深度学习与自然语言处理教程(3) - 神经网络与反向传播(NLP通关指南·完结)

- 作者:韩信子@ShowMeAI
- 教程地址:http://www.showmeai.tech/tutorials/36
- 本文地址:http://www.showmeai.tech/article-detail/234
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

本系列为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》的全套学习笔记,对应的课程视频可以在 这里 查看。


ShowMeAI为CS224n课程的全部课件,做了中文翻译和注释,并制作成了 GIF动图!点击 第3讲-词向量进阶 和 第4讲-神经网络反向传播与计算图 查看的课件注释与带学解读。更多资料获取方式见文末。
引言
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程,核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
这组笔记介绍了单层和多层神经网络,以及如何将它们用于分类目的。然后我们讨论如何使用一种称为反向传播的分布式梯度下降技术来训练它们。我们将看到如何使用链式法则按顺序进行参数更新。在对神经网络进行严格的数学讨论之后,我们将讨论一些训练神经网络的实用技巧和技巧,包括:神经元单元(非线性)、梯度检查、Xavier参数初始化、学习率、Adagrad等。最后,我们将鼓励使用递归神经网络作为语言模型。
内容要点
- 神经网络
- 反向传播
- 梯度计算
- 神经元
- 合页损失
- 梯度检查
- Xavier参数初始化
- 学习率
- Adagrad优化算法
1.神经网络基础
(本部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 神经网络基础,深度学习教程 | 浅层神经网络和深度学习教程 | 深层神经网络)
在前面的讨论中认为,因为大部分数据是线性不可分的所以需要非线性分类器,不然的话线性分类器在这些数据上的表现是有限的。神经网络就是如下图所示的一类具有非线性决策分界的分类器。我们可以在图上清晰地看到其非线性决策边界,下面我们来看看模型是如何学习得到它的。
神经网络是受生物学启发的分类器,这就是为什么它们经常被称为“人工神经网络”,以区别于有机类。然而,在现实中,人类神经网络比人工神经网络更有能力、更复杂,因此通常最好不要在两者之间画太多的相似点。

1.1 单个神经元
神经元是一个通用的计算单元,它接受 n n n 个输入并产生一个输出。不同的神经元根据它们不同的参数(一般认为是神经元的权值)会有不同的输出。
对神经元来说一个常见的选择是 s i g m o i d sigmoid sigmoid ,或者称为“二元逻辑回归”单元。这种神经元以 n n n 维的向量作为输入,然后计算出一个激活标量(输出) a a a 。该神经元还与一个 n n n 维的权重向量 w w w 和一个偏置标量 b b b 相关联。
这个神经元的输出是:
a = 1 1 + e x p ( − ( w T x + b ) ) a=\frac{1}{1+exp(-(w^{T}x+b))} a=1+exp(−(wTx+b))1
我们也可以把上面公式中的权值和偏置项结合在一起:
a = 1 1 + e x p ( − [ w T x ] ⋅ [ x 1 ] ) a=\frac{1}{1+exp(-[w^{T}\;\;x]\cdot [x\;\;1])} a=1+exp(−[wTx]⋅[x1])1
上述公式可视化如下图所示:
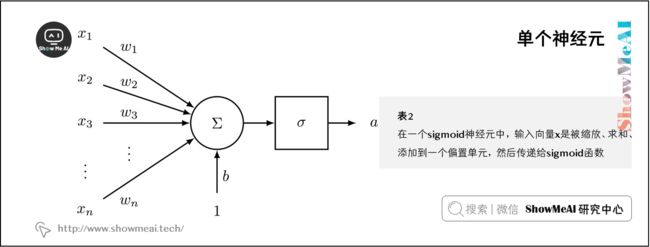
❐ 神经元是神经网络的基本组成部分。我们将看到神经元可以是许多允许非线性在网络中积累的函数之一。
1.2 单层神经网络
我们将上述思想扩展到多个神经元,考虑输入 x x x 作为多个这样的神经元的输入,如下图所示。

如果我们定义不同的神经元的权值为 { w ( 1 ) , ⋯ , w ( m ) } \{w^{(1)}, \cdots ,w^{(m)}\} {w(1),⋯,w(m)} 、偏置为 { b 1 , ⋯ , b m } \{b_1, \cdots ,b_m\} {b1,⋯,bm} 和相对应的激活输出为 { a 1 , ⋯ , a m } \{a_1, \cdots ,a_m\} {a1,⋯,am} :
a 1 = 1 1 + e x p ( − ( w ( 1 ) T x + b 1 ) ) a_{1} =\frac{1}{1+exp(-(w^{(1)T}x+b_1))} a1=1+exp(−(w(1)Tx+b1))1
⋮ \vdots ⋮
a m = 1 1 + e x p ( − ( w ( m ) T x + b m ) ) a_{m} =\frac{1}{1+exp(-(w^{(m)T}x+b_m))} am=1+exp(−(w(m)Tx+bm))1
让我们定义简化公式以便于更好地表达复杂的网络:
σ ( z ) = [ 1 1 + e x p ( z 1 ) ⋮ 1 1 + e x p ( z m ) ] \sigma(z) = \begin{bmatrix} \frac{1}{1+exp(z_1)} \\ \vdots \\ \frac{1}{1+exp(z_m)} \end{bmatrix} σ(z)=⎣⎢⎡1+exp(z1)1⋮1+exp(zm)1⎦⎥⎤
b = [ b 1 ⋮ b m ] ∈ R m b = \begin{bmatrix} b_{1} \\ \vdots \\ b_{m} \end{bmatrix} \in \mathbb{R}^{m} b=⎣⎢⎡b1⋮bm⎦⎥⎤∈Rm
W = [ − w ( 1 ) T − ⋯ − w ( m ) T − ] ∈ R m × n W = \begin{bmatrix} -\;\;w^{(1)T}\;\;- \\ \cdots \\ -\;\;w^{(m)T}\;\;- \end{bmatrix} \in \mathbb{R}^{m\times n} W=⎣⎡−w(1)T−⋯−w(m)T−⎦⎤∈Rm×n
我们现在可以将缩放和偏差的输出写成:
z = W x + b z=Wx+b z=Wx+b
激活函数sigmoid可以变为如下形式:
[ a 1 ⋮ a m ] = σ ( z ) = σ ( W x + b ) \begin{bmatrix} a_{1} \\ \vdots \\ a_{m} \end{bmatrix} = \sigma(z) = \sigma(Wx+b) ⎣⎢⎡a1⋮am⎦⎥⎤=σ(z)=σ(Wx+b)
那么这些激活的作用是什么呢?我们可以把这些激活看作是一些加权特征组合存在的指标。然后,我们可以使用这些激活的组合来执行分类任务。
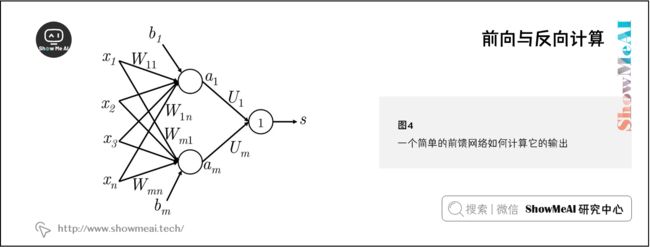
1.3 前向与反向计算
到目前为止我们知道一个输入向量 x ∈ R n x\in \mathbb{R}^{n} x∈Rn 可以经过一层 s i g m o i d sigmoid sigmoid 单元的变换得到激活输出 a ∈ R m a\in \mathbb{R}^{m} a∈Rm 。但是这么做的直觉是什么呢?让我们考虑一个NLP中的命名实体识别问题作为例子:
Museums in Paris are amazing
