GPT2中文文本生成对话应用尝试
目录
1、数据清洗
2、模型训练
3、模型推理
4、效果展示
文本对话是一个很复杂的任务,难度比较大。按照对话文本产生的方式可以分为检索式和生成式;按照技术实现的方式可以分为端到端和pipeline的方式。为了保证对话的多样性和丰富性,以及减少流程的繁琐例如构建对话管理、对话理解等模块,我们基于GPT2模型以及GPT2-chat项目,在保险领域进行了中文文本生成对话应用,尝试。总而言之,本文并不是一个创新性的内容,更多的是一种现有技术和模型在业务中的尝试和效果验证。
背景前提已经为客户搭建了一套基于FAQ的问答对话系统,效果也还可以。为了提供一个不一样的体验,保证对话的多样性和丰富性,采用GPT2模型仿照GPT2-chat项目的整体思路对保险领域下对话生成进行了一个应用尝试。
1、数据清洗
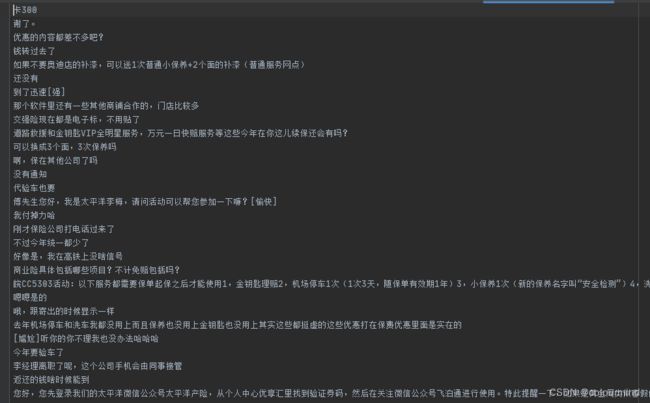
数据获取和清洗,这个是最为关键的一步,拿到300万条对话约30万通的对话记录如下:

清除噪声、微信表情包、特殊字符等等以及无意义的回复等,把同一个坐席连续说的话用分号拼接成一句话,最后的数据格式如下:

注意训练模型的时候分为微调和预训练,那数据格式也是不一样的,预训练的数据就是其中的每一句话:
2、模型训练
模型训练分为预训练和微调;
预训练的时候模型的输入:text
微调的时候模型的输入:text_客户[SEP]text_坐席[SEP]text_客户[SEP]text_坐席
读取数据做词典映射的时候,代码如下:
from torch.utils.data import Dataset
import torch
import os
from tqdm import tqdm
class MyDataset(Dataset):
"""
"""
def __init__(self, file_path, args,logger):
self.file_path = file_path
self.train_type = args.train_type
self.tokenizer = args.tokenizer
self.max_len = args.max_len
self.logger = logger
self.input_list = self.texts_tokenize()
def texts_tokenize(self):
cache_path = self.file_path.replace('.txt','_cache.bin')
if os.path.exists(cache_path):
self.logger.info('load datas from cache_path:%s'%(cache_path))
datas = torch.load(cache_path)
else:
self.logger.info('cache_path not exists process datas')
if self.train_type == 'pretrain':
datas = self.process_pretrain_data()
else:
datas = self.process_finetune_data()
torch.save(datas, cache_path)
return datas
def process_pretrain_data(self):
with open(self.file_path,'r',encoding='utf-8') as f:
lines = f.readlines()
datas = []
for line in tqdm(lines,desc='process_pretrain_data'):
line = line.strip('\n').strip('\r\n')
if len(line) < self.max_len:
input_ids = self.tokenizer(line)['input_ids']
attention_mask = self.tokenizer(line)['attention_mask']
input_ids = torch.tensor(input_ids,dtype=torch.long)
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
labels = [id if id != 0 else -100 for id in input_ids]
labels = torch.tensor(labels, dtype=torch.long)
datas.append((input_ids, attention_mask, labels))
return datas
def process_finetune_data(self):
with open(self.file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
datas = []
s = ""
for line in tqdm(lines,desc='process_finetune_data'):
if line != '\n' and line != '\r\n':
line = line.strip('\n').strip('\r\n').strip('坐席:').strip('客户:')
s += line + '[SEP]'
else:
s = s.strip('[SEP]')[0:self.max_len]
if len(s) <= self.max_len:
input_ids = self.tokenizer(s)['input_ids']
attention_mask = self.tokenizer(s)['attention_mask']
input_ids = torch.tensor(input_ids, dtype=torch.long)
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
labels = [ id if id !=0 else -100 for id in input_ids]
labels = torch.tensor(labels, dtype=torch.long)
datas.append((input_ids,attention_mask, labels))
s = ""
return datas
def __getitem__(self, index):
input_ids = self.input_list[index][0]
attention_mask = self.input_list[index][1]
labels = self.input_list[index][2]
return input_ids, attention_mask, labels
def __len__(self):
return len(self.input_list)
padding的方式
模型训练的时候使用GPU和采用batch的方式,需要特别注意的是——padding的方式
这里的padding的方式和Bert模型是不同的,bert的padding是在句子后面,而GPT2类生成模型必须实在句子前面,不然padding放在句子后面,padding会对生成的结果有影响,导致inference的时候batch内最长句子不同,padding的长度不同,相同的句子最后的结果也不一致
一个batch的数据
[
"要3天后啊[SEP]对的",
"你[SEP]您好"
]那么GPT2的padding方式如下:
[
"要3天后啊[SEP]对的",
"[PAD][PAD][PAD][PAD]你[SEP]您好"
]代码实现(前向后向padding都支持):
def pad_sequence(sequences, padding_value=0,padding='pre'):
max_len = max([s.size(0) for s in sequences])
max_size = sequences[0].size()
trailing_dims = max_size[1:]
out_dims = (len(sequences), max_len) + trailing_dims
out_tensor = sequences[0].new_full(out_dims, padding_value)
for i, tensor in enumerate(sequences):
length = tensor.size(0)
if padding == 'pre':
out_tensor[i, -length:, ...] = tensor
else:
# use index notation to prevent duplicate references to the tensor
out_tensor[i, 0:length, ...] = tensor
return out_tensor
def collate_fn(batch):
input_ids, attention_mask,labels = zip(*batch)
input_ids = pad_sequence(input_ids, padding_value=0,padding='pre')
attention_mask = pad_sequence(attention_mask, padding_value=0, padding='pre')
labels = pad_sequence(labels, padding_value=-100, padding='pre')
return input_ids, attention_mask, labels由于GPT2没有开源的中文权重,因此我们需要自己重新预训练一个中文的权重;这里词典和权重以及tokenizer都是直接使用Bert的,而模型结构使用GPT2。训练代码如下:
import argparse
import torch
import torch.nn.functional as F
import logging
from datetime import datetime
import os
from torch.utils.data import DataLoader
import transformers
import pickle
from transformers import BertTokenizerFast, GPT2LMHeadModel, GPT2Config
import torch.nn.utils.rnn as rnn_utils
from data_reader.mydataset import MyDataset
from torch.optim import AdamW
from tools.progressbar import ProgressBar
torch.backends.cudnn.enable =True
def set_args():
parser = argparse.ArgumentParser()
parser.add_argument('--train_type', default='finetune_std', type=str, required=False, help='设置使用哪些显卡')
# parser.add_argument('--train_type', default='pretrain', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--device', default='0', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--vocab_path', default='vocab/vocab.txt', type=str, required=False,
help='词表路径')
parser.add_argument('--model_config', default='small_config/config.json', type=str, required=False,
help='设置模型参数')
parser.add_argument('--data_path', default='data/', type=str, required=False, help='训练集路径')
parser.add_argument('--max_len', default=512, type=int, required=False, help='训练时,输入数据的最大长度')
parser.add_argument('--log_path', default='logs/', type=str, required=False, help='训练日志存放位置')
parser.add_argument('--log', default=True, help="是否记录日志")
parser.add_argument('--ignore_index', default=-100, type=int, required=False, help='对于ignore_index的label token不计算梯度')
# parser.add_argument('--input_len', default=200, type=int, required=False, help='输入的长度')
parser.add_argument('--epochs', default=100, type=int, required=False, help='训练的最大轮次')
parser.add_argument('--batch_size', default= 8, type=int, required=False, help='训练的batch size')
parser.add_argument('--lr', default=2.6e-5, type=float, required=False, help='学习率')
parser.add_argument('--eps', default=1.0e-09, type=float, required=False, help='衰减率')
parser.add_argument('--log_step', default=1000, type=int, required=False, help='多少步汇报一次loss')
parser.add_argument('--gradient_accumulation_steps', default=8, type=int, required=False, help='梯度积累')
parser.add_argument('--max_grad_norm', default=2.0, type=float, required=False)
parser.add_argument('--save_model_path', default='model_output/', type=str, required=False,
help='模型输出路径')
