人脸检测概述(不是人脸识别)
目录
1 引言... 3
2 人脸检测技术的发展与现状... 4
3 人脸检测算法相关工作... 4
3.1 评价指标... 5
3.2 人脸检测常用数据库... 6
3.2.1 FDDB数据库... 6
3.2.2 WIDER FACE数据库... 6
4 深度学习人脸检测算法... 7
4.1 卷积神经网络... 7
4.2 级联卷积神经网络(Cascde CNN). 8
4.2.1 级联思想... 8
4.2.2 网络结构及训练策略... 9
4.3 DenseBox——一种端到端的目标检测方法... 10
4.3.1 DenseBox流程及结构... 10
4.3.2 基于landmark定位... 11
4.4 Faceness-Net 12
4.5 多任务级联卷积神经网络(MTCNN)... 13
4.6 Face R-CNN.. 15
4.6.1 延续Faster R-CNN框架... 15
4.6.2 center loss和多任务loss. 16
4.6.3 在线硬样本挖掘(OHEM). 17
4.7 检测小面孔(Finding Tiny Faces). 17
5 总结... 19
参考文献... 20
深度学习人脸检测概述
1 引言
人脸检测(Face Detection),就是给一幅图像,找出图像中的所有人脸位置,通常用一个矩形框框起来,输入是一幅图像img,输出是若干个包含人脸的矩形框位置(x,y,w,h),图1-1是一个图像的人脸检测结果。
人脸检测对于我们人类非常容易,出于社会生活的需要,我们大脑中有专门的人脸检测模块,对人脸非常敏感,即使小孩子画的简笔画,大脑也能轻易检测出人脸和各自的表情。但是计算机对于人脸的检测却是一个相对较难的问题。虽然人脸的结构是确定的,由眉毛、眼睛、鼻子和嘴等部位组成,近似是一个刚体,但由于姿态和表情的变化,不同人的外观差异,光照,遮挡的影响,所以通过计算机准确的检测处于各种条件下的人脸是一件相对困难的事情。
人脸检测算法要解决以下几个核心问题:
(1)人脸可能出现在图像中的任何一个位置。
(2)人脸可能有不同的大小。
(3)人脸在图像中可能有不同的视角和姿态。
(4)人脸可能部分被遮挡

图1-1 人脸检测效果
2 人脸检测技术的发展与现状
自动人脸检测是围绕自动人脸图像分析的所有应用的基础,包括但不限于:人脸识别和验证,监控场合的人脸跟踪,面部表情分析,面部属性识别(性别/年龄识别,颜值评估),面部光照调整和变形,面部形状重建,图像视频检索,数字相册的组织和演示。
从问题的领域来看,人脸检测属于目标检测领域,更细化为特定类别目标检测领域。特定类别目标检测即仅检测图像中某一类特定目标,如人脸检测,行人检测,车辆检测等等,特定类别目标检测核心是1(目标)+1(背景)=2分类问题。这类检测通常模型比较小,速度要求非常高,这里问题的基本要求就是CPU real-time。
从人脸检测技术发展来看,深度学习技术在其中起了非常大的作用。在深度学习阶段,经典检测算法都是针对通用目标提出的,比如性能更好的Faster-RCNN, R-FCN系列,速度更快的YOLO, SSD系列,强大的深度学习只要一个CNN就可以搞定多类别检测任务。虽然这些都是多类别方法,但它们都可以用来解决单类别问题,目前人脸检测、行人检测等特定目标检测问题的State-of-the-art(SOTA)都是这类方法的针对性改进。
虽然基于深度学习的通用目标检测技术已经比较成熟,效果也比较好,但是在实际应用过程中还是存在诸多问题。比如,Faster-RCNN系列模型的优点是性能高,缺点是速度慢,在GPU上都无法实时,无法满足人脸检测对速度的极高要求,既然性能不是问题,这类方法的研究重点是提高效率。SSD系列方法的优势是速度快,在GPU上能实时,缺点是对密集小目标的检测比较差,而人脸刚好是密集小目标,这类方法的研究重点是提高密集小目标的检测性能,同时速度也需要尽可能快,GPU实时算法在应用中依然受限。
3 人脸检测算法相关工作
