【网络设计】ConvNeXt:A ConvNet for the 2020s
文章目录
-
- 一、背景
- 二、方法
-
- 2.1 训练方法
- 2.2 宏观设计
- 2.3 ResNeXt-ify:79.5%→80.5%
- 2.4 Inverted Bottleneck: 80.5%→80.6%
- 2.5 Large Kernel Sizes
- 2.6 微观设计
- 三、实验
- 四、结论

论文链接:https://arxiv.org/pdf/2201.03545.pdf
代码链接:https://github.com/facebookresearch/ConvNeXt
一、背景
2020年出现了 ViT,是基于 Transformer 的网络模型,并且很快超越了基于 CNN 的网络模型的效果。
原始 ViT 由于只能提取单层特征,无法使用于目标检测和分割等任务。
层级 Transformer(Swin 等),引入了卷积神经网络的特性,提出了一个基于 Transformer 的 backbone,并且在下有任务上取得了很好的效果。
但这种效果应该来源于 Transformer 的内在优势,而非卷积固有的归纳偏差能力。
所以本文中,作者探索了 CNN 的边界,使用 Transformer 的设计思想,重新优化了标准 ResNet。
卷积神经网络有很多内在的归纳偏置的能力,有助于其适应于不同的视觉任务。比如最重要的平移不变性,这个特性就很适用于目标检测。卷积神经网络的计算效率也比较高,因为卷积核是共享的。
Transformer 是从 NLP 衍生到图像任务上的,这也使得两个任务的网络形式有了进一步的统一,除过图像需要 patch 之外,其他都很类似。ViT 没有引入图像的相关归纳偏置,且和 NLP 使用的网络结构很相似。随着大模型和大数据集的引入,ViT 的效果比 CNN 强很多,尤其在图像分类上,但图像任务不仅仅只有图像分类。Transformer 没有卷积网络的归纳偏置能力,所以原始的 ViT 模型无法成为一个通用的 backbone,最重要的一点在于计算量,ViT 内部使用的 attention 结构计算量是输入图像的平方倍,所以如果输入图像分辨率增大的话,计算量会提高很多。
Swin Transformer 是一个重要的转折,该方法将 sliding window 引入了 Transformer,和卷积网络非常类似,也证明了 Transformer 能够作为 backbone,并且能够在除过图像分类外的场景取得 SOTA 的效果,
不同于卷积的逐步进步,Transformer一提出的效果就是很好的,所以本文主要对比卷积和 Transformer 的架构差异,并测试纯卷积网络的极限。

二、方法
如何修正卷积网络?
作者对比:
- ResNet50 和 Swin-T , FLOPs 大约 4.5 × 1 0 9 4.5 \times 10^9 4.5×109
- ResNet200 和 Swin-B, FLOPs 大约 15.0 × 1 0 9 15.0 \times 10^9 15.0×109
作者探索的过程如下,如图2所示:
- 训练 ResNet50 :使用和 Transformer 相同的训练方式训练 ResNet50,然后和原始训练 ResNet50 的结果做对比,作为基准
- 修正的设计原则:
- 宏观设计
- ResNeXt
- inverted bottleneck
- 大卷积核
- 不同层的微观设计

2.1 训练方法
作者使用 DeiT 和 Swin 的训练方法,epoch 从 90 增加到 300,AdamW 优化器,各种数据增强方式,使得 ResNet50 的准确率从 76.1% 提升到了 78.8%。这也说明了卷积网络没有 Transformer 效果好的原因也和训练方式有关。
2.2 宏观设计
由于 Swin 也是多级的网络结构,每个stage的特征图分辨率是不同的,所以,以下两个问题的考虑是很有必要的:
1、改变 stage compute ratio: 78.8% → 79.4%
原始的 ResNet 在不同 stage 的计算量分布其实是依靠经验性的,最重的 res4 stage 主要是向下兼容下游任务,如目标检测在 14x14 的特征图上连接检测头。但 Swin-T 每个 stage 的计算量比率基本为 1:1:3:1,更大的网络是 1:1:9:1,所以作者将 ResNet50 的每个 stage 中的 blocks 的个数设置从 (3, 4, 6, 3) 修改为 (3, 3, 9, s3)。该操作将准确率从 78.8% 提高到了 79.4%。
2、改变 stem cell structure 为 “Patchify”:79.4%→79.5%
Stem 的设计决定了图片的前处理方式,ResNet 的 stem 一般都会降低输入图像的分辨率,ResNet 的 stem 是步长为 2 的 7x7 卷积,后面跟随一个 max pooling,输入图像总共会下采样 4 倍。但 Transformer 是使用不重叠的卷积对图像进行分块。所以此处作者也使用了类似的方法,使用步长为 4 的 4x4 卷积,这一操作将准确率从 79.4% 提升到了 79.5%。
2.3 ResNeXt-ify:79.5%→80.5%
作者也参考了 ResNeXt 的设计,因为 ResNeXt 比原始的 ResNet 有着更好的 FLOPs 和 accuracy 平衡,主要思想是卷积被分成了不同组。
所以,本文作者使用了 depth-wise 卷积,该卷积其实类似于 self-attention 中的加权求和,并且很大程度上降低了计算量。所以,作者提升了网络的宽度到和 Swin-T 相同(64→96),准确率提高到了 80.5%。