# parser.add_argument('--seed', type=int, default=None, help='设置种子用于生成随机数,以使得训练的结果是确定的')
parser.add_argument('--num_workers', type=int, default=0, help="dataloader加载数据时使用的线程数量")
parser.add_argument('--patience', type=int, default=0, help="用于early stopping,设为0时,不进行early stopping.early stop得到的模型的生成效果不一定会更好。")
parser.add_argument('--warmup_steps', type=int, default=4000, help='warm up步数')
# parser.add_argument('--label_smoothing', default=True, action='store_true', help='是否进行标签平滑')
args = parser.parse_args()
return args
def create_logger(args):
"""
将日志输出到日志文件和控制台
"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
formatter = logging.Formatter('%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s')
# 创建一个handler,用于写入日志文件
file_handler = logging.FileHandler(filename=args.log_path)
file_handler.setFormatter(formatter)
file_handler.setLevel(logging.INFO)
logger.addHandler(file_handler)
# 创建一个handler,用于将日志输出到控制台
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
console.setFormatter(formatter)
logger.addHandler(console)
return logger
def pad_sequence(sequences, padding_value=0,padding='pre'):
max_len = max([s.size(0) for s in sequences])
max_size = sequences[0].size()
trailing_dims = max_size[1:]
out_dims = (len(sequences), max_len) + trailing_dims
out_tensor = sequences[0].new_full(out_dims, padding_value)
for i, tensor in enumerate(sequences):
length = tensor.size(0)
if padding == 'pre':
out_tensor[i, -length:, ...] = tensor
else:
# use index notation to prevent duplicate references to the tensor
out_tensor[i, 0:length, ...] = tensor
return out_tensor
def collate_fn(batch):
input_ids, attention_mask,labels = zip(*batch)
input_ids = pad_sequence(input_ids, padding_value=0,padding='pre')
attention_mask = pad_sequence(attention_mask, padding_value=0, padding='pre')
labels = pad_sequence(labels, padding_value=-100, padding='pre')
return input_ids, attention_mask, labels
def train_epoch(model, train_dataloader, optimizer, scheduler, logger, epoch, args):
all_correct = 0
all_total = 0
model.train()
device = args.device
# pad_id = args.pad_id
# sep_id = args.sep_id
ignore_index = args.ignore_index
epoch_start_time = datetime.now()
total_loss = 0 # 记录下整个epoch的loss的总和
# epoch_correct_num:每个epoch中,output预测正确的word的数量
# epoch_total_num: 每个epoch中,output预测的word的总数量
epoch_correct_num, epoch_total_num = 0, 0
pbar = ProgressBar(n_total=len(train_dataloader), desc='Training')
for batch_idx, (input_ids, attention_mask, labels) in enumerate(train_dataloader):
# 捕获cuda out of memory exception
try:
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
outputs = model.forward(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
loss = loss.mean()
# 统计该batch的预测token的正确数与总数
batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)
# 统计该epoch的预测token的正确数与总数
epoch_correct_num += batch_correct_num
epoch_total_num += batch_total_num
# 计算该batch的accuracy
batch_acc = batch_correct_num / batch_total_num
total_loss += loss.item()
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
all_total += batch_total_num
all_correct += batch_correct_num
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
#梯度累加——进行一定step的梯度累计之后,更新参数
if (batch_idx + 1) % args.gradient_accumulation_steps == 0:
# 更新参数
optimizer.step()
# 更新学习率
scheduler.step()
# 清空梯度信息
optimizer.zero_grad()
