读论文《Learning to Measure Changes: Fully Convolutional Siamese Metric Networks for Scene Change Detec》
Learning to Measure Changes: Fully Convolutional Siamese Metric Networks for Scene Change Detection
学习量测变化:用于场景变化检测的全卷积孪生度量网络
摘要
场景变化检测的一个关键挑战是:由不同光照、阴影和相机视角形成的噪声变化与语义变化纠缠,使得场景的方差难以定义和量测。按照“直接比较一对特征的差异来检测变化”的想法,我们提出了一个全卷积孪生度量网络(CosimNet),通过自定义的隐式度量来量测变化。为了学到更多的鉴别性指标,我们利用对比度损失函数来减小不变特征间的距离、扩大变化特征间的距离。具体来说,为了解决大视角差异的问题,我们提出了阈值对比损失函数(TCL),以更具容忍性的策略来惩罚噪声变化。我们在三个有挑战性的数据集(CDnet, PCD2015 和 VL-CMU-CD)上进行了实验,证明了该方法的有效性。我们的方法在许多有挑战性的条件下具有鲁棒性,如光照变化、相机运动和缩放造成的大视角差异。此外,我们将距离度量纳入分割框架,并通过可视化的变化图和特征分布来验证其有效性。源码地址为: https://github.com/gmayday1997/ChangeDet
关键词:变化检测,孪生网络,距离度量学习,量测变化
一、引言
当一个人被要求来确定同一场景在不同时间的变化时,自然要基于像素级别比较一对图像,然后根据语义不同推断场景的变化。当前最先进的场景变化检测算法差不多是基于全卷积网络(FCN),但这并不直观,因为基于FCN的网络检测变化是通过学习一个范围最大化的决策边界,而不是直接量测差异性或变化。
不同于简单的全变化检测分类,我们力求提出一种新的近于直接测量一组不同时相影像的差异性或变化的方法。这种思想背后的核心观念是认为变化就是差异。此外,为了实现这一目标,需要回答一个核心的问题:如何定义一个差异函数来衡量或测量变化?
从变化的角度上,它包含了感兴趣变化(即语义变化)和不必要的变化(即噪声变化)。给定一对图像,变化检测旨在于识别不同时相的语义变化。然而,这项任务的关键在于,由其他因素(如光照、阴影、相机视角)造成的噪声变化很难和语义变化区分开,由于语义变化与噪声变化纠缠,变化难以定义和测量。直观地说,如果想要探查语义变化并抑制噪声变化,一种可行的方法是学习更多的差异性度量特征来量测变化,并给语义变化更高的量测值,给噪声变化或无变化更低的量测值。
如上所述,解决该问题的方法是制定一个判别度量来区分语义变化和噪声变化。然而,得到一个明确的度量函数很难。近期,深层度量学习已成为计算机视觉任务中学习更多区别性特征的一项关键因素,例如面部识别和特征学习。其核心思想是鼓励降低类内方差和增强类间差异。这种学习策略提供了一个可行性的方案,即我们可以通过深层神经网络作为一个近似来学习这种隐式度量。具体来说,我们将一对图像相同位置的变化区域定义为变化对,即深层度量学习中的正例,不变的区域称为不变对,即反例。从深层度量学习上,我们尝试学习到一种基于距离的隐式度量,这种距离在不变对上尽可能小,在变化对尽可能大。
在我们的研究中,我们提出了一种新的变化检测框架,命名为全卷积孪生度量网络(CosimNet)。不同于简单的分类,我们利用的是通过制定一个有区别的隐式度量来直接对比一组图像的直观想法。它包含了两个部分:通过全卷积孪生网络(FCSN)提取的深层特征和预定义的距离度量。所有的过程可以看做是直接在原始影像上学习一个差异性函数。我们的方法在许多有挑战性的条件下都是有鲁棒性的,如光照变化和视角差异。更多例子如图1所示。
