比ResNet更强的RepVGG代码详解
RepVGG的PaddlePaddle复现

This is a super simple ConvNet architecture that achieves over 80% top-1 accuracy on ImageNet with a stack of 3x3 conv and ReLU!
paper:https://arxiv.org/abs/2101.03697
前言
Hi Guy!欢迎来到这里,这里是对RepVGG复现以及代码深入讲解,RepVGG通过结构重参数化来使得具有多分支结构的训练模型转化为直筒式单路推理模型,在速度和精度tradeoff下达到了SOTA
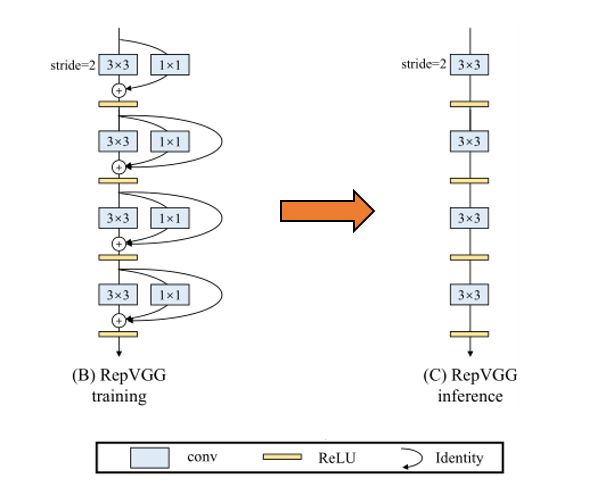
- 本论文代码基于官方Pytorch代码,更原汁原味
- AI Studio有大佬复现过RepVGG,但是没有给出推理模型的转换,本文代码更全,配合代码讲解,更容易理解
- 论文解读:github
RepVGG基础搭建
import paddle
import numpy as np
import paddle.nn as nn
# 国际惯例,导入所需要的包
print('当前版本为:',paddle.__version__)
当前版本为: 2.0.1
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = paddle.nn.Sequential(
('conv',nn.Conv2D(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias_attr=False)),
('bn',nn.BatchNorm2D(num_features=out_channels))
)
return result
# 构造conv+bn组合
# 构建RepVGGBlock模块
# RepVGG除了最后的池化层和分类层之外,都是清一色RepVGGBlock堆叠,十分简单
class RepVGGBlock(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy # deploy是推理部署的意思
self.groups = groups # 输入的特征层分为几组,这是分组卷积概念,单卡GPU不用考虑,默认为1,分组卷积概念详见下面
self.in_channels = in_channels # 输入通道
assert kernel_size == 3
assert padding == 1 # 为什么这么设置呢,图像padding=1后经过 3x3 卷积之后图像大小不变
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias_attr=True, padding_mode=padding_mode)
# 定义推理模型时,基本block就是一个简单的 conv2D
else:
self.rbr_identity = nn.BatchNorm2D(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
# 直接连接,类似resnet残差连接,注意当输入通道和输出通道不同时候,只有 1x1 和 3x3 卷积,没有identity,下面网络图自己体会
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups) #3x3卷积+BN
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups) #1x1卷积+BN
print('RepVGG Block, identity = ', self.rbr_identity) # 这句话就是判断这个block没有identity,没有的话返回None,具体看下图输出
# 定义训练模型时,基本block是 identity、1x1 conv_bn、3x3 conv_bn 组合
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
# 推理阶段, conv2D 后 ReLU
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
# 训练阶段,3x3、1x1、identity 相加后 ReLU
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense) # 卷积核两个参数 W 和 b 提出来
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity) # 为啥可以提出两个参数,看论文公式
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
# 先理解 _fuse_bn_tensor 这个是干啥的,这模块就好理解了
# 卷积核运算本质就是 W(x)+b,但是为啥 identity 可以提取W、b?看后面
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1,1,1,1])
# 这代码讲的是将 1x1 conv padding 一圈成 3x3 conv,填充的是0
# [0 0 0]
# [1] >>>padding>>> [0 1 0]
# [0 0 0]
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
# 当branch不是3x3、1x1、BN,那就返回 W=0, b=0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight # conv权重
running_mean = branch.bn._mean # BN mean
running_var = branch.bn._variance # BN var
gamma = branch.bn.weight # BN γ
beta = branch.bn.bias # BN β
eps = branch.bn._epsilon # 防止分母为0
