【论文笔记】_RepVGG: Making VGG-style ConvNets Great Again
RepVGG: Making VGG-style ConvNets Great Again【论文笔记】
- 1.介绍
- 2.相关工作
-
- 2.1. From Single-path to Multi-branch
- 2.2.Effective Training of Single-path Models
- 2.3.Model Re-parameterization
- 2.4.Winograd Convolution
- 3. 通过结构重参数化构建RepVGG
-
- 3.1.Simple is Fast, Memory-economical, Flexible
- 3.2.Training-time Multi-branch Architecture
- 3.3. Re-param for Plain Inference-time Model
- 3.4. Architectural Specification
- 4.实验
-
- 4.1. RepVGG for ImageNet Classification
- 4.2. Structural Re-parameterization is the Key
- 4.3. Semantic Segmentation
- 4.4. Limitations
- 5.结论
- 参考文献

RepVGG是一种推理阶段的VGG-like型,训练阶段是用多分支拓扑的网络,仅仅使用了3×3卷积核ReLU。训练与推理的解耦通过结构重参数化(re-parmeterization)技术实现,所以它叫做RepVGG。
模型性能:On ImageNet, RepVGG reaches over 80% top-1 accuracy, which is the first time for a plain model, to the best of our knowledge. On NVIDIA 1080Ti GPU, RepVGG models run 83% faster than ResNet-50 or 101% faster than ResNet-101 with higher accuracy and show favorable accuracy-speed trade-off compared to the state-of-the-art models like EfficientNet and RegNet.
代码:github地址
1.介绍
文章这里列举了复杂模型较简单模型缺点:

影响实际速度因素有很多,FLOPs不能准确反映实际速度



文章贡献:

2.相关工作
2.1. From Single-path to Multi-branch
列举了GoogleNet、ResNet、DenseNet、NAS特点与缺点
2.2.Effective Training of Single-path Models

2.3.Model Re-parameterization
这里介绍了两种之前的重参数化工作:
- DiracNet:本文方法与DiracNet不同之处: 1) Our structural re-parameterization is implemented by the actual dataflow through a concrete structure which can be later converted into another, while DiracNet merely uses another mathematical expression of conv kernels for the ease of optimization. I.e., a structurally re-parameterized plain model is a real training-time multi-branch model, but a DiracNet is not. 2) The performance of a DiracNet is higher than a normally parameterized plain model but lower than a comparable ResNet, while RepVGG models outperform ResNets by a large margin.

- Asym Conv Block(ACB)

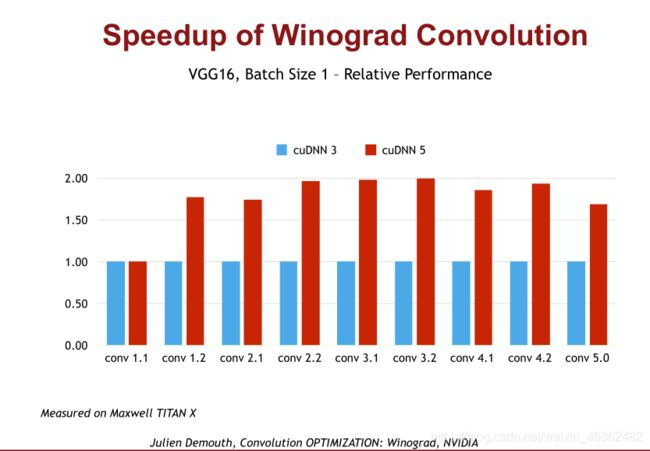
2.4.Winograd Convolution
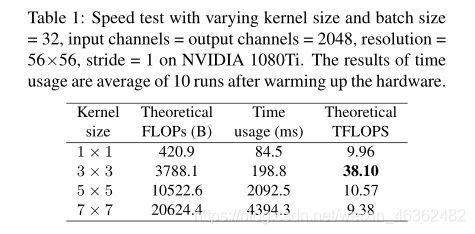
TFLOPS:Tera FLoating-point Operations Per Second
It is shown that the theoretical computational density of 3× 3 conv is around 4× as the others,suggesting that the total theoretical FLOPs is not a comparable proxy for the actual speed among different architectures.

细节:

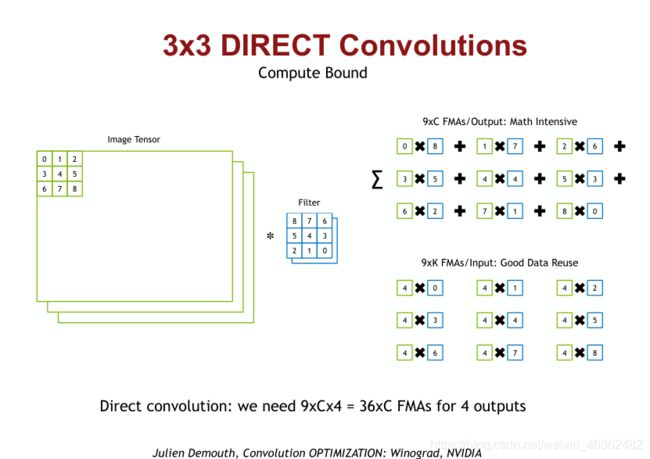
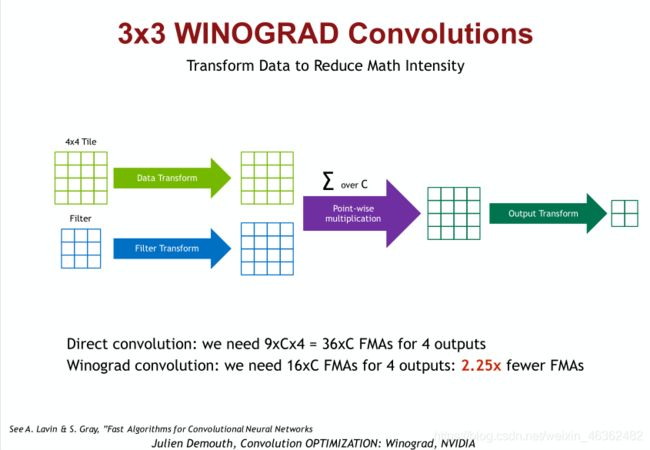
这里插入song han老师的CS231课程内关于winograd conv的描述:
3. 通过结构重参数化构建RepVGG
3.1.Simple is Fast, Memory-economical, Flexible
- Fast:E.g., VGG-16 has 8.4× FLOPs as EfficientNet-B3 but runs 1.8× faster on 1080Ti (Table. 4), which means the computational density of the former is 15× as the latter.
除了winograd conv带来的加速外FLOPs与速度差异的原因大致有两个(这些因素对速度影响较大,而FLOPs未考虑):

- Memory-economical:

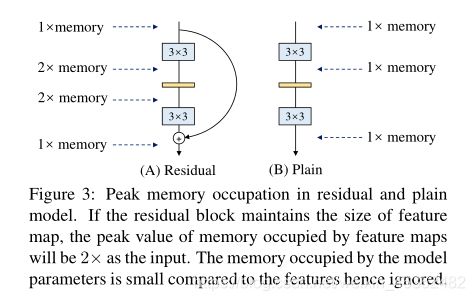
- Flexible:主要有两点:1、多分支结构合并时需要保证tensor的shape一致;2、多分支在通道剪枝上很费劲
3.2.Training-time Multi-branch Architecture
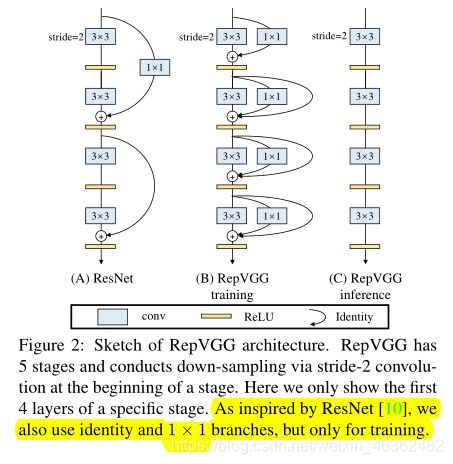
RepVGG重参数化方法由ResNet启发而来,跳跃连接相当于多个block不同层次聚合。而多分支貌似只是对于训练有好处。
ResNet相当于聚合了2^n 个块,即y=g(x)+f(x),g表示1x1操作。而RepVGG训练时相当于聚合了3^n 个块,y=x+g(x)+f(x),而推理时,y=h(x),h由单个卷积层实现,有训练而来的那几个分支变换而来。
3.3. Re-param for Plain Inference-time Model
合成推导:

合成图示:

即1x1与3x3合成时,可先补零,然后相加。
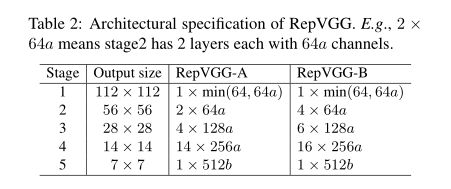
3.4. Architectural Specification
未使用max pooling,共设置5个stage的3x3 conv,每个stage的第一层conv步长为2。对图像分类任务,使用了全局平均池化。
设计思路:1) The first stage operates with large resolution, which is time-consuming, so we use onlyone layer for lower latency. 2) The last stage shall have more channels, so we use only one layer to save the parameters. 3) We put the most layers into the second last stage(with 14 × 14 output resolution on ImageNet), following ResNet and its recent variants (e.g., ResNet-101 uses 69 layers in its 14 × 14-resolution stage).
RepVGG-A stages:1,2,4,14,1
RepVGG-B has 2 more layers in stage2, 3 and 4。
layer width :[64,128,256,512]

进一步缩减参数量与运算量可用分组卷积思路,并参照shufflenet设计g:

4.实验
4.1. RepVGG for ImageNet Classification
on ImageNet1K: comprises 1.28M high-resolution images for training and 50K for validation from 1000 classes
实验RepVGG具体设置:
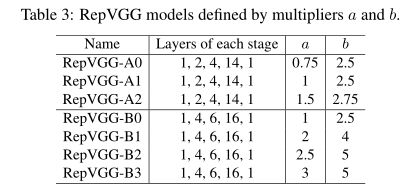
其中采用分组卷积的网络加上g2/g4表示
实验配置:We use a global batch size
of 256 on 8 GPUs, a learning rate initialized as 0.1 and cosine annealing for 120 epochs, standard SGD with momentum coefficient of 0.9 and weight decay of 10−4on the kernels of conv and fully-connected layers.
实验结果: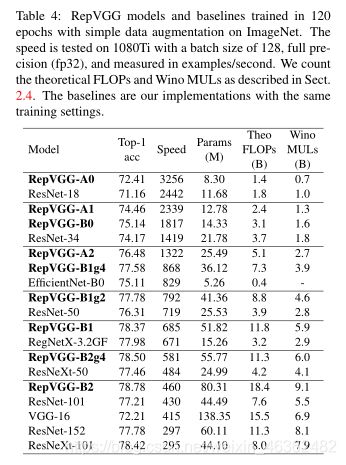
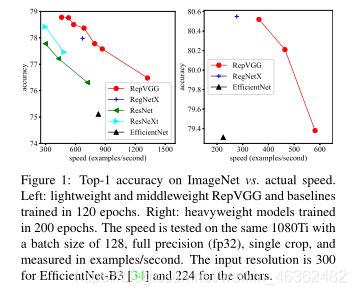
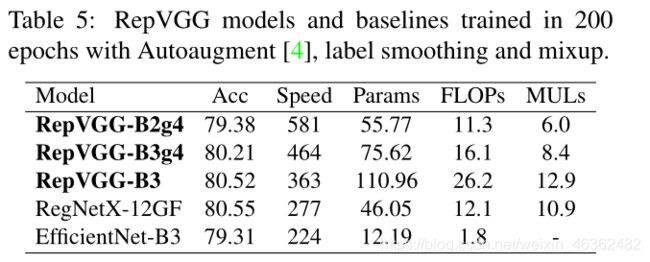
4.2. Structural Re-parameterization is the Key
关于 “re-parameterization technique”的消融实验(All the models are trained from scratch for 120 epochs with the same simple training settings described above):

其他变体以及baseline的消融实验:
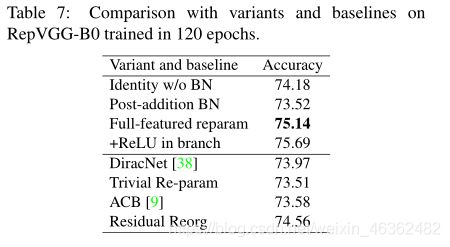
- Identity w/o BN:removes the BN in identity branch.
- Post-addition BN: removes the BN layers in the three branches and appends a BN layer after the addition. I.e., the position of BN is changed from pre-addition to post-addition.
- +ReLU in branches: inserts ReLU into each branch (after BN and before addition). Since such a block cannot be converted into a single conv layer, it is of no practical use, and we merely desire to see whether more nonlinearity will bring higher performance.
- DiracNet : adopts a well-designed re-parameterization of conv kernels, as introduced in Sect. 2.2. We use its official PyTorch code to build the layers to replace the original 3 × 3 conv.
- Trivial Re-param: is a simpler re-parameterization of conv kernels by directly adding an identity kernel to the 3 × 3 kernel, which can be viewed a degraded version of DiracNet (ˆW = I + W ).
- Asymmetric Conv Block (ACB): can be viewed as another form of structural re-parameterization. We compare with ACB to see whether the improvement of our structural re-parameterization is due to the component-level over-parameterization (i.e., the extra parameters making every 3 × 3 conv stronger).
- Residual Reorg: builds each stage by re-organizing it
具体分析:

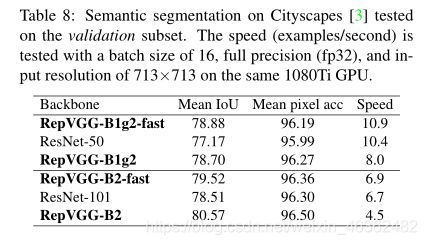
4.3. Semantic Segmentation
- dataset:Cityscapes, which contains 5K finely annotated images and 19 categories.
- framework:PSPNet
- details: a poly learning rate policy with base of 0.01 and power of 0.9, weight decay of 10−4and a global batch size of 16 on 8 GPUs for 40 epochs.

4.4. Limitations
适用于GPU较大模型,尽管其比ResNet性能好,但在移动端上,速度与精度的trade-off比不上mobilenet、shufflenet等。
5.结论

参考文献
【1】Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, Jian Sun:RepVGG: Making VGG-style ConvNets Great Again. CoRR abs/2101.03697 (2021)
论文地址