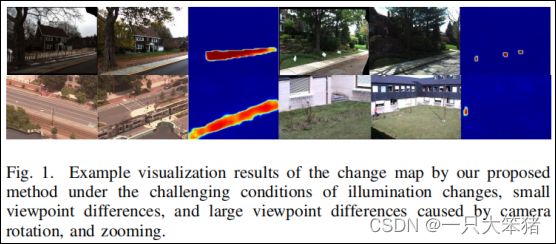
图1 我们提出的方法在各种挑战性条件下的变化图可视化结果示例,分别为:光照变化、小视角差异、由相机转动造成的大视角差异以及变焦。
我们的主要贡献如下:
(1)我们提出了一个新的基于深层度量学习的场景变化检测方法,它可以使用学到的隐式度量直接量测变化,将变化检测任务转化为一个隐式度量学习问题。据我们所知,这是通过端到端的深层度量学习来解决许多挑战性问题的统一体系的首次提出,特别是针对视角差异大的情况。
(2)我们开发了阈值对比损失函数(TCL)用于克服由较大的相机视野变化产生的噪声变化,这是一个显著的改进。更多细节将在第五节A部分说明。
(3)与基线方法相比,本文方法在PCD2015和VL-CMU-CD数据集上均有优异的表现,在CDnet数据集上也有较好表现。
(4)遵循学习一个更有鉴别力的特征的想法,基于FCN架构,我们将距离度量整合到基线中,使模型性能更好。我们也从变化图的可视化结果中找到了一个合理的解释。
二、研究现状
场景变化检测(SCD)是计算机视觉领域的一项基础任务。场景变化检测的核心思想是检测相同场景不同时间的多景影像的变化。变化的定义可以分为语义变化和噪声变化,语义变化可以定义为场景由于事物的消失、重建造成的变化,例如建筑物重建和车辆运动;在各种挑战性因素影响下,噪声变化划分为辐射变化(光照、阴影和季节变化)和几何变化(相机转动和变焦导致的视角变化)。显然,相比噪声变化,我们对语义变化更感兴趣。然而,噪声变化明显会影响图像的表现,这会导致“语义融合”,尤其是在巨大的视角差异条件下。如何正确检测语义变化并压制招生变化在这个任务中仍是一个挑战。
最传统和经典的场景变化检测方法是图像差分,具体是通过识别两个影像中“显著差异”的像素集生成变化图,然后通过阈值化获得一个二值掩膜。该方法的优点是计算成本小,缺点是原始RGB特征不能有效区分语义变化和噪声变化。为了获得更多鉴别性的特征,图像定量、变化向量分析、马尔可夫随机场和字典学习等方法被用于解决此问题。然而,受限于手工特征的标识,传统方法仍然对包括光照变化或视角差异在内的噪声变化非常敏感。
近年来,卷积神经网络框架在计算机视觉任务中有卓越的表现,几乎所有先进的变化检测方法都是基于全卷积网络(FCN),这是因为稠密预测任务的精度较高。此外,如图2所示,基于FCN的场景变化检测方法可以分为早期融合和晚期融合,它们都是通过学习到一个决策边界来表示检测到的变化。然而,学习一个决策边界仍然不能回答三个关键问题:(1)什么是变化?(2)怎样量测变化?(3)是否存在一个适合测量变化的度量方法,对变化有更高的测量值,对未变化的测量值更低?
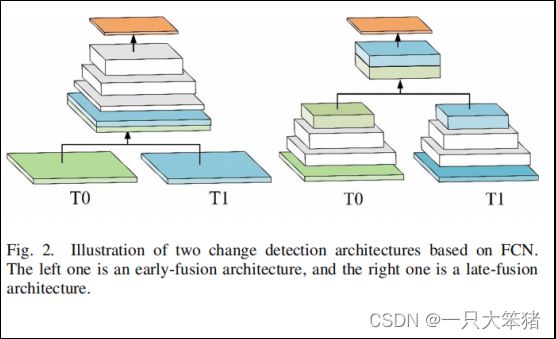
图2 两个基于FCN的变化检测架构图。左图为早期融合结构,右图为晚期融合结构。
为了解决这些问题,我们提出了一个新的检测变化的方法,它将变化视为语义的相似度,直接通过距离度量变化,旨在学习更有效的特征来区分变化和未变化。我们的工作是基于[3]中提出的想法,它同样使用距离度量来描述变化。然而,[3]中的方法使用VGG模型提取预训练特征,没有微调学习,这些特征没有足够的鉴别性,不足以描述变化。与此相反,我们提出了一个端到端的可训练方法来学习鉴别性特征,并采用了对比损失函数,该方法为场景变化检测任务制定了更强的特征。与我们工作相关的是,它也使用了对比损失函数。除此之外,我们提出了一个联合的方法应对更有挑战性的情况,例如使用阈值对比损失函数来克服更大的视角差异。