这里我们想判断中心词 Paris是不是以命名实体。在这种情况下,我们很可能不仅想要捕捉窗口中单词的单词向量,还想要捕捉单词之间的一些其他交互,以便进行分类。例如,可能只有 Museums 是第一个单词和 in 是第二个单词的时候, Paris 才是命名实体。这样的非线性决策通常不能被直接提供给Softmax函数的输入捕获,而是需要添加神经网络中间层再进行评分。因此,我们可以使用另一个矩阵 U ∈ R m × 1 \mathbf{U} \in \mathbb{R}^{m \times 1} U∈Rm×1 与激活输出计算得到未归一化的得分用于分类任务:
s = U T a = U T f ( W x + b ) s=\mathbf{U}^{T}a=\mathbf{U}^{T}f(Wx+b) s=UTa=UTf(Wx+b)
其中, f f f 是激活函数(例如sigmoid函数)。
维度分析:如果我们使用 4 4 4 维的词向量来表示每个单词,并使用 5 5 5 个词的窗口,则输入是 x ∈ R 20 x\in \mathbb{R}^{20} x∈R20 。如果我们在隐藏层使用 8 8 8 个sigmoid单元和从激活函数中生成一个分数输出,其中 W ∈ R 8 × 20 W\in \mathbb{R}^{8\times 20} W∈R8×20 , b ∈ R 8 b\in \mathbb{R}^{8} b∈R8 , U ∈ R 8 × 1 U\in \mathbb{R}^{8\times 1} U∈R8×1 , s ∈ R s\in \mathbb{R} s∈R 。
1.4 合页损失
类似很多的机器学习模型,神经网络需要一个优化目标函数,一个我们想要最小化或最大化的误差。这里我们讨论一个常用的误差度量方法:maximum margin objective 最大间隔目标函数。使用这个目标函数的背后的思想是保证对“真”标签数据的计算得分要比“假”标签数据的计算得分要高。
回到前面的例子,如果我们令“真”标签窗口 Museums in Paris are amazing 的计算得分为 s s s ,令“假”标签窗口 Not all museums in Paris 的计算得分为 s c s_c sc (下标 c c c 表示这个这个窗口corrupt)
然后,我们对目标函数最大化 ( s − s c ) (s-s_c) (s−sc) 或者最小化 ( s c − s ) (s_c-s) (sc−s) 。然而,我们修改目标函数来保证误差仅在 s c > s ⇒ ( s c − s ) > 0 s_c > s \Rightarrow (s_c-s) > 0 sc>s⇒(sc−s)>0 才进行计算。这样做的直觉是,我们只关心“正确”数据点的得分高于“错误”数据点,其余的都不重要。因此,当 s c > s s_c > s sc>s 则误差为 ( s c − s ) (s_c-s) (sc−s) ,否则为0。因此,我们的优化的目标函数现在为:
m i n i m i z e J = m a x ( s c − s , 0 ) minimize\;J=max\,(s_c-s,0) minimizeJ=max(sc−s,0)
然而,上面的优化目标函数是有风险的,因为它不能创造一个安全的间隔。我们希望“真”数据要比“假”数据的得分大于某个正的间隔 Δ \Delta Δ 。换而言之,我们想要误差在 ( s − s c < Δ ) (s-s_c < \Delta) (s−sc<Δ) 就开始计算,而不是当 ( s − s c < 0 ) (s-s_c < 0) (s−sc<0) 时就计算。因此,我们修改优化目标函数为:
m i n i m i z e J = m a x ( Δ + s c − s , 0 ) minimize\;J=max\,(\Delta+s_c-s,0) minimizeJ=max(Δ+sc−s,0)
我们可以把这个间隔缩放使得 Δ = 1 \Delta=1 Δ=1 ,让其他参数在优化过程中自动进行调整,并且不会影响模型的表现。(合页损失与最小间隔问题,大家可以阅读ShowMeAI的机器学习算法教程中对SVM算法的讲解)。最后,我们定义在所有训练窗口上的优化目标函数为:
m i n i m i z e J = m a x ( 1 + s c − s , 0 ) minimize\;J=max\,(1+s_c-s,0) minimizeJ=max(1+sc−s,0)
按照上面的公式有:
s c = U T f ( W x c + b ) s_c=\mathbf{U}^{T}f(Wx_c+b) sc=UTf(Wxc+b)
s = U T f ( W x + b ) s=\mathbf{U}^{T}f(Wx+b) s=UTf(Wx+b)
❐ 最大边际目标函数通常与支持向量机一起使用
1.5 反向传播(单样本形态)
上一节我们提到了合页损失,下面我们讲解一下当损失函数 J J J 为正时,模型中不同参数时是如何训练的。如果损失为 0 0 0 时,那么不需要再更新参数。我们一般使用梯度下降(或者像SGD这样的变体)来更新参数,所以要知道在更新公式中需要的任意参数的梯度信息:
θ ( t + 1 ) = θ ( t ) − α ∇ θ ( t ) J \theta^{(t+1)}=\theta^{(t)}-\alpha\nabla_{\theta^{(t)}}J θ(t+1)=θ(t)−α∇θ(t)J
反向传播是一种利用微分链式法则来计算模型上任意参数的损失梯度的方法。为了更进一步理解反向传播,我们先看下图中的一个简单的网络:

这里我们使用只有单个隐藏层和单个输出单元的神经网络。现在让我们先建立一些符号定义:
- x i x_i xi 是神经网络的输入
- s s s 是神经网络的输出
- 每层(包括输入和输出层)的神经元都接收一个输入和生成一个输出。第 k k k 层的第 j j j 个神经元接收标量输入 z j ( k ) z_j^{(k)} zj(k) 和生成一个标量激活输出 a j ( k ) a_j^{(k)} aj(k)
- 我们把 z j ( k ) z_j^{(k)} zj(k) 计算出的反向传播误差定义为 δ j ( k ) \delta_j^{(k)} δj(k)
- 第 1 1 1 层是输入层,而不是第 1 1 1 个隐藏层。对输入层而言, x j = z j ( 1 ) = a j ( 1 ) x_j=z_j^{(1)}=a_j^{(1)} xj=zj(1)=aj(1)
- W ( k ) W^{(k)} W(k) 是将第 k k k 层的输出映射到第 k + 1 k+1 k+1 层的输入的转移矩阵,因此将这个新的符号用在上面1.3节中的例子 W ( 1 ) = W W^{(1)}=W W(1)=W 和 W ( 2 ) = U W^{(2)}=U W(2)=U
现在开始反向传播:
假设损失函数 J = ( 1 + s c − s ) J=(1+s_c-s) J=(1+sc−s) 为正值,我们想更新参数 W 14 ( 1 ) W_{14}^{(1)} W14(1) ,我们看到 W 14 ( 1 ) W_{14}^{(1)} W14(1) 只参与了 z 1 ( 2 ) z_1^{(2)} z1(2) 和 a 1 ( 2 ) a_1^{(2)} a1(2) 的计算。这点对于理解反向传播是非常重要的——反向传播的梯度只受它们所贡献的值的影响。 a 1 ( 2 ) a_1^{(2)} a1(2) 在随后的前向计算中和 W 1 ( 2 ) W_1^{(2)} W1(2) 相乘计算得分。我们可以从最大间隔损失看到:
∂ J ∂ s = − ∂ J ∂ s c = − 1 \frac{\partial J}{\partial s}=-\frac{\partial J}{\partial s_c}=-1 ∂s∂J=−∂sc∂J=−1
为了简化我们只分析 ∂ s ∂ W i j ( 1 ) \frac{\partial s}{\partial W_{ij}^{(1)}} ∂Wij(1)∂s 。所以,