# 当branch是3x3、1x1时候,返回以上数据,为后面做融合
else:
assert isinstance(branch, nn.BatchNorm2D)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups # 通道分组,单个GPU不用考虑,详情去搜索分组卷积
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) # 定义新的3x3卷积核,参数为0,这里用到DepthWise,详情去搜索MobileNetV1
# 这部分看后面讲解
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 将卷积核对角线部分赋予1
self.id_tensor = paddle.to_tensor(kernel_value)
kernel = self.id_tensor # conv权重
running_mean = branch._mean # BN mean
running_var = branch._variance # BN var
gamma = branch.weight # BN γ
beta = branch.bias # BN β
eps = branch._epsilon # 防止分母为0
# 当branch是 identity,也即只有BN时候返回以上数据
std = (running_var + eps).sqrt()
t = (gamma / std).reshape((-1, 1, 1, 1))
# 提取W、b,不管你是 3x3 1x1 identity都要提取
return kernel * t, beta - running_mean * gamma / std
# 细心的读者发现,上述公式没有提到 conv 1x1、conv 3x3 的 bias
# 这部分是精华,也是难以理解的部分,希望读者多多阅读代码,推推公式,深入理解原理
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return kernel.numpy(), bias.numpy()
代码疑惑部分讲解
- Conv怎么和BN融合
std = (running_var + eps).sqrt()
t = (gamma / std).reshape((-1, 1, 1, 1))
return kernel * t, beta - running_mean * gamma / std

- Identity怎么转3x3 Conv
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups # 通道分组,单个GPU不用考虑,详情去搜索分组卷积
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) # 定义新的3x3卷积核,参数为0,这里用到DepthWise,详情去搜索MobileNetV1
# 这部分看后面讲解
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 将卷积核对角线部分赋予1
self.id_tensor = paddle.to_tensor(kernel_value)
首先我们看分组卷积,图中groups=3,in_channels被分为3份,相应地,Conv channel缩小,降低了一定的参数量,有利于多卡训练,有兴趣请查阅相关文献,本文不做详细讨论
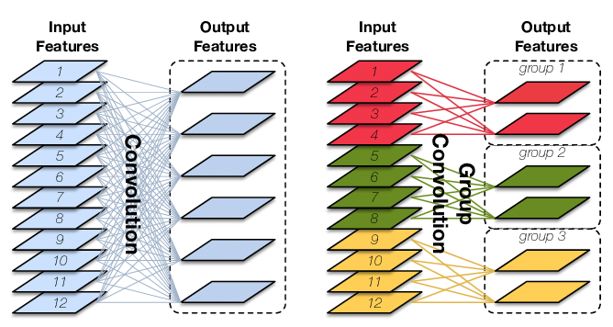
这次为了好理解代码,设置groups=1,input_dim=in_channel
我们来思考一下对于一个Identity,什么样的Conv可以等效

如上图所示,input size为3xHxW,Conv size为3x3x1x1,白色部分是weight=1,灰色部分是weight=0,很容易得出这样的Conv能输出原特征图,达到Identity效果
实际上,由论文我们可以知道,1x1 Conv可以用3x3 Conv替代
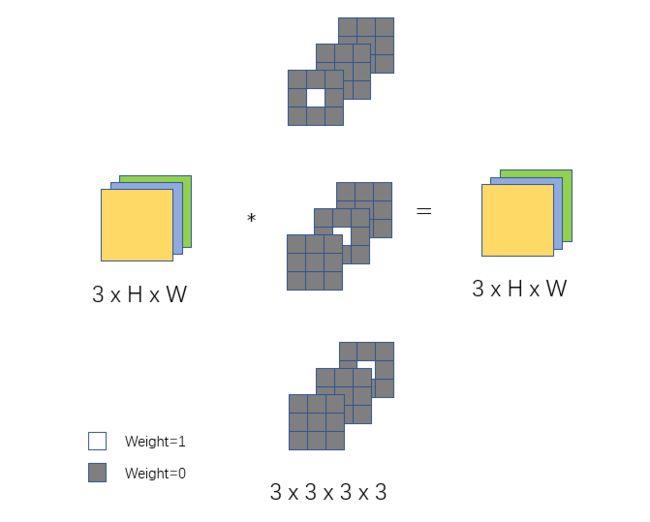
这样的话,Identity就可以由这样的3x3 Conv替代,3x3Conv size为3x3x3x3,
对应代码kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
下面看一下这个Conv中权值为1的位置有什么特点

对应kernel_value[i, i % input_dim, 1, 1] = 1,这样的话刚好可以构建上图所示的Conv
- RepVGG Block
self.rbr_identity = nn.BatchNorm2D(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups) #3x3卷积+BN
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups) #1x1卷积+BN
print('RepVGG Block, identity = ', self.rbr_identity)
- 当RepVGG Block的in_channel ≠ out_channel时,在RepVGG里面负责下采样(stride=2),输入特征图空间维度缩小,特征通道增加,以便提取高层语义特征,此时Block没有Identity,print输出None,a
- 当RepVGG Block的in_channel = out_channel时,Block包含三个Branch,stride=1,print输出相应的BN信息,如b
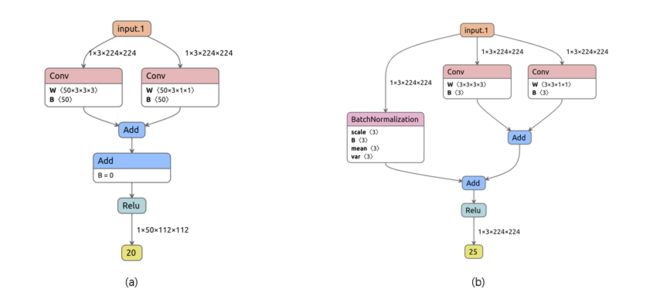
class RepVGG(nn.Layer):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4 # 江湖人称瘦身因子,减小网络的宽度,就是输出通道乘以权重变小还是变大
self.deploy = deploy