三、本文提出的方法
A.概述
这一节中,我们将阐述所提出的方法CosimNet,展示如何使用一个合适的度量来测量变化。如图3所示,原始图像首先输入到一个全卷积孪生网络中生成特征对,然后,我们采用一个简单的预定义距离度量,例如欧几里得距离或余弦相似度,来生成变化图。变化图的值为0-1,表示了变化的可信度。我们定义相同位置的图像中的变化区域为变化对,相同位置重叠图像中的不变区域为不变对。如上述所言,我们将包含深层特征和预定义距离度量的可用于量测变化的联合方法命名为隐式度量。因此,关键在于制定一个合适的度量,给变化对赋予高距离值,给不变对赋予低距离值。为了实现这个目标,利用对比损失函数将不变对拉近、将变化对分离。此外,还提出了阈值对比损失函数来解决大视角差异带来的挑战。下一节将讨论第三节B部分和C部分中具有损失函数的隐式度量和度量学习的更多细节。
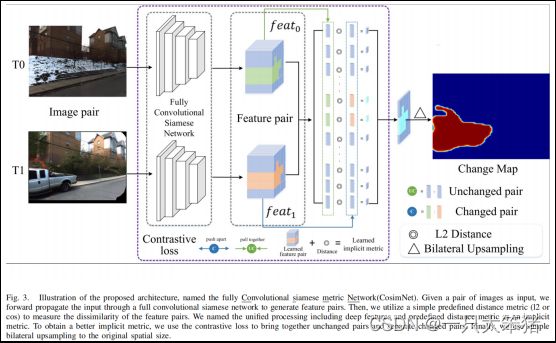
图3 CosimNet架构说明
给定一对输入影像,通过前向传播通过全卷积孪生网络得到特征对,然后利用简单预定义距离度量来量测特征对的相异性。我们将包含深层特征和预定义的距离度量的统一处理命名为隐式度量。为了获得更好的隐式度量,我们使用对比损失函数将不变对聚合、将变化对分离。最终,我们使用简单上采样还原成原始大小。
B.隐式度量学习
遵循将变化视为相异性的思想,我们基于直接对比和测量不同时间的影像对的相异性来检测变化。很显然,我们工作的关键要素是如何制定一个合适的距离度量来量测相异性或变化。通常,相异函数包含两部分:特征描述(如HOG)和距离度量(如欧式距离、马氏距离)。然而,它仍受到视角差异或光照变化的影响。
为了突破这个限制,我们采用深层卷积网络来学习更多鉴别性特征,特别是孪生网络。孪生网络被广泛应用于多种视觉任务中,例如补丁匹配、流量估计、目标跟踪和人脸识别。具体来说,孪生网络包括两个共享权重的卷积结构分枝,孪生网络的骨干可以是任何流行的架构,例如GoogleNet或者DeepLab。孪生网络的基本能力是将图像映射成特征对。为了度量特征对的相异性,我们首先将这个嵌入约束在C维超球面上,然后在规范化特征上建立一个简单的预定义度量。
最常用的预定义距离函数是欧几里得距离和余弦相似度。选择一个适合的距离度量取决于相应的任务,距离度量会严重影响模型的性能。例如,人脸识别通常使用欧几里得距离,而余弦相似度适合用于文本处理任务。在我们的工作中,我们设计了对上述两种距离度量函数的对比实验,并提供了对比敏感指标的定量分析,名为RMS对比。更多细节见V.B。
C.区别度量学习
1)对比度损失
如上所述,如何学习一个有判别力的度量来在这个任务中取得突出的表现是我们工作的另一核心价值(判别力指的是给变化对赋高值和给不变对赋低值)。以此想法为目标,我们采用对比度损失来监督CosimNet,旨在增大类间差异并同时减小类内差异,从而学习到一个良好的隐式度量。对比度损失的公式如下:
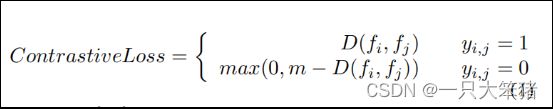
式中fi,fj是从特征对相同位置提取的特征向量,D(fi,fj)是fi和fj的欧几里得距离。y(i,j) = 1表示该处无变化,此时,损失函数试图使fi和fj的距离最小。,y(i,j) = 0表示该位置处发生变化,使距离m大于边缘处。此外,余弦相似性的公式如下:
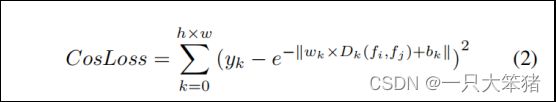
式中Dk(fi, fj)是特征向量fi与fj的余弦相似性,wk和bk 是可学习的缩放和平移参数。
2)阈值对比度损失