人脸检测算法的相关工作包括评价指标和人脸检测常用数据库
3.1 评价指标
评价一个人脸检测算法好坏的常用指标主要有以下三个指标:
(1)召回率(recall):人脸检测系统检测出来的矩形框越接近人工标注的矩形框,说明检测结果越好,通常交并比IoU大于0.5就认为是检测出来了,所以 召回率recall = 检测出来的人脸数量/图像中总人脸数量。
(2)误检数(false positives):人脸检测系统可能会把其他东西认为是人脸,这种情况越少越好,我们用检测错误的绝对数量来表示,这个指标就是误检数false positives。与recall相对,人络检测系统检测出来的矩形框与任何人工标注框的IoU都小于0.5,则认为这个检测结果是误检,误检越少越好,比如FDDB上,论文中一般比较1000个或2000个误检时的召回率情况,工业应用中通常比较100或200个误检的召回率情况。
(3)检测速度(speed):算法的运行速度也是人脸检测算法的重要指标尤其在实际应用场景中更加重要。检测一幅图像所用的时间越少越好,通常用帧率(frame-per-second,FPS)来表示。
一般情况下误检数越多召回率越高,同等误检数量下比较召回率,同等测试环境和图像比较速度,尽可能保持客观结果。下图是评价指标的简单示例,图3-1总共包含7个人脸(黄色椭圆),某detector给出了8个检测结果(绿色框),其中5个正确,3个错误,这时候误检数为3,召回率为5/7=71.43%。
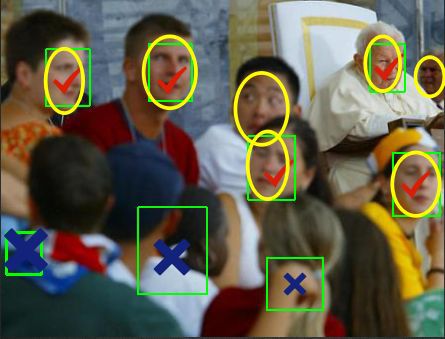
图3-1 人脸检测实例
3.2 人脸检测常用数据库
3.2.1 FDDB数据库
FDDB总共2845张图像,5171张,人脸非约束环境,人脸的难度较大,有面部表情,双下巴,光照变化,穿戴,夸张发型,遮挡等难点,是目标最常用的数据库。有以下特点:
(1)图像分辨率较小,所有图像的较长边缩放到450,也就是说所有图像都小于450*450,最小标注人脸20*20,包括彩色和灰度两类图像;
(2)每张图像的人脸数量偏少,平均1.8人脸/图,绝大多数图像都只有一人脸;
(3)数据集完全公开,published methods通常都有论文,大部分都开源代码且可以复现,可靠性高;unpublished methods没有论文没有代码,无法确认它们的训练集是否完全隔离,持怀疑态度最好,通常不做比较。(扔几张FDDB的图像到训练集,VJ也可以训练出很高的召回率。。需要考虑人品能不能抵挡住利益的诱惑)
(4)有其他隔离数据集无限制训练再FDDB测试,和FDDB十折交叉验证两种,鉴于FDDB图像数量较少,近几年论文提交结果也都是无限制训练再FDDB测试方式,所以,如果要和published methods提交结果比较,请照做。山世光老师也说十折交叉验证通常会高1~3%。
3.2.2 WIDER FACE数据库
来源于香港中文大学信息工程系。WIDER FACE数据集是面部检测基准数据集,其中图像从可公开获得的选定WIDER数据集。数据库选择了32,203张图像,并标记了393,703张在比例,姿势和遮挡方面具有高度可变性的面部。WIDER FACE数据集基于61个事件类别进行组织。对于每个事件类别,随机选择40%/ 10%/ 50%数据作为训练,验证和测试集。采用与PASCAL VOC数据集相同的评估指标。图像分辨率普遍偏高,所有图像的宽都缩放到1024,最小标注人脸10*10,都是彩色图像;
每张图像的人脸数据偏多,平均12.2人脸/图,密集小人脸非常多;
分训练集train/验证集val/测试集test,分别占40%/10%/50%,而且测试集的标注结果(ground truth)没有公开,需要提交结果给官方比较,更加公平公正,而且测试集非常大,结果可靠性极高;
根据EdgeBox的检测率情况划分为三个难度等级:Easy, Medium, Hard。
4 深度学习人脸检测算法
