RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
RepVGG,用结构重参数化(structural re-parameterization)“复兴”VGG式单路极简架构,一路3x3卷到底,在速度和性能上达到SOTA水平,在ImageNet上超过80%正确率。已经被CVPR-2021接收。

论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2101.03697
开源预训练模型和代码(PyTorch版):https://github.com/DingXiaoH/RepVGG
本文的VGG式”指的是:
-
没有任何分支结构。即通常所说的plain或feed-forward架构。
-
仅使用3x3卷积。
-
仅使用ReLU作为激活函数。
下面用一句话介绍RepVGG模型的基本架构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
再用一句话介绍RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64, 128, 256, 512]的若干倍。这里的倍数是随意指定的诸如1.5,2.5这样的“工整”的数字,没有经过细调。
为什么要用VGG式模型
除了我们相信简单就是美以外,VGG式极简模型至少还有五大现实的优势(详见论文)。
- 3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
- 单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
- 单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
- 单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
- RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。别忘了,单路架构省内存的特性也可以帮我们少做存储单元。
结构重参数化让VGG再次伟大
相比于各种多分支架构(如ResNet,Inception,DenseNet,各种NAS架构),近年来VGG式模型鲜有关注,主要自然是因为性能差。例如,有研究[1]认为,ResNet性能好的一种解释是ResNet的分支结构(shortcut)产生了一个大量子模型的隐式ensemble(因为每遇到一次分支,总的路径就变成两倍),单路架构显然不具备这种特点。
既然多分支架构是对训练有益的,而我们想要部署的模型是单路架构,我们提出解耦训练时和推理时架构。我们通常使用模型的方式是:
- 训练一个模型
- 部署这个模型
但在这里,我们提出一个新的做法: - 训练一个多分支模型
- 将多分支模型等价转换为单路模型
- 部署单路模型
这样就可以同时利用多分支模型训练时的优势(性能高,能达到更高的准确度)和单路模型推理时的好处(速度快、内存少)。这里的关键显然在于这种多分支模型的构造形式和转换的方式。
在实现方式是在训练时,为每一个33的卷积层添加平行的11卷积分支和恒等映射分支,构成一个RepVGG Block。这种设计是借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,而我们是每层都加。

训练完成后,对模型做等家转换,得到部署模型。根据卷积的线性(可理解成可加性),设三个3*3卷积核分别是W1,W2,W3,有conv(x, W1) + conv(x, W2) + conv(x, W3) = conv(x, W1+W2+W3))。怎样利用这一原理将一个RepVGG Block转换为一个卷积呢?
其实非常简单,因为RepVGG Block中的1x1卷积是相当于一个特殊(卷积核中有很多0)的3x3卷积,而恒等映射是一个特殊(以单位矩阵为卷积核)的1x1卷积,因此也是一个特殊的3x3卷积!我们只需要:
- 把identity转换为1x1卷积,只要构造出一个以单位矩阵为卷积核的1x1卷积即可;
- 把1x1卷积等价转换为3x3卷积,只要用0填充即可。
下图描述了这一转换过程

在这一示例中,输入和输出通道都是2,故两个3x3卷积的参数是4个3x3矩阵,一个1x1卷积的参数是一个2x2矩阵。注意三个分支都有BN(batch normalization)层,其参数包括累积得到的均值及标准差和学得的缩放因子及bias。这并不会妨碍转换的可行性,因为推理时的卷积层和其后的BN层可以等价转换为一个带bias的卷积层(也就是通常所谓的“吸BN”)。
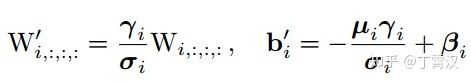
对三分支分别“吸BN”之后(注意恒等映射可以看成一个“卷积层”,其参数是一个2x2单位矩阵!),将得到的1x1卷积核用0给pad成3x3。最后,三分支得到的卷积核和bias分别相加即可。这样,每个RepVGG Block转换前后的输出完全相同,因而训练好的模型可以等价转换为只有3x3卷积的单路模型。