我们的目标是在任何挑战性的外部条件影响下都能稳健地量测变化,尤其是在相机转动、变焦造成的大视角差异情况。在这种情况下,原有的对比损失函数存在优化过程中表现不佳、收敛速度慢等缺点。主要原因是以下两个矛盾点的存在:一方面,由于严重的不配准,大的视角差异很容易引入很多无关信息,不变对和变化对的纠缠必然导致“语义融合”;另一方面,传统的对比度损失函数旨在使从包含大视角差异的原始数据提取的特征对到0的距离最小化,这有助于0预测表现出较好的性能。
导致矛盾的关键问题是:使语义相异的特征对的距离等于0是不合理的。为了解决这个问题,我们尝试采用更灵活的策略来优化噪声变化。我们稍微修改了对比度损失函数,设了边界Tk,即TCL,表示没有必要将距离最小到0。[35]中也有相似的想法,具体公式如式3所示。
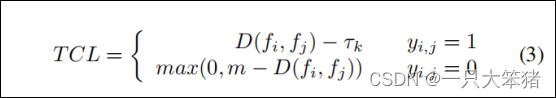
为了证明TCL在大视角差异的情况下的优异性能,我们以不同阈值在CD2014数据集上进行了大量实验,更多细节见第五章B节。
D.训练策略
为了提高SCD任务的判别力,我们在工作中采用了多层侧输出(MLSO)训练策略,它首次被提出是在[41]和[28]的深层监督网络中。多层侧输出是基于以下两个观点设计:(1)在训练阶段,单层损失的监督信息会随着后向传播层级逐步减少,导致中间层的鉴别特征随监督信息丢失而减少;(2)在测试阶段,上层特征的表现严重依赖于中间层特征的判别力。
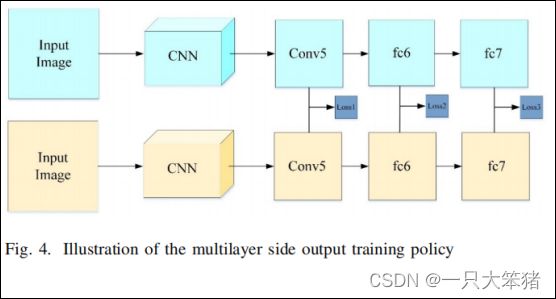
图4 多层侧输出训练策略图示
受此启发,我们引入了伴生损失函数,具体来说是对比损失函数,用来监督中间层的特征学习,它可以看做是对上层隐藏层的附加约束。在训练过程中,为了平衡不同层的损失,我们引入了层平衡权重,称为βh。具体公式如下:
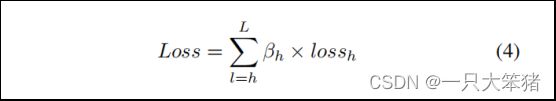
式中lossh指的是距离图和真实变化之间的差。在推理阶段,我们也对不同层设了不同的置信阈值,最终预测结果是所有输出的平均值。
四.实验与论述
这一部分,我们阐述了我们的实验评估,并提出了对所提出的架构的消融研究。我们展示了在CD2014、VL-CMU-CD和PCD2015数据集上,我们的方法与基线对比更有竞争性的性能。
A.实施细节
在实验中,CosimNet的骨干是基于DeepLabV2,DeepLabV2最后的分类层被移除。在微调时,顶层的5层学习率被初始化为1e-7,特征层fc6和fc7的学习率为1e-8。我们使用随机梯度下降法训练所有模型,动量为0.9,权重衰减为5e-5。本文中所有实验均基于Pytorch框架,训练硬件为GTX TITAN 1080。下一节,我们将展示CosimNet在3个数据集上的表现。
B.数据集和结果
1)VL-CMU-CD
VL-CMU-CD数据集是一个变化检测数据集,具有长时间跨度和挑战性的变化,包括语义变化(如新的建筑物和建设区)和噪声变化(如视角变化、光照条件/天气/季节变化)。该数据集包含了151个序列,相当于1362个图像对。其中有5类标签掩膜,包括车辆和交通信号。根据[2]提供的数据拆分,拆分数据包括一个97组含933个图像对的训练数据集和一个54组含429个图像对的测试数据集。在训练过程汇总,我们将所有样例重采样为512*512大小,并将多分类标签掩膜转变为二值变化图,这意味着我们只关注变化而非类别信息。本文提出的方法和其他先进算法的性能对比如表1所示。
表1 VL-CMU-CD数据集上本文方法与其他流行方法的性能比较(F指标)