∂ s ∂ W i j ( 1 ) = ∂ W ( 2 ) a ( 2 ) ∂ W i j ( 1 ) = ∂ W i ( 2 ) a i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) ∂ a i ( 2 ) ∂ W i j ( 1 ) ⇒ W i ( 2 ) ∂ a i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) ∂ a i ( 2 ) ∂ z i ( 2 ) ∂ z i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) f ( z i ( 2 ) ) ∂ z i ( 2 ) ∂ z i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) f ′ ( z i ( 2 ) ) ∂ z i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) f ′ ( z i ( 2 ) ) ∂ ∂ W i j ( 1 ) ( b i ( 1 ) + a 1 ( 1 ) W i 1 ( 1 ) + a 2 ( 1 ) W i 2 ( 1 ) + a 3 ( 1 ) W i 3 ( 1 ) + a 4 ( 1 ) W i 4 ( 1 ) ) = W i ( 2 ) f ′ ( z i ( 2 ) ) ∂ ∂ W i j ( 1 ) ( b i ( 1 ) + ∑ k a k ( 1 ) W i k ( 1 ) ) = W i ( 2 ) f ′ ( z i ( 2 ) ) a j ( 1 ) = δ i ( 2 ) ⋅ a j ( 1 ) \begin{aligned} \frac{\partial s}{\partial W_{ij}^{(1)}} &= \frac{\partial W^{(2)}a^{(2)}}{\partial W_{ij}^{(1)}}=\frac{\partial W_i^{(2)}a_i^{(2)}}{\partial W_{ij}^{(1)}}=W_i^{(2)}\frac{\partial a_i^{(2)}}{\partial W_{ij}^{(1)}} \\ \Rightarrow W_i^{(2)}\frac{\partial a_i^{(2)}}{\partial W_{ij}^{(1)}} &= W_i^{(2)}\frac{\partial a_i^{(2)}}{\partial z_i^{(2)}}\frac{\partial z_i^{(2)}}{\partial W_{ij}^{(1)}} \\ &= W_i^{(2)}\frac{f(z_i^{(2)})}{\partial z_i^{(2)}}\frac{\partial z_i^{(2)}}{\partial W_{ij}^{(1)}} \\ &= W_i^{(2)}f^{\prime}(z_i^{(2)})\frac{\partial z_i^{(2)}}{\partial W_{ij}^{(1)}} \\ &= W_i^{(2)}f^{\prime}(z_i^{(2)})\frac{\partial}{\partial W_{ij}^{(1)}}(b_i^{(1)}+a_1^{(1)}W_{i1}^{(1)}+a_2^{(1)}W_{i2}^{(1)}+a_3^{(1)}W_{i3}^{(1)}+a_4^{(1)}W_{i4}^{(1)}) \\ &= W_i^{(2)}f^{\prime}(z_i^{(2)})\frac{\partial}{\partial W_{ij}^{(1)}}(b_i^{(1)}+\sum_{k}a_{k}^{(1)}W_{ik}^{(1)}) \\ &= W_i^{(2)}f^{\prime}(z_i^{(2)})a_j^{(1)} \\ &= \delta_i^{(2)}\cdot a_j^{(1)} \end{aligned} ∂Wij(1)∂s⇒Wi(2)∂Wij(1)∂ai(2)=∂Wij(1)∂W(2)a(2)=∂Wij(1)∂Wi(2)ai(2)=Wi(2)∂Wij(1)∂ai(2)=Wi(2)∂zi(2)∂ai(2)∂Wij(1)∂zi(2)=Wi(2)∂zi(2)f(zi(2))∂Wij(1)∂zi(2)=Wi(2)f′(zi(2))∂Wij(1)∂zi(2)=Wi(2)f′(zi(2))∂Wij(1)∂(bi(1)+a1(1)Wi1(1)+a2(1)Wi2(1)+a3(1)Wi3(1)+a4(1)Wi4(1))=Wi(2)f′(zi(2))∂Wij(1)∂(bi(1)+k∑ak(1)Wik(1))=Wi(2)f′(zi(2))aj(1)=δi(2)⋅aj(1)
其中, a ( 1 ) a^{(1)} a(1) 指输入层的输入。我们可以看到梯度计算最后可以简化为 δ i ( 2 ) ⋅ a j ( 1 ) \delta_i^{(2)}\cdot a_j^{(1)} δi(2)⋅aj(1) ,其中 δ i ( 2 ) \delta_i^{(2)} δi(2) 本质上是第 2 2 2 层中第 i i i 个神经元反向传播的误差。 a j ( 1 ) a_j^{(1)} aj(1) 与 W i j W_{ij} Wij 相乘的结果,输入第 2 2 2 层中第 i i i 个神经元中。
我们以下图为例,让我们从“误差共享/分配”的来阐释一下反向传播,现在我们要更新 W 14 ( 1 ) W_{14}^{(1)} W14(1) :

- ① 我们从 a 1 ( 3 ) a_1^{(3)} a1(3) 的1的误差信号开始反向传播
- ② 然后我们把误差与将 z 1 ( 3 ) z_1^{(3)} z1(3) 映射到 a 1 ( 3 ) a_1^{(3)} a1(3) 的神经元的局部梯度相乘。在这个例子中梯度正好等于1,则误差仍然为1。所以有 δ 1 ( 3 ) = 1 \delta_1^{(3)}=1 δ1(3)=1
- ③ 这里误差信号1已经到达 z 1 ( 3 ) z_1^{(3)} z1(3) 。我们现在需要分配误差信号使得误差的“公平共享”到达 a 1 ( 2 ) a_1^{(2)} a1(2)
- ④ 现在在 a 1 ( 2 ) a_1^{(2)} a1(2) 的误差为 δ 1 ( 3 ) × W 1 ( 2 ) = W 1 ( 2 ) \delta_1^{(3)}\times W_1^{(2)}=W_1^{(2)} δ1(3)×W1(2)=W1(2) (在 z 1 ( 3 ) z_1^{(3)} z1(3) 的误差信号为 δ 1 ( 3 ) \delta_1^{(3)} δ1(3) )。因此在 a 1 ( 2 ) a_1^{(2)} a1(2) 的误差为 W 1 ( 2 ) W_1^{(2)} W1(2)
- ⑤ 与第2步的做法相同,我们在将 z 1 ( 2 ) z_1^{(2)} z1(2) 映射到 a 1 ( 2 ) a_1^{(2)} a1(2) 的神经元上移动误差,将 a 1 ( 2 ) a_1^{(2)} a1(2) 与局部梯度相乘,这里的局部梯度为 f ′ ( z 1 ( 2 ) ) f'(z_1^{(2)}) f′(z1(2))
- ⑥ 因此在 z 1 ( 2 ) z_1^{(2)} z1(2) 的误差是 f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) f'(z_1^{(2)})W_1^{(2)} f′(z1(2))W1(2) ,我们将其定义为 δ 1 ( 2 ) \delta_1^{(2)} δ1(2)
- ⑦ 最后,我们通过将上面的误差与参与前向计算的 a 4 ( 1 ) a_4^{(1)} a4(1) 相乘,把误差的“误差共享”分配到 W 14 ( 1 ) W_{14}^{(1)} W14(1) 。