近年来,随着机器学习的不断发展,深度学习作为一个崭新的研究方向引起人工智能领域的广泛关注。2012年12月29日《纽约时报》的头版报道称“深度学习让机器执行人类的活动,如看、听和思考,为模式识别提供了可能性,促进了人工智能技术 的进步”。2013年,《麻省理工科技评论》(MIT Technology Review)将深度学习列为世界十大技术突破之首。深度学习的输入数据分布式表示,并具有强大的集中学习数据集本质特征的能力,从而可以提高学习效率。
4.1 卷积神经网络
卷积神经网络(convolutional neural networks,CNN)[[[1]]]是第一个真正成功 训练多层网络结构的学习算法,利用BP算法设计并训练[[[2]]]。CNN是一种适应二维人脸图像识别场景的有效学习方式,被大量文献用于解决人脸识别问题,主要用来识别位移、缩放及其他形式扭曲不变性的二维图像。由于CNN的特征检测层通过训练数据进行学习,避免了显式的特征提取,隐式地从训练数据中进行学习;而且由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是 CNN相对于神经元彼此相连网络的优势.其布局更接近实际的生物神经网络,权值共享降低了网络的复杂性,尤其是多维输入向量的图像可以直接输入网络,避免了特征提取和分类过程中数据重建的复杂度.图4-1是图像分类的两层卷积神经网络。

图4-1 图像分类的两层卷积神经网络示例
在深度学习框架下,学习算法直接从原始图像学 习判别性的人脸特征。在海量人脸数据支撑下,基于 深度学习的人脸识别在速度和精度方面已经远远超 过人类.深度学习借助于图形处理器(GPU)组成的运算系统作大数据分析,人脸识别是图像处理及人工智能的一个重要指标,证明深度学习模型有助于推动人工智能发展,将来甚至可能超越人类的智能水平。
4.2 级联卷积神经网络(Cascde CNN)
该算法来源于2015CVPR《A Convolutional Neural Network Cascade for Face Detection》[[3]]。本篇文章的方法可以说是对经典的Viola jones方法的深度卷积网络实现,并没有让人眼前一亮的地方,但依然有以下几点可以学习。
4.2.1 级联思想
该神经网络大致思路:首先使用一个小型网络 12-net 对图像进行全局搜索人脸候选区域,检测区域是 12×12图像块,搜索步长是4个像素,可以快速排除90%的非人脸区域,使用非极大值抑制排除一些重叠区域,再对剩下的候选区域使用一个小网络 12-calibration-net 进行人脸矩形框微调,包括位置和尺度。微调后再使用一个中型网络 24-net 对微调后的人脸候选区进行二分类,检测区域是 24×24 图像块,再排除90%的非人脸区域,再对剩下的候选区域使用一个中型网络 24-calibration-net 进行人脸矩形框微调,包括位置和尺度,使用非极大值抑制排除一些重叠区域,微调后再使用一个大型网络 48-net 对微调后的人脸候选区进行二分类,检测区域是 48×48 图像块,非极大值抑制,最后用48-calibration-net 进行人脸矩形框微调输出结果。

图4-2 三级级联示意图
级联的工作原理和好处:
1、最初阶段的网络可以比较简单,判别阈值可以设得宽松一点,这样就可以在保持较高召回率的同时排除掉大量的非人脸窗口;
2、最后阶段网络为了保证足够的性能,因此一般设计的比较复杂,但由于只需要处理前面剩下的窗口,因此可以保证足够的效率;
3、 级联的思想可以帮助我们去组合利用性能较差的分类器,同时又可以获得一定的效率保证。
4.2.2 网络结构及训练策略

图4-2 三阶网络结构
由上图可以看出,前2阶的网络都非常简单,只有第3阶才比较复杂。这不是重点,重点是我们要从上图中学习多尺度特征组合。以第2阶段的24-net为例,首先把上一阶段剩下的窗口resize为24*24大小,然后送入网络,得到全连接层的特征。同时,将之前12-net的全连接层特征取出与之拼接在一起。最后对组合后的特征进行softmax分类。
另外,该网络针对级联问题,采用了特殊的训练策略。训练过程如图4-3.

