第1周学习:深度学习入门和pytorch基础
目录
一、绪论
二、深度学习
三、pytorch基础
前言:
1. 定义数据
2. 定义操作
四、螺旋数据分类
初始化3000个样本的特征
1. 构建线性模型分类
torch.optim.SGD(x,x,x)
nn.Linear()-Linear中包含四个属性:
梯度清零
2. 构建三层前馈神经网络,引入非线性激活函数ReLU
3.下面试一试双隐层神经网络训练模型的效果
一、绪论

二、深度学习
三、pytorch基础
前言:
首先我更新了笔记本的显卡,配置了cuda和cudnn;随后在anaconda下创建了一个新环境pytorch_env,将pytorch安装在此环境下(直接下载的torch和torchvision的whl文件,未使用官网推荐的命令行方式),最后给pytorch_env这个新环境配置了jupyter notebook,下载pycharm并进行配置。
参考:
1、cuda,cudnn安装
2、更新显卡、pytorch安装等
3、相应的视频——来自B站,很靠谱
PyTorch是一个python库,它主要提供了两个高级功能:
- GPU加速的张量计算
- 构建在反向自动求导系统上的深度神经网络
1. 定义数据
一般定义数据使用torch.Tensor,tensor的意思是张量,是数字各种形式的总称
import torch
a = torch.tensor(666) # 可以是一个数
b = torch.tensor([1,2,3,4,5,6]) # 可以是一维数组(向量)
c = torch.ones(2,3) # 可以是二维数组(矩阵)
d = torch.ones(2,3,4) # 可以是任意维度的数组(张量)
Tensor支持各种各样类型的数据,包括:
torch.float32, torch.float64, torch.float16, torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64 。
创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm
x = torch.rand(5,3) # 创建一个随机初始化的张量
x = torch.zeros(5,3,dtype=torch.long) # 创建一个全0的张量,里面的数据类型为 long
# 基于现有的tensor,创建一个新tensor,
# 从而可以利用原有的tensor的dtype,device,size之类的属性信息
y = x.new_ones(5,3)
z = torch.randn_like(x, dtype=torch.float) # 利用原来的tensor的大小,但是重新定义了dtype
2. 定义操作
(1)基本运算
(2)布尔运算
(3)线性运算:矩阵乘法,求模,求行列式
注意:torch.Tensor() 建立的张量默认数据类型是 torch.float32,张量类型是 torch.FloatTensor; 而 torch.tensor() 建立的张量默认数据类型 torch.int64,张量类型是 torch.LongTensor
数量积 m @ v
v = torch.arange(1,5) # tensor([1, 2, 3, 4])
m = torch.Tensor([[2, 5, 3, 7],[4, 2, 1, 9]])
'''
tensor([[2., 5., 3., 7.],
[4., 2., 1., 9.]])
'''
print(m.dtype)
print(v.dtype)![]()