- ⑧ 所以,对于 W 14 ( 1 ) W_{14}^{(1)} W14(1) 的梯度损失可以计算为 a 4 ( 1 ) f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) a_4^{(1)}f'(z_1^{(2)})W_1^{(2)} a4(1)f′(z1(2))W1(2)
注意我们使用这个方法得到的结果是和之前微分的方法的结果是完全一样的。因此,计算网络中的相应参数的梯度误差既可以使用链式法则也可以使用误差共享和分配的方法——这两个方法能得到相同结果,但是多种方式考虑它们可能是有帮助的。
偏置更新:偏置项(例如 b 1 ( 1 ) b_1^{(1)} b1(1) )和其他权值在数学形式是等价的,只是在计算下一层神经 z 1 ( 2 ) z_1^{(2)} z1(2) 元输入时相乘的值是常量1。因此在第k层的第 i i i 个神经元的偏置的梯度时 δ i ( k ) \delta_i^{(k)} δi(k) 。例如在上面的例子中,我们更新的是 b 1 ( 1 ) b_1^{(1)} b1(1) 而不是 W 14 ( 1 ) W_{14}^{(1)} W14(1) ,那么这个梯度为 f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) f'(z_1^{(2)})W_1^{(2)} f′(z1(2))W1(2) 。
从 δ ( k ) \delta^{(k)} δ(k) 到 δ ( k − 1 ) \delta^{(k-1)} δ(k−1) 反向传播的一般步骤:
- ① 我们有从 z i ( k ) z_i^{(k)} zi(k) 向后传播的误差 δ i ( k ) \delta_i^{(k)} δi(k) ,如下图所示
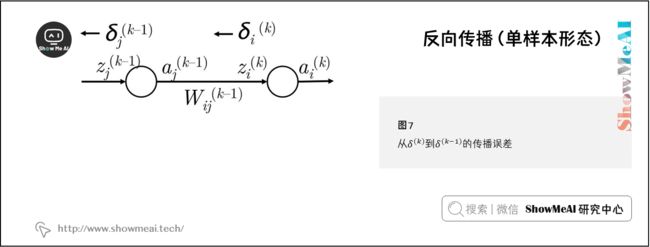
- ② 我们通过把 δ i ( k ) \delta_i^{(k)} δi(k) 与路径上的权值 W i j ( k − 1 ) W_{ij}^{(k-1)} Wij(k−1) 相乘,将这个误差反向传播到 a j ( k − 1 ) a_j^{(k-1)} aj(k−1)
- ③ 因此在 a j ( k − 1 ) a_j^{(k-1)} aj(k−1) 接收的误差是 δ i ( k ) W i j ( k − 1 ) \delta_i^{(k)}W_{ij}^{(k-1)} δi(k)Wij(k−1)
- ④ 然而, a j ( k − 1 ) a_j^{(k-1)} aj(k−1) 在前向计算可能出下图的情况,会参与下一层中的多个神经元的计算。那么第 k k k 层的第 m m m 个神经元的误差也要使用上一步方法将误差反向传播到 a j ( k − 1 ) a_j^{(k-1)} aj(k−1) 上
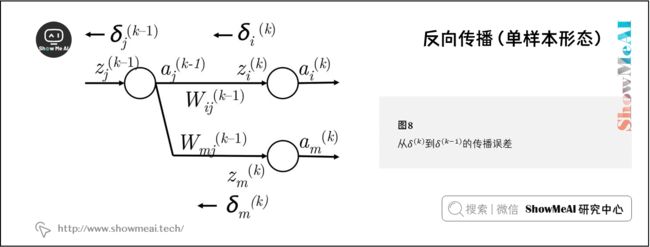
- ⑤ 因此现在在 a j ( k − 1 ) a_j^{(k-1)} aj(k−1) 接收的误差是 δ i ( k ) W i j ( k − 1 ) + δ m ( k ) W m j ( k − 1 ) \delta_i^{(k)}W_{ij}^{(k-1)}+\delta_m^{(k)}W_{mj}^{(k-1)} δi(k)Wij(k−1)+δm(k)Wmj(k−1)
- ⑥ 实际上,我们可以把上面误差和简化为 ∑ i δ i ( k ) W i j ( k − 1 ) \sum_i\delta_i^{(k)}W_{ij}^{(k-1)} ∑iδi(k)Wij(k−1)
- ⑦ 现在我们有在 a j ( k − 1 ) a_j^{(k-1)} aj(k−1) 正确的误差,然后将其与局部梯度 f ′ ( z j ( k − 1 ) ) f^{\prime}(z_j^{(k-1)}) f′(zj(k−1)) 相乘,把误差信息反向传到第 k − 1 k-1 k−1 层的第 j j j 个神经元上
- ⑧ 因此到达 z j ( k − 1 ) z_j^{(k-1)} zj(k−1) 的误差为 f ′ ( z j ( k − 1 ) ) ∑ i δ i ( k ) W i j ( k − 1 ) f ^{\prime} (z_j^{(k-1)})\sum_i\delta_i^{(k)}W_{ij}^{(k-1)} f′(zj(k−1))∑iδi(k)Wij(k−1)
1.6 反向传播(向量化形态)
在真实的神经网络训练过程中,我们通常会基于一批样本来更新网络权重,这里更高效的方式是向量化方式,借助于向量化的形态,我们可以直接一次更新权值矩阵和偏置向量。注意这只是对上面模型的简单地扩展,这将有助于更好理解在矩阵-向量级别上进行误差反向传播的方法。
对更定的参数 W i j ( k ) W_{ij}^{(k)} Wij(k) ,我们知道它的误差梯度是 δ j ( k + 1 ) ⋅ a j ( k ) \delta_j^{(k+1)}\cdot a_j^{(k)} δj(k+1)⋅aj(k) 。其中 W ( k ) W^{(k)} W(k) 是将 a ( k ) a^{(k)} a(k) 映射到 z ( k + 1 ) z^{(k+1)} z(k+1) 的矩阵。因此我们可以确定整个矩阵 W ( k ) W^{(k)} W(k) 的梯度误差为:
∇ W ( k ) = [ δ 1 ( k + 1 ) a 1 ( k ) δ 1 ( k + 1 ) a 2 ( k ) ⋯ δ 2 ( k + 1 ) a 1 ( k ) δ 2 ( k + 1 ) a 2 ( k ) ⋯ ⋮ ⋮ ⋱ ] = δ ( k + 1 ) a ( k ) T \nabla_{W^{(k)}} = \begin{bmatrix} \delta_1^{(k+1)}a_1^{(k)} & \delta_1^{(k+1)}a_2^{(k)} & \cdots \\ \delta_2^{(k+1)}a_1^{(k)} & \delta_2^{(k+1)}a_2^{(k)} & \cdots \\ \vdots & \vdots & \ddots \\ \end{bmatrix} = \delta^{(k+1)}a^{(k)T} ∇W(k)=⎣⎢⎢⎡δ1(k+1)a1(k)δ2(k+1)a1(k)⋮δ1(k+1)a2(k)δ2(k+1)a2(k)⋮⋯⋯⋱⎦⎥⎥⎤=δ(k+1)a(k)T
因此我们可以将整个矩阵形式的梯度写为在矩阵中的反向传播的误差向量和前向激活输出的外积。
现在我们来看看如何能够计算误差向量 δ ( k + 1 ) \delta^{(k+1)} δ(k+1) 。
我们从上面的例子中有
δ i ( k ) = f ′ ( z j ( k ) ) ∑ i δ i ( k + 1 ) W i j ( k ) \delta_i^{(k)}=f^{\prime}(z_j^{(k)})\sum_i\delta_i^{(k+1)}W_{ij}^{(k)} δi(k)=f′(zj(k))i∑δi(k+1)Wij(k)
这可以简单地改写为矩阵的形式:
δ i ( k ) = f ′ ( z ( k ) ) ∘ ( W ( k ) T δ ( k + 1 ) ) \delta_i^{(k)}=f^{\prime} (z^{(k)})\circ (W^{(k)T}\delta^{(k+1)}) δi(k)=f′(z(k))∘(W(k)Tδ(k+1))
在上面的公式中 ∘ \circ ∘ 运算符是表示向量之间对应元素的相乘( R N × R N → R N \mathbb{R}^{N}\times \mathbb{R}^{N}\rightarrow \mathbb{R}^{N} RN×RN→RN )。