图4-3 级联训练策略
1、按照一般的方法组织正负样本训练第一阶段的12-net和12-calibration-net网络;
2、 利用上述的1层网络在AFLW数据集上作人脸检测,在保证99%的召回率的基础上确定判别阈值T1。
3、将在AFLW上判为人脸的非人脸窗口作为负样本,将所有真实人脸作为正样本,训练第二阶段的24-net和24-calibration-net网络;
4、重复2和3,完成最后阶段的训练
4.3 DenseBox——一种端到端的目标检测方法
本方法的目标是将单个全卷积神经网络(FCN)应用到目标检测中。DenseBox[[4]]不需要生成proposal,在训练过程中也可以达到最优。与现存的基于滑动窗的FCN的检测框架相类似,DenseBox更偏重于小目标及较为模糊目标的检测。本文通过对DenseBox训练,使用hard negative mining技术来提升检测性能为了进一步提高,后面多任务联合学习结合了landmark定位来进一步提升性能。
4.3.1 DenseBox流程及结构
DenseBox的整体流程如下图4-4所示,单一的卷积网路同时输出不同的预测框及类别分数。DenseBox中的所有目标检测模块都为全卷积网络结构,除了NMS处理部分,因此,proposal的生成是没有必要的。测试时,输入图片大小为(mxnx3),输出为(m/4 x n/4 *5),第i个位置的像素的输出feature map用一个5维向量描述。最后对带有边框及类别分数的框进行NMS处理。

图4-4 DenseBox算法流程
网络结构如下图4-5所示,基于VGG19进行的改进,整个网络包含16层卷积,前12层由VGG19初始化,输出conv4_4后接4个1x1的卷积,前两个卷积产生1-channel map用于类别分数,后两个产生4-channel map用于预测相对位置。最后一个1x1的卷积担当这全连接层的作用。

图4-5 DenseBox网络结构
4.3.2 基于landmark定位
在DenseBox中由于是全卷积网络,因此,基于landmark定位可以通过简单添加一些层来进行实现。通过融合landmark heatmaps及目标score maps来对检测结果进行增强。如下图4-6所示,增加了一个分支用于landmark定位,假设存在N个landmarks,landmark 定位分支将会输出N个响应maps,其中,每个像素值代表该位置为landmark的置信分数。该任务的ground truth maps与检测的十分相似,对于一个landmark 实例,landmark k的第i个实例,其对应的ground truth 是位于输出坐标空间中第k个响应 map上的positive 标记的区域。半径rl应当较小从而避免准确率的损失。与分类任务相似,landmark 定位损失也是定义为预测值与真实值的L2损失。同样使用negative mining及ignore region。
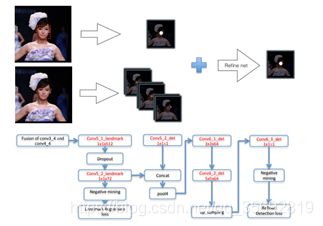
图4-6 基于landmark定位流程
将分类score map及landmark localization maps作为输入的增强分支的最终输出用于增强检测结果。通过一些高层次空间模型来了解landmark confidence及边界框分数的方法来进一步提高检测性能。
4.4 Faceness-Net
这是一种新颖的卷积神经网络,最重要的思想是考虑通过根据面部部位的空间结构和排列来对面部部位的反应进行评分,从而从新的角度寻找面部。考虑到仅部分可见面部的挑战性情况,精心制定了评分机制。根据这一点,网络可以检测到严重遮挡和不受约束的姿势变化下的人脸,这是大多数现有人脸检测方法的主要困难和瓶颈。
Faceness-Net[[5]]是一个典型的由粗到精的工作流,借助了多个基于DCNN网络的facial parts分类器对人脸进行打分,然后根据每个部件的得分进行规则分析得到Proposal的人脸区域,最后通过一个Refine的网络得到最终的人脸检测结果。

图4-7 整体流程图
系统主要包含了2个阶段:
第1阶段:生成partness map,由局部推理出人脸候选区域。