针对不同的设置,包括各种距离度量(欧几里得距离、余弦相似性)和不同的训练策略(MLSO),我们设计了一系列对比实验。如表1所示,我们对比了CosimNet和其他先进的模型,CosimNet展现出了显著的性能提升。具体来说,CosimNet-3-layer-l2实现了15%的提升,CosimNet-1 layer-cos也有8%的提升。此外,我们观察到两种现象:(1)MLSO训练策略确实提升了中间层的语义表现,中间层的有力表现提升了性能。(2)欧氏距离在量测变化时的表现优于余弦相似性。为了探索不同度量的更多表现,第五章B部分阐述了变化图的可视化分析和使用对比敏感度的定量分析。
2)PCD2015
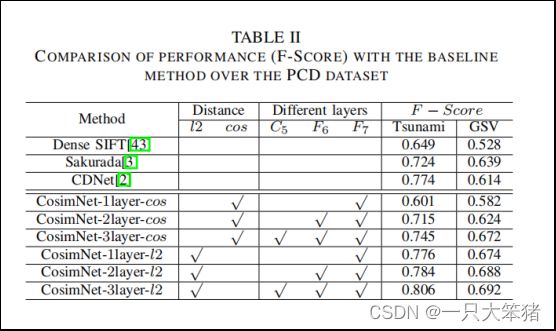
PCD2015数据集包含两个子集:Tsunami和GSV。详细说来,Tsunami包含海啸前后的100对全景影像场景,GSV包含92组谷歌街景全景影像对。在我们的实验设置中,我们直接保持了原始大小1024*1024的数据来训练,并进行8:2比例的5折交叉验证。与第四章B部分的设置相似,我们也设了6组不同因素的对比实验,对比结果如表2所示,CosimNet-3 layer-l2在Tsunami数据集上有3%的性能提升,在GSV数据集上有接近8%的提升。
表2 PCD2015数据集上本文方法与其他流行方法的性能比较(F指标)
3)CDnet
CDnet数据集由31个视频组成,描绘了不同场景下的室内和室外场景,有船只、卡车和行人。它包含一系列挑战性因素,包括动态背景、相机抖动、阴影、相对运动、PTZ和夜间视频,旨在解决复杂户外条件下的前景检测。一般来说,前景检测可以认为是基于多帧序列的变化检测,其通常的做法是进行图像差分。
如图5所示,我们选择了T0时的背景影像(无任何前景要素)作为参考图像,T1时刻影像作为查询影像。详细说来,我们建立了一个含91595图像对的数据,其中73276对为训练数据,18319对为预测数据,所有影像缩放为512*512大小进行训练。首先,我们直接对比了CosimNet-3-layer-l2,与其他先进的方法对比,它是之前实验中表现最好的。本文方法与其他常用基线方法的对比结果如表3所示。

图5 CDnet数据集中不同时间的图像对 第一行是完全对齐的影像,第二行是因相机移动或变焦造成的大视角差异而未对齐的样本
表3 CDnet数据集上前景检测与其他方法的结果比较
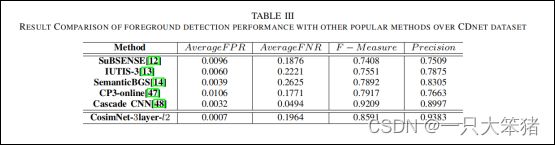
与其他先进的方法对比,我们的模型取得了有竞争力的表现,但仍然在一些指标上表现不足。原因可以分为2部分:一方面,几乎所有先进的算法都采用了语义分割方法来弥补,因为每一帧都有像素级别的注释;另一方面,本文方法是基于图像差分方法,模型的性能严重依赖于背景的选择和图像对的配准。具体而言,通过一些设计(如TCL),我们的模型性能对大视角差异情况有显著提升。然而,与语义分割的方法相比精度仍然较低。更多在CDnet数据集上进行变化检测的演示可以访问地址:https://www.youtube.com/watch?v=VcJIpfX-iA,https://www.youtube.com/watch?v=trhQE4Uq-GM。
五、讨论
为了进一步证明CosimNet的性能,我们将讨论3个挑战性问题:(1)CosimNet对相机转动、变焦引起的视角差异情况具有鲁棒性吗?(2)CosimNet框架可以被视为一个需要固定阈值才能生成二值掩膜的图像差分方法,因此引申出一个很自然的问题,模型性能对阈值敏感吗?(3)由对比损失限制的度量学习真的能学到更有鉴别性的特征来进行变化检测任务吗?为了解决这些问题,我们在CD2014和VL-CMU-CD数据集上进行了实验。
A.对视角差异是否有鲁棒性?