计算效率:在探索了element-wise的更新和vector-wise的更新之后,必须认识到在科学计算环境中,如MATLAB或Python(使用Numpy / Scipy 库),向量化运算的计算效率是非常高的。因此在实际中应该使用向量化运算。此外,我们也要减少反向传播中的多余的计算——例如,注意到 δ ( k ) \delta^{(k)} δ(k) 是直接依赖在 δ ( k + 1 ) \delta^{(k+1)} δ(k+1) 上。所以我们要保证使用 δ ( k + 1 ) \delta^{(k+1)} δ(k+1) 更新 W ( k ) W^{(k)} W(k) 时,要保存 δ ( k + 1 ) \delta^{(k+1)} δ(k+1) 用于后面 δ ( k ) \delta^{(k)} δ(k) 的计算-然后计算 ( k − 1 ) ⋯ ( 1 ) (k-1) \cdots (1) (k−1)⋯(1) 层的时候重复上述的步骤。这样的递归过程是使得反向传播成为计算上可负担的过程。
2.神经网络:技巧与建议
(本部分内容也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 深度学习的实用层面)
2.1 梯度检查
上一部分我们介绍了如何用基于微积分的方法计算神经网络中的参数的误差梯度/更新。
这里我们介绍一种用数值近似这些梯度的方法——虽然在计算上的低效不能直接用于训练神经网络,这种方法可以非常准确地估计任何参数的导数;因此,它可以作为对导数的正确性的有用的检查。
给定一个模型的参数向量 θ \theta θ 和损失函数 J J J ,围绕 θ i \theta_i θi 的数值梯度由 central difference formula 得出:
f ′ ( θ ) ≈ J ( θ ( i + ) ) − J ( θ ( i − ) ) 2 ε f^{\prime}(\theta)\approx \frac{J(\theta^{(i+)})-J(\theta^{(i-)})}{2\varepsilon } f′(θ)≈2εJ(θ(i+))−J(θ(i−))
其中 ε \varepsilon ε 是一个很小的值(一般约为 1 e − 5 1e^{-5} 1e−5 )。当我们使用 + ε +\varepsilon +ε 扰动参数 θ \theta θ 的第 i i i 个元素时,就可以在前向传播上计算误差 J ( θ ( i + ) ) J(\theta^{(i+)}) J(θ(i+)) 。相似地,当我们使用 − ε -\varepsilon −ε 扰动参数 θ \theta θ 的第 i i i 个元素时,就可以在前向传播上计算误差 J ( θ ( i − ) ) J(\theta^{(i-)}) J(θ(i−)) 。
因此,计算两次前向传播,我们可以估计在模型中任意给定参数的梯度。我们注意到数值梯度的定义和导数的定义很相似,其中,在标量的情况下:
f ′ ( θ ) ≈ f ( x + ε ) − f ( x ) ε f^{\prime}(\theta)\approx \frac{f(x+\varepsilon)-f(x)}{\varepsilon} f′(θ)≈εf(x+ε)−f(x)
当然,还是有一点不同——上面的定义仅仅在正向扰动 x x x 计算梯度。虽然是可以用这种方式定义数值梯度,但在实际中使用 central difference formula 常常可以更准确和更稳定,因为我们在两个方向都对参数扰动。为了更好地逼近一个点附近的导数/斜率,我们需要在该点的左边和右边检查函数 f ′ f^{\prime} f′ 的行为。也可以使用泰勒定理来表示 central difference formula 有 ε 2 \varepsilon^{2} ε2 比例误差,这相当小,而导数定义更容易出错。
现在你可能会产生疑问,如果这个方法这么准确,为什么我们不用它而不是用反向传播来计算神经网络的梯度?
- ① 我们需要考虑效率——每当我们想计算一个元素的梯度,需要在网络中做两次前向传播,这样是很耗费计算资源的。
- ② 很多大规模的神经网络含有几百万的参数,对每个参数都计算两次明显不是一个好的选择。
- ③ 在例如 SGD 这样的优化技术中,我们需要通过数千次的迭代来计算梯度,使用这样的方法很快会变得难以应付。
我们只使用梯度检验来验证我们的分析梯度的正确性。梯度检验的实现如下所示:
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient
at
"""
f(x) = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index',
op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh_left = f(x) # evaluate f(x + h)
x[ix] = old_value - h # decrement by h
fxh_right = f(x) # evaluate f(x - h)
# restore to previous value (very important!)
x[ix] = old_value
# compute the partial derivative
# the slope
grad[ix] = (fxh_left - fxh_right) / (2 * h)
it.iternext() # step to next dimension
return grad
2.2 正则化
和很多机器学习的模型一样,神经网络很容易过拟合,这令到模型在训练集上能获得近乎完美的表现,但是却不能泛化到测试集上。一个常见的用于解决过拟合(“高方差问题”)的方法是使用 L 2 L2 L2 正则化。我们只需要在损失函数 J J J 上增加一个正则项,现在的损失函数如下:
J R = J + λ ∑ i = 1 L ∥ W ( i ) ∥ F J_{R}=J+\lambda\sum_{i=1}^{L}\left \| W^{(i)} \right \| _F JR=J+λi=1∑L∥∥∥W(i)∥∥∥F
在上面的公式中, ∥ W ( i ) ∥ F \left \| W^{(i)} \right \| _F ∥∥W(i)∥∥F 是矩阵 W ( i ) W^{(i)} W(i) (在神经网络中的第 i i i 个权值矩阵)的 Frobenius 范数, λ \lambda λ 是超参数控制损失函数中的权值的大小。
❐ 矩阵 U U U 的 Frobenius 范数的定义: ∥ U ∥ F = ∑ i ∑ l U i l 2 \left \| U \right \| _F=\sqrt{\sum_i \sum_{l} U_{i l}^{2}} ∥U∥F=∑i∑lUil2
当我们尝试去最小化 J R J_R JR ,正则化本质上就是当优化损失函数的时候,惩罚数值太大的权值(让权值的数值分配更加均衡,防止出现部分权值特别大的情况)。
由于 Frobenius 范数的二次的性质(计算矩阵的元素的平方和), L 2 L2 L2 正则项有效地降低了模型的灵活性和因此减少出现过拟合的可能性。
增加这样一个约束可以使用贝叶斯派的思想解释,这个正则项是对模型的参数加上一个先验分布,优化权值使其接近于 0——有多接近是取决于 λ \lambda λ 的值。选择一个合适的 λ \lambda λ 值是很重要的,并且需要通过超参数调整来选择。
- λ \lambda λ 的值太大会令很多权值都接近于 0 0 0 ,则模型就不能在训练集上学习到有意义的东西,经常在训练、验证和测试集上的表现都非常差。
- λ \lambda λ 的值太小,会让模型仍旧出现过拟合的现象。
需要注意的是,偏置项不会被正则化,不会计算入损失项中——尝试去思考一下为什么
❐ 为何在损失项中不计算偏置项?