self.override_groups_map = override_groups_map or dict() # 这部分是分组卷积,单个GPU不用考虑
assert 0 not in self.override_groups_map
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy)
self.cur_layer_idx = 1 # 分组卷积
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2D(output_size=1) # 全局池化,变成 Nx1x1(CxHxW),类似 flatten
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1) # 分组卷积
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x):
out = self.stage0(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.gap(out)
out = paddle.flatten(out,start_axis=1)
out = self.linear(out)
return out
RepVGG模型实例化
只要改变上述的参数,可以得出不同规模的网络,作者把网络规模分为A类和B类,配置如下

- a,b是缩放系数
- 第一个stage处理大分辨率,只设计一个3x3卷积而减小参数量
- 最后一层channel很多,只设计一个3x3卷积而减小参数量
- 按照ResNet,更多层放到倒数第二个stage
- 为了实现下采样,每个stage第一个3x3卷积将stride设置2
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}
def create_RepVGG_A0(deploy=False,num_classes=10):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=num_classes,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A1(deploy=False,num_classes=10):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=num_classes,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A2(deploy=False,num_classes=10):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=num_classes,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy)
def create_RepVGG_B0(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1g2(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B1g4(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B2(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B2g2(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B2g4(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B3(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B3g2(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B3g4(deploy=False,num_classes=10):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=num_classes,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy)
这次我们选择 RepVGG_A0 作为实例化对象,如果对精度有更高要求,读者也可以选择更大的模型,比如 RepVGG_B2
repvgg_b2=create_RepVGG_B2(num_classes=10)
不同规模网络性能如下
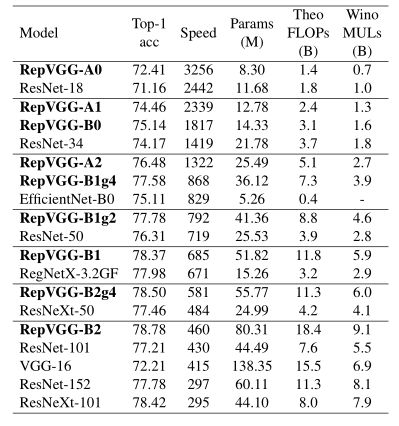
repvgg_a0=create_RepVGG_A0(num_classes=10)
RepVGG Block, identity = None
RepVGG Block, identity = None
RepVGG Block, identity = BatchNorm2D(num_features=48, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = None
RepVGG Block, identity = BatchNorm2D(num_features=96, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=96, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=96, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = None
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = BatchNorm2D(num_features=192, momentum=0.9, epsilon=1e-05)
RepVGG Block, identity = None
repvgg_a0 训练模型可视化,长图警告!!!
