利用TensorRT在Ubuntu部署YOLOv5
利用TensorRT在Ubuntu部署YOLOv5
- 一、CUDA、CUDNN、TensorRT以及OpenCV安装
-
- 1. CUDA安装
- 2. CUDNN安装
- 3. TensorRT安装
- 4. OpenCV安装
- 二、YOLOv5部署
-
- 1. 文件准备
- 2. 模型文件转换
- 3.生成wts文件
- 4.生成部署引擎
- 5.端侧部署模型测试图片
- 6.视频检测
- 7.安卓部署
- 8.C++部署
- 三、解决方案
-
- 1. 编译tensorrtx/yolov5时
- 2. 生成模型引擎时
- 3. 无法找到opencv的库文件
- 4. terminate called after throwing an instance of 'cv::Exception' 。。。configure script in function 'cvShowImage'
- 5. Failed to load module "canberra-gtk-module"
- 6.[rdparty/protobuf/src/google/protobuf/stubs/common.cc:52:2: error](https://blog.csdn.net/qq_36786467/article/details/124299205)
- 7.[ubuntu安装libgtk2.0-dev报错](https://blog.csdn.net/qq_36786467/article/details/124295467)
- 8.opencv error: unknown type name ‘size_t’
一、CUDA、CUDNN、TensorRT以及OpenCV安装
1. CUDA安装
# CUDA=10.2
# 选择生成软链接,不需要安装驱动
sudo sh cuda_10.2.89_440.33.01_linux.run
# 查看CUDA版本
cat /usr/local/cuda/version.txt
# 测试CUDA,安装成功则显示PASS
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
2. CUDNN安装
# CUDNN=8.1.1.33
# 将压缩包解压
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
# 查看CUDNN版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
3. TensorRT安装
# TensorRT=7.2.3.4(Ubuntu18.08_cuda10.2_cudnn_8.1)
# 解压压缩包,配置环境变量
tar xzvf TensorRT
mv TensorRT-7.2.3.4 /usr/local/
sudo gedit ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-7.2.3.4/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-7.2.3.4/include
# 安装TensorRT
cd /usr/local/TensorRT-7.2.3.4/
cd python
# 选择对应的Python版本
pip install tensorrt-7.2.3.4-cp38-none-linux_x86_64.whl
# 安装graphsurgeon
cd ../graphsurgeon
pip install graphsurgeon-0.4.5-py2.py3-none-any.whl
# 安装uff(TensorRT与TensorFlow配合试用时)
cd ../uff
pip install uff-0.6.9-py2.py3-none-any.whl
# 将tensorrt的库和头文件复制到系统路径
cd ..
sudo cp -r ./lib/* /usr/lib
sudo cp -r ./include/* /usr/include
# 安装测试
python # 进入Python环境
import tensorrt
4. OpenCV安装
国内源码地址
国外源码地址
# 安装必要的软件包
sudo apt install build-essential
sudo apt install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
# 若第三步报错:无法定位软件包libjasper-dev ,安装libjasper-dev的依赖包libjasper1
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt update
sudo apt upgrade
sudo apt install libjasper1 libjasper-dev
# opencv-3.4.2
# 下载对应版本的安装包:87.3 MB
# 解压安装包
unzip opencv-3.4.2.zip
# 新建build文件夹
mv opencv-3.4.2 /usr/local/
cd opencv-3.4.2
mkdir build
cd build
# 编译
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..