偏置项在模型中仅仅是偏移的关系,使用少量的数据就能拟合到这项,而且从经验上来说,偏置值的大小对模型表现没有很显著的影响,因此不需要正则化偏置项
有时候我们会用到其他类型的正则项,例如 L 1 L1 L1 正则项,它将参数元素的绝对值全部加起来-然而,在实际中很少会用 L 1 L1 L1 正则项,因为会令权值参数变得稀疏。在下一部分,我们讨论 Dropout ,这是另外一种有效的正则化方法,通过在前向传播过程随机将神经元设为 0 0 0
❐ Dropout 实际上是通过在每次迭代中忽略它们的权值来实现“冻结”部分 unit 。这些“冻结”的 unit 不是把它们设为 0 0 0 ,而是对于该迭代,网络假定它们为 0 0 0 。“冻结”的 unit 不会为此次迭代更新
2.3 随机失活Dropout
Dropout 是一个非常强大的正则化技术,是 Srivastava 在论文 《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》中首次提出,下图展示了 Dropout 如何应用在神经网络上。
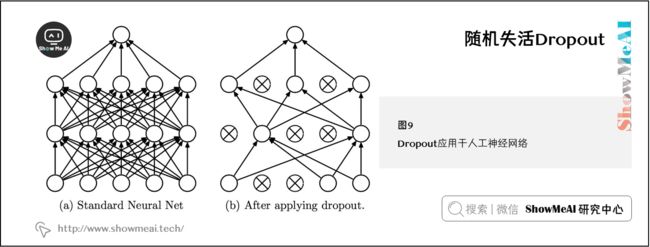
这个想法是简单而有效的——训练过程中,在每次的前向/反向传播中我们按照一定概率 ( 1 − p ) (1-p) (1−p) 随机地“ drop ”一些神经元子集(或者等价的,我们保持一定概率 p p p 的神经元是激活的)。然后,在测试阶段,我们将使用全部的神经元来进行预测。
使用 Dropout 神经网络一般能从数据中学到更多有意义的信息,更少出现过拟合和通常在现今的任务上获得更高的整体表现。这种技术应该如此有效的一个直观原因是, Dropout 本质上作的是一次以指数形式训练许多较小的网络,并对其预测进行平均。
实际上,我们使用 Dropout 的方式是我们取每个神经元层的输出 h h h ,并保持概率 p p p 的神经元是激活的,否则将神经元设置为 0 0 0 。然后,在反向传播中我们仅对在前向传播中激活的神经元回传梯度。最后,在测试过程,我们使用神经网络中全部的神经元进行前向传播计算。然而,有一个关键的微妙之处,为了使 Dropout 有效地工作,测试阶段的神经元的预期输出应与训练阶段大致相同——否则输出的大小可能会有很大的不同,网络的表现已经不再明确了。因此,我们通常必须在测试阶段将每个神经元的输出除以某个值——这留给读者作为练习来确定这个值应该是多少,以便在训练和测试期间的预期输出相等(该值为 p p p ) 。
1) Dropout内容补充
以下源于 《神经网络与深度学习》
-
目的:缓解过拟合问题,一定程度上达到正则化的效果
-
效果:减少下层节点对其的依赖,迫使网络去学习更加鲁棒的特征
2) 集成学习的解释
每做一次丢弃,相当于从原始的网络中采样得到一个子网络。 如果一个神经网络有 n n n 个神经元,那么总共可以采样出 2 n 2^n 2n 个子网络。
每次迭代都相当于训练一个不同的子网络,这些子网络都共享原始网络的参数。那么,最终的网络可以近似看作是集成了指数级个不同网络的组合模型。
3) 贝叶斯学习的解释
丢弃法也可以解释为一种贝叶斯学习的近似。用 y = f ( x , θ ) y=f(\mathbf{x}, \theta) y=f(x,θ) 来表示要学习的神经网络,贝叶斯学习是假设参数 θ \theta θ 为随机向量,并且先验分布为 q ( θ ) q(\theta) q(θ) ,贝叶斯方法的预测为:
E q ( θ ) [ y ] = ∫ q f ( x , θ ) q ( θ ) d θ ≈ 1 M ∑ m = 1 M f ( x , θ m ) \begin{aligned} \mathbb{E}_{q(\theta)}[y] &=\int_{q} f(\mathbf{x}, \theta) q(\theta) d \theta \\ & \approx \frac{1}{M} \sum_{m=1}^{M} f\left(\mathbf{x}, \theta_m\right) \end{aligned} Eq(θ)[y]=∫qf(x,θ)q(θ)dθ≈M1m=1∑Mf(x,θm)
其中 f ( x , θ m ) f(\mathbf{x}, \theta_m) f(x,θm) 为第m次应用丢弃方法后的网络,其参数 θ m \theta_m θm 为对全部参数 θ \theta θ 的一次采样。
4) RNN中的变分Dropout (Variational Dropout)
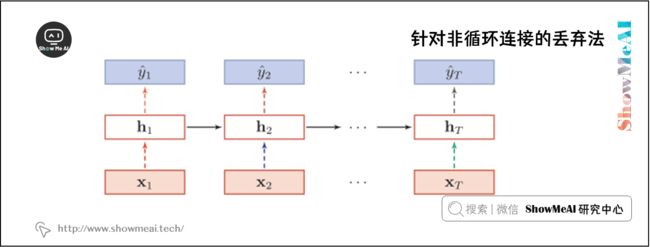
Dropout一般是针对神经元进行随机丢弃,但是也可以扩展到对神经元之间的连接进行随机丢弃,或每一层进行随机丢弃。
在RNN中,不能直接对每个时刻的隐状态进行随机丢弃,这样会损害循环网络在时间维度上记忆能力。一种简单的方法是对非时间维度的连接(即非循环连接)进行随机丢失。如图所示,虚线边表示进行随机丢弃,不同的颜色表示不同的丢弃掩码。
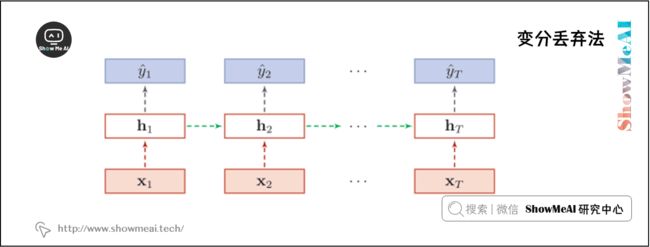
然而根据贝叶斯学习的解释,丢弃法是一种对参数 θ θ θ 的采样。每次采样的参数需要在每个时刻保持不变。因此,在对循环神经网络上使用丢弃法时,需要对参数矩阵的每个元素进行随机丢弃,并在所有时刻都使用相同的丢弃掩码。这种方法称为变分丢弃法(Variational Dropout)。
下图给出了变分丢弃法的示例,相同颜色表示使用相同的丢弃掩码。
2.4 神经元激活函数
我们在前面看到的神经网络都是基于sigmoid激活函数做非线性分类的。但是在很多应用中,使用其他激活函数可以设计更好的神经网络。下面列出一些常见的激活函数和激活函数的梯度定义,它们可以和前面讨论过的sigmoidal函数互相替换。
1) Sigmoid
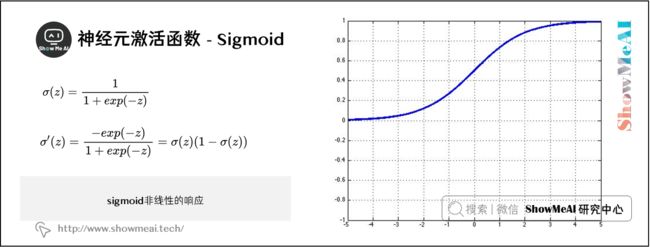
这是我们讨论过的常用选择,激活函数 σ \sigma σ 为:
σ ( z ) = 1 1 + e x p ( − z ) \sigma(z)=\frac{1}{1+exp(-z)} σ(z)=1+exp(−z)1
其中 σ ( z ) ∈ ( 0 , 1 ) \sigma(z)\in (0,1) σ(z)∈(0,1)
σ ( z ) \sigma(z) σ(z) 的梯度为:
σ ′ ( z ) = − e x p ( − z ) 1 + e x p ( − z ) = σ ( z ) ( 1 − σ ( z ) ) \sigma^{\prime}(z)=\frac{-exp(-z)}{1+exp(-z)}=\sigma(z)(1-\sigma(z)) σ′(z)=1+exp(−z)−exp(−z)=σ(z)(1−σ(z))
2) tanh
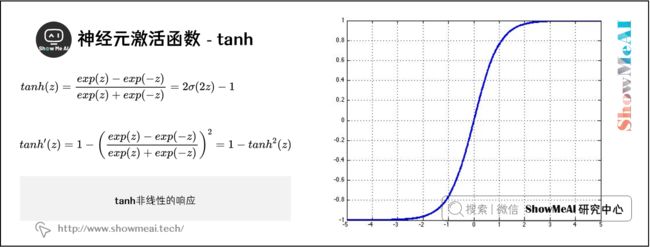
tanh函数是sigmoid函数之外的另一个选择,在实际中它能更快地收敛。tanh和sigmoid的主要不同在于tanh的输出范围在-1到1,而sigmoid的输出范围在0到1。
t a n h ( z ) = e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) = 2 σ ( 2 z ) − 1 tanh(z)=\frac{exp(z)-exp(-z)}{exp(z)+exp(-z)}=2\sigma(2z)-1 tanh(z)=exp(z)+exp(−z)exp(z)−exp(−z)=2σ(2z)−1
其中 t a n h ( z ) ∈ ( − 1 , 1 ) tanh(z)\in (-1, 1) tanh(z)∈(−1,1)
$ anh(z) $的梯度为:
t a n h ′ ( z ) = 1 − ( e x p ( z ) − e x p ( − z ) e x p ( z ) + e x p ( − z ) ) 2 = 1 − t a n h 2 ( z ) tanh^{\prime}(z)=1-\bigg(\frac{exp(z)-exp(-z)}{exp(z)+exp(-z)}\bigg)^{2}=1-tanh^{2}(z) tanh′(z)=1−(exp(z)+exp(−z)exp(z)−exp(−z))2=1−tanh2(z)
3) hard tanh

有时候hardtanh函数有时比tanh函数的选择更为优先,因为它的计算量更小。然而当 z z z 的值大于 1 1 1 时,函数的数值会饱和(如下图所示会恒等于1)。
hardtanh激活函数为:
h a r d t a n h ( z ) = { − 1 : z < 1 z : − 1 ≤ z ≤ 1 1 : z > 1 \begin{aligned} hardtanh(z) = \begin{cases} -1& :z<1\\ z & :-1\le z \le 1 \\ 1 & :z>1 \end{cases} \end{aligned} hardtanh(z)=⎩⎪⎨⎪⎧−1z1:z<1:−1≤z≤1:z>1