if (batch_idx + 1) % args.log_step == 0:
logger.info(
"batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(
batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))
pbar(batch_idx, {'loss': loss.item()})
del input_ids, outputs
except RuntimeError as exception:
if "out of memory" in str(exception):
logger.info("WARNING: ran out of memory")
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
else:
print(input_ids.shape)
print(labels.shape)
logger.info(str(exception))
raise exception
# 记录当前epoch的平均loss与accuracy
epoch_mean_loss = total_loss / len(train_dataloader)
epoch_mean_acc = epoch_correct_num / epoch_total_num
# writer.add_scalar('train_loss', epoch_mean_loss, global_step=len(train_dataloader) * args.epochs)
# writer.add_scalar('train_acc', epoch_mean_acc,global_step=len(train_dataloader) * args.epochs)
logger.info("epoch {}: train_loss {}, train_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))
# # save model
# if epoch % 10 == 0:
# logger.info('saving model for epoch {}'.format(epoch + 1))
# model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))
# if not os.path.exists(model_path):
# os.mkdir(model_path)
# model_to_save = model.module if hasattr(model, 'module') else model
# model_to_save.save_pretrained(model_path)
# logger.info('epoch {} finished'.format(epoch + 1))
epoch_finish_time = datetime.now()
logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))
return epoch_mean_loss,epoch_mean_acc
def validate_epoch(model, validate_dataloader, logger, epoch, args):
logger.info("start validating")
model.eval()
all_correct = 0
all_total = 0
device = args.device
# pad_id = args.pad_id
# sep_id = args.sep_id
ignore_index = args.ignore_index
epoch_start_time = datetime.now()
total_loss = 0 # 记录下整个epoch的loss的总和
# epoch_correct_num:每个epoch中,output预测正确的word的数量
# epoch_total_num: 每个epoch中,output预测的word的总数量
epoch_correct_num, epoch_total_num = 0, 0
pbar = ProgressBar(n_total=len(validate_dataloader), desc='Valing')
for batch_idx, (input_ids, attention_mask, labels) in enumerate(validate_dataloader):
# 捕获cuda out of memory exception
try:
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
outputs = model.forward(input_ids, attention_mask=attention_mask, labels=labels)
logits = outputs.logits
loss = outputs.loss
loss = loss.mean()
# 统计该batch的预测token的正确数与总数
batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)
# 统计该epoch的预测token的正确数与总数
epoch_correct_num += batch_correct_num
epoch_total_num += batch_total_num
total_loss += loss.item()
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
all_total += batch_total_num
all_correct += batch_correct_num
pbar(batch_idx, {'loss': loss.item()})
del input_ids, outputs
except RuntimeError as exception:
if "out of memory" in str(exception):
logger.info("WARNING: ran out of memory")
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
else:
logger.info(str(exception))
raise exception
# 记录当前epoch的平均loss与accuracy
epoch_mean_loss = total_loss / len(validate_dataloader)
epoch_mean_acc = epoch_correct_num / epoch_total_num
# writer.add_scalar('train_loss', epoch_mean_loss, global_step=len(train_dataloader) * args.epochs)
# writer.add_scalar('train_acc', epoch_mean_acc,global_step=len(train_dataloader) * args.epochs)
logger.info("epoch {}: val_loss {}, val_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))
