CV-Model【3】:VGG16
文章目录
- 前言
- 1. 配置环境
-
- 1.1. 导入相关库
- 1.2. 下载数据集
-
- 1.2.1. 准备训练集和验证集
- 1.2.2. 准备测试集
- 1.2.3. 下载数据集
- 2. 搭建神经网络
-
- 2.1. 神经网络框架
- 2.2. 网络
- 3. 训练模型
-
- 3.1. 实例化模型并设置优化器
- 3.2. 定义计算准确度的函数
- 3.3. 训练模型
- 3.4. 绘制训练损失曲线
- 3.5. 绘制准确度曲线
- 4. 预测
-
- 4.1. 示例
- 4.2. 打印矩阵
- 总结
前言
VGG网络有五种配置,命名为A到E。配置的深度从左(A)到右(B)增加,增加的层数也多。下面是一个描述所有潜在网络结构的表格。
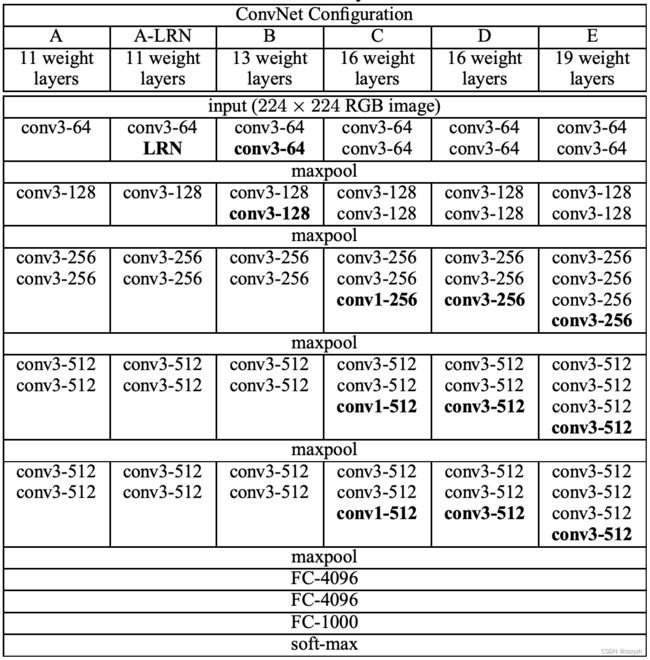
所有的配置都遵循结构上的通用模式,只在深度上有区别;从网络A的11个权重层(8个卷积层和3个全连接层),到网络E的19个权重层(16个卷积层和3个全连接层)。卷积层的通道数量相当少,从第一层的64个开始,然后在每个最大集合层之后增加2倍,直到达到512个。
本文主要探讨的是D列,即16 weights layers。使用的数据集为CIFAR-10。
1. 配置环境
1.1. 导入相关库
import numpy as np
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
import time
import matplotlib.pyplot as plt
RANDOM_SEED = 123
BATCH_SIZE = 256
NUM_EPOCHS = 50
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
1.2. 下载数据集
1.2.1. 准备训练集和验证集
def get_train_valid_loader(data_dir,
batch_size,
random_seed,
valid_size=0.1,
shuffle=True,
num_workers=0):
# 数据集中每个通道 (R, G, B) 的平均值和标准偏差来定义变量normalize。
normalize = transforms.Normalize(
mean=[0.4914, 0.4822, 0.4465],
std=[0.2023, 0.1994, 0.2010],
)
# 定义验证集的transforms
valid_transform = transforms.Compose([
# 重设图片大小
transforms.Resize((70, 70)),
# 中心裁剪
transforms.CenterCrop((64, 64)),
transforms.ToTensor(),
normalize,
])
# 定义训练集的transforms
train_transform = transforms.Compose([
# 重设图片大小
transforms.Resize((70, 70)),
# 中心裁剪
transforms.CenterCrop((64, 64)),
transforms.ToTensor(),
normalize,
])
# 下载数据集
train_dataset = datasets.CIFAR10(
root=data_dir, train=True,
download=True, transform=train_transform,
)
valid_dataset = datasets.CIFAR10(
root=data_dir, train=True,
download=True, transform=valid_transform,
)
# 获取训练集的标签
num_train = len(train_dataset)
indices = list(range(num_train))
# 找到训练集和验证集划分的区间
split = int(np.floor(valid_size * num_train))
# 打乱数据集,若进行多次训练,每次训练获得的数据集将有不同
if shuffle:
np.random.seed(random_seed)
np.random.shuffle(indices)
# 划分训练集和验证集
train_idx, valid_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, num_workers=num_workers, drop_last=True, sampler=train_sampler)
valid_loader = torch.utils.data.DataLoader(
valid_dataset, batch_size=batch_size, num_workers=num_workers, sampler=valid_sampler)
return train_loader, valid_loader
Dataloader参数
- num_workers
每次dataloader加载数据时:dataloader一次性创建num_worker个worker,(也可以说dataloader一次性创建num_worker个工作进程,worker也是普通的工作进程),并用batch_sampler将指定batch分配给指定worker,worker将它负责的batch加载进RAM。然后,dataloader从RAM中找本轮迭代要用的batch,如果找到了,就使用。如果没找到,就要num_worker个worker继续加载batch到内存,直到dataloader在RAM中找到目标batch。
num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的进程是CPU复制的嘛)。num_workers的经验设置值是自己电脑/服务器的CPU核心数,如果CPU很强、RAM也很充足,就可以设置得更大些。 - drop_last
当设置drop_last=True时,每轮epoch训练的最后一批数据若不能满足一个batch_size,那些数据将会被舍弃
1.2.2. 准备测试集
def get_test_loader(data_dir,
batch_size,
shuffle=False,
num_workers=0):
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)
# 定义测试集的transform
transform = transforms.Compose([
# 重设图片大小
transforms.Resize((70, 70)),
# 中心裁剪
transforms.CenterCrop((64, 64)),
transforms.ToTensor(),
normalize,
])
dataset = datasets.CIFAR10(
root=data_dir, train=False,
download=True, transform=transform,
)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, num_workers=num_workers, shuffle=shuffle)
return data_loader
1.2.3. 下载数据集
# CIFAR10 dataset
train_loader, valid_loader = get_train_valid_loader(data_dir = 'autodl-tmp/data/', batch_size = BATCH_SIZE, random_seed = RANDOM_SEED)