hardtanh这个函数的微分也可以用分段函数的形式表示:
h a r d t a n h ′ ( z ) = { 1 : − 1 ≤ z ≤ 1 0 : o t h e r w i s e \begin{aligned} hardtanh ^{\prime}(z) &= \begin{cases} 1 & :-1\le z \le 1 \\ 0 & :otherwise \end{cases} \end{aligned} hardtanh′(z)={10:−1≤z≤1:otherwise
4) soft sign

soft sign函数是另外一种非线性激活函数,它可以是tanh的另外一种选择,因为它和hard clipped functions 一样不会过早地饱和:
s o f t s i g n ( z ) = z 1 + ∣ z ∣ softsign(z)=\frac{z}{1+ \left | z \right |} softsign(z)=1+∣z∣z
soft sign函数的微分表达式为:
s o f t s i g n ′ ( z ) = s g n ( z ) ( 1 + z ) 2 softsign^{\prime}(z)=\frac{sgn(z)}{(1+z)^{2}} softsign′(z)=(1+z)2sgn(z)
其中, s g n sgn sgn 是符号函数,根据 z z z 的符号返回1或者-1。
5) ReLU
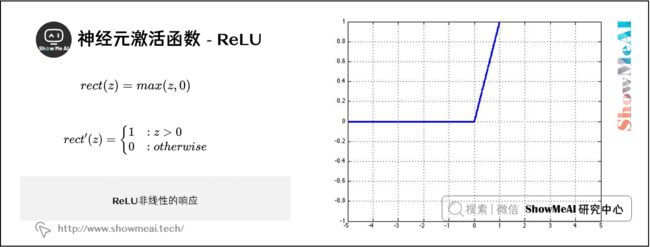
ReLU ( Rectified Linear Unit )函数是激活函数中的一个常见的选择,当 z z z 的值特别大的时候它也不会饱和。在计算机视觉应用中取得了很大的成功:
r e c t ( z ) = m a x ( z , 0 ) rect(z)=max(z,0) rect(z)=max(z,0)
ReLU函数的微分是一个分段函数:
r e c t ′ ( z ) = { 1 : z > 0 0 : o t h e r w i s e \begin{aligned} rect^{\prime}(z) &= \begin{cases} 1 & :z > 0 \\ 0 & :otherwise \end{cases} \end{aligned} rect′(z)={10:z>0:otherwise
6) Leaky ReLU
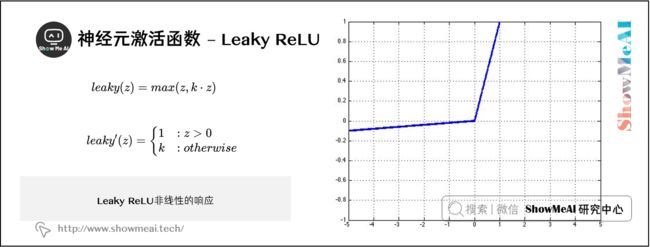
传统的ReLU单元当 z z z 的值小于 0 0 0 时,是不会反向传播误差leaky ReLU改善了这一点,当 z z z 的值小于 0 0 0 时,仍然会有一个很小的误差反向传播回去。
l e a k y ( z ) = m a x ( z , k ⋅ z ) leaky(z)=max(z, k\cdot z) leaky(z)=max(z,k⋅z)
其中 0 < k < 1 0
leaky ReLU函数的微分是一个分段函数:
l e a k y ′ ( z ) = { 1 : z > 0 k : o t h e r w i s e \begin{aligned} leaky ^{\prime} (z) &= \begin{cases} 1 & :z > 0 \\ k & :otherwise \end{cases} \end{aligned} leaky′(z)={1k:z>0:otherwise
2.5 数据预处理
与机器学习模型的一般情况一样,确保模型在当前任务上获得合理性能的一个关键步骤是对数据执行基本的预处理。下面概述了一些常见的技术。
1) 去均值
给定一组输入数据 X X X ,一般把 X X X 中的值减去 X X X 的平均特征向量来使数据零中心化。在实践中很重要的一点是,只计算训练集的平均值,而且在训练集,验证集和测试集都是减去同一平均值。
2) 归一化
另外一个常见的技术(虽然没有 m e a n S u b t r a c t i o n mean\;Subtraction meanSubtraction 常用)是将每个输入特征维度缩小,让每个输入特征维度具有相似的幅度范围。这是很有用的,因此不同的输入特征是用不同“单位”度量,但是最初的时候我们经常认为所有的特征同样重要。实现方法是将特征除以它们各自在训练集中计算的标准差。
3) 白化
相比上述的两个方法,whitening没有那么常用,它本质上是数据经过转换后,特征之间相关性较低,所有特征具有相同的方差(协方差阵为 1 1 1 )。首先对数据进行Mean Subtraction处理,得到 X ′ X ^{\prime} X′ 。然后我们对 X ′ X ^{\prime} X′ 进行奇异值分解得到矩阵 U U U , S S S , V V V ,计算 U X ′ UX^{\prime} UX′ 将 X ′ X^{\prime} X′ 投影到由 U U U 的列定义的基上。我们最后将结果的每个维度除以 S S S 中的相应奇异值,从而适当地缩放我们的数据(如果其中有奇异值为0,我们就除以一个很小的值代替)。
2.6 参数初始化
让神经网络实现最佳性能的关键一步是以合理的方式初始化参数。一个好的起始方法是将权值初始化为通常分布在0附近的很小的随机数-在实践中效果还不错。
在论文《Understanding the difficulty of training deep feedforward neural networks (2010)》, Xavier 研究不同权值和偏置初始化方案对训练动力( training dynamics )的影响。实验结果表明,对于sigmoid和tanh激活单元,当一个权值矩阵 W ∈ R n ( l + 1 ) × n ( l ) W\in \mathbb{R}^{n^{(l+1)}\times n^{(l)}} W∈Rn(l+1)×n(l) 以如下的均匀分布的方式随机初始化,能够实现更快的收敛和得到更低的误差:
W ∼ U [ − 6 n ( l ) + n ( l + 1 ) , 6 n ( l ) + n ( l + 1 ) ] W\sim U\bigg[-\sqrt{\frac{6}{n^{(l)}+n^{(l+1)}}},\sqrt{\frac{6}{n^{(l)}+n^{(l+1)}}}\;\bigg] W∼U[−n(l)+n(l+1)6,n(l)+n(l+1)6]
其中 n ( l ) n^{(l)} n(l) 是W ( f a n - i n ) (fan\text{-}in) (fan-in) 的输入单元数, n ( l + 1 ) n^{(l+1)} n(l+1) 是W ( f a n - o u t ) (fan\text{-}out) (fan-out) 的输出单元数。在这个参数初始化方案中,偏置单元是初始化为 0 0 0 。这种方法是尝试保持跨层之间的激活方差以及反向传播梯度方差。如果没有这样的初始化,梯度方差(当中含有纠正信息)通常随着跨层的反向传播而衰减。
2.7 学习策略
训练期间模型参数更新的速率/幅度可以使用学习率进行控制。在最简单的梯度下降公式中, α \alpha α 是学习率:
θ n e w = θ o l d − α ∇ θ J t ( θ ) \theta^{new}=\theta^{old}-\alpha\nabla_{\theta}J_{t}(\theta) θnew=θold−α∇θJt(θ)
你可能会认为如果要更快地收敛,我们应该对 α \alpha α 取一个较大的值——然而,在更快的收敛速度下并不能保证更快的收敛。实际上,如果学习率非常高,我们可能会遇到损失函数难以收敛的情况,因为参数更新幅度过大,会导致模型越过凸优化的极小值点,如下图所示。在非凸模型中(我们很多时候遇到的模型都是非凸),高学习率的结果是难以预测的,但是损失函数难以收敛的可能性是非常高的。
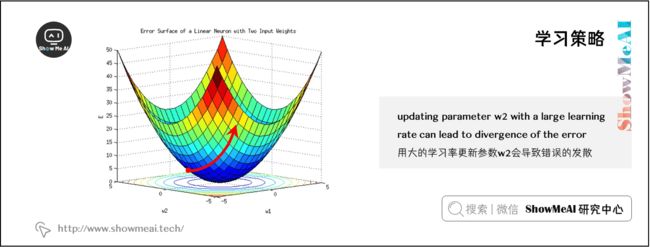
避免损失函数难以收敛的一个简答的解决方法是使用一个很小的学习率,让模型谨慎地在参数空间中迭代——当然,如果我们使用了一个太小的学习率,损失函数可能不会在合理的时间内收敛,或者会困在局部最优点。因此,与任何其他超参数一样,学习率必须有效地调整。
深度学习系统中最消耗计算资源的是训练阶段,一些研究已在尝试提升设置学习率的新方法。例如,Ronan Collobert通过取 f a n - i n fan\text{-}in fan-in 的神经元 ( n ( l ) ) (n^{(l)}) (n(l)) 的平方根的倒数来缩放权值 W i j W_{ij} Wij ( W ∈ R n ( l + 1 ) × n ( l ) W\in \mathbb{R}^{n^{(l+1)}\times n^{(l)}} W∈Rn(l+1)×n(l) )的学习率。