# 8线程并行编译,线程增加会缩短编译时间
make -j8
# 安装
sudo make install

# 配置环境
# 打开配置文件
sudo gedit /etc/ld.so.conf
# 添加库文件路径,更新系统共享链接库
include /usr/local/opencv-3.4.2/build/lib
sudo gedit /etc/ld.so.conf.d/opencv.conf
# 添加文本
/usr/local/lib
# 配置文件生效
sudo ldconfig


# 配置 bash
sudo gedit /etc/bash.bashrc
# 添加文本
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
# 使配置生效
source /etc/bash.bashrc
# 更新
sudo updatedb
![]()
# 查看opencv版本
pkg-config --modversion opencv
# OpenCV示例测试
cd /usr/local/opencv-3.4.2/samples/cpp/example_cmake
cmake .
make
./opencv_example
# 摄像头打开,出现Hello OpenCV则证明安装成功

# 测试代码
#include 二、YOLOv5部署
适用于笔记本和NX
所有的操作在Ubuntu系统中进行
深度学习模型部署途径:
方法1:pt --> onnx/torchscript/wts -–> openvino/tensorrt --> 树莓派/jetson(linux)
方法2:pt --> onnx/torchscipt --> ncnn --> 安卓端(android studio)
方法3:pt --> onnx/torchscript --> ML --> ios端(xcode)
部署在jeston xavier nx
1. 文件准备
YOLOv5-5.0项目
tensorrtx地址,包含代码及相关说明
# 安装tensorrt
# 安装pycuda
conda install pycuda # pip安装报错,则选择conda安装
# 在NX上安装pycuda
pip install pycuda

2. 模型文件转换
以预训练模型yolov5s.pt为例,将其转换为onnx、torchscript.pt、mlmodel。
# pt --> onnx/torchscript/mlmodel
# 将model/export.py文件移动至项目路径下
mv model/export.py ./
# 给定三个主要参数
parser.add_argument('--weights', type=str, default='./weights/yolov5s.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
python export.py # nx:python3 export.py
3.生成wts文件
# 激活虚拟环境pytorch1.8_cuda10.2
cd tensorrtx/yolov5
python gen_wts.py ../../weights/yolov5s.pt ./ # nx:python3
# python [gen_wts.py] [pt模型] [输出文件路径]
# 在当前目录下生成yolov5s.wts文件
4.生成部署引擎
相关文件参数设置
- tensorrtx/yolov5/yololayer.h
- tensorrtx/yolov5/yolov5.cpp
# tensorrtx/yolov5/yololayer.h
MAX_OUTPUT_BBOX_COUNT = 1000 # 最大输出的检测框数
CLASS_NUM = 80 # 检测类别数,根据实际任务设置
INPUT_H = 640 # 输入图片高度,32的倍数
INPUT_W = 640 # 输入图片宽度,32的倍数
# tensorrtx/yolov5/yolov5.cpp
USE_FP16 # set USE_INT8 or USE_FP16 or USE_FP32
DEVICE 0 # GPU id
NMS_THRESH 0.4 # NMS阈值
CONF_THRESH 0.5 # 置信度阈值
BATCH_SIZE 1 # batch大小
# 还包括各层模型结构设置
相关执行命令
# 新建编译文件夹
mkdir build
cd build
# 编译
cmake ..
make -j6
#基于C++的engine部署引擎文件生成
#sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/s6/m6/l6/x6 or c/c6 gd gw]
sudo ./yolov5 -s ../yolov5s.wts yolov5s.engine s
sudo ./yolov5 -s ../yolov5s.wts yolov5s.engine s6
# 自定义网络depth_multiple=0.17, width_multiple=0.25
sudo ./yolov5 -s yolov5_custom.wts yolov5.engine c6 0.17 0.25

5.端侧部署模型测试图片
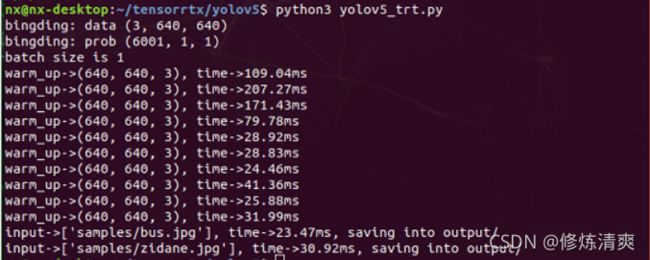
推理测试
sudo ./yolov5 -d yolov5s.engine ../samples
# sudo ./yolov5 -d [.engine文件] [待检测图片的文件夹]
# 在build文件夹下输出检测图片