要修改@两边张量的数据类型,使其一致
m = m.type(torch.long)
m @ v![]()
矩阵转置
print(m.t()) # 转置,由 2x4 变为 4x2
print(m.transpose(0, 1)) # 使用 transpose 也可以达到相同的效果拼接矩阵
a = torch.tensor([[1, 2, 3, 4]])
b = torch.tensor([[5, 6, 7, 8]])
# 在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵
print(torch.cat((a,b),0))
# 在 1 方向拼接 (即在 X 方各上拼接), 会得到 1x8 的矩阵
print(torch.cat((a,b),1))
生成 1000 个随机数,并按照 100 个 bin 统计直方图
from matplotlib import pyplot as plt# matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示
# 注意 randn 是生成均值为 0, 方差为 1 的随机数
# 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
plt.hist(torch.randn(1000).numpy(),100)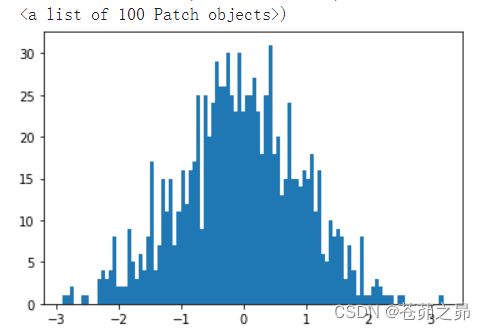
当数据非常多的时候,呈正态分布
plt.hist(torch.randn(10**6).numpy(),100);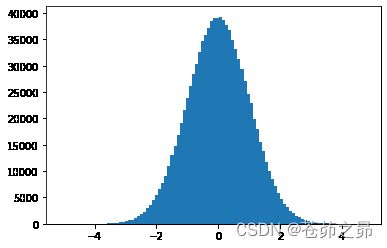
四、螺旋数据分类
理论:https://atcold.github.io/pytorch-Deep-Learning/zh/week02/02-3/
# 下载绘图函数到本地。(画点的过程中要用到里面的一些函数)
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.py引入基本的库,然后初始化重要参数
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度 2D-2维平面(x, y)
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量![]()
初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列,大家得注意下,不要搞反了。
如果 zeros 参数只有一个,是x方向的,即矩阵的列。
下面结合代码看看 3000个样本的特征是如何初始化的。
初始化3000个样本的特征
X = torch.zeros(N * C, D).to(device) #特征矩阵
Y = torch.zeros(N * C, dtype=torch.long).to(device) #样本标签
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
# 根据公式计算出三类样本(可以构成螺旋形)
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())
# visualise the data
plot_data(X, Y)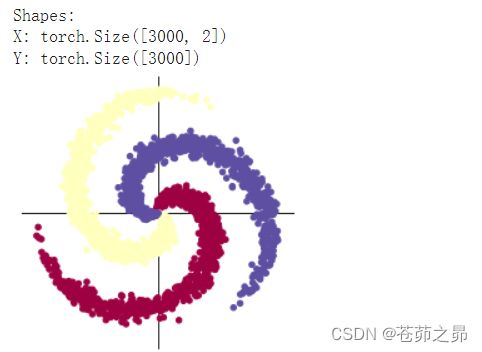
1. 构建线性模型分类
降低梯度:
参数沿着负梯度方向更新可以使函数值下降,能迅速达到局部极小值点,通过优化算法对损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。
随机梯度下降SGD:
从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
models = t.nn.Sequential( t.nn.Linear(input_data, hidden_layer), t.nn.ReLU(), t.nn.Linear(hidden_layer, output_data) )torch.nn.Sequential 括号内的内容就是我们搭建的神经网络模型的具体结:
torch.nn.Linear(input_data,hidden_layer) 完成从输入层到隐藏层的线性变换;
torch.nn.ReLU() 为激活函数;
torch.nn.Linear(hidden_layer, output_data) 完成从隐藏层到输出层的线性变换;
torch.optim.SGD(x,x,x)
model.parameters()
是获取model网络的参数,构建好神经网络后,网络的参数都保存在parameters()函数当中。
learning rate 学习率
学习率即为梯度下降的初始值,设定时可以先将它设置为一个较大的值,然后快速收敛至极值点附近,再减小学习率直至到达极值点
学习率较小时,收敛到极值的速度较慢。 学习率较大时,容易在搜索过程中发生震荡
第三个参数
是一些配置变量,用来优化梯度下降用的,为了防止求得的最优解是局部最优解而不是全局最优解。配置变量包括:learningRate(梯度下降速率),learningRateDecay(梯度下降速率的衰减),weightDecay(权重衰减),momentum(动量 or 冲量)等等
nn.Linear()-Linear中包含四个属性:
1)in_features: 上层神经元个数【每个输入样本的大小】
2)out_features: 本层神经元个数【每个输出样本的大小】
3)weight:权重,形状【out_features , in_features】
4)bias: 偏置,形状[out_features]。网络层是否有偏置,默认存在,且维度为 [out_features];若bias=False,则该网络层无偏置,图层不会学习附加偏差。
创建一个不含激活函数的三层神经网络
learning_rate = 1e-3 # 设定学习率
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 不含激活函数的三层神经网络
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练-1000轮
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率 把预测的和实际的作比较
loss = criterion(y_pred, Y)
# 沿着第二个方向(即X方向)提取最大值。最大的那个值存在score中,所在的位置(即第几列的最大)保存在predicted中
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
# 每轮都打印一下 可以加上if(i%50==0): 让其每50轮打印一下
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
'''grad在反向传播的过程中是累加的,
也就是说上一次反向传播的结果会对下一次的反向传播的结果造成影响,
则意味着每一次运行反向传播,梯度都会累加之前的梯度,
所以一般在反向传播之前需要把梯度清零。
'''
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()![]() 准确率差
准确率差
梯度清零
每一次反向传播前,都要把梯度清零,这个在知乎上有一个回答,可以参考:PyTorch中在反向传播前为什么要手动将梯度清零? - 知乎
PyTorch默认会对梯度进行累加。在反向传播时,如果不想先前的梯度对当前的梯度计算产生影响,就需要手动清零。Pytorch设计这种需要手动清零的方式,目的在于反向传播时,可以支持多种传播方式
这里对上面的一些关键函数进行说明:
使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。下面代码把第10行的情况输出,供解释说明:
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
# Plot trained model
print(model)
plot_model(X, Y, model)
上面使用 print(model) 把模型输出,可以看到有两层:
- 第一层输入为 2(因为特征维度为主2),输出为 100;
- 第二层输入为 100 (上一层的输出),输出为 3(类别数)
从上面图示可以看出,线性模型的准确率最高只能达到 50% 左右,对于这样复杂的一个数据分布,线性模型难以实现准确分类。
2. 构建三层前馈神经网络,引入非线性激活函数ReLU
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)![]()
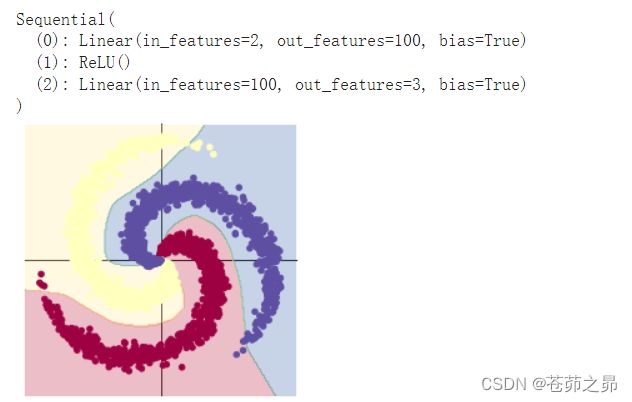
在两层神经网络里加入 ReLU 激活函数以后,准确率达到95%,分类的准确率得到了显著提高。
如果增加神经网络中隐层单元的数量:
H = 200![]()
损失率下降,准确率提高
3.下面试一试双隐层神经网络训练模型的效果

双隐层-四层神经网络
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, 100),
nn.ReLU(),
nn.Linear(100, C),
)
model.to(device)![]()
准确率高达99.9%,损失下降,训练效果极好

另外:激活函数Sigmoid()如果只嵌套一层相比于ReLu等其他的激活函数则其精确度差
详细讲解:神经网络中的激活函数(activation function) - 知乎 (zhihu.com)