区分语义变化和噪声变化是SCD任务的一个关键特性。本文提出的方法是基于图像差分思想,自然对由相机转动或缩放造成的视角差异敏感。为了解决这一挑战性问题,通常会使用预处理算法(例如SFM)来配准影像对。然而,这个方法不仅计算量大,而且性能有限。因此,很自然会提出以下问题:是否有方法可以从未配准的影像对直接提取语义变化,不需要任何预处理或后处理就可以抑制噪声?考虑到不同角度的视角差异对模型性能产生不同程度的影像,我们在VL-CMU-CD数据集上评估了联合处理方法解决小视角差异和大视角差异的表现。
(1)小视角差异
由于图像采集时间不同,难以保证从同一视角拍摄,尤其是在长时间跨度的情况下,因此产生较小的视角差异是很常见的。为了解决这一问题,我们直接尝试了原始对比度损失(公式2)在小视角差异下直接量测变化。如图6所示,我们观察到小视角差异并不足以降低CosimNet的性能。最直观的解释是:CNN的感受野很大,并随着层深增加而扩大,因此小的视角差异不足以影响图像的表现。因此,原始的对比度损失可以应对这一挑战性问题。
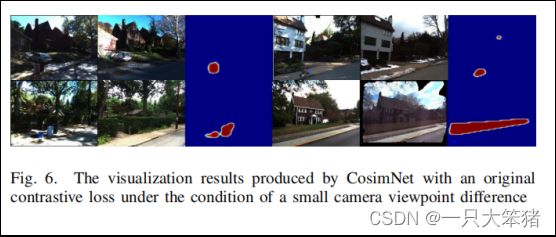
图6 CosimNet在小视角差异下利用对比度损失检测的结果可视化
(2)大视角差异
在所有噪声变化中,大视角差异是最具有挑战性的因素,它使CosimNet的性能严重降低。如前所述,我们提出了阈值对比度损失(TCL)来解决这一问题。为了评估TCL(公式3)的有效性,我们设计了一系列基于CD2014数据集的对比实验,尤其是与PTZ类对比(包括Pan,Intermittent Pan, TwoPositionPTZCam, and zoomInZoomOut)。我们设了[0-0.4]区间,以0.1为间隔的不同的阈值,TCL相当于阈值为0时的原始对比度损失。我们探究了不同阈值设置时的性能,对比结果如图8所示,我们发现:
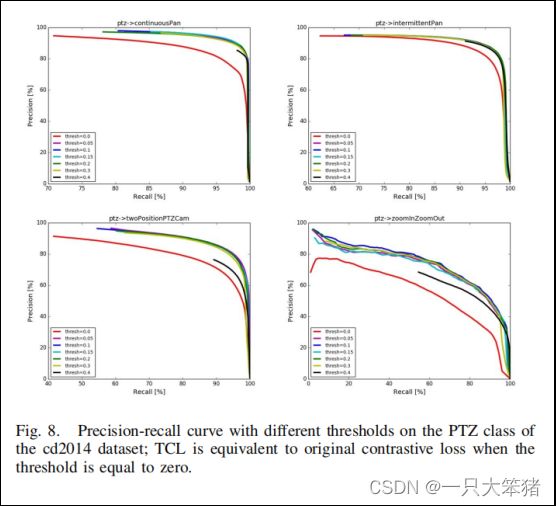
图8 CD2014数据集上PTZ类不同阈值准确度-召回率曲线图
当阈值为0时,TCL相当于原始对比度损失。
(1)在解决大视角差异问题上,TCL比原始的对比度损失函数表现更好,这意味着更多容错优化对噪声变化具有鲁棒性。
(2)加入TCL的CosimNet在阈值为0.1时有最优性能,阈值为0.4时性能下降,这意味着容错过度会降低层间差异。为了进一步验证TCL的性能,我们可视化了CD2014数据集上大视角差异的变化图。如图7所示,
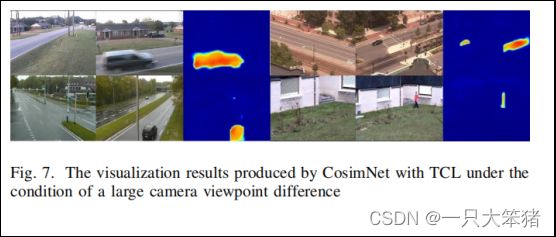
图7 加入TCL的CosimNet对大视角差异的检测结果可视化
B.对比度灵敏度
考虑到阈值会严重影响到模型的性能,我们用了定量化度量方法——阈值对比法来量测对比度敏感度,它表示自然图像中前景和后景之间的阈值。具体来说,有许多阈值对比方法来量测对比度敏感度,如Michelson对比度和RMS对比度。其中,Michelson对比度适用于重复的图案,如正弦波。而RMS对比度适用于复杂图案,如随机的点图案或自然图像,文中利用的正是此方法。