python测试
# 参数设置:阈值设置
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.4
# 必要文件:
PLUGIN_LIBRARY = "build/libmyplugins.so" #自定义插件文件
engine_file_path = "build/yolov5s.engine" #模型引擎文件
cd ..
python3 yolov5 _trt.py
# 在output文件夹下输出检测图片
6.视频检测
使用USB摄像头或者笔记本自带摄像头进行实时检测。
#include (end - start).count() << "ms" << std::endl;
int fps = 1000.0/std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
//add FPS in the windows
// std::string jetson_fps = "Jetson NX FPS: " + std::to_string(fps);
// cv::putText(frame, jetson_fps, cv::Point(11,80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5",frame);
key = cv::waitKey(1);
if (key == 'q'){
break;
}
fcount = 0;
}
capture.release();
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
用以上代码替换原来的yolov5.cpp,然后重新编译:
cd tensorrtx/yolov5/build
cmake ..
make
sudo ./yolov5 -v yolov5s.engine
7.安卓部署
待更新
8.C++部署
待更新
三、解决方案
# tensorrtx/yolov5/yolov5.cpp
USE_FP16 # set USE_INT8 or USE_FP16 or USE_FP32
DEVICE 0 # GPU id
NMS_THRESH 0.4 # NMS阈值
CONF_THRESH 0.5 # 置信度阈值
BATCH_SIZE 1 # batch大小
1. 编译tensorrtx/yolov5时
出现“fatal error: NvInfer.h: No such file or directory”
# tensorrtx/yolov5/CMakeLists.txt文件中添加tensorRT的安装路径
include_directories(/usr/local/TensorRT-7.2.3.4/include)
link_directories(/usr/local/TensorRT-7.2.3.4/lib)
参考链接
2. 生成模型引擎时
出现“./yolov5: error while loading shared libraries: libcudnn.so.8: cannot open shared object file: No such file or directory”
或者“/usr/bin/ld: warning: libcudnn.so.8, needed by /usr/local/TensorRT-7.2.3.4/lib/libnvinfer.so, not found (try using -rpath or -rpath-link)/usr/local/TensorRT-7.2.3.4/lib/libnvinfer.so:对‘[email protected]’未定义的引用”
# CUDNN版本与TensorRT的版本不对应
# 将CUDA添加至环境变量,并重新生成软链接
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=/usr/local/cuda
sudo rm -rf /usr/local/cuda #删除之前生成的软链接
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda #生成新的软链接
cat /usr/local/cuda/version.txt#查看当前cuda的版本
sudo ldconfig
3. 无法找到opencv的库文件
# tensorrtx/yolov5/CMakeLists.txt文件中添加opencv静态库的路径
link_directories(/usr/local/opencv-3.4.2/build/lib)
4. terminate called after throwing an instance of ‘cv::Exception’ 。。。configure script in function ‘cvShowImage’
terminate called after throwing an instance of ‘cv::Exception’ what(): OpenCV(3.4.2) /usr/local/opencv-3.4.2/modules/highgui/src/window.cpp:632: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Carbon support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function ‘cvShowImage’ 已放弃
# 安装OpenCV时出错,不能仅仅使用cmake
# 按照本文的方法重新配置环境,编译即可
5. Failed to load module “canberra-gtk-module”
![]()
sudo apt-get install libcanberra-gtk-module
6.rdparty/protobuf/src/google/protobuf/stubs/common.cc:52:2: error
7.ubuntu安装libgtk2.0-dev报错
8.opencv error: unknown type name ‘size_t’
卸载linux-libc-dev:amd64
sudo apt remove linux-libc-dev:amd64
重装linux-libc-dev:amd64
sudo apt-get install linux-libc-dev:amd64
重新安装软件依赖
sudo apt install build-essential
sudo apt install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
参考1
参考2