根据attribute-aware深度网络生成人脸部件map图(partness map),如上图Faceness(a)中的颜色图,文章共使用了5个部件:hair,eye,nose,mouth,beard. 通过part的结合计算人脸的score.部件与部件之间是有相对位置关系的,比如头发在眼睛上方,嘴巴在鼻子下方,因此利用部件的spatial arrangement可以计算face likeliness. 通过这个打分对原始的人脸proposal进行重排序. 如图Faceness(b)。
第2阶段:Refining the face hypotheses。
上一阶段proposal生成的候选框已经有较高的召回率,通过训练一个人脸分类和边界回归的CNN可以进一步提升其效果。
Faceness的整体性能在当时看来非常令人兴奋。此前学术界在FDDB上取得的最好检测精度是在100个误检时达到84%的检测率,Faceness在100个误检时,检测率接近88%,提升了几乎4个百分点;除了算法本身的精度有很大提升,作者还做了很多工程上的优化比如:通过多个网络共享参数,降低网络参数量 83%;采用多任务的训练方式同一网络实现不同任务等。
4.5 多任务级联卷积神经网络(MTCNN)
MTCNN[[6]],Multi-task convolutional neural network(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,它的主题框架类似于cascade。总体可分为P-Net、R-Net、和O-Net三层网络结构。它是2016年中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,该模型主要采用了三个级联的网络,采用候选框加分类器的思想,进行快速高效的人脸检测。这三个级联的网络分别是快速生成候选窗口的P-Net、进行高精度候选窗口过滤选择的R-Net和生成最终边界框与人脸关键点的O-Net。和很多处理图像问题的卷积神经网络模型,该模型也用到了图像金字塔、边框回归、非最大值抑制等技术。

图4-8 MTCNN的三个阶段
MTCNN总体流程如图4-8所示。给定一个图像,我们最初将其调整到不同的比例以构建图像金字塔,这是以下三阶段级联框架的输入:
阶段1:利用完全卷积网络,称为Proposal Network(P-Net) ),以与类似的方式获得候选窗口及其边界框回归向量。然后我们使用估计的边界框回归向量来校准候选者。之后,我们采用非最大抑制(NMS)来合并高度重叠的候选者。阶段2:所有候选人都被馈送到另一个CNN,称为Refine Network(R-Net),它进一步拒绝大量错误候选者,使用边界框回归执行校准,以及NMS候选者合并。
虽然人脸检测的CNN已经很多了,但是它的性能可能受到以下事实的限制:(1)一些过滤器缺乏权重的多样性,这可能限制它们产生有区别的描述。(2)与其他多类异象检测和分类任务相比,人脸检测是一项挑战性的二元分类任务,因此可能需要较少数量的过滤器,但需要对它们进行更多的区分。为此减少滤波器的数量并将5×5滤波器更改为3×3滤波器以减少计算,同时增加深度以获得更好的性能。通过这些改进,与先前架构相比,我们可以以更少的运行时间获得更好的性能。CNN的三个阶段具体架构如图4-9所示。

图4-9 P-NET,R-NET,O-NET架构
4.6 Face R-CNN
Face R-CNN[[7]]是基于目标检测的Faster R-CNN网络进行针对人脸检测改进的模型。对于人脸检测任务,Faster R-CNN还有一些不足的之处。对于Faster使用的softmax loss函数,该函数倾向于区分特征之间的类间可分性,不能获取类内的紧凑性。而前人的工作已经证明了对于CNN特征,不管是类间可分性,还是类内紧凑性都十分重要。为了减少类内变化并且拉大类间距离,作者在Faster R-CNN框架的原有loss函数上增加了一个新的loss函数叫做center loss。通过增加center loss,类内变化可以有效的减小,相对的让学到的特征辨别力增强。
另外,为了进一步提升检测的准确度,这里采用了在线硬样本挖掘(online hard example mining,OHEM)和多尺度训练策略。