在我们的工作中,我们希望将前景和后景的对比度(即变化)最大化,这样模型的性能将不会很大程度上依赖阈值的选择。为了证明我们设计的选择的效用,我们分析了两个不同设置下的阈值对比度,包括不同的距离度量和不同层提取的特征。
(1)不同距离度量
毫无疑问,不同距离度量对于量测特征对距离具有不同的能力。从场景变化检测任务的角度来看,选择合适度量方法的核心原则是给变化对的距离值更高、不变对的距离值更低。在上述实验中,我们发现l2距离的性能总是优于余弦相似度。为了探索其中原因,我们对2种距离度量的RMS对比度进行了定量分析,如图9所示。
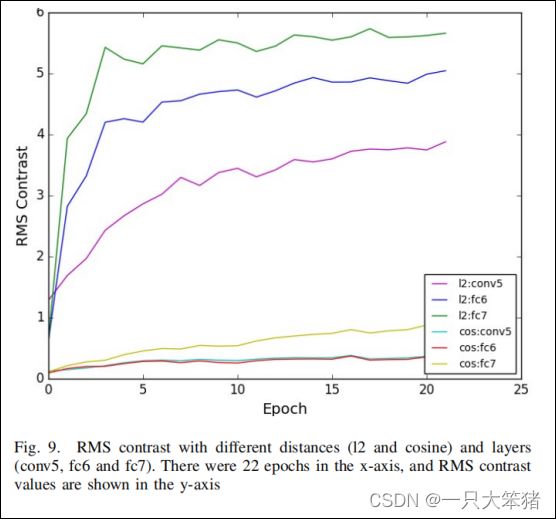
图9 不同距离和层的RMS对比度 X轴为22批次训练,Y轴为RMS对比度的值
我们观察到RMS对比度量在训练过程中有明显增加。根据相同层的特征,我们发现了l2距离的对比度远大于余弦相似度,这表示l2距离区别变化和背景的能力更强。
此外,为了对两种距离度量有更深入的理解,我们进行了变化图可视化,来展示哪些变化区域的反映最强烈。如图10所示,与余弦相速度相比,由l2距离生成的变化图在每一层都表现出更多相关的语义变化,并且抑制的噪声变化更多,这表示l2距离比余弦相似性更能分离变化对和聚合不变对。
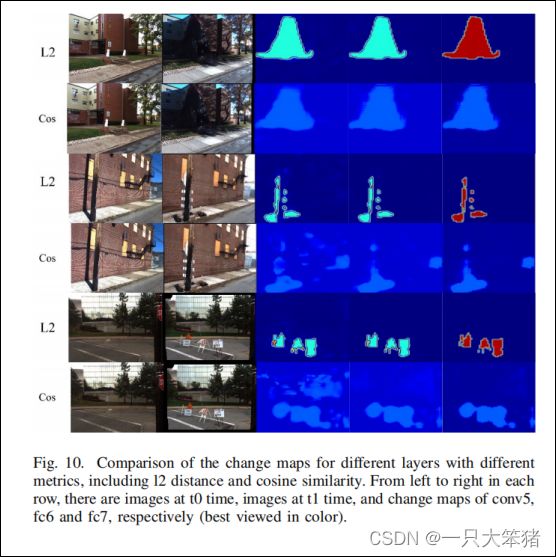
图10 不同层采用不同度量的变化图对比,包括l2距离和余弦相似度
每行从左到右依次为:t0时刻图像,t1时刻图像,conv5、fc6和fc7层的变化图(为展示效果进行了彩色渲染)
(2)不同层的语义特征
众所周知,相比浅层特征,深层特征包含更丰富的语义信息。与上述图9的分析相同,相同距离度量下,fc7层的RMS对比度值远大于fc6层和conv5。除此之晚,如图10所示,fc7层的变化图相比其他2层的响应更强烈,并且强烈关注相关的语义变化,这意味着更多的鉴别性特征可使模型性能更健壮。
C.FCN架构中更强的特征表示
1)学习鉴别性特征
如何提高特征的语义辨别能力是计算机视觉任务的核心问题,解决这一问题的关键是增大类间差异、减少类内差异。基于FCN的变化检测方法将不同时期捕获的特征对进行维度上的连接,该框架的本质是学习不同特征类别之间的决策边界,通过特征与决策边界之间的距离来确定某一类的特征。因此,学习鉴别性特征对分类任务至关重要。
CosimNet引入了可量测变化的前验知识,给变化对赋予更高的距离量测值,给不变对赋予更低的距离量测值。同样,对语义特征的学习,我们希望特征对{featk0 , featk1}在特征空间聚集,这恰恰反映了特征语义的区分学习的基本要求。循着提升特征的鉴别性的思想,我们在基于FCN的模型中引入距离度量学习,并使用相似度学习来对特征进行约束。实施过程中,我们基于DeepLabV2使用了多任务损失函数(如式7)优化了模型。其中,损失由两部分组成,Lossclass是交叉熵,常用于像素级分类;Lossfeat是对比度损失,用于学习鉴别性特征。此外,为了防止训练中的梯度域,我们设了一个常数λ来抵消两种损失的不平衡,在实验中,λ等于3。