还有其他已经被证明有效的技术-这个方法叫annealing退火,在多次迭代之后,学习率以以下方式降低:保证以一个高的的学习率开始训练和快速逼近最小值;当越来越接近最小值时,开始降低学习率,让我们可以在更细微的范围内找到最优值。一个常见的实现annealing的方法是在每 n n n 次的迭代学习后,通过一个因子 x x x 来降低学习率 α \alpha α 。
指数衰减也是很常见的方法,在 t t t 次迭代后学习率变为 α ( t ) = α 0 e − k t \alpha(t)=\alpha_0 e^{-kt} α(t)=α0e−kt ,其中 α 0 \alpha_0 α0 是初始的学习率和 k k k 是超参数。
还有另外一种方法是允许学习率随着时间减少:
α ( t ) = α 0 τ m a x ( t , τ ) \alpha(t)=\frac{\alpha_0\tau}{max(t,\tau)} α(t)=max(t,τ)α0τ
在上述的方案中, α 0 \alpha_0 α0 是一个可调的参数,代表起始的学习率。 τ \tau τ 也是一个可调参数,表示学习率应该在该时间点开始减少。在实际中,这个方法是很有效的。在下一部分我们讨论另外一种不需要手动设定学习率的自适应梯度下降的方法。
2.8 带动量的优化更新(Momentum)
(神经网络优化算法也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 神经网络优化算法)
动量方法,灵感来自于物理学中的对动力学的研究,是梯度下降方法的一种变体,尝试使用更新的“速度”的一种更有效的更新方案。动量更新的伪代码如下所示:
# Computes a standard momentum update
# on parameters x
v = mu * v - alpha * grad_x
x += v
2.9 自适应优化算法
(神经网络优化算法也可以参考ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 神经网络优化算法)
AdaGrad是标准的随机梯度下降(SGD)的一种实现,但是有一点关键的不同:对每个参数学习率是不同的。每个参数的学习率取决于每个参数梯度更新的历史,参数的历史更新越小,就使用更大的学习率加快更新。换句话说,过去没有更新太大的参数现在更有可能有更高的学习率。
θ t , i = θ t − 1 , i − α ∑ τ = 1 t g τ , i 2 g t , i w h e r e g t , i = ∂ ∂ θ i t J t ( θ ) \theta_{t,i}=\theta_{t-1,i}-\frac{\alpha}{\sqrt{\sum_{\tau=1}^{t}g_{\tau,i}^{2}}} g_{t,i} \\ where \ g_{t,i}=\frac{\partial}{\partial\theta_i^{t}}J_{t}(\theta) θt,i=θt−1,i−∑τ=1tgτ,i2αgt,iwhere gt,i=∂θit∂Jt(θ)
在这个技术中,我们看到如果梯度的历史RMS很低,那么学习率会非常高。这个技术的一个简单的实现如下所示:
# Assume the gradient dx and parameter vector x
cache += dx ** 2
x += -learning_rate * dx / np.sqrt(cache + 1e-8)
其他常见的自适应方法有 RMSProp 和 Adam ,其更新规则如下所示:
# Update rule for RMS prop
cache = decay_rate * cache + (1 - decay_rate) * dx ** 2
x += -learning_rate * dx / (np.sqrt(cache) + eps)
# Update rule for Adam
m = beta * m + (1 - beta1) * dx
v = beta * v + (1 - beta2) * (dx ** 2)
x += -learning_rate * m / (np.sqrt(v) + eps)
- RMSProp是利用平方梯度的移动平局值,是AdaGrad的一个变体——实际上,和AdaGrad不一样,它的更新不会单调变小。
- Adam更新规则又是RMSProp的一个变体,但是加上了动量更新。
3.参考资料
- 《ShowMeAI 深度学习与自然语言处理教程》的PDF在线阅读版本 - note3
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
- Stanford官网 | CS224n: Natural Language Processing with Deep Learning
- 如果希望了解以上的梯度优化算法的具体细节,可以阅读这篇文章: An overview of gradient descent optimization algorithms
ShowMeAI 深度学习与自然语言处理教程(完整版)
- ShowMeAI 深度学习与自然语言处理教程(1) - 词向量、SVD分解与Word2vec
- ShowMeAI 深度学习与自然语言处理教程(2) - GloVe及词向量的训练与评估
- ShowMeAI 深度学习与自然语言处理教程(3) - 神经网络与反向传播
- ShowMeAI 深度学习与自然语言处理教程(4) - 句法分析与依存解析
- ShowMeAI 深度学习与自然语言处理教程(5) - 语言模型、RNN、GRU与LSTM
- ShowMeAI 深度学习与自然语言处理教程(6) - 神经机器翻译、seq2seq与注意力机制
- ShowMeAI 深度学习与自然语言处理教程(7) - 问答系统
- ShowMeAI 深度学习与自然语言处理教程(8) - NLP中的卷积神经网络
- ShowMeAI 深度学习与自然语言处理教程(9) - 句法分析与树形递归神经网络
ShowMeAI 斯坦福NLP名课 CS224n带学详解(20讲·完整版)
- 斯坦福NLP名课带学详解 | CS224n 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP名课带学详解 | CS224n 第2讲 - 词向量进阶
- 斯坦福NLP名课带学详解 | CS224n 第3讲 - 神经网络知识回顾
- 斯坦福NLP名课带学详解 | CS224n 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP名课带学详解 | CS224n 第5讲 - 句法分析与依存解析
- 斯坦福NLP名课带学详解 | CS224n 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP名课带学详解 | CS224n 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP名课带学详解 | CS224n 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP名课带学详解 | CS224n 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP名课带学详解 | CS224n 第10讲 - NLP中的问答系统
- 斯坦福NLP名课带学详解 | CS224n 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP名课带学详解 | CS224n 第12讲 - 子词模型
- 斯坦福NLP名课带学详解 | CS224n 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP名课带学详解 | CS224n 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP名课带学详解 | CS224n 第15讲 - NLP文本生成任务
- 斯坦福NLP名课带学详解 | CS224n 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP名课带学详解 | CS224n 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP名课带学详解 | CS224n 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP名课带学详解 | CS224n 第19讲 - AI安全偏见与公平
- 斯坦福NLP名课带学详解 | CS224n 第20讲 - NLP与深度学习的未来
ShowMeAI系列教程精选推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