- 注意这是训练模型,具有多分支结构,resnet已经证明分支结构适合训练提取特征
- 如果太长影响阅读,点击右上
^键,收缩该图

数据准备
通过Cifar10简单训练网络,本次训练只用简单的Normalize,没有用过多的数据增强,读者可以自己尝试,也可以用更大的数据集(Cifar100)测试该网络的性能
import paddle.vision.transforms as T
from paddle.vision.datasets import Cifar10
# 数据准备
transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
val_dataset = Cifar10(mode='test', transform=transform)
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
Download finished
高层API训练
高层API灵活度不够,暂时没有想到办法通过高层API将 train model 转化成 deploy model,不过大家可以训练一下看看acc如何,作为参考,强烈建议跳过这一部分,看基础API训练
# 高层API
model = paddle.Model(repvgg_a0)
model.summary((1,3,224,224))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 48, 112, 112] 1,296
BatchNorm2D-1 [[1, 48, 112, 112]] [1, 48, 112, 112] 192
Conv2D-2 [[1, 3, 224, 224]] [1, 48, 112, 112] 144
BatchNorm2D-2 [[1, 48, 112, 112]] [1, 48, 112, 112] 192
ReLU-1 [[1, 48, 112, 112]] [1, 48, 112, 112] 0
RepVGGBlock-1 [[1, 3, 224, 224]] [1, 48, 112, 112] 0
Conv2D-3 [[1, 48, 112, 112]] [1, 48, 56, 56] 20,736
BatchNorm2D-3 [[1, 48, 56, 56]] [1, 48, 56, 56] 192
Conv2D-4 [[1, 48, 112, 112]] [1, 48, 56, 56] 2,304
BatchNorm2D-4 [[1, 48, 56, 56]] [1, 48, 56, 56] 192
ReLU-2 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
RepVGGBlock-2 [[1, 48, 112, 112]] [1, 48, 56, 56] 0
BatchNorm2D-5 [[1, 48, 56, 56]] [1, 48, 56, 56] 192
Conv2D-5 [[1, 48, 56, 56]] [1, 48, 56, 56] 20,736
BatchNorm2D-6 [[1, 48, 56, 56]] [1, 48, 56, 56] 192
Conv2D-6 [[1, 48, 56, 56]] [1, 48, 56, 56] 2,304
BatchNorm2D-7 [[1, 48, 56, 56]] [1, 48, 56, 56] 192
ReLU-3 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
RepVGGBlock-3 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
Conv2D-7 [[1, 48, 56, 56]] [1, 96, 28, 28] 41,472
BatchNorm2D-8 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-8 [[1, 48, 56, 56]] [1, 96, 28, 28] 4,608
BatchNorm2D-9 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
ReLU-4 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-4 [[1, 48, 56, 56]] [1, 96, 28, 28] 0
BatchNorm2D-10 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-9 [[1, 96, 28, 28]] [1, 96, 28, 28] 82,944
BatchNorm2D-11 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-10 [[1, 96, 28, 28]] [1, 96, 28, 28] 9,216
BatchNorm2D-12 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
ReLU-5 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-5 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
BatchNorm2D-13 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-11 [[1, 96, 28, 28]] [1, 96, 28, 28] 82,944
BatchNorm2D-14 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-12 [[1, 96, 28, 28]] [1, 96, 28, 28] 9,216
BatchNorm2D-15 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
ReLU-6 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-6 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
BatchNorm2D-16 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-13 [[1, 96, 28, 28]] [1, 96, 28, 28] 82,944
BatchNorm2D-17 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
Conv2D-14 [[1, 96, 28, 28]] [1, 96, 28, 28] 9,216
BatchNorm2D-18 [[1, 96, 28, 28]] [1, 96, 28, 28] 384
ReLU-7 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-7 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
Conv2D-15 [[1, 96, 28, 28]] [1, 192, 14, 14] 165,888
BatchNorm2D-19 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-16 [[1, 96, 28, 28]] [1, 192, 14, 14] 18,432
BatchNorm2D-20 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-8 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-8 [[1, 96, 28, 28]] [1, 192, 14, 14] 0
BatchNorm2D-21 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-17 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-22 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-18 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-23 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-9 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-9 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-24 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-19 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-25 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-20 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-26 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-10 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-10 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-27 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-21 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-28 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-22 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-29 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-11 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-11 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-30 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-23 