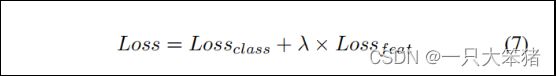
对比结果如表4所示,与深层度量学习的结合在3个数据上实现了轻微的性能提升。为了探索提升的主要原因,我们可视化对比了传统FCN和深层度量学习。如图11中每行第3列显示,长椅和交通信号被碎片化或误标,从分类的角度可以视为误分类,但在特征学习领域有待进一步探索的是,误分类是由组内不一致导致的,这也是FCN的一大短板。同样,如图11每行最后2列所示,我们发现在变化图中,模型相比原始FCN有了明显的一致性增强。具体而言,引入距离度量可以视为增加了特征学习的约束,这降低了组内的方差并且可以获得更平滑的边界。
表4 三种数据集上的性能比较(F指标)


图11 每行从左到右分别为:t0时刻影像、t1时刻影像、实际变化、最后融合预测、本文方法生产的变化图、本文方法的预测结果图(为展示效果进行了彩色渲染)
2)特征可视化
为了进一步探索深层度量学习强化的理解,我们采用t-SNE算法对CosimNet的FCN模型和fc7层的特征分布进行可视化,fc7特征二维分布如图12所示,根据与变化检测结果的对比,CosimNet的优势在于保持了边界的平滑和对象的一致性。此外,观察两种方法对应的二维特征分布,我们发现CosimNet学习到的特征的可分离性更高、类内方差更小。显然,引入深层度量学习确实可以使类内更紧凑和类间可分离,这有助于学习到更有鉴别性的特征、解决语义变化与噪声变化的纠缠,从而获得更好的性能。
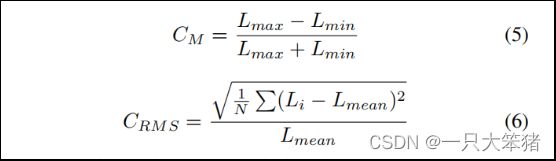

图12 从左到右每行为:(1)变化图,(2)CosimNet预测结果,(3)FCN预测结果,(4)二维fc7特征嵌入CosimNet,(5)二维fc7特征嵌入FCN,如每行最后两列所示,不同色彩代表不同类,青色表示变化对特征嵌入,纯色表示未变化。(为显示效果采用彩色渲染)
六、结论
我们提出了一个名为CosimNet的结构用于场景变化检测任务,它可以通过学习隐式度量来直接量测变化。为了使不变对的距离减少、变化对的距离增大,本文使用了孪生网络从图像对上提取特征,并使用对比度损失来学习更好的隐式度量。具体来说,我们定义了阈值对比度损失,使用一个容错更好的策略来惩罚噪声变化,可以解决大视角差异的问题。在3个流行的数据集上的对比实验表明,本文提出的方法在许多挑战性条件下具有鲁棒性,例如光照变化、季节变化、相机转动和变焦。低维空间的特征可视化表明,CosimNet学习到了解决变化特征和不变特征的纠缠并加以区分,学到的解缠方法可以被认为是机器学习模型优化很有帮助的要素,这是我们的模型可以取得更好表现的关键因素。我们的框架可能为重新思考如何衡量场景变化检测任务中的“变化”提供了新的思路。