return epoch_mean_loss, epoch_mean_acc
def train(model, logger, train_dataset, validate_dataset, args):
train_dataloader = DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True, collate_fn=collate_fn
)
validate_dataloader = DataLoader(validate_dataset, batch_size=args.batch_size, shuffle=True,
collate_fn=collate_fn)
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs
optimizer = AdamW(model.parameters(), lr=args.lr, eps=args.eps)
args.warmup_steps = max(len(train_dataloader)*0.1,args.warmup_steps)
scheduler = transformers.get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
logger.info('starting training')
# 用于记录每个epoch训练和验证的loss
train_losses, validate_losses = [], []
# 记录验证集的最小loss
# best_val_acc = 0.506633
best_val_acc = 0
early_stop = 5
no_improving = 0
# 开始训练
for epoch in range(args.epochs):
# ========== train ========== #
train_loss,train_acc = train_epoch(
model=model, train_dataloader=train_dataloader,
optimizer=optimizer, scheduler=scheduler,
logger=logger, epoch=epoch, args=args)
train_losses.append(train_loss)
logger.info('saving train model for epoch {}'.format(epoch + 1))
model_path = os.path.join(args.save_model_path,str(epoch))
if not os.path.exists(model_path):
os.mkdir(model_path)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(model_path)
args.model_config.save_pretrained(model_path)
# ========== validate ========== #
validate_loss, val_acc = validate_epoch(
model=model, validate_dataloader=validate_dataloader,
logger=logger, epoch=epoch, args=args)
validate_losses.append(validate_loss)
# 保存当前困惑度最低的模型,困惑度低,模型的生成效果不一定会越好
if best_val_acc < val_acc:
logger.info('saving current best model for epoch {}'.format(epoch + 1))
best_val_acc = val_acc
model_path = os.path.join(args.save_model_path, "best_val")
if not os.path.exists(model_path):
os.mkdir(model_path)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(model_path)
args.model_config.save_pretrained(model_path)
no_improving = 0
else:
no_improving += 1
logger.info('train_acc:%.6f val_acc:%.6f best_val_acc:%.6f '%(train_acc, val_acc, best_val_acc))
logger.info('training finished')
logger.info("train_losses:{}".format(train_losses))
logger.info("validate_losses:{}".format(validate_losses))
def calculate_acc(logit, labels, ignore_index=-100):
logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))
labels = labels[..., 1:].contiguous().view(-1)
_, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index
# 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1
non_pad_mask = labels.ne(ignore_index)
n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item()
n_word = non_pad_mask.sum().item()
return n_correct, n_word
def main():
# 初始化参数
args = set_args()
timestr = datetime.now().strftime('%Y-%m-%d_%H')
args.log_path = os.path.join(args.log_path, args.train_type)
if not os.path.exists(args.log_path):
os.makedirs(args.log_path)
args.log_path = os.path.join(args.log_path, timestr+'.log')
# 设置使用哪些显卡进行训练
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
if args.batch_size < 2048 and args.warmup_steps <= 4000:
print('[Warning] The warmup steps may be not enough.\n' \
'(sz_b, warmup) = (2048, 4000) is the official setting.\n' \
'Using smaller batch w/o longer warmup may cause ' \
'the warmup stage ends with only little data trained.')