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-31 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-24 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-32 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-12 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-12 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-33 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-25 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-34 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-26 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-35 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-13 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-13 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-36 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-27 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-37 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-28 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-38 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-14 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-14 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-39 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-29 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-40 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-30 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-41 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-15 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-15 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-42 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-31 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-43 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-32 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-44 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-16 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-16 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-45 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-33 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-46 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-34 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-47 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-17 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-17 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-48 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-35 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-49 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-36 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-50 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-18 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-18 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-51 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-37 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-52 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-38 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-53 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-19 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-19 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-54 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-39 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-55 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-40 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-56 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-20 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-20 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
BatchNorm2D-57 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-41 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,776
BatchNorm2D-58 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
Conv2D-42 [[1, 192, 14, 14]] [1, 192, 14, 14] 36,864
BatchNorm2D-59 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU-21 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-21 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-43 [[1, 192, 14, 14]] [1, 1280, 7, 7] 2,211,840
BatchNorm2D-60 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 5,120
Conv2D-44 [[1, 192, 14, 14]] [1, 1280, 7, 7] 245,760
BatchNorm2D-61 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 5,120
ReLU-22 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 0
RepVGGBlock-22 [[1, 192, 14, 14]] [1, 1280, 7, 7] 0
AdaptiveAvgPool2D-1 [[1, 1280, 7, 7]] [1, 1280, 1, 1] 0
Linear-1 [[1, 1280]] [1, 10] 12,810
===============================================================================
Total params: 7,864,426
Trainable params: 7,817,130
Non-trainable params: 47,296
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 88.73
Params size (MB): 30.00
Estimated Total Size (MB): 119.30