4.6.1 延续Faster R-CNN框架
Face R-CNN还是延续了Faser的基本网络框架,在该架构上增加了一个新的多任务loss函数去扶助训练有无人脸的二值分类器;用在线硬样本挖掘算法生成硬样本以供后续处理;使用多尺度训练策略去帮助提升检测性能。
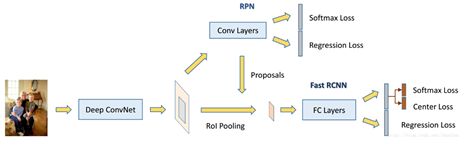
图4-10 Face R-CNN框架
如图4-10所示该网络结构包含一个ConvNet,一个RPN,和一个Fast RCNN模块。ConvNet:是一个卷积层和最大池化层的堆叠,用来生成卷积feature map;RPN:该模块生成一系列的矩形区域候选框,这些候选框大概率都包含了人脸。是一个全卷积网络,构建在卷积feature map上。该RPN的loss层包含一个二值分类层和一个边界框回归层;Fast R-CNN:生成的区域候选框会被送入Fast RCNN模块,并作为ROI区域。ROI层处理这些ROIs去提取固定长度的特征向量。最终输出到两个分开的全连接层用于分类和回归。
4.6.2 center loss和多任务loss
center loss函数被证明在人脸识别任务中有很好的效果,center loss的基本思想是鼓励网络学习辨识性特征,以此来最小化类内变化,同时扩大类间变化。center loss的公式:
Lx=12i=1mxi-cyi22
这里x表示输入的特征向量,cyi表示第yi个类中心。这些类中心是在每次的mini-batch迭代时更新的,所以它可以很容易的通过SGD训练。对于人脸检测任务,只有2个中心:有人脸和没有人脸。我们的目的是最小化类内变化。center loss支持与softmax loss联合最优化。而且center loss可以很大程度上减少类内变化,同时softmax loss在最大化类间变化上有些优势。所以就很自然的将center loss和softmax结合起来去共同推进特征的辨识性。
对于RPN阶段,采用的是多任务loss,该loss是基于结合box-分类loss和box-回归loss。分类loss采用关于是前景还是背景的二分类的softmax loss。回归loss采用的是平滑L1范式。对于fast r-cnn阶段,基于之前提到的center loss设计了一个多任务loss。使用center loss和softmax loss结合来作为分类任务的loss。然后用平滑L1 loss作为边界框回归的任务。整个loss函数形式如下:
Lp,t,x=Lclsp,p*+λLregt,t*+μLc(x)
这里p是预测当前候选框是人脸的概率。p∗是ground-truth,如果为1则表示是正样本,为0则表示负样本。t是一个向量,对应着预测边界框的4个参数化坐标,t∗是对应的ground-truth。这里平滑L1 用于回归。超参数λ,μ用来可能告知三个loss之间的平衡。
4.6.3 在线硬样本挖掘(OHEM)
在线硬样本挖掘(online hard example mining, OHEM)是一个简单但是十分有效的引导技术。关键的想法是收集硬样本,即那些预测不正确的,将这些样本输送给网络以增强分辨性。因为loss可以表示当前网络拟合的程度,所以可以通过他们的loss将生成的候选框进行排序,然后只提取前N个最差的样本作为硬样本。
标准的OHEM会遇到数据不平衡的问题,因为选择的硬样本可能其中负样本的量很可能压倒性的超过正样本的量(或者反过来)。并且注意到,当使用center loss的时候,保持正和负的训练样本的平衡对于训练阶段来说十分重要。最后,我们在正样本和负样本上分别独立使用OHEM,并在每个mini-batch中将正负样本的比例保持1:1。
在训练的时候,OHEM与SGD交替的执行。对于一次SGD迭代,OHEM是通过前向一次当前的网络实现的。然后将选择的硬样本在下一次迭代中使用。
4.7 检测小面孔(Finding Tiny Faces)
虽然目前在目标检测有了较好的进步,可是检测小物体[[8]]仍然是一个极具挑战的事情。对于几乎所有当前的识别和目标检测系统而言,尺度不变性是一个必须的特性。但是从实际角度来说,尺度不变性也只是一定程度的不变性,因为对于一个3像素的和300像素的缩放来说,的确相差太大了。