# 创建日志对象
logger = create_logger(args)
# 当用户使用GPU,并且GPU可用时
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
args.device = device
logger.info('using device:{}'.format(device))
# # 初始化tokenizer
# tokenizer = BertTokenizerFast(vocab_file=args.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")
tokenizer = BertTokenizerFast.from_pretrained('./vocab')
args.tokenizer = tokenizer
args.sep_id = tokenizer.sep_token_id
args.pad_id = tokenizer.pad_token_id
args.cls_id = tokenizer.cls_token_id
if args.train_type != "pretrain":
args.batch_size = args.batch_size//2
logger.info('args.batch_size:%d'%args.batch_size)
# 创建模型的输出目录
if args.train_type == "pretrain":
args.save_model_path = os.path.join(args.save_model_path, 'pretrain_6_layers')
elif args.train_type == "finetune_std":
args.save_model_path = os.path.join(args.save_model_path, 'finetune_std_final')
else:#mmi模型
args.save_model_path = os.path.join(args.save_model_path, 'finetune_mmi')
if not os.path.exists(args.save_model_path):
os.makedirs(args.save_model_path)
logger.info('save_model_path: {}'.format(args.save_model_path))
model_config = GPT2Config.from_json_file(args.model_config)
args.model_config = model_config
# 创建模型
#从0预训练
if args.train_type == "pretrain":
# 从0开始预训练
model = GPT2LMHeadModel(config=model_config)
# #继续预训练
# model = GPT2LMHeadModel.from_pretrained('./model_output/pretrain/')
#领域语料预训练后,微调
else:#finetune
# model = GPT2LMHeadModel.from_pretrained('./model_output/pretrain/')
# model = GPT2LMHeadModel.from_pretrained('./model_output/pretrain_small/')
# model = GPT2LMHeadModel.from_pretrained('./model_output/pretrain_6_layers/')
model = GPT2LMHeadModel.from_pretrained('./model_output/finetune_std_padding_left_6_layers_biggest_data/')
model = model.to(device)
logger.info('model config:\n{}'.format(model.config.to_json_string()))
assert model.config.vocab_size == tokenizer.vocab_size
# 计算模型参数数量
num_parameters = 0
parameters = model.parameters()
for parameter in parameters:
num_parameters += parameter.numel()
