基于知识图谱的问答系统实践
文章目录
- 1 项目目标
-
- 1.1 数据情况
- 1.2 问题分类
- 2 技术方案
-
- 2.1 数据准备
- 2.2 数据入库
- 2.3 查询部分
- 3 模型
-
- 3.1 问题分类
-
- 3.1.1 数据准备
- 3.1.2 分类模型TextCNN
- 3.2 不同类型的问题处理逻辑
- 4 总结与优化
1 项目目标
1.1 数据情况
基于知识图谱的问答系统,简称为KBQA,是知识图谱的一种应用方式。在本项目中的知识图谱数据是关于公司的。数据中包含公司的主键、名称、分红方式、所处行业、债券类型等,也包含公司主要职位的人物名称,还有公司与公司之间的关系。
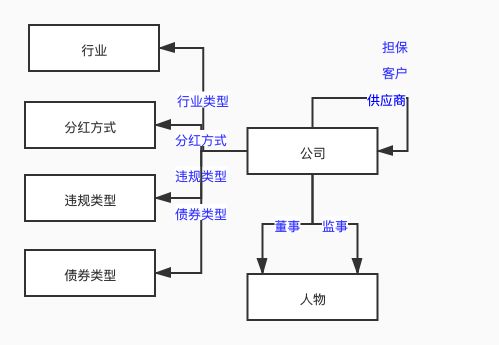
经过分析之后,我们建立的图谱中的实体有:公司、人物、行业、分红方式、违规类型、债券类型。公司的属性有:名称、收益。人物的属性有:名称、年龄。其他实体的属性只有:名称。
公司与公司之间的关系有:供应商、客户、公担保。人物与公司之间的关系有:监事、董事。公司与行业的关系:属于。公司与分红方式的关系:属于。其他类似。将属性公司的所处行业属性按照关系来处理,便于之后进行查询。
1.2 问题分类
KBQA问题可以分为事实类问题、是非类问题、对比类问题、原因方法类问题等。我们这里只回答事实类问题。
事实类问题又分为:查询实体、查询属性、查询关系。
查询实体:收益大于1000的公司有哪些
查询属性:秦皇岛兴龙房地产集团有限公司的收益是多少
查询关系:秦皇岛兴龙房地产集团有限公司的董事是谁 秦皇岛兴龙房地产集团有限公司的供应商的收益是多少
其中查询关系又分为一跳和多跳。
项目目标1:能够识别这三类问题,给出正确答案。
项目目标2:能够识别公司名称缩写,在输入缩写名称的时候也能查询到正确答案。例如 输入 兴隆地产,也能连接到秦皇岛兴龙房地产集团有限公司。
2 技术方案
2.1 数据准备
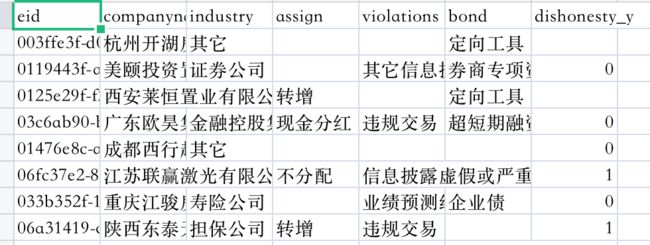
原始数据存在excel中,是以属性的方式存储的。将其拆分为公司、人物、行业等excel。
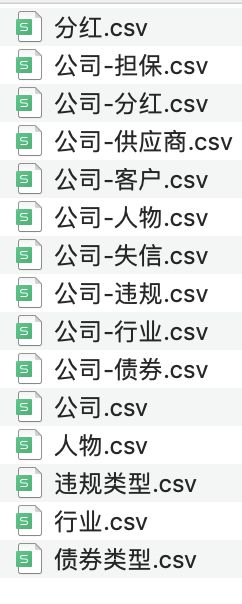
2.2 数据入库
使用py2neo4j库,将数据存入neo4j数据库。形成6类实体,9类关系。
部分代码。
def import_company():
df = pd.read_csv('company_data/公司.csv')
eid = df['eid'].values
name = df['companyname'].values
nodes = []
data = list(zip(eid, name))
for eid, name in tqdm(data):
profit = np.random.randint(10000, 1000000, 1)[0]
node = Node('company', name=name, profit=int(profit), eid=eid)
nodes.append(node)
graph.create(Subgraph(nodes))

2.3 查询部分
我们的实现逻辑是:先对问题分类,每一类问题有对应的,符合cypher语法的模板。
查询实体、查询属性、查询关系。
查询实体:收益大于1000的公司有哪些
查询属性:秦皇岛兴龙房地产集团有限公司的收益是多少
查询关系:秦皇岛兴龙房地产集团有限公司的董事是谁 秦皇岛兴龙房地产集团有限公司的供应商的收益是多少
其中查询关系又分为一跳和多跳。
例如对于查询实体类的问题:收益大于1000的公司有哪些。当分到”查询实体类“这个类别之后,提取出关系【收益】,提取出object 1000,提取操作符 大于,使用语句:match (n:company) where n.profit > 1000 return n.name,对应的查询模板是:match (n:{subject_type}) where n.{attribute}{op}{num} return n.name
整个的处理过程是:问题分类->提取值,填充模板->查询。
问题分类使用TextCNN模型。
提取值,填充模板:不同类型的问题有不同的处理逻辑
查询:使用py2neo4j查询
3 模型
3.1 问题分类
我们已知问题分为查询实体、查询属性、查询关系3个类别。
3.1.1 数据准备
我们按照需求调研阶段发现的用户可能问问题的方式自动生成一些分类数据,用来训练分类模型。
例如查询实体,我们可能根据名称、收益、年龄三个属性查询实体。提出的问题可能有:
收益大于1000的公司
收益等于1000的公司
收益是1000的公司
哪些公司收益大于1000
哪些公司收益等于1000
哪些公司收益是1000
秦皇岛兴龙房地产集团有限公司
刘放心
