到我们框架。
最明显就是在时空维度上以轨迹为中心的局部特征。我们只使用了光流,没有考虑轨迹。
另外一个改进是相机抖动,我们使用的平均位移减法来补偿(mean displacement subtraction)。
4、重要图表
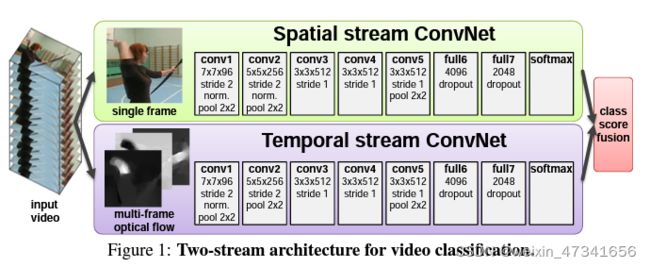
图1: 双流网络结构,Spatial stream ConvNet和Temporal stream ConvNet最后将分类分数fusion。
Spatial stream ConvNet:输入为单帧图片,网络结构为 5conv+2fc+softmax
Temporal stream ConvNet:输入为多帧光流,网络结构为 5conv+2fc+softmax

图2:光流
(a)(b):在一对连续的视频帧,用青色矩形框出移动的手周围的区域
(c):矩形框中的密集光流
(d):水平位移分量![]()
(e):垂直位移分量![]()
Temporal stream ConvNet 包含多个光流作为一次输入

图3:时间卷积的多帧光流输入
左侧:光流堆叠,对多帧中同一位置的d进行采样。
右侧:路径堆叠,沿着轨迹对矢量进行采样。
图中帧和位移向量使用了相同的颜色标记

表1:UCF101上单卷积表现
(a)空间流,dropout ration = 0.5时,pre-trained + last layer;dropout ration = 0.9时,pre-trained + fine-truning;
(b)时间流,optical flow stacking > trajectory stacking,mean subtraction on>off

表2:HMDB51时间流上的表现,Muti-task learning表现最好

表3:单向+多任务,late fusion中svm最好
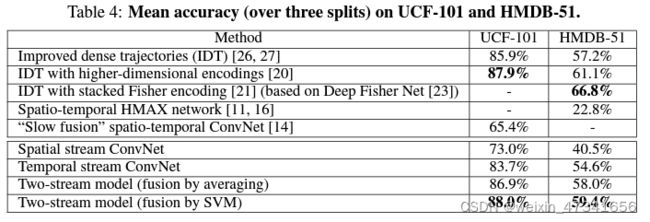
表4:UCF101,HMDB51平均精度
双流的准确率和手工特征表现相当
5、解决了什么问题
视频中的动作识别
6、采用了什么方法
采用双流网络结构
7、达到了什么效果
取得和手动和浅层学习相当的效果