而现在大多数的目标检测任务使用的无外乎2种形式来解决尺度不变性问题:(1)基于一个图像金字塔进行窗口滑动的方式,如MTCNN;(2)基于ROI-pooling方式进行区域分类,如fast-rcnn。
如何从预训练的深度网络中最佳地提取尺度不变的特征。虽然许多应用于“多分辨率”的识别系统都是处理一个图像金字塔,但我们发现在插值金字塔的最底层对于检测小目标尤为重要。最终方法是:通过尺度不变方式,来处理图像金字塔以捕获大规模变化,并采用特定尺度混合检测器,如图4-11

图4-11 各种方法捕捉尺度不变性
图像金字塔方法:如(a),传统的方法是建立一个单尺度模板,将其用在图像金字塔上面;
不同尺度采用不同检测器:如(b),而如果想要利用到不同分辨率上的信息,那么需要基于不同的对象尺度构建不同的检测器(如在一张图片上,检测小脸的一个检测器,检测大脸的一个检测器),而这样的方法在极端对象尺度上还是会失败,因为可能这个尺度的根本没出现过在训练集中;
本模型方法:如(c)先用粗略的图像金字塔去抓取极端的尺度变化。然后为了提升关于小脸的检测,增加了额外的上下文信息,即通过一个固定大小的感受野在所有特定尺度上进行抓取,如(d)。然后如(e),基于同一个深度模型,在网络不同层上提取的特征来定义模板。
另外模型怎样才能最好的编码上下文信息?模型作者证明从多个层中提取的卷积深度特征(也称为 “hypercolumn” features)是有效的“ foveal”描述符,其能捕获大感受野上的高分辨率细节和粗略的低分辨率线索。如图4-12从输入图像开始,首先创建一个图像金字塔(2x插值)。然后我们将缩放的输入图像输入到CNN中,获得不同分辨率下人脸预测响应图(后续用于检测和回归)。最后将在不同尺度上得到的候选区域映射回原始分辨率图像上,应用非极大值抑制(NMS)来获得最终检测结果。

图4-12 模型架构
5 总结
本篇概述第一章给出了人脸检测问题的基本概念和面对的难题。第二章总结了当前人脸检测领域的发展历史和基本现状,以及深度学习技术对人脸检测的影响。第三章介绍了人脸检测问题的评价指标和人脸检测常用数据库。第四章主要通过近几年发表在计算机视觉领域顶级期刊的一些论文,归纳总结了基于深度学习的人脸检测方法。
参考文献
[[1]]Lecun Y,Boser L,Denker J S,et al. Backpropagation applied to handwritten zip code Recognition[J]. Neural Computation,1989, 1(4):541–551.
[[2]] Lecun Y,Botou L,Bengio Y,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86(11):2278–2324.
[[3]] Li H , Lin Z , Shen X , et al. A convolutional neural network cascade for face detection[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015.
[[4]] Huang L , Yang Y , Deng Y , et al. DenseBox: Unifying Landmark Localization with End to End Object Detection[J]. Computer Science, 2015.
[[5]] Yang S , Luo P , Loy C C , et al. From Facial Parts Responses to Face Detection: A Deep Learning Approach[J]. 2015.
[[6]] Zhang K , Zhang Z , Li Z , et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10):1499-1503.
[[7]] Wang H , Li Z , Ji X , et al. Face R-CNN[J]. 2017.
[[8]] Hu P , Ramanan D . Finding Tiny Faces[J]. 2016.