logger.info('number of model parameters: {}'.format(num_parameters))
# 加载训练集和验证集
# ========= Loading Dataset ========= #
if args.train_type == "pretrain":
train_path = os.path.join(args.data_path, 'pretrain_data', 'train.txt')
val_path = os.path.join(args.data_path, 'pretrain_data', 'val.txt')
elif args.train_type == "finetune_std":
train_path = os.path.join(args.data_path, 'finetune_std_data', 'train_biggest.txt')
val_path = os.path.join(args.data_path, 'finetune_std_data', 'val.txt')
else:
train_path = os.path.join(args.data_path, 'finetune_mmi_data', 'train.txt')
val_path = os.path.join(args.data_path, 'finetune_mmi_data', 'val.txt')
train_dataset = MyDataset(train_path,args,logger)
validate_dataset = MyDataset(val_path, args,logger)
train(model, logger, train_dataset, validate_dataset, args)
if __name__ == '__main__':
main()
代码中给出了预训练和微调的全部代码,当然还有数据加载的代码;注意从头预训练一个GPT2和微调都是采用同一个模型结构GPT2LMHeadModel模型,只不过是前者没有加载权重,随机初始化的权重;后者是加载了预训练过的权重。由于数据量巨大,采用3090都训练了几个星期。训练过程就不一一展示了。
后面为了保证推理速度能够满足并发需求,希望batch_size=100的时候推理能在1S内结束,那就需要对模型进行压缩。压缩也很简单,直接从头预训练一个6层的GPT2然后再进行微调。代码和之前的一样,只是配置不同。
3、模型推理
模型推理要注意的是:第一batch解码的时候,要考虑到padding的影响,只有padding在句子的左边才不会对生成产生影响;第二就是解码策略的选择,这个就需要多去尝试,topk、topp、repetition_penalty(重复惩罚系数)、num_beams等参数(具体的理解和参考之前的文章——浅谈文本生成或者文本翻译解码策略);最后就是变量占用显存的释放
代码如下:
def text_batch_generate(model,tokenizer,args, texts):
datas = []
attention_masks = []
for text in texts:
input_ids = tokenizer(text)['input_ids']
attention_mask = tokenizer(text)['attention_mask']
input_ids = torch.tensor(input_ids,dtype=torch.long)
attention_mask = torch.tensor(attention_mask,dtype=torch.long)
datas.append(input_ids)
attention_masks.append(attention_mask)
datas = pad_sequence(datas, padding_value=0, padding='pre')
attention_masks = pad_sequence(attention_masks, padding_value=0, padding='pre')
curr_input_tensor = datas.to(args.device)
attention_masks = attention_masks.to(args.device)
batch = {'input_ids': curr_input_tensor, 'attention_mask': attention_masks}
max_length = 64 + curr_input_tensor.shape[1]
num_returns = 3