test_loader = get_test_loader(data_dir = 'autodl-tmp/data/', batch_size = BATCH_SIZE)
2. 搭建神经网络
2.1. 神经网络框架

2.2. 网络
class VGG16(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 计算padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
self.block_1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
height, width = 3, 3 # 根据输入照片的尺寸进行调节
self.avg_pool = torch.nn.AdaptiveAvgPool2d((height, width))
self.classifier = torch.nn.Sequential(
torch.nn.Linear(512*height*width, 4096),
torch.nn.ReLU(True),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(True),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, num_classes),
)
for m in self.modules():
if isinstance(m, torch.torch.nn.Conv2d) or isinstance(m, torch.torch.nn.Linear):
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
logits = self.classifier(x)
return logits
nn.AdaptiveAvgPool2d()
自适应平均池化层- 使用这种池化方式,kernel_size和stride是函数根据输入的原始尺寸、目标尺寸自动计算出来的。
- 参数为输出的大小
- self.modules()
- 采用深度优先遍历的方式,存储了搭建的网络的所有模块
- isinstance(object, classinfo)
用于判断一个对象是否是一个已知的类型- object – 实例对象。
- classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。
- 认为子类是一种父类类型,考虑继承关系
torch.nn.init.kaiming_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
神经网络权重初始化。权重初始化的目的是防止在深度神经网络的正向传播过程中层激活函数的输出损失梯度出现爆炸或消失。如果发生任何一种情况,损失梯度太大或太小,就无法有效地向后传播,并且即便可以向后传播,网络也需要花更长时间来达到收敛。- pytorch默认使用kaiming正态分布初始化卷积层参数,即 kaiming_normal_
- kaiming_表示针对于Relu的初始化方法
- a:该层后面一层的激活函数中负的斜率(默认为ReLU,此时a=0)
- mode
- ‘fan_in’ (default): 使用fan_in保持weights的方差在前向传播中不变;
- ‘fan_out’: 使用fan_out保持weights的方差在反向传播中不变
3. 训练模型
3.1. 实例化模型并设置优化器
model = VGG16(num_classes=10)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.1,
mode='max',
verbose=True)
torch.optim.lr_scheduler.ReduceLROnPlateau
当一个指标停止改进时,降低学习率。一旦学习停滞不前,模型通常会从降低 2-10 倍的学习率中受益。这个调度器读取一个指标数量,如果在一个 “耐心” 的历时数内没有看到改进,学习率就会降低。
- optimizer - 网络的优化器
- mode - default ‘min’
- ‘min’ - 监控量停止下降的时候,学习率将减小
- ‘max’ - 监控量停止上升的时候,学习率将减小为 ‘min’
- factor - 学习率每次降低倍数,new_lr = old_lr * factor
- patience - 容忍网路的性能不提升的次数,高于这个次数就降低学习率
- verbose - default False
- True,则为每次更新向stdout输出一条消息。
- threshold - 测量新最佳值的阈值,仅关注重大变化。 default 1e-4
- cooldown - 减少lr后恢复正常操作之前要等待的时期数。 default 0。
- min_lr - 学习率的下限
- eps - default 1e-8
- 适用于lr的最小衰减。
- 如果新旧lr之间的差异小于eps,则忽略更新。
3.2. 定义计算准确度的函数
def compute_accuracy(model, data_loader, device):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.float().to(device)
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
num_examples += targets.size(0)
# 累加每批次的预测正确的样本数,以获得一个测试周期的所有预测正确的样本数
correct_pred += (predicted_labels == targets).sum().item()
return correct_pred/num_examples * 100
3.3. 训练模型
def train_model(model, num_epochs, train_loader,
valid_loader, test_loader, optimizer,
device, logging_interval=50,
scheduler=None,
scheduler_on='valid_acc'):
# 系统时钟的时间戳
start_time = time.time()
minibatch_loss_list, train_acc_list, valid_acc_list = [], [], []
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
# 前向与后向传播
logits = model(features)
loss = torch.nn.functional.cross_entropy(logits, targets)
optimizer.zero_grad()
loss.backward()
# 更新模型参数
optimizer.step()
# 打印日志
minibatch_loss_list.append(loss.item())
if not batch_idx % logging_interval:
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Batch {batch_idx:04d}/{len(train_loader):04d} '
f'| Loss: {loss:.4f}')
model.eval()
with torch.no_grad():
train_acc = compute_accuracy(model, train_loader, device=device)
valid_acc = compute_accuracy(model, valid_loader, device=device)