从这一转换过程中,我们看到了“结构重参数化”的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数;只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
实验结果
在1080Ti上测试,RepVGG模型的速度-精度相当出色。在公平的训练设定下,同精度的RepVGG速度是ResNet-50的183%,ResNet-101的201%,EfficientNet的259%,RegNet的131%。注意,RepVGG取得超过EfficientNet和RegNet的性能并没有使用任何的NAS或繁重的人工迭代设计。

这也说明,在不同的架构之间用FLOPs来衡量其真实速度是欠妥的。例如,RepVGG-B2的FLOPs是EfficientNet-B3的10倍,但1080Ti上的速度是后者的2倍,这说明前者的计算密度是后者的20余倍。
在Cityscapes上的语义分割实验表明,在速度更快的情况下,RepVGG模型比ResNet系列高约1%到1.7%的mIoU,或在mIoU高0.37%的情况下速度快62%。

另外一系列ablation studies和对比实验表明,结构重参数化是RepVGG模型性能出色的关键
最后需要注明的是,RepVGG是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如MobileNet和ShuffleNet系列适用。
代码
import torch.nn as nn
import numpy as np
import torch
import copy
from .se_block import SEBlock
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
# Optional. This improves the accuracy and facilitates quantization.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
K3 = self.rbr_dense.conv.weight
K1 = self.rbr_1x1.conv.weight
t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
return l2_loss_eq_kernel + l2_loss_circle
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
self.use_se = use_se
assert 0 not in self.override_groups_map
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy, use_se=self.use_se)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy, use_se=self.use_se))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x):
out = self.stage0(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
# out = self.gap(out)
# out = out.view(out.size(0), -1)
# out = self.linear(out)
return out
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}
def create_RepVGG_A0(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A1(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A2(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy)
def create_RepVGG_B0(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B1g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B2g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B2g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B3(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B3g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B3g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_D2se(deploy=False):
return RepVGG(num_blocks=[8, 14, 24, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True)
func_dict = {
'RepVGG-A0': create_RepVGG_A0,
'RepVGG-A1': create_RepVGG_A1,
'RepVGG-A2': create_RepVGG_A2,
'RepVGG-B0': create_RepVGG_B0,
'RepVGG-B1': create_RepVGG_B1,
'RepVGG-B1g2': create_RepVGG_B1g2,
'RepVGG-B1g4': create_RepVGG_B1g4,
'RepVGG-B2': create_RepVGG_B2,
'RepVGG-B2g2': create_RepVGG_B2g2,
'RepVGG-B2g4': create_RepVGG_B2g4,
'RepVGG-B3': create_RepVGG_B3,
'RepVGG-B3g2': create_RepVGG_B3g2,
'RepVGG-B3g4': create_RepVGG_B3g4,
'RepVGG-D2se': create_RepVGG_D2se, # Updated at April 25, 2021. This is not reported in the CVPR paper.
}
def get_RepVGG_func_by_name(name):
return func_dict[name]
# Use this for converting a RepVGG model or a bigger model with RepVGG as its component
# Use like this
# model = create_RepVGG_A0(deploy=False)
# train model or load weights
# repvgg_model_convert(model, save_path='repvgg_deploy.pth')
# If you want to preserve the original model, call with do_copy=True
# ====================== for using RepVGG as the backbone of a bigger model, e.g., PSPNet, the pseudo code will be like
# train_backbone = create_RepVGG_B2(deploy=False)
# train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
# train_pspnet = build_pspnet(backbone=train_backbone)
# segmentation_train(train_pspnet)
# deploy_pspnet = repvgg_model_convert(train_pspnet)
# segmentation_test(deploy_pspnet)
# ===================== example_pspnet.py shows an example
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model
在模型训练的时候,调用的create_RepVGG_A1中的deploy=False
模型的结构重组的实现:
import torch
train_model = create_RepVGG_A0(deploy=False)
train_model.eval() # Don't forget to call this before inference.
deploy_model = repvgg_model_convert(train_model,save_path="***")
模型经过结构重组后,在推理的时,将create_RepVGG_A1中的deploy=True,并加载重组后的模型
实现对比:
对比结构重组前后的推理速度,重组后的模型的推理速度比重组前的快一丢丢,效果不明显