我们可以改变数值、公司名称、人物名称生成更多的分类数据。同时,将收益替换成年龄,生成分类数据。
查询属性,我们可能查询公司的收益,查询人物的年龄。提出的问题可能有:
刘放心多大
刘放心几岁
刘放心的年龄
秦皇岛兴龙房地产集团有限公司的收益
秦皇岛兴龙房地产集团有限公司的收入
查询关系,我们可能查询公司的分红方式、合作伙伴、供应商等。提出的问题可能有:
秦皇岛兴龙房地产集团有限公司的董事
秦皇岛兴龙房地产集团有限公司的董事是谁
秦皇岛兴龙房地产集团有限公司的违规类型
秦皇岛兴龙房地产集团有限公司的违规类型是什么
秦皇岛兴龙房地产集团有限公司的违规类型是啥
秦皇岛兴龙房地产集团有限公司的供应商
秦皇岛兴龙房地产集团有限公司的供应商的分红方式
改变公司名称、关系类型,一跳两跳关系,产生更多的数据。
3.1.2 分类模型TextCNN
读取分类数据,并且分词,将得到的词保存到vocab.txt,作为词库。按照单词所处的行作为单词的index。
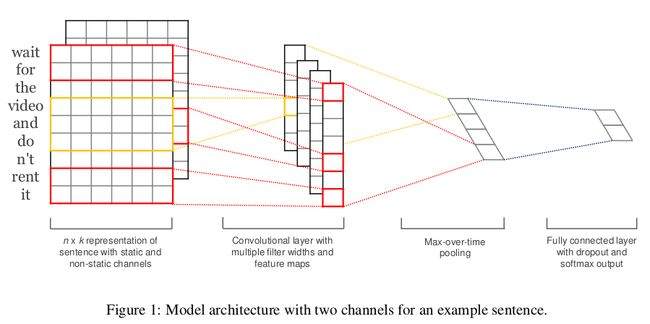
TextCNN详细过程:
- Embedding:将每个单词用256维的向量表示。
- Convolution:模型中设计了3个Convolution。kernel_size 分别为:[3,256],[4,256],[5,256]。每个卷积的输出是100维。这个可以看做分别对句子做了3-gram,4-gram,5-gram语言模型。捕捉了不同长度语言模型的特征。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
- 拼接:将三个卷积经过max-pooling之后的结果拼接起来作为一个结果。输送到下一层。
- dropout:经过dropout层,防止过拟合。
- FullConnection:最后接一层全连接,输出每个类别的概率。
class TextCNN(nn.Module):
def __init__(self, vocab_len, embedding_size, n_class):
super().__init__()
self.embedding = nn.Embedding(vocab_len, embedding_size)
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[3, embedding_size])
self.cnn2 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[4, embedding_size])
self.cnn3 = nn.Conv2d(in_channels=1, out_channels=100, kernel_size=[5, embedding_size])
self.max_pool1 = nn.MaxPool1d(kernel_size=8)
self.max_pool2 = nn.MaxPool1d(kernel_size=7)
self.max_pool3 = nn.MaxPool1d(kernel_size=6)
self.dropout = nn.Dropout(0.2)
self.full_connect = nn.Linear(300, n_class)
def forward(self, x):
embedding = self.embedding(x)
embedding = embedding.unsqueeze(1)
cnn1_out = self.cnn1(embedding)
cnn1_out = cnn1_out.squeeze(-1)
cnn2_out = self.cnn2(embedding)
cnn2_out = cnn2_out.squeeze(-1)
cnn3_out = self.cnn3(embedding)
cnn3_out = cnn3_out.squeeze(-1)
out1 = self.max_pool1(cnn1_out)
out2 = self.max_pool2(cnn2_out)
out3 = self.max_pool3(cnn3_out)
out = torch.cat([out1, out2, out3], dim=1).squeeze(-1)
out = self.dropout(out)
out = self.full_connect(out)
return out
3.2 不同类型的问题处理逻辑
1 查询实体:根据属性以及属性值查询实体。本项目中的实体有公司和人物两类。我们再次看一下问题:
收益大于1000的公司
收益等于1000的公司
收益是1000的公司
哪些公司收益大于1000
哪些公司收益等于1000
哪些公司收益是1000
秦皇岛兴龙房地产集团有限公司
刘放心