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Train: {train_acc :.2f}% '
f'| Validation: {valid_acc :.2f}%')
train_acc_list.append(train_acc)
valid_acc_list.append(valid_acc)
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
if scheduler is not None:
if scheduler_on == 'valid_acc':
scheduler.step(valid_acc_list[-1])
elif scheduler_on == 'minibatch_loss':
scheduler.step(minibatch_loss_list[-1])
else:
raise ValueError(f'Invalid `scheduler_on` choice.')
# 计算运行时间
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')
test_acc = compute_accuracy(model, test_loader, device=device)
print(f'Test accuracy {test_acc :.2f}%')
return minibatch_loss_list, train_acc_list, valid_acc_list
# 训练模型
minibatch_loss_list, train_acc_list, valid_acc_list = train_model(
model=model,
num_epochs=NUM_EPOCHS,
train_loader=train_loader,
valid_loader=valid_loader,
test_loader=test_loader,
optimizer=optimizer,
device=DEVICE,
scheduler=scheduler,
scheduler_on='valid_acc',
logging_interval=100)
# 保存模型参数
torch.save(model.state_dict(), 'model/VGG16/vgg_16_model.pth') # 只保存模型的参数,不保存模型
torch.save(optimizer.state_dict(), 'model/VGG16/vgg_16_optimizer.pth') # 保存优化器的参数,如学习率等
3.4. 绘制训练损失曲线
def plot_training_loss(minibatch_loss_list, num_epochs, iter_per_epoch, averaging_iterations=100):
plt.figure()
ax1 = plt.subplot(1, 1, 1)
ax1.plot(range(len(minibatch_loss_list)),
(minibatch_loss_list), label='Minibatch Loss')
if len(minibatch_loss_list) > 1000:
ax1.set_ylim([
0, np.max(minibatch_loss_list[1000:])*1.5
])
ax1.set_xlabel('Iterations')
ax1.set_ylabel('Loss')
ax1.plot(np.convolve(minibatch_loss_list,
np.ones(averaging_iterations,)/averaging_iterations,
mode='valid'),
label='Running Average')
ax1.legend()
# 设置双坐标轴
ax2 = ax1.twiny()
newlabel = list(range(num_epochs+1))
newpos = [e*iter_per_epoch for e in newlabel]
ax2.set_xticks(newpos[::10])
ax2.set_xticklabels(newlabel[::10])
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 45))
ax2.set_xlabel('Epochs')
ax2.set_xlim(ax1.get_xlim())
plt.tight_layout()
plt.savefig("model/VGG16/plot_training_loss.pdf")
plot_training_loss(minibatch_loss_list=minibatch_loss_list,
num_epochs=NUM_EPOCHS,
iter_per_epoch=len(train_loader),
averaging_iterations=200)
plt.show()

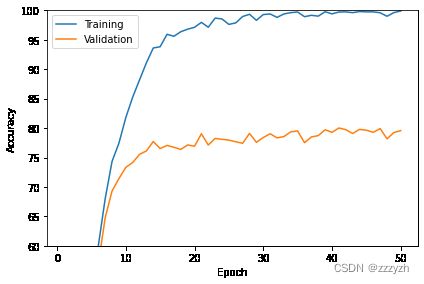
3.5. 绘制准确度曲线
def plot_accuracy(train_acc_list, valid_acc_list):
num_epochs = len(train_acc_list)
plt.plot(np.arange(1, num_epochs+1),
train_acc_list, label='Training')
plt.plot(np.arange(1, num_epochs+1),
valid_acc_list, label='Validation')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig("model/VGG16/plot_acc_training_validation.pdf")
plot_accuracy(train_acc_list=train_acc_list,
valid_acc_list=valid_acc_list)
plt.ylim([60, 100])
plt.show()
4. 预测
4.1. 示例
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
for t, m, s in zip(tensor, self.mean, self.std):
t.mul_(s).add_(m)
return tensor
def show_examples(model, data_loader, unnormalizer=None, class_dict=None):
for batch_idx, (features, targets) in enumerate(data_loader):
with torch.no_grad():
features = features
targets = targets
logits = model(features)
predictions = torch.argmax(logits, dim=1)
break
fig, axes = plt.subplots(nrows=3, ncols=5,
sharex=True, sharey=True)
if unnormalizer is not None:
for idx in range(features.shape[0]):
features[idx] = unnormalizer(features[idx])
nhwc_img = np.transpose(features, axes=(0, 2, 3, 1))
if nhwc_img.shape[-1] == 1:
nhw_img = np.squeeze(nhwc_img.numpy(), axis=3)