-------------------------------------------------------------------------------
{'total_params': 7864426, 'trainable_params': 7817130}
# 开始训练,也可以不训练,不影响后面运行,建议跳过这一部分
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
vdl_callback = paddle.callbacks.VisualDL(log_dir='log') # 训练可视化
model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=64,
epochs=10,
save_dir='save_models',
verbose=1,
callbacks=vdl_callback # 训练可视化
)
基础API训练
train_batch = paddle.io.DataLoader(train_dataset, batch_size=128, shuffle=True, drop_last=True)
val_batch = paddle.io.DataLoader(val_dataset, batch_size=128, shuffle=True , drop_last=True)
for i in train_batch:
print('迭代器第一轮批次:')
print('图片数据',i[0].shape)
print('标签数据',i[1].shape)
break
print('')
print('标签数据需要利用paddle.unsqueeze()变成[128,1]')
迭代器第一轮批次:
图片数据 [128, 3, 224, 224]
标签数据 [128]
标签数据需要利用paddle.unsqueeze()变成[128,1]
def fit(model,train_batch,val_batch,epoch):
# 参数optimizer设置优化器,参数loss损失函数
opt = paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters())
# 参数loss损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
for epoch_id in range(epoch):
model.train()
for batch_id,batch_data in enumerate(train_batch):
input_batch = batch_data[0]
label_batch = paddle.unsqueeze(batch_data[1],axis=1) # 标签维度变化
predict = model(input_batch)
loss = loss_fn(predict, label_batch)
acc = paddle.metric.accuracy(predict, label_batch)
# 反向传播
loss.backward()
# 更新参数
opt.step()
# 梯度清零
opt.clear_grad()
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch_id, batch_id, loss.numpy(), acc.numpy()))
model.eval()
for batch_id,batch_data in enumerate(val_batch):
img_batch = batch_data[0]
label_batch = paddle.unsqueeze(batch_data[1],axis=1)
predict = model(img_batch)
loss = loss_fn(predict, label_batch)
acc = paddle.metric.accuracy(predict, label_batch)
if batch_id % 20 == 0:
print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id, loss.numpy(), acc.numpy()))
fit(repvgg_a0, train_batch, val_batch, epoch=10)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
epoch: 0, batch_id: 0, loss is: [2.377829], acc is: [0.1015625]
epoch: 0, batch_id: 100, loss is: [1.6956916], acc is: [0.34375]
epoch: 0, batch_id: 200, loss is: [1.2747836], acc is: [0.515625]
epoch: 0, batch_id: 300, loss is: [1.0669378], acc is: [0.609375]
batch_id: 0, loss is: [1.1263782], acc is: [0.609375]
epoch: 1, batch_id: 0, loss is: [1.0189099], acc is: [0.5859375]
epoch: 1, batch_id: 100, loss is: [0.98348755], acc is: [0.6640625]
epoch: 1, batch_id: 200, loss is: [0.8737333], acc is: [0.6640625]
epoch: 1, batch_id: 300, loss is: [0.9537698], acc is: [0.6796875]
batch_id: 0, loss is: [0.6566773], acc is: [0.75]
epoch: 2, batch_id: 0, loss is: [0.65497804], acc is: [0.8046875]
epoch: 2, batch_id: 100, loss is: [0.501753], acc is: [0.8359375]
epoch: 2, batch_id: 200, loss is: [0.6873904], acc is: [0.765625]
epoch: 2, batch_id: 300, loss is: [0.7049354], acc is: [0.765625]
batch_id: 0, loss is: [0.7807969], acc is: [0.734375]
epoch: 3, batch_id: 0, loss is: [0.54755455], acc is: [0.828125]
epoch: 3, batch_id: 100, loss is: [0.50581074], acc is: [0.859375]
epoch: 3, batch_id: 200, loss is: [0.6492828], acc is: [0.7734375]
epoch: 3, batch_id: 300, loss is: [0.4320676], acc is: [0.8515625]
batch_id: 0, loss is: [0.7076975], acc is: [0.7421875]
epoch: 4, batch_id: 0, loss is: [0.3518965], acc is: [0.875]
epoch: 4, batch_id: 100, loss is: [0.37317213], acc is: [0.875]
epoch: 4, batch_id: 200, loss is: [0.52790904], acc is: [0.8359375]
epoch: 4, batch_id: 300, loss is: [0.35826653], acc is: [0.84375]
batch_id: 0, loss is: [0.6337395], acc is: [0.7734375]
epoch: 5, batch_id: 0, loss is: [0.38129145], acc is: [0.84375]
epoch: 5, batch_id: 100, loss is: [0.25682098], acc is: [0.8984375]
epoch: 5, batch_id: 200, loss is: [0.38154456], acc is: [0.8359375]
epoch: 5, batch_id: 300, loss is: [0.25734812], acc is: [0.890625]
batch_id: 0, loss is: [0.45733023], acc is: [0.8515625]
epoch: 6, batch_id: 0, loss is: [0.2598531], acc is: [0.8828125]
epoch: 6, batch_id: 100, loss is: [0.26805323], acc is: [0.90625]
epoch: 6, batch_id: 200, loss is: [0.32644916], acc is: [0.875]
epoch: 6, batch_id: 300, loss is: [0.28311527], acc is: [0.921875]
batch_id: 0, loss is: [0.61987674], acc is: [0.828125]
epoch: 7, batch_id: 0, loss is: [0.2908793], acc is: [0.90625]
epoch: 7, batch_id: 100, loss is: [0.28610078], acc is: [0.90625]
epoch: 7, batch_id: 200, loss is: [0.14960657], acc is: [0.953125]
epoch: 7, batch_id: 300, loss is: [0.08674078], acc is: [0.96875]
batch_id: 0, loss is: [0.69591975], acc is: [0.796875]
epoch: 8, batch_id: 0, loss is: [0.14409035], acc is: [0.953125]
epoch: 8, batch_id: 100, loss is: [0.1729168], acc is: [0.9375]
epoch: 8, batch_id: 200, loss is: [0.24014926], acc is: [0.90625]
epoch: 8, batch_id: 300, loss is: [0.10751949], acc is: [0.96875]