topktopp_translations = model.generate(**batch, top_k=8, num_return_sequences=num_returns, max_length=max_length,do_sample=True,repetition_penalty=0.8, use_cache=True, num_beams=num_returns).detach().cpu().tolist()
res = tokenizer.batch_decode(topktopp_translations, skip_special_tokens=True)
del topktopp_translations
del batch
del curr_input_tensor
del attention_masks
torch.cuda.empty_cache()
lengths = []
for text in texts:
for _ in range(num_returns):
lengths.append(len(text.replace('[SEP]','')))
res = [re.replace(' ', '')[length:] for length,re in zip(lengths,res)]
max = 0
index = 0
count = 0
final_res = []
for i, re in enumerate(res):
if count < num_returns:
if len(re) > max:
max = len(re)
index = i
count += 1
else:
final_res.append(res[index])
max = 0
count = 0
if count < num_returns:
if len(re) > max:
max = len(re)
index = i
count += 1
if len(final_res) < len(res)//num_returns:
final_res.append(res[index])
print(final_res)
assert len(final_res) == len(res)//num_returns
return final_res简单的说一说解码过程,首先把文本通过tokenizer映射成token,使用pad_pad_sequence进行padding;然后就把tensors输入到模型中得到解码结果,主要就是采用了如下函数(huggingface出品的transformers中)
model.generate(**batch, top_k=8, num_return_sequences=num_returns, max_length=max_length,do_sample=True,repetition_penalty=0.8, use_cache=True, num_beams=num_returns)
它内置了5中解码模式,把贪心、beamsearch、topk和topp都融合在一起了。
4、效果展示
做了一个demo,采用flask+html+js+css(前端代码就不展示了,网上到处都是,我也是网上找的)来展示这个GPT2训练的端到端的模型效果如何
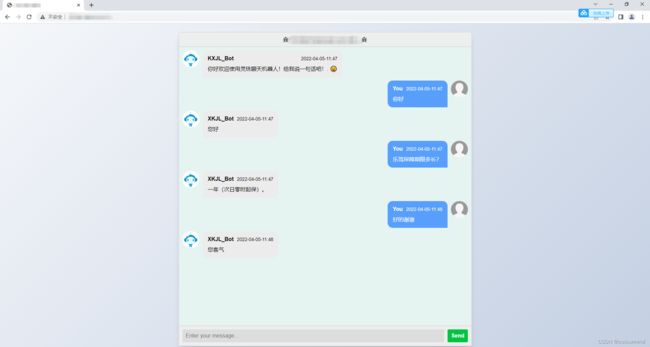
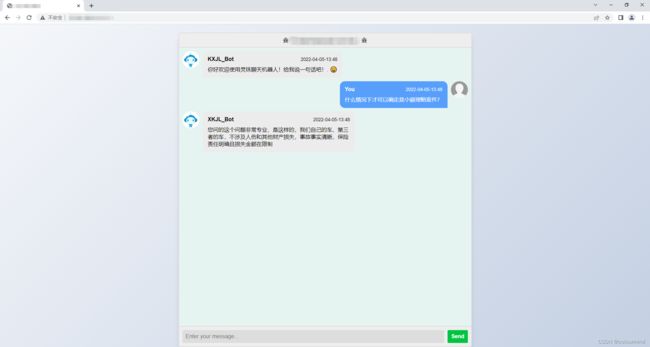
不错的对话逻辑
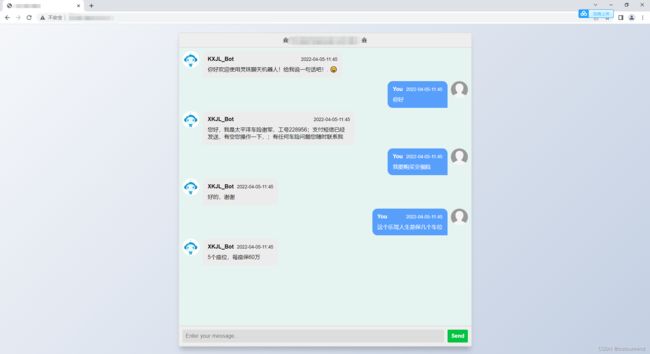
还行
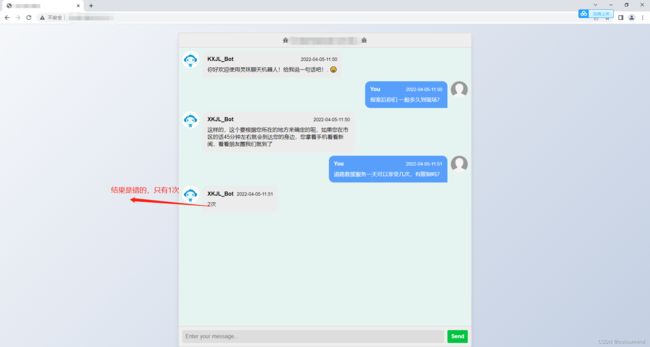
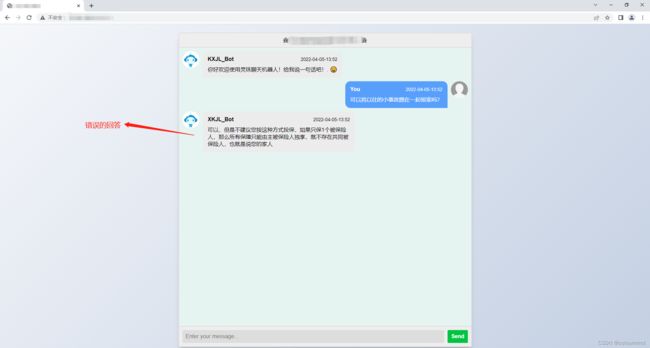
逻辑错误
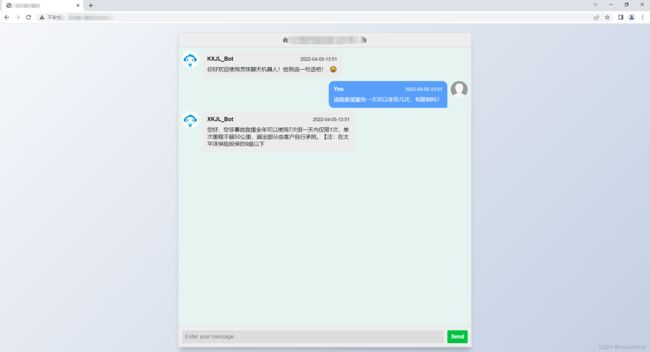
单轮回答
错误的回答
总体来说对话效果还是稍微差一点。单轮的问答大部分还是不错的,符合我们的预期;能把语料中的知识能学习到;但是多轮的时候就不可控了,还有一些回答逻辑错误,重复回答,以及不符合角色定位等等。如果能把这些问题都解决好的话,那么端到端的生成就可以作为商用了;不过如果用闲聊的语料进行训练,那么只要保证语料的质量,一个生成式闲聊的机器人还是有可能的。
本文主要是把GPT2这种生成模型,依赖GPT2-chat项目的思路进行了语料的迁移训练和效果验证,发现使用在问答要求比较高的领域和业务场景下(逻辑强、回答准确)还是很欠缺的;但是回答的多样性和丰富性确实很好。
参考文章
transformers
基于GPT2的中文闲聊机器人/GPT2 for Chinese chitchat