第一种是输入名称查询实体,名称可能是公司名称或者是人物名称。我们可以使用AC自动机提取出人名、公司名。换句话说:如果输入的词只有公司名称,那就按照:match (n:company) where n.name = ‘{公司名称}’ return n 返回实体。如果输入的词只有人名,那就按照:match (n:person) where n.name = ‘{人名}’ return n 返回实体。
第二种是按照 年龄、收入查询实体。将属性放入一个集合中,按照字符串匹配识别出属性。接着识别出操作符:大于、小于、等于/是。最后识别出属性值,这里属性值都是数值类型,并且是整数,可以按照正则识别。查询模板:match (n:{subject_type}) where n.{attribute}{op}{num} return n.name,替换具体的值之后查询符合要求的实体。subject_type是查询实体类型:公司、人物。
2 查询属性:我们可能查询公司的收益,查询人物的年龄。我们再看一次问题:
刘放心多大
刘放心的几岁
刘放心的年龄
秦皇岛兴龙房地产集团有限公司的收益
秦皇岛兴龙房地产集团有限公司的收入
发现问题中肯定会有公司名称或者人物名称。多大/几岁/年龄都可以映射到关系age。收入/收益可以映射到关系profit。
这里我们可以使用AC自动机提取出人名、公司名。这里与上一个分类中要做的步骤是一样的。接着,按照字符串匹配的方式找到关系。按照查询模板:match (n:{subject_type}) where n.name = “{subject}” return n.{predicate} ,替换具体的值之后查询实体的属性值。subject_type是查询实体类型:公司、人物。
3 查询关系。我们再看一次问题:
秦皇岛兴龙房地产集团有限公司的董事
秦皇岛兴龙房地产集团有限公司的董事是谁
秦皇岛兴龙房地产集团有限公司的违规类型
秦皇岛兴龙房地产集团有限公司的违规类型是什么
秦皇岛兴龙房地产集团有限公司的违规类型是啥
秦皇岛兴龙房地产集团有限公司的供应商
秦皇岛兴龙房地产集团有限公司的供应商的分红方式
我们已知关系有:董事、理事、违规类型、供应商、客户等9种。
对于一跳关系查询:秦皇岛兴龙房地产集团有限公司的董事,这个处理和查询属性类似:使用AC自动机提取人名/公司名称,字符串匹配得到关系,使用模板:match (s:company)-[p:{p}]->(o) where s.name=’{subject}’ return o.name 查询。
对于多跳关系查询:秦皇岛兴龙房地产集团有限公司的供应商的分红方式。这就要求先找到 ”秦皇岛兴龙房地产集团有限公司的供应商“查询得到答案: 重庆广建装饰股份有限公司。然后将问题替换为”重庆广建装饰股份有限公司的分红方式“。对于该问题要先分类,然后再按照不同类型问题的模板去查询。当前对于这个问题应该属于第三类查询关系,并且是一跳关系。按照模板处理。
这里补充一段代码。
4 总结与优化
本项目完成了基本的KBQA的功能。在知识图谱结构简单的情况下,基本理解了用户的自然语言。
text:刘放心
question type: 0
[[Node(‘person’, age=24, name=‘刘放心’, pid=‘20599583’)]]
text:秦皇岛兴龙房地产集团有限公司
question type: 0
[[Node(‘company’, eid=‘ac386ac1-ec6d-4fdb-b1a7-83ecd383e1ad’, name=‘秦皇岛兴龙房地产集团有限公司’, profit=658095)]]
text:刘放心多大
question type: 1
[[24]]
text:秦皇岛兴龙房地产集团有限公司的收益
question type: 1
[[658095]]
text:龙口市福尔生化科技有限公司的客户的收益
question type: 2
new question: 重庆广建装饰股份有限公司的收益
question type: 1
[[667278]]
text:龙口市福尔生化科技有限公司的客户的董事
question type: 2
new question: 重庆广建装饰股份有限公司的董事
question type: 2
[[‘舒宜民’]
[‘叶东’]
[‘雷吉波’]
[‘叶志常’]
[‘李新来’]
[‘罗武良’]
[‘张志明’]
[‘叶红洁’]
[‘郭赋斌’]
[‘王敬龙’]]
当图谱关系很多,复杂的时候,上述使用逻辑的方式来处理,就不太可能,代码复杂度会变更。这时候可以尝试使用分类算法,将一个问题分类到某种关系查询意图。
这里对于实体识别使用AC自动机的方式,可以考虑替换为分词方式。可以扩展出更多的实体种类。
当前项目只回答了事实类问题,对于是非类问题(例如:刘放心35岁吗?)没有涉及。可以采用适当的方式回答这类问题。