2.4 Inverted Bottleneck: 80.5%→80.6%
Transformer block 中的一个很重要的设计师 inverted bottleneck,也就是 MLP 的 hidden 层维度是输入维度的 4 倍(图4),在ConvNets中使用的扩展比为 4,图 3 的 a 到 b 展示了相关改变。
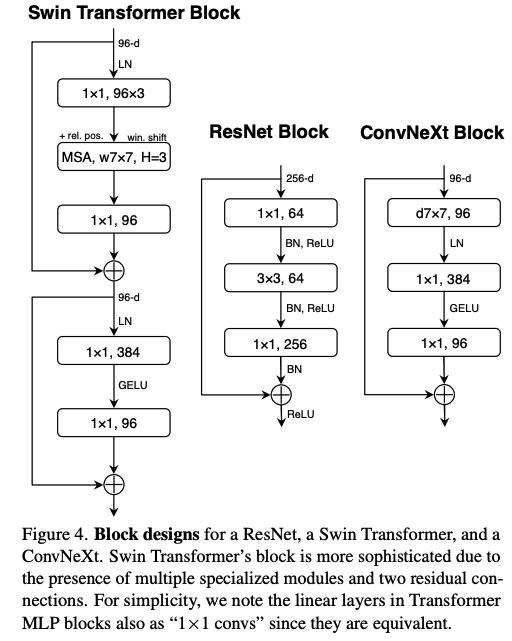
2.5 Large Kernel Sizes
由于 Transformer 中的 self-attention 和卷积中的卷积核卷积是有较大不同的,self-attention 能够捕捉全局的特征,尽管 Swin 的 window size 大小为 7 ,那也比 ResNet 中的 3 大很多。
1、将 depth-wise 层向上移动:图 3b 到图 3c ,80.6%→79.9%
为了探索大卷积的效果,作者将 depth-wise 卷积的位置向上移动了,图 3b 到图 3c,这和 Transformer 类似,Transformer 的 MSA block 是在 MLP 之前的。由于作者已经采用了 inverted bottleneck block,所以复杂的模块(MSA,large-kernel conv)就会有更少的通道。FLOPs 降低到了 4.1 G,准确率降低到了 79.9%
2、增大卷积核
作者使用了多种不同大小的卷积核,包括 3, 5, 7, 9, 11。效果从 79.9% (3x3)提升到了 80.6%(7x7),并且效果在 7x7 的时候已经达到饱和了。所以作者都是使用了 7x7 的 depth-wise 卷积。
2.6 微观设计
1、使用 GELU 替换 ReLU
虽然没有带来效果的提升,仍然是 80.6%,但作者仍然认为 GELU 效果更好一些
2、使用更少的激活函数:80.6%→81.4%
参考 Transformer,作者移除了两个 BN 层,只在 1x1 卷积前面保留了一个 BN 层,将效果提升到了 81.4%,超越了 Swin-T 的效果。同时,作者发现在每个 block 之前都使用 BN 不会提高效果。
3、使用 LN 代替 BN:81.4%→81.5%
直接在原始 ResNet 中替换 BN 并不会带来提升,反而会带来效果下降,但在整体做了修改之后替换 BN,就可以得到效果的提升,提升到了 81.5%。
4、分离下采样层:
在 ResNet 中,空间下采样一般都是使用步长为 2 的 3x3 卷积,在 Swin 中,在每两个 stage 中间都会使用分离的下采样层,所以,作者也使用了步长为 2 的 2x2 大小的卷积来实现下采样。且发现在分辨率改变的地方添加 normalization 层会提高训练稳定性。该操作提升效果到了82%,Swin-T 是 81.3%。
三、实验
作者也建立了不同大小的模型, ConvNeXt-T/S/B/L,对标 Swin-T/S/B/L。

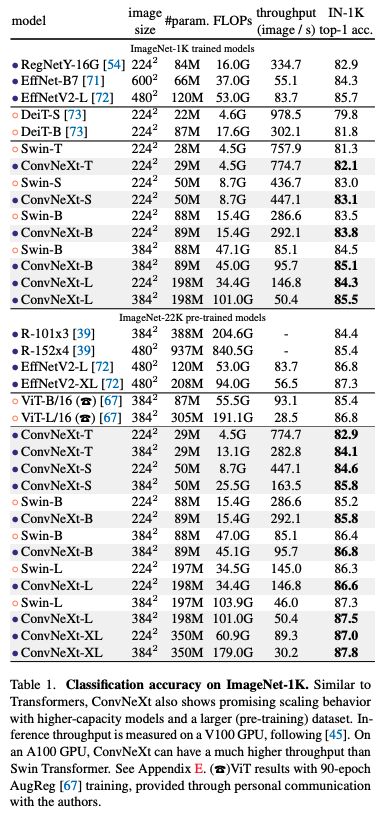





四、结论
本文提出的纯 CNN 的网络 ConvNeXt,在多种任务上取得了超越 Transformer 的效果,同时能够保留 ConvNet 的简洁高效性质。作者期望本文的结论能够推进对卷积及训练的重新思考。