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhw_img[idx], cmap='binary')
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
else:
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhwc_img[idx])
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
plt.tight_layout()
plt.show()
model.cpu()
unnormalizer = UnNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
class_dict = {0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'}
show_examples(model=model, data_loader=test_loader, unnormalizer=unnormalizer, class_dict=class_dict)

4.2. 打印矩阵
from itertools import product
def compute_confusion_matrix(model, data_loader, device):
all_targets, all_predictions = [], []
with torch.no_grad():
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
all_targets.extend(targets.to('cpu'))
all_predictions.extend(predicted_labels.to('cpu'))
all_predictions = all_predictions
all_predictions = np.array(all_predictions)
all_targets = np.array(all_targets)
class_labels = np.unique(np.concatenate((all_targets, all_predictions)))
if class_labels.shape[0] == 1:
if class_labels[0] != 0:
class_labels = np.array([0, class_labels[0]])
else:
class_labels = np.array([class_labels[0], 1])
n_labels = class_labels.shape[0]
lst = []
z = list(zip(all_targets, all_predictions))
for combi in product(class_labels, repeat=2):
lst.append(z.count(combi))
mat = np.asarray(lst)[:, None].reshape(n_labels, n_labels)
return mat
def plot_confusion_matrix(conf_mat,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=False,
show_absolute=True,
show_normed=False,
class_names=None):
if not (show_absolute or show_normed):
raise AssertionError('Both show_absolute and show_normed are False')
if class_names is not None and len(class_names) != len(conf_mat):
raise AssertionError('len(class_names) should be equal to number of'
'classes in the dataset')
total_samples = conf_mat.sum(axis=1)[:, np.newaxis]
normed_conf_mat = conf_mat.astype('float') / total_samples
fig, ax = plt.subplots(figsize=figsize)
ax.grid(False)
if cmap is None:
cmap = plt.cm.Blues
if figsize is None:
figsize = (len(conf_mat)*1.25, len(conf_mat)*1.25)
if show_normed:
matshow = ax.matshow(normed_conf_mat, cmap=cmap)
else:
matshow = ax.matshow(conf_mat, cmap=cmap)
if colorbar:
fig.colorbar(matshow)
for i in range(conf_mat.shape[0]):
for j in range(conf_mat.shape[1]):
cell_text = ""
if show_absolute:
cell_text += format(conf_mat[i, j], 'd')
if show_normed:
cell_text += "\n" + '('
cell_text += format(normed_conf_mat[i, j], '.2f') + ')'
else:
cell_text += format(normed_conf_mat[i, j], '.2f')
ax.text(x=j,
y=i,
s=cell_text,
va='center',
ha='center',
color="white" if normed_conf_mat[i, j] > 0.5 else "black")
if class_names is not None:
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=90)
plt.yticks(tick_marks, class_names)
if hide_spines:
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.yaxis.set_ticks_position('left')
ax.xaxis.set_ticks_position('bottom')
if hide_ticks:
ax.axes.get_yaxis().set_ticks([])
ax.axes.get_xaxis().set_ticks([])
plt.xlabel('predicted label')
plt.ylabel('true label')
return fig, ax
mat = compute_confusion_matrix(model=model, data_loader=test_loader, device=torch.device('cpu'))
plot_confusion_matrix(mat, class_names=class_dict.values())
plt.show()

总结
我们首先了解了VGG-16模型的架构和不同种类的层。
接下来,我们使用Torchvision加载并预处理了CIFAR10数据集。
然后,我们使用PyTorch从头开始建立我们的VGG-16模型,同时了解Torch中不同类型的层。
最后,我们在CIFAR100数据集上训练并测试了我们的模型。