batch_id: 0, loss is: [0.5920343], acc is: [0.8203125]
epoch: 9, batch_id: 0, loss is: [0.06296505], acc is: [0.9921875]
epoch: 9, batch_id: 100, loss is: [0.08444205], acc is: [0.9609375]
epoch: 9, batch_id: 200, loss is: [0.18563382], acc is: [0.9296875]
epoch: 9, batch_id: 300, loss is: [0.15956914], acc is: [0.9609375]
batch_id: 0, loss is: [0.33377635], acc is: [0.875]
训练模型转换推理模型
我们知道,多分支结构适合训练,去拟合数据,防止梯度爆炸梯度消失,但是多分支结构有很多不足,比如占内存,每一个分支就要占据一部分内存,比如推理速度变慢,mac成本高,而对于传统VGG来说,虽然精度不是很高,但是其推理速度十分优秀,原因是直筒式结构,单路一路到底的卷积,尤其是 3x3 卷积,得益于现有计算库比如CuDNN,其计算密度比其他卷积高不少,所以基于此作者提出了结构重参数化,将1x1,identity分支参数融合到3x3,使得RepVGG模型在推理阶段是一路的3x3卷积到底,在速度与精度部分实现了SOTA
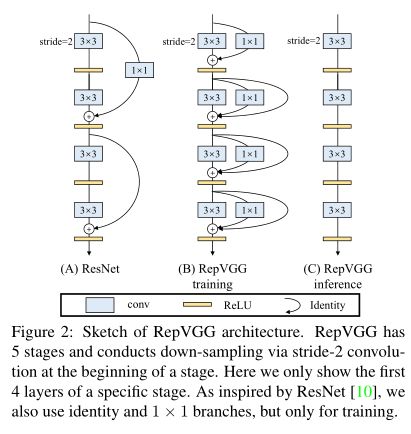
# 模型转换
def repvgg_model_convert(model, build_func):
converted_weights = {} # 将训练模型各层 W 和 bias 存入字典
for name, module in model.named_sublayers():
if hasattr(module, 'repvgg_convert'):
kernel, bias = module.repvgg_convert()
converted_weights[name + '.rbr_reparam.weight'] = kernel
converted_weights[name + '.rbr_reparam.bias'] = bias
elif isinstance(module, nn.Linear):
converted_weights[name + '.weight'] = module.weight.numpy()
converted_weights[name + '.bias'] = module.bias.numpy()
deploy_model = build_func
for name, param in deploy_model.named_parameters():
print('deploy param: ', name, np.mean(converted_weights[name]))
param.data = paddle.to_tensor(converted_weights[name])
return deploy_model
deploy_model = repvgg_model_convert(repvgg_a0, create_RepVGG_A0(deploy=True,num_classes=10))
# 输出每一block参数
deploy param: stage0.rbr_reparam.weight -0.012085067
deploy param: stage0.rbr_reparam.bias 0.045714345
deploy param: stage1.0.rbr_reparam.weight -4.6854173e-05
deploy param: stage1.0.rbr_reparam.bias -0.020605326
deploy param: stage1.1.rbr_reparam.weight 0.0008855257
deploy param: stage1.1.rbr_reparam.bias -0.12333813
deploy param: stage2.0.rbr_reparam.weight -0.00063567486
deploy param: stage2.0.rbr_reparam.bias 0.23614872
deploy param: stage2.1.rbr_reparam.weight -0.00056437775
deploy param: stage2.1.rbr_reparam.bias 0.24321677
deploy param: stage2.2.rbr_reparam.weight -0.00067081465
deploy param: stage2.2.rbr_reparam.bias 0.2832947
deploy param: stage2.3.rbr_reparam.weight -0.0004131663
deploy param: stage2.3.rbr_reparam.bias 0.04254788
deploy param: stage3.0.rbr_reparam.weight -0.0011545079
deploy param: stage3.0.rbr_reparam.bias 0.5689105
deploy param: stage3.1.rbr_reparam.weight -0.00042346717
deploy param: stage3.1.rbr_reparam.bias 0.020992994
deploy param: stage3.2.rbr_reparam.weight -0.00041332928
deploy param: stage3.2.rbr_reparam.bias 0.03356257
deploy param: stage3.3.rbr_reparam.weight -0.00028026314
deploy param: stage3.3.rbr_reparam.bias -0.103242874
deploy param: stage3.4.rbr_reparam.weight -0.00030400493
deploy param: stage3.4.rbr_reparam.bias -0.0461667
deploy param: stage3.5.rbr_reparam.weight -4.5831683e-05
deploy param: stage3.5.rbr_reparam.bias -0.26605505
deploy param: stage3.6.rbr_reparam.weight 6.658539e-05
deploy param: stage3.6.rbr_reparam.bias -0.32315442
deploy param: stage3.7.rbr_reparam.weight 9.768512e-05
deploy param: stage3.7.rbr_reparam.bias -0.32622793
deploy param: stage3.8.rbr_reparam.weight 0.000116009425
deploy param: stage3.8.rbr_reparam.bias -0.2892122
deploy param: stage3.9.rbr_reparam.weight 0.00022997792
deploy param: stage3.9.rbr_reparam.bias -0.36509892
deploy param: stage3.10.rbr_reparam.weight 0.00022792583
deploy param: stage3.10.rbr_reparam.bias -0.35063317
deploy param: stage3.11.rbr_reparam.weight 0.00033351785
deploy param: stage3.11.rbr_reparam.bias -0.3873196
deploy param: stage3.12.rbr_reparam.weight 0.0002637774
deploy param: stage3.12.rbr_reparam.bias -0.32720482
deploy param: stage3.13.rbr_reparam.weight 4.850667e-05
deploy param: stage3.13.rbr_reparam.bias -0.097426474
deploy param: stage4.0.rbr_reparam.weight 7.6041026e-05
deploy param: stage4.0.rbr_reparam.bias -0.17974474
deploy param: linear.weight -0.0033639586
deploy param: linear.bias 2.7480442e-05
# 得到的deploy_model在Cifar10数据集进行eval
deploy_model.eval()
loss_fn = paddle.nn.CrossEntropyLoss()
for batch_id,batch_data in enumerate(val_batch):
img_batch = batch_data[0]
label_batch = paddle.unsqueeze(batch_data[1],axis=1)
predict = repvgg_a0(img_batch)
loss = loss_fn(predict, label_batch)
acc = paddle.metric.accuracy(predict, label_batch)
if batch_id % 20 == 0:
print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id, loss.numpy(), acc.numpy()))
# 和上面训练模型比一下 acc
batch_id: 0, loss is: [0.66172945], acc is: [0.765625]
batch_id: 20, loss is: [1.0397379], acc is: [0.7890625]
batch_id: 40, loss is: [0.89671266], acc is: [0.7890625]
batch_id: 60, loss is: [0.49206328], acc is: [0.84375]
# 查看模型
# print(deploy_model)
# 高阶封装查看
deploy_model_hapi=paddle.Model(deploy_model)
deploy_model_hapi.summary((1,3,224,224))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-45 [[1, 3, 224, 224]] [1, 48, 112, 112] 1,344
ReLU-23 [[1, 48, 112, 112]] [1, 48, 112, 112] 0
RepVGGBlock-23 [[1, 3, 224, 224]] [1, 48, 112, 112] 0
Conv2D-46 [[1, 48, 112, 112]] [1, 48, 56, 56] 20,784
ReLU-24 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
RepVGGBlock-24 [[1, 48, 112, 112]] [1, 48, 56, 56] 0
Conv2D-47 [[1, 48, 56, 56]] [1, 48, 56, 56] 20,784
ReLU-25 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
RepVGGBlock-25 [[1, 48, 56, 56]] [1, 48, 56, 56] 0
Conv2D-48 [[1, 48, 56, 56]] [1, 96, 28, 28] 41,568
ReLU-26 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-26 [[1, 48, 56, 56]] [1, 96, 28, 28] 0
Conv2D-49 [[1, 96, 28, 28]] [1, 96, 28, 28] 83,040
ReLU-27 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-27 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
Conv2D-50 [[1, 96, 28, 28]] [1, 96, 28, 28] 83,040
ReLU-28 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-28 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
Conv2D-51 [[1, 96, 28, 28]] [1, 96, 28, 28] 83,040
ReLU-29 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
RepVGGBlock-29 [[1, 96, 28, 28]] [1, 96, 28, 28] 0
Conv2D-52 [[1, 96, 28, 28]] [1, 192, 14, 14] 166,080
ReLU-30 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-30 [[1, 96, 28, 28]] [1, 192, 14, 14] 0
Conv2D-53 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-31 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-31 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-54 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-32 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-32 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-55 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-33 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-33 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-56 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-34 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-34 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-57 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-35 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-35 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-58 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-36 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-36 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-59 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-37 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-37 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-60 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-38 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-38 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-61 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-39 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-39 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-62 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-40 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-40 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-63 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-41 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-41 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-64 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-42 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-42 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-65 [[1, 192, 14, 14]] [1, 192, 14, 14] 331,968
ReLU-43 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
RepVGGBlock-43 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-66 [[1, 192, 14, 14]] [1, 1280, 7, 7] 2,213,120
ReLU-44 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 0
RepVGGBlock-44 [[1, 192, 14, 14]] [1, 1280, 7, 7] 0
AdaptiveAvgPool2D-2 [[1, 1280, 7, 7]] [1, 1280, 1, 1] 0
Linear-2 [[1, 1280]] [1, 10] 12,810
===============================================================================
Total params: 7,041,194
Trainable params: 7,041,194
Non-trainable params: 0
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 41.07
Params size (MB): 26.86
Estimated Total Size (MB): 68.50
-------------------------------------------------------------------------------
{'total_params': 7041194, 'trainable_params': 7041194}
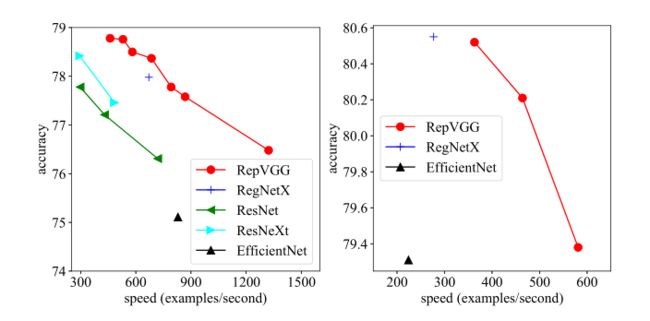
和上面训练模型(高阶封装)对比一下大小,这个是不是很小呀,才68mb左右,一路的3x3卷积是不是特别容易部署
有人问,为什么要特意强调3x3卷积,别的卷积不行吗
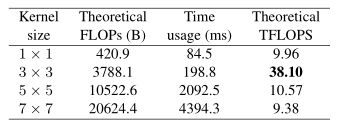
现有的计算库比如CUDA对3x3运算支持有很大的优势,上图可以看出其计算密度(FLOPs/推理时间)达到了38.10!
尤其是对芯片比如FPGA实现,只需要定义简单的算子,就能实现一流的结果
作者在结尾补充,在低端cpu设备,mobilenetv3还是有优势,但是在低端gpu设备下,repvgg优势还是很明显
repvgg_a0 推理模型可视化

Summary
恭喜你一路下滑看到这里,相信你有所收获
总结就不写了,手酸233,下次补上,主要内容都在Github里面了,就是上面的链接
本文长期保持维护更新!
还有自我介绍,就不写了,大家关注我就好啦
长期活跃在AI studio,研究方向是OD(目标检测),每天都在线,有疑问欢迎大家提问,尽力详细回复
Github主页